1. 正則表達式基礎
1.1. 簡單介紹
正則表達式并不是Python的一部分。正則表達式是用于處理字符串的強大工具,擁有自己獨特的語法以及一個獨立的處理引擎,效率上可能不如str自帶的方法,但功能十分強大。得益于這一點,在提供了正則表達式的語言里,正則表達式的語法都是一樣的,區別只在于不同的編程語言實現支持的語法數量不同;但不用擔心,不被支持的語法通常是不常用的部分。如果已經在其他語言里使用過正則表達式,只需要簡單看一看就可以上手了。
下圖展示了使用正則表達式進行匹配的流程:
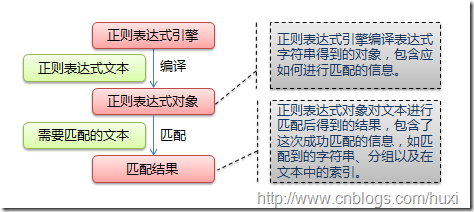
正則表達式的大致匹配過程是:依次拿出表達式和文本中的字符比較,如果每一個字符都能匹配,則匹配成功;一旦有匹配不成功的字符則匹配失敗。如果表達式中有量詞或邊界,這個過程會稍微有一些不同,但也是很好理解的,看下圖中的示例以及自己多使用幾次就能明白。
下圖列出了Python支持的正則表達式元字符和語法:
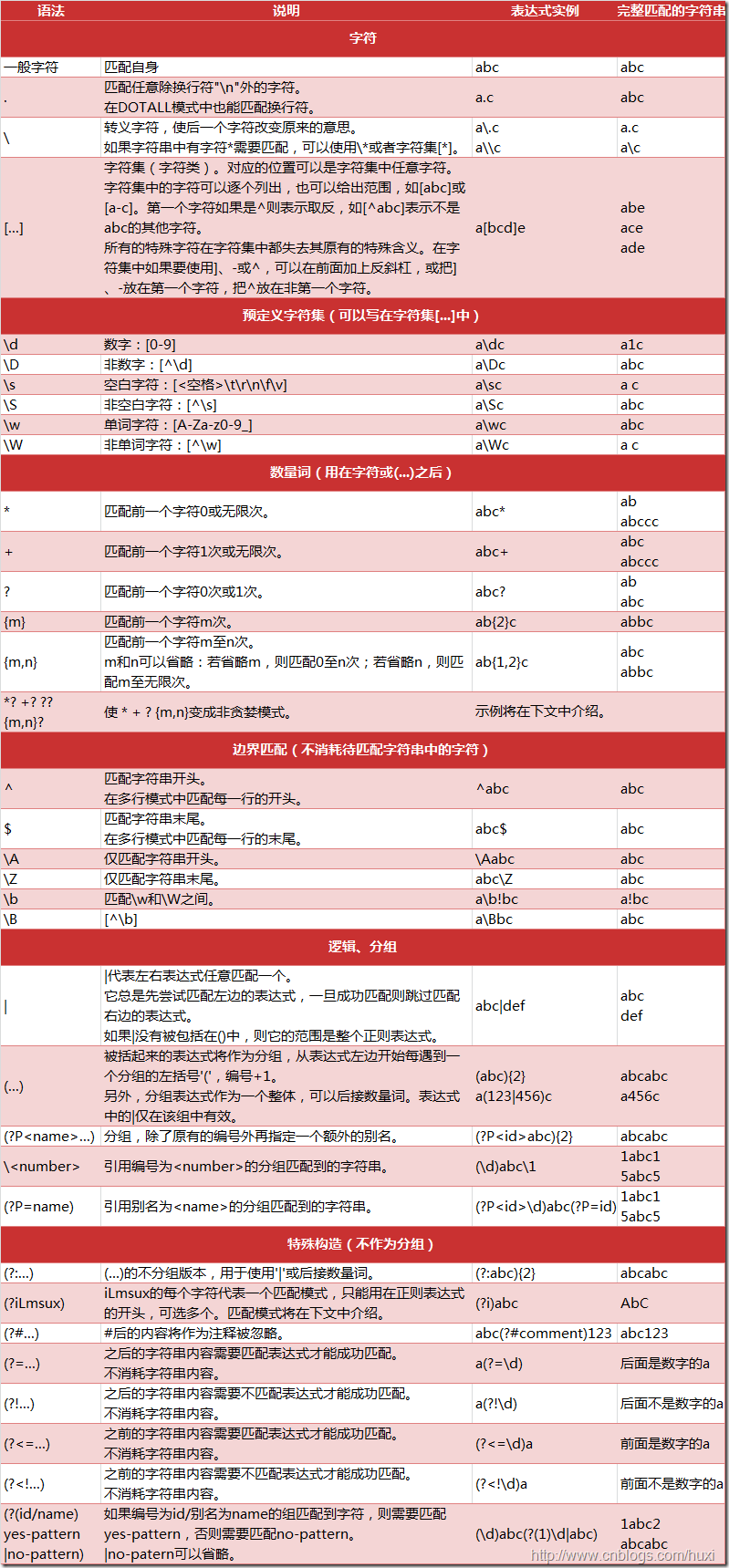
1.2. 數量詞的貪婪模式與非貪婪模式
正則表達式通常用于在文本中查找匹配的字符串。Python里數量詞默認是貪婪的(在少數語言里也可能是默認非貪婪),總是嘗試匹配盡可能多的字符;非貪婪的則相反,總是嘗試匹配盡可能少的字符。例如:正則表達式"ab*“如果用于查找"abbbc”,將找到"abbb"。而如果使用非貪婪的數量詞"ab*?“,將找到"a”。
1.3. 反斜杠的困擾
與大多數編程語言相同,正則表達式里使用"“作為轉義字符,這就可能造成反斜杠困擾。假如你需要匹配文本中的字符”“,那么使用編程語言表示的正則表達式里將需要4個反斜杠”\\\“:前兩個和后兩個分別用于在編程語言里轉義成反斜杠,轉換成兩個反斜杠后再在正則表達式里轉義成一個反斜杠。Python里的原生字符串很好地解決了這個問題,這個例子中的正則表達式可以使用r”\“表示。同樣,匹配一個數字的”\\d"可以寫成r"\d"。有了原生字符串,你再也不用擔心是不是漏寫了反斜杠,寫出來的表達式也更直觀。
1.4. 匹配模式
正則表達式提供了一些可用的匹配模式,比如忽略大小寫、多行匹配等,這部分內容將在Pattern類的工廠方法re.compile(pattern[, flags])中一起介紹。
2. re模塊
2.1. 開始使用re
Python通過re模塊提供對正則表達式的支持。使用re的一般步驟是先將正則表達式的字符串形式編譯為Pattern實例,然后使用Pattern實例處理文本并獲得匹配結果(一個Match實例),最后使用Match實例獲得信息,進行其他的操作。
# encoding: UTF-8
import re# 將正則表達式編譯成Pattern對象
pattern = re.compile(r'hello')# 使用Pattern匹配文本,獲得匹配結果,無法匹配時將返回None
match = pattern.match('hello world!')if match:# 使用Match獲得分組信息print match.group()### 輸出 ###
# hello
re.compile(strPattern[, flag]):
這個方法是Pattern類的工廠方法,用于將字符串形式的正則表達式編譯為Pattern對象。 第二個參數flag是匹配模式,取值可以使用按位或運算符’|‘表示同時生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile(‘pattern’, re.I | re.M)與re.compile(’(?im)pattern’)是等價的。
可選值有:
* re. **I** (re.IGNORECASE): 忽略大小寫(括號內是完整寫法,下同)
* **M** (MULTILINE): 多行模式,改變'^'和'$'的行為(參見上圖)
* **S** (DOTALL): 點任意匹配模式,改變'.'的行為
* **L** (LOCALE): 使預定字符類 \w \W \b \B \s \S 取決于當前區域設定
* **U** (UNICODE): 使預定字符類 \w \W \b \B \s \S \d \D 取決于unicode定義的字符屬性
