目錄
一、前言
二、Hive事務背景知識
hive事務實現原理
hive事務原理之 —— delta文件夾命名格式
_orc_acid_version 說明
bucket_00000
合并器(Compactor)
二、Hive事務使用限制
參數設置
客戶端參數設置
客戶端參數設置
三、Hive事務使用操作演示
操作步驟
客戶端設置參數
創建一張事務表
插入幾條數據
刪除一條數據
針對事務表的增刪改查操作演示
創建事務表
插入一條數據
修改數據
刪除數據
一、前言
使用過mysql的同學對mysql的事務這個概念應該不陌生,當對mysql的表進行增刪改的時候,mysql會開啟一個事務,以確保本次操作的數據的安全性,在hive3.0之后,hive也開始支持了事務,以滿足一些增刪改的業務場景,接下來將對hive的事務操作做詳細的說明。
二、Hive事務背景知識
Hive設計之初時,是不支持事務的,原因:
- Hive的核心目標是將已經存在的結構化數據文件映射成為表,然后提供基于表的SQL分析處理,是一款面向歷史、面向分析的工具;
- Hive作為數據倉庫,是分析數據規律的,而不是創造數據規律的;
- Hive中表的數據存儲于HDFS上,而HDFS是不支持隨機修改文件數據的,其常見的模型是一次寫入,多次讀取;
從Hive0.14版本開始,具有ACID語義的事務(支持INSERT,UPDATE和DELETE)已添加到Hive中,以解決以下場景下遇到的問題:
1)流式傳輸數據
使用如Apache Flume或Apache Kafka之類的工具將數據流式傳輸到現有分區中,可能會有臟讀(開始查詢后能看到寫入的數據)
2)變化緩慢數據更新
星型模式數據倉庫中,維度表隨時間緩慢變化。例如,零售商將開設新商店,需要將其添加到商店表中,或者現有商店可能會更改其平方英尺或某些其他跟蹤的特征。這些更改需要插入單個記錄或更新記錄(取決于所選策略)
3)數據修正
有時發現收集的數據不正確,需要局部更正
hive事務實現原理
Hive的文件是存儲在HDFS上的,而HDFS上又不支持對文件的任意修改,只能是采取另外的手段來完成。具體來說:
- 用HDFS文件作為原始數據(基礎數據),用delta保存事務操作的記錄增量數據;
