這里主要是前一篇博文的后續內容,簡單回顧一下:本文選取了n/s/m三款不同量級的模型來依次構建訓練模型,所有的參數保持同樣的設置,之后探索在不同剪枝處理操作下的性能影響。
在上一篇博文中保持30的剪枝程度得到的效果還是比較理想的。這里進行的是分別進行60和90兩種不同程度的剪枝,之后對其進行微調訓練開發,對比分析模型性能。
先看60的結果:
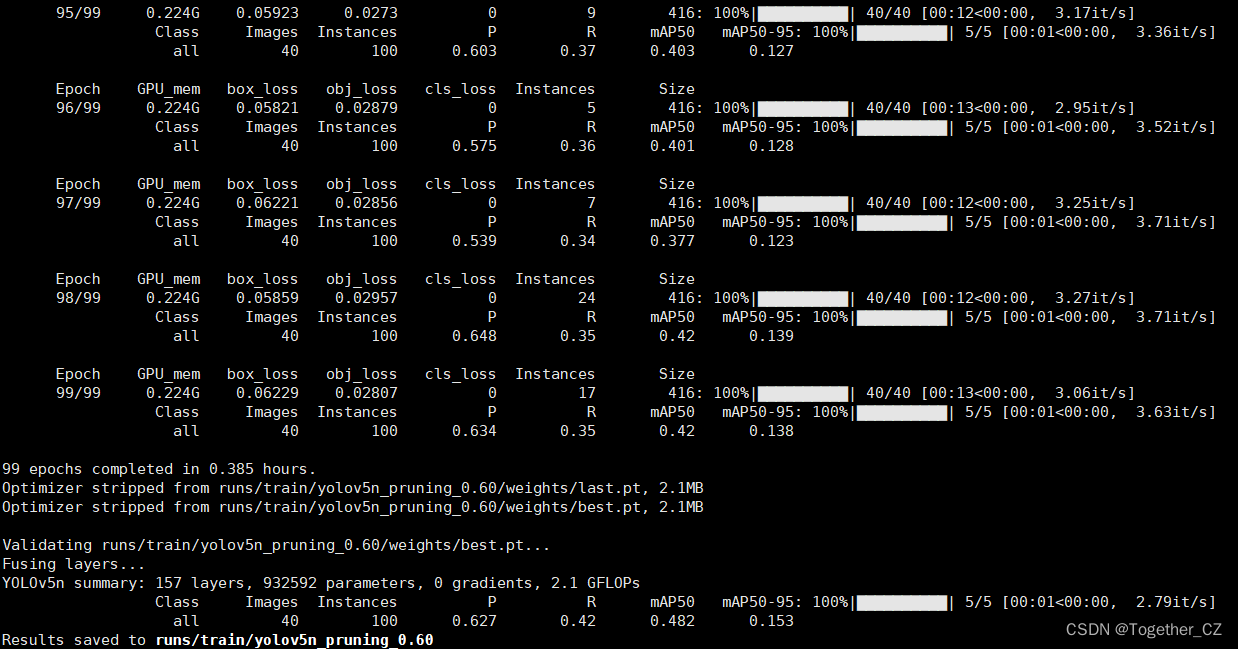
【yolov5n_pruning】