* **X** (VERBOSE): 詳細模式。這個模式下正則表達式可以是多行,忽略空白字符,并可以加入注釋。以下兩個正則表達式是等價的:
Match
Match對象是一次匹配的結果,包含了很多關于此次匹配的信息,可以使用Match提供的可讀屬性或方法來獲取這些信息。
屬性:
- string : 匹配時使用的文本。
- re : 匹配時使用的Pattern對象。
- pos : 文本中正則表達式開始搜索的索引。值與Pattern.match()和Pattern.seach()方法的同名參數相同。
- endpos : 文本中正則表達式結束搜索的索引。值與Pattern.match()和Pattern.seach()方法的同名參數相同。
- lastindex : 最后一個被捕獲的分組在文本中的索引。如果沒有被捕獲的分組,將為None。
- lastgroup : 最后一個被捕獲的分組的別名。如果這個分組沒有別名或者沒有被捕獲的分組,將為None。
方法:
1. **group([group1, …]):**
獲得一個或多個分組截獲的字符串;指定多個參數時將以元組形式返回。group1可以使用編號也可以使用別名;編號0代表整個匹配的子串;不填寫參數時,返回group(0);沒有截獲字符串的組返回None;截獲了多次的組返回最后一次截獲的子串。
2. groups([default]):
以元組形式返回全部分組截獲的字符串。相當于調用group(1,2,…last)。default表示沒有截獲字符串的組以這個值替代,默認為None。
3. **groupdict([default]):
** 返回以有別名的組的別名為鍵、以該組截獲的子串為值的字典,沒有別名的組不包含在內。default含義同上。
4. start([group]):
返回指定的組截獲的子串在string中的起始索引(子串第一個字符的索引)。group默認值為0。
5. **end([group]):
** 返回指定的組截獲的子串在string中的結束索引(子串最后一個字符的索引+1)。group默認值為0。
6. **span([group]):
** 返回(start(group), end(group))。
# match,從起始位置開始匹配,匹配成功返回一個對象,未匹配成功返回Nonematch(pattern, string, flags=0)# pattern: 正則模型# string : 要匹配的字符串# falgs : 匹配模式X VERBOSE Ignore whitespace and comments for nicer looking RE's.I IGNORECASE Perform case-insensitive matching.M MULTILINE "^" matches the beginning of lines (after a newline)as well as the string."$" matches the end of lines (before a newline) as wellas the end of the string.S DOTALL "." matches any character at all, including the newline.A ASCII For string patterns, make \w, \W, \b, \B, \d, \Dmatch the corresponding ASCII character categories(rather than the whole Unicode categories, which is thedefault).For bytes patterns, this flag is the only availablebehaviour and needn't be specified.L LOCALE Make \w, \W, \b, \B, dependent on the current locale.U UNICODE For compatibility only. Ignored for string patterns (itis the default), and forbidden for bytes patterns.