- 正在執行中的事務,是以一個staging開頭的文件夾維護的,執行結束就是delta文件夾。每次執行一次事務操作都會有這樣的一個delta增量文件夾;
- 當訪問Hive數據時,根據HDFS原始文件和delta增量文件做合并,查詢最新的數據;

對于insert,update,delete三種操作來說,
1、INSERT語句會直接創建delta目錄;
2、DELETE目錄的前綴是delete_delta;
3、UPDATE語句采用了split-update特性,即先刪除、后插入;
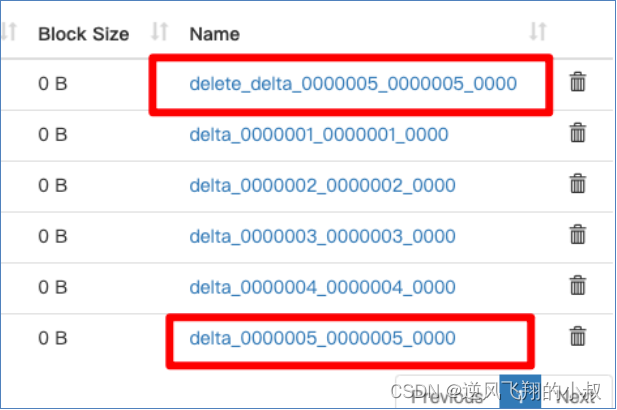
hive事務原理之 —— delta文件夾命名格式
通過上面的描述,大概了解到hive的事務在執行過程中,delta目錄文件很重要,具體來說,一個delta文件的完整名稱,可以拆開來看,各個部分的含義需要分別去理解,比如當我們執行一條delete語句開啟一個事務時,將會出現類似下面第一條格式的文件;

?對于這個文件來說,其完整的含義,可以類比為:delta_minWID_maxWID_stmtID,拆開來看即:
1、即delta前綴、寫事務的ID范圍、以及語句ID;刪除時前綴是delete_delta,里面包含了要刪除的文件;
2、Hive會為寫事務(INSERT、DELETE等)創建一個寫事務ID(Write ID),該ID在表范圍內唯一;
3、語句ID(Statement ID)則是當一個事務中有多條寫入語句時使用的,用作唯一標識;
而每個事務的delta文件夾下,都存在兩個文件

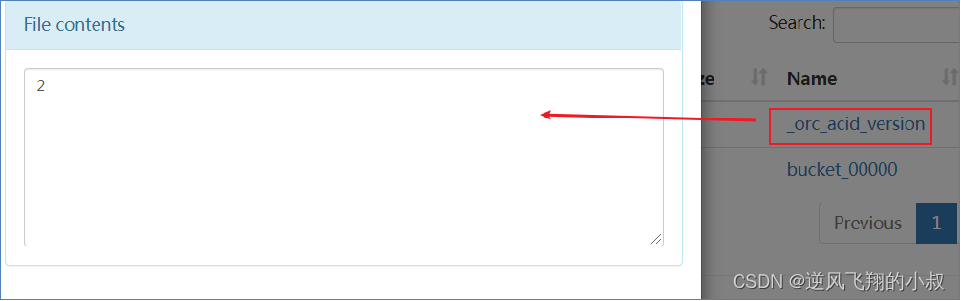
_orc_acid_version 說明
?_orc_acid_version的內容是2,即當前ACID版本號是2。和版本1的主要區別是UPDATE語句采用了split-update特性,即先刪除、后插入。這個文件不是ORC文件,可以下載下來直接查看。
bucket_00000
bucket_00000文件則是寫入的數據內容。如果事務表沒有分區和分桶,就只有一個這樣的文件。文件都以ORC格式存儲,底層二級制,需要使用ORC TOOLS查看,詳見附件資料;
可以通過引入相關的依賴包進行查看

?對于其中的內容做一下補充說明:
- operation:0 表示插入,1 表示更新,2 表示刪除。由于使用了split-update,UPDATE是不會出現的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2;
- originalTransaction、currentTransaction:該條記錄的原始寫事務ID,當前的寫事務ID;
- rowId:一個自增的唯一ID,在寫事務和分桶的組合中唯一;
- row:具體數據,對于DELETE語句,則為null,對于INSERT就是插入的數據,對于UPDATE就是更新后的數據;
合并器(Compactor)
隨著表的修改操作,創建了越來越多的delta增量文件,就需要合并以保持足夠的性能,合并器Compactor是一套在Hive Metastore內運行,支持ACID系統的后臺進程。所有合并都是在后臺完成的,不會阻止數據的并發讀、寫。合并后,系統將等待所有舊文件的讀操作完成后,刪除舊文件。
合并操作分為兩種
- minor compaction(小合并),小合并會將一組delta增量文件重寫為單個增量文件,默認觸發條件為10個delta文件;
- major compaction(大合并),大合并將一個或多個增量文件和基礎文件重寫為新的基礎文件,默認觸發條件為delta文件相應于基礎文件占比10%;

二、Hive事務使用限制
然Hive支持了具有ACID語義的事務,但是在使用起來,并沒有像在MySQL中使用那樣方便,有很多限制,歸納如下:
- 尚不支持BEGIN,COMMIT和ROLLBACK,所有語言操作都是自動提交的;
- 表文件存儲格式僅支持ORC(STORED AS ORC);
- 需要配置參數開啟事務使用;
- 外部表無法創建為事務表,因為Hive只能控制元數據,無法管理數據;
- 表屬性參數transactional必須設置為true;
- 必須將Hive事務管理器設置為org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID表;
- 事務表不支持LOAD DATA ...語句;
參數設置
在使用hive的事務表時,需要對部分參數做設置之后才能生效,參數的設置可以在客戶端,也可以在服務端,兩者任選其一;