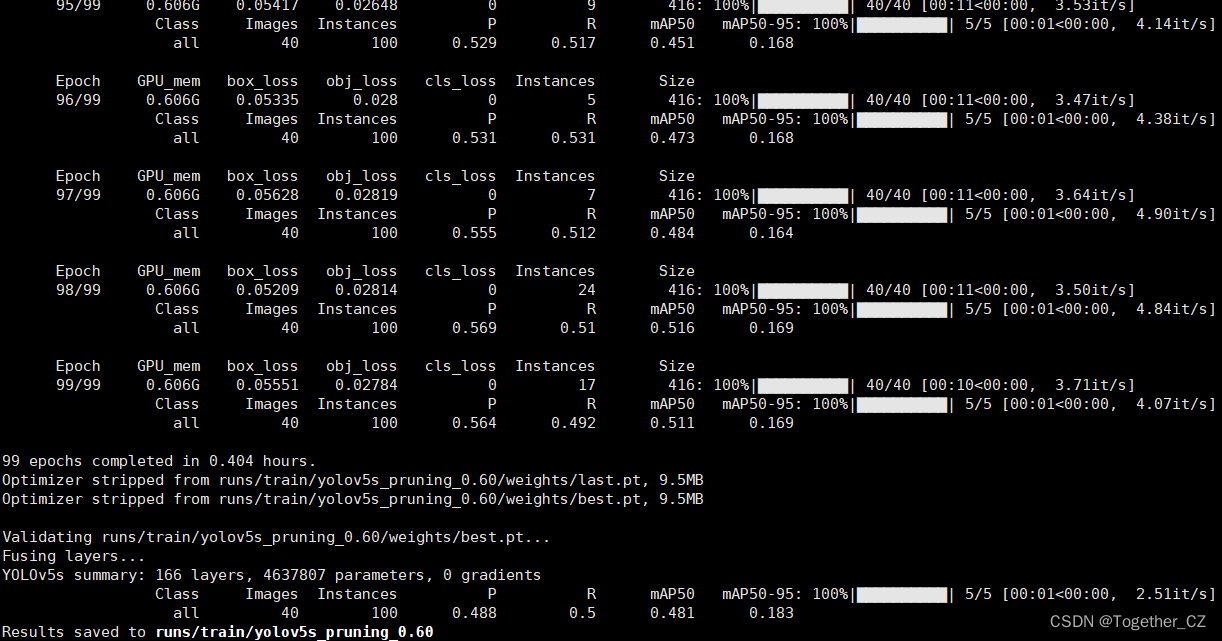
?【yolov5s_pruning】
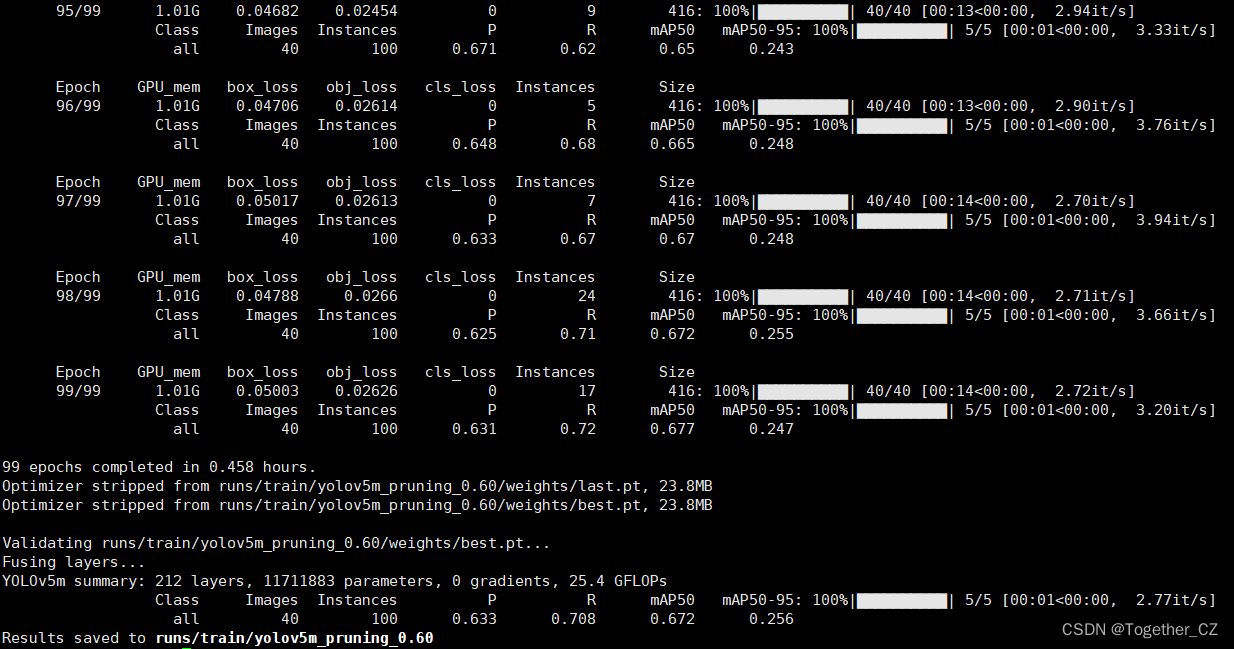
【yolov5m_pruning】
?三款參數量級的模型對比評估結果詳情如下所示:
【yolov5n_pruning】
Validating runs/train/yolov5n_pruning_0.60/weights/best.pt...