# 無分組r = re.match("h\w+", origin)print(r.group()) # 獲取匹配到的所有結果print(r.groups()) # 獲取模型中匹配到的分組結果print(r.groupdict()) # 獲取模型中匹配到的分組結果# 有分組# 為何要有分組?提取匹配成功的指定內容(先匹配成功全部正則,再匹配成功的局部內容提取出來)r = re.match("h(\w+).*(?P<name>\d)$", origin)print(r.group()) # 獲取匹配到的所有結果print(r.groups()) # 獲取模型中匹配到的分組結果print(r.groupdict()) # 獲取模型中匹配到的分組中所有執行了key的組
demo
**search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
** 這個方法用于查找字符串中可以匹配成功的子串。從string的pos下標處起嘗試匹配pattern,如果pattern結束時仍可匹配,則返回一個Match對象;若無法匹配,則將pos加1后重新嘗試匹配;直到pos=endpos時仍無法匹配則返回None。
pos和endpos的默認值分別為0和len(string));re.search()無法指定這兩個參數,參數flags用于編譯pattern時指定匹配模式。
# search,瀏覽整個字符串去匹配第一個,未匹配成功返回None
# search(pattern, string, flags=0)

# 無分組r = re.search("a\w+", origin)print(r.group()) # 獲取匹配到的所有結果print(r.groups()) # 獲取模型中匹配到的分組結果print(r.groupdict()) # 獲取模型中匹配到的分組結果# 有分組r = re.search("a(\w+).*(?P<name>\d)$", origin)print(r.group()) # 獲取匹配到的所有結果print(r.groups()) # 獲取模型中匹配到的分組結果print(r.groupdict()) # 獲取模型中匹配到的分組中所有執行了key的組
demo
**split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
** 按照能夠匹配的子串將string分割后返回列表。maxsplit用于指定最大分割次數,不指定將全部分割。
# split,根據正則匹配分割字符串split(pattern, string, maxsplit=0, flags=0)
# pattern: 正則模型
# string : 要匹配的字符串
# maxsplit:指定分割個數
# flags : 匹配模式


# 無分組origin = "hello alex bcd alex lge alex acd 19"r = re.split("alex", origin, 1)print(r)# 有分組origin = "hello alex bcd alex lge alex acd 19"r1 = re.split("(alex)", origin, 1)print(r1)r2 = re.split("(al(ex))", origin, 1)print(r2)
demo
**findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
** 搜索string,以列表形式返回全部能匹配的子串。
# findall,獲取非重復的匹配列表;如果有一個組則以列表形式返回,且每一個匹配均是字符串;如果模型中有多個組,則以列表形式返回,且每一個匹配均是元祖;
# 空的匹配也會包含在結果中
#findall(pattern, string, flags=0)


# 無分組r = re.findall("a\w+",origin)print(r)# 有分組origin = "hello alex bcd abcd lge acd 19"r = re.findall("a((\w*)c)(d)", origin)print(r)
demo
**sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
** 使用repl替換string中每一個匹配的子串后返回替換后的字符串。
當repl是一個字符串時,可以使用\id或\g、\g引用分組,但不能使用編號0。
當repl是一個方法時,這個方法應當只接受一個參數(Match對象),并返回一個字符串用于替換(返回的字符串中不能再引用分組)。
count用于指定最多替換次數,不指定時全部替換。
# sub,替換匹配成功的指定位置字符串sub(pattern, repl, string, count=0, flags=0)
# pattern: 正則模型
# repl : 要替換的字符串或可執行對象
# string : 要匹配的字符串
# count : 指定匹配個數
# flags : 匹配模式


# 與分組無關origin = "hello alex bcd alex lge alex acd 19"r = re.sub("a\w+", "999", origin, 2)print(r)
demo
**subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
** 返回 (sub(repl, string[, count]), 替換次數)。
import rep = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'print p.subn(r'\2 \1', s)def func(m):return m.group(1).title() + ' ' + m.group(2).title()print p.subn(func, s)### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)



