Fusing layers...
YOLOv5n summary: 157 layers, 932592 parameters, 0 gradients, 2.1 GFLOPsClass Images Instances P R mAP50 mAP50-95: 100%|██████████| 5/5 [00:01<00:00, 2.79it/s] all 40 100 0.627 0.42 0.482 0.153
Results saved to runs/train/yolov5n_pruning_0.60【yolov5s_pruning】
Validating runs/train/yolov5s_pruning_0.60/weights/best.pt...
Fusing layers...
YOLOv5s summary: 166 layers, 4637807 parameters, 0 gradientsClass Images Instances P R mAP50 mAP50-95: 100%|??????????| 5/5 [00:01<00:00, 2.51it/s] all 40 100 0.488 0.5 0.481 0.183
Results saved to runs/train/yolov5s_pruning_0.60【yolov5m_pruning】
Validating runs/train/yolov5m_pruning_0.60/weights/best.pt...
Fusing layers...
YOLOv5m summary: 212 layers, 11711883 parameters, 0 gradients, 25.4 GFLOPsClass Images Instances P R mAP50 mAP50-95: 100%|██████████| 5/5 [00:01<00:00, 2.77it/s] all 40 100 0.633 0.708 0.672 0.256
Results saved to runs/train/yolov5m_pruning_0.60
綜合對比不難發現:在60%的剪枝程度處理下,各款模型都發現了明顯的精度下降的問題。為了直觀對比分析,我對其進行了可視化,如下所示:
【Precision曲線】
精確率曲線(Precision-Recall Curve)是一種用于評估二分類模型在不同閾值下的精確率性能的可視化工具。它通過繪制不同閾值下的精確率和召回率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率(Precision)是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率曲線。
根據精確率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察精確率曲線,我們可以根據需求確定最佳的閾值,以平衡精確率和召回率。較高的精確率意味著較少的誤報,而較高的召回率則表示較少的漏報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
精確率曲線通常與召回率曲線(Recall Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。

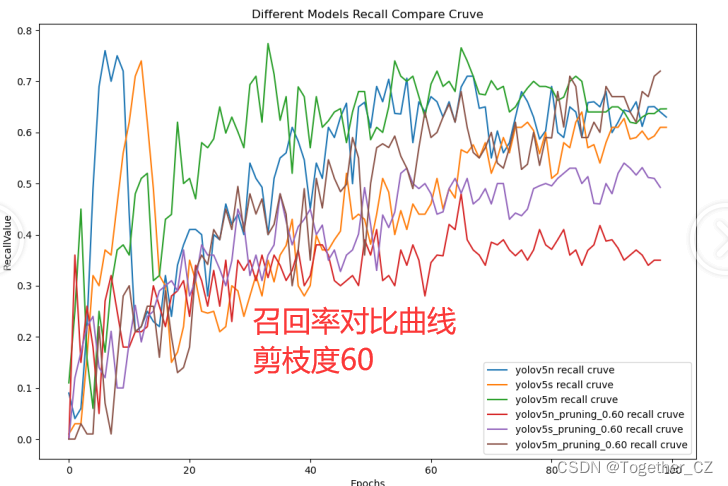
【Recall曲線】
召回率曲線(Recall Curve)是一種用于評估二分類模型在不同閾值下的召回率性能的可視化工具。它通過繪制不同閾值下的召回率和對應的精確率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。召回率也被稱為靈敏度(Sensitivity)或真正例率(True Positive Rate)。
繪制召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的召回率和對應的精確率。
將每個閾值下的召回率和精確率繪制在同一個圖表上,形成召回率曲線。
根據召回率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察召回率曲線,我們可以根據需求確定最佳的閾值,以平衡召回率和精確率。較高的召回率表示較少的漏報,而較高的精確率意味著較少的誤報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
召回率曲線通常與精確率曲線(Precision Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。
【F1值曲線】
F1值曲線是一種用于評估二分類模型在不同閾值下的性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)、召回率(Recall)和F1分數的關系圖來幫助我們理解模型的整體性能。
F1分數是精確率和召回率的調和平均值,它綜合考慮了兩者的性能指標。F1值曲線可以幫助我們確定在不同精確率和召回率之間找到一個平衡點,以選擇最佳的閾值。
繪制F1值曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率、召回率和F1分數。
將每個閾值下的精確率、召回率和F1分數繪制在同一個圖表上,形成F1值曲線。
根據F1值曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
F1值曲線通常與接收者操作特征曲線(ROC曲線)一起使用,以幫助評估和比較不同模型的性能。它們提供了更全面的分類器性能分析,可以根據具體應用場景來選擇合適的模型和閾值設置。
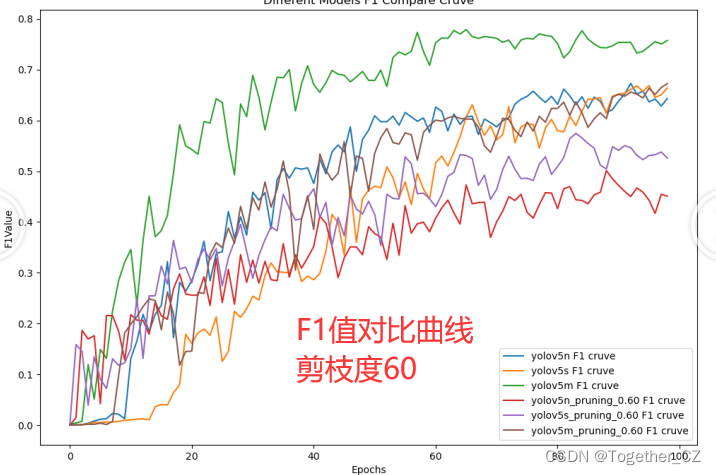
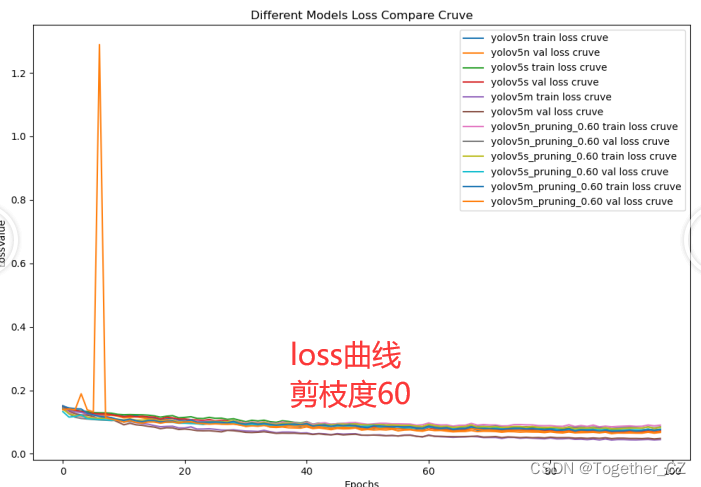
?【loss曲線】
?接下來是剪枝度為90的最后一組實驗。
【yolov5n_pruning】

?【yolov5s_pruning】

?【yolov5m_pruning】

?三款不同參數量級在剪枝度90的情況下,模型評估結果對比如下所示:
【yolov5n_pruning】
Validating runs/train/yolov5n_pruning_0.90/weights/best.pt...
Fusing layers...
YOLOv5n summary: 157 layers, 710530 parameters, 0 gradients, 1.4 GFLOPsClass Images Instances P R mAP50 mAP50-95: 100%|██████████| 5/5 [00:01<00:00, 3.53it/s] all 40 100 0.267 0.23 0.189 0.0464
Results saved to runs/train/yolov5n_pruning_0.90【yolov5s_pruning】
Validating runs/train/yolov5s_pruning_0.90/weights/best.pt...
Fusing layers...
YOLOv5s summary: 166 layers, 3920903 parameters, 0 gradientsClass Images Instances P R mAP50 mAP50-95: 100%|??????????| 5/5 [00:01<00:00, 3.59it/s] all 40 100 0.204 0.27 0.175 0.0635
Results saved to runs/train/yolov5s_pruning_0.90【yolov5m_pruning】
Validating runs/train/yolov5m_pruning_0.90/weights/best.pt...
Fusing layers...
YOLOv5m summary: 212 layers, 8908815 parameters, 0 gradients, 17.7 GFLOPsClass Images Instances P R mAP50 mAP50-95: 100%|??????????| 5/5 [00:01<00:00, 3.21it/s] all 40 100 0.213 0.35 0.221 0.078
Results saved to runs/train/yolov5m_pruning_0.90同樣為了直觀對比分析,我對其也進行了對比可視化展示,如下所示:
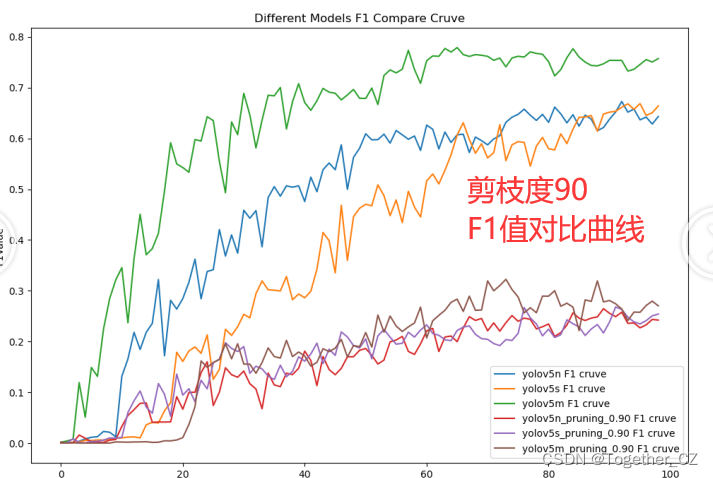
【F1值】
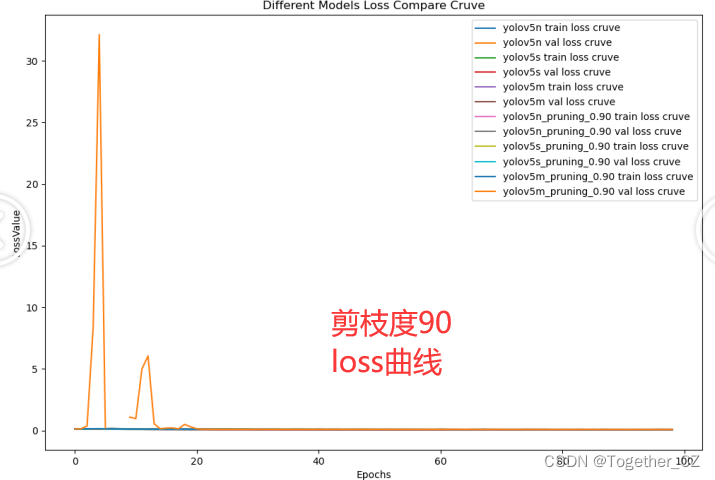
【loss曲線】
?【Precision】
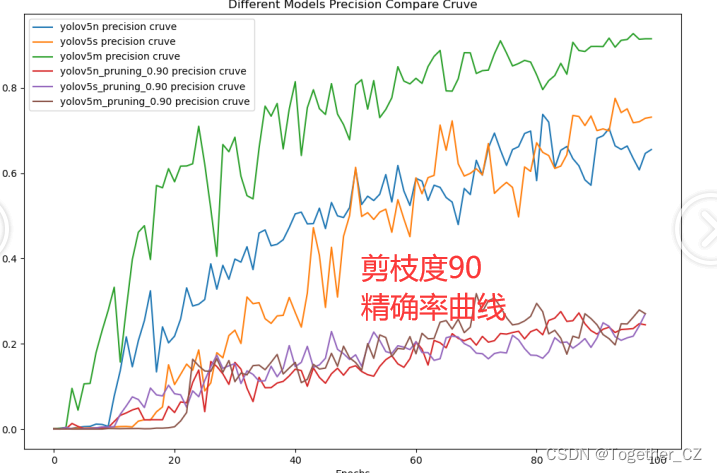
?【Recall】
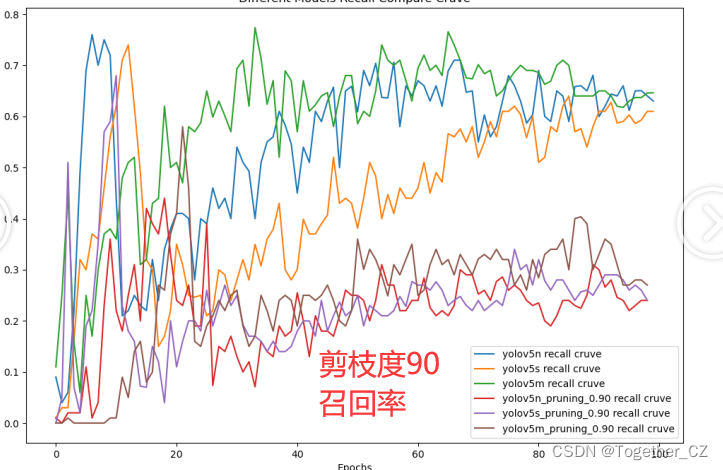
?90的話結果已經變差了很多了。
接下來我整體對比一下30/60/90這三組剪枝實驗結果,如下所示:
【F1值】
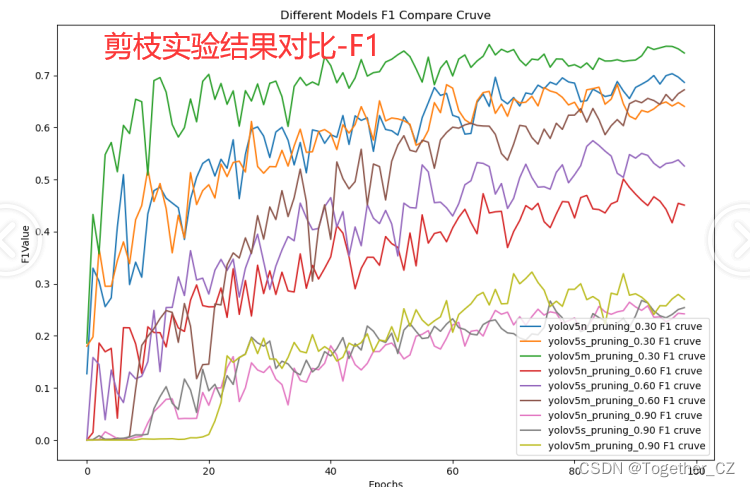
?【loss】

?【Precision】

?【Recall】
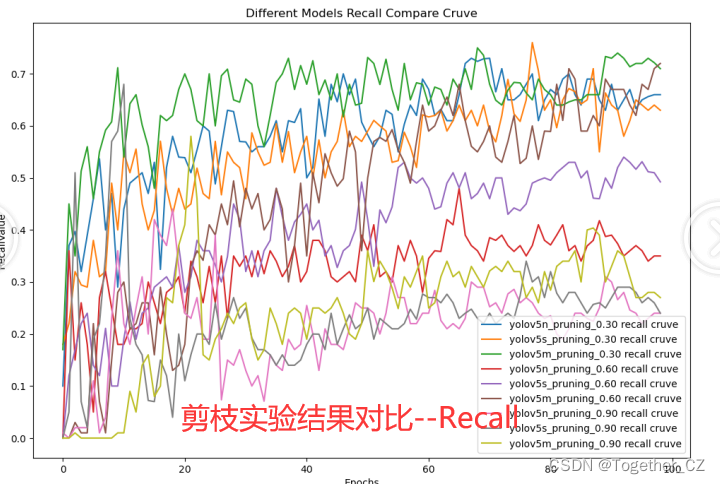
?從對比可視化曲線上面不難看出:剪枝三組實驗效果依次遞降。
精度和速度本身就是一堆需要平衡的指標,在算力條件允許的情況下盡量保持較低程度的剪枝水平會帶來不錯的精度體驗。
最后我們來直觀體驗感受下不同剪枝水平下模型體量的差異:
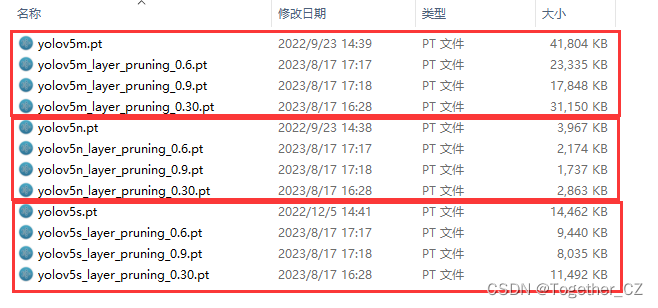
?后面有時間再繼續實驗分析吧。

)














)