客戶端參數設置
# 可以使用set設置當前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; --Hive是否支持并發
set hive.enforce.bucketing = true; --從Hive2.0開始不再需要 是否開啟分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --動態分區模式 非嚴格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --事務管理器客戶端參數設置
set hive.compactor.initiator.on = true; --是否在Metastore實例上運行啟動壓縮合并
set hive.compactor.worker.threads = 1; --在此metastore實例上運行多少個合并程序工作線程三、Hive事務使用操作演示
接下來通過實際操作演示下hive事務表的使用
操作步驟
客戶端設置參數
打開一個客戶端窗口后,執行下面的事務設置參數
set hive.support.concurrency = true; --Hive是否支持并發
set hive.enforce.bucketing = true; --從Hive2.0開始不再需要 是否開啟分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --動態分區模式 非嚴格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore實例上運行啟動壓縮合并
set hive.compactor.worker.threads = 1; --在此metastore實例上運行多少個壓縮程序工作線程。
創建一張事務表
CREATE TABLE emp (id int, name string, salary int)
STORED AS ORC TBLPROPERTIES ('transactional' = 'true');
?
插入幾條數據
INSERT INTO emp VALUES (1, 'Jerry', 5000);
INSERT INTO emp VALUES (2, 'Tom', 8000);
INSERT INTO emp VALUES (3, 'Kate', 6000);
執行過程可以看到走了M-R任務
?同時執行過程中,觀察hdfs目錄文件,可以看到產生了下面的staging文件

?
而執行完成后,正好產生了一個_orc_acid_version文件,以及bucket_00000文件;

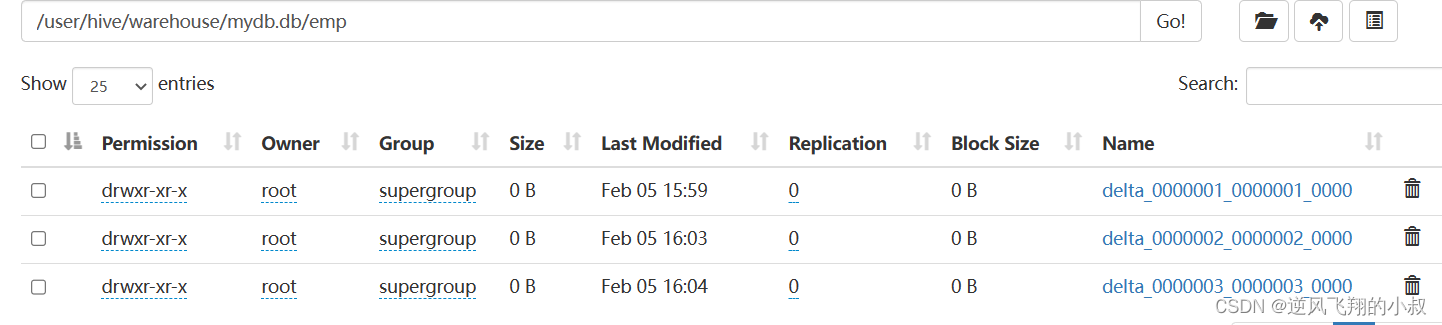
?如果執行多條數據的插入,就會產生多少個下面的文件目錄;
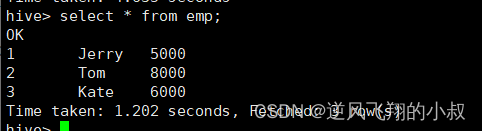
?查詢數據,可以看到已經完成數據的插入;
刪除一條數據
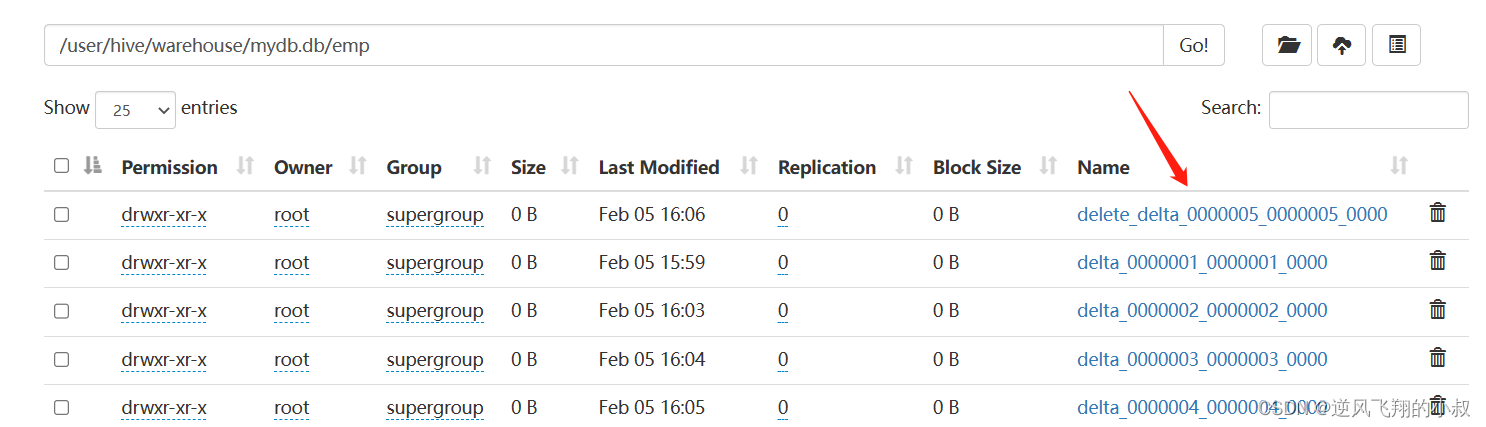
delete from emp where id =2;
執行刪除之后,再次查看hdfs文件目錄,可以看到這里多了一個delete_delta文件,關于這個文件上面我們有詳細的說明;
針對事務表的增刪改查操作演示
創建事務表
create table trans_student(id int,name String,age int
)stored as orc TBLPROPERTIES('transactional'='true');可以通過describe命令查看表的詳細信息
describe formatted trans_student;
插入一條數據
insert into trans_student (id, name, age) values (1,"allen",18);
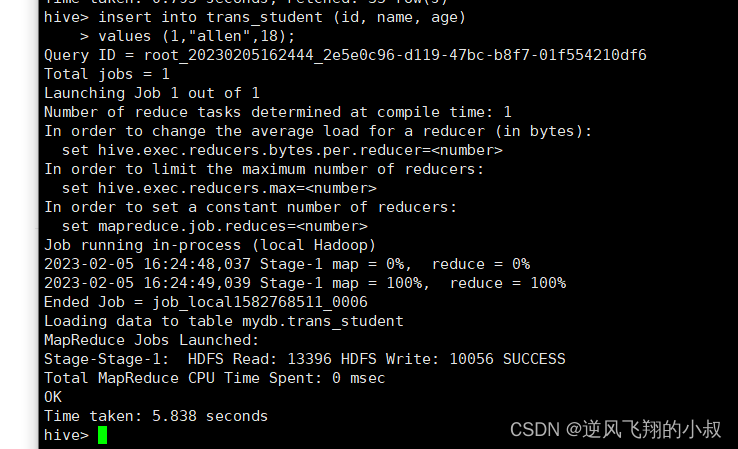
?插入完成后,hdfs文件目錄就生成了相關的事務文件

修改數據
update trans_student
set age = 20
where id = 1;
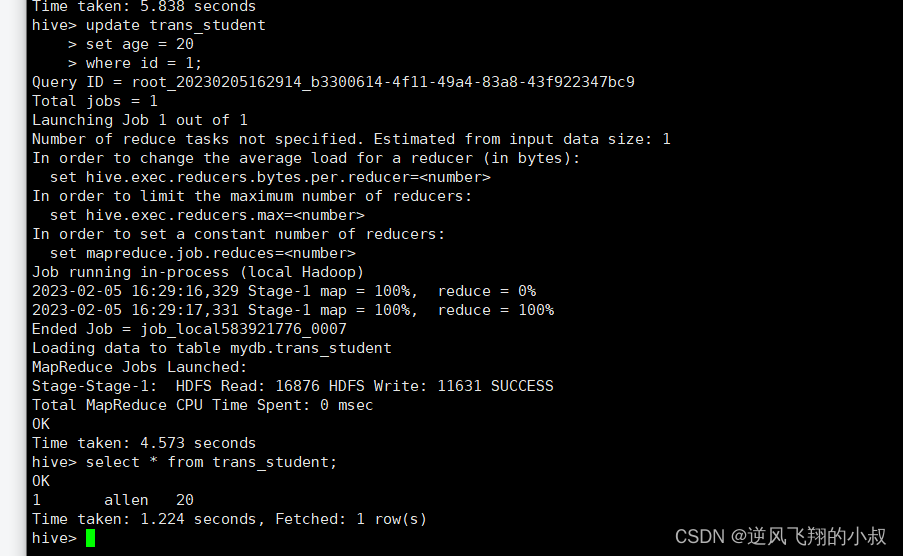
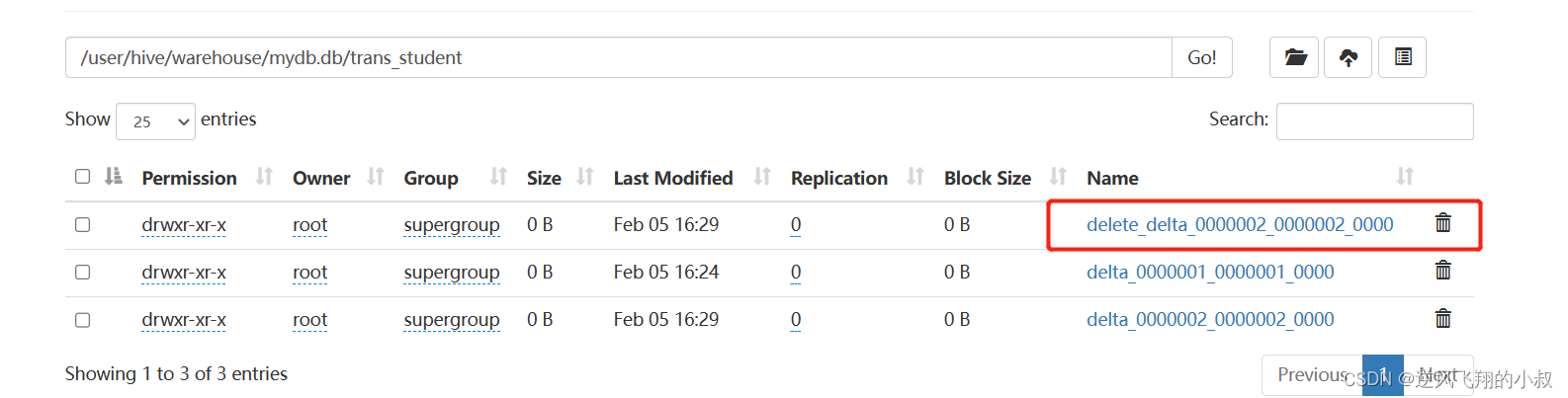
執行完成后,檢查hdfs目錄就多了一個delete_delta文件;
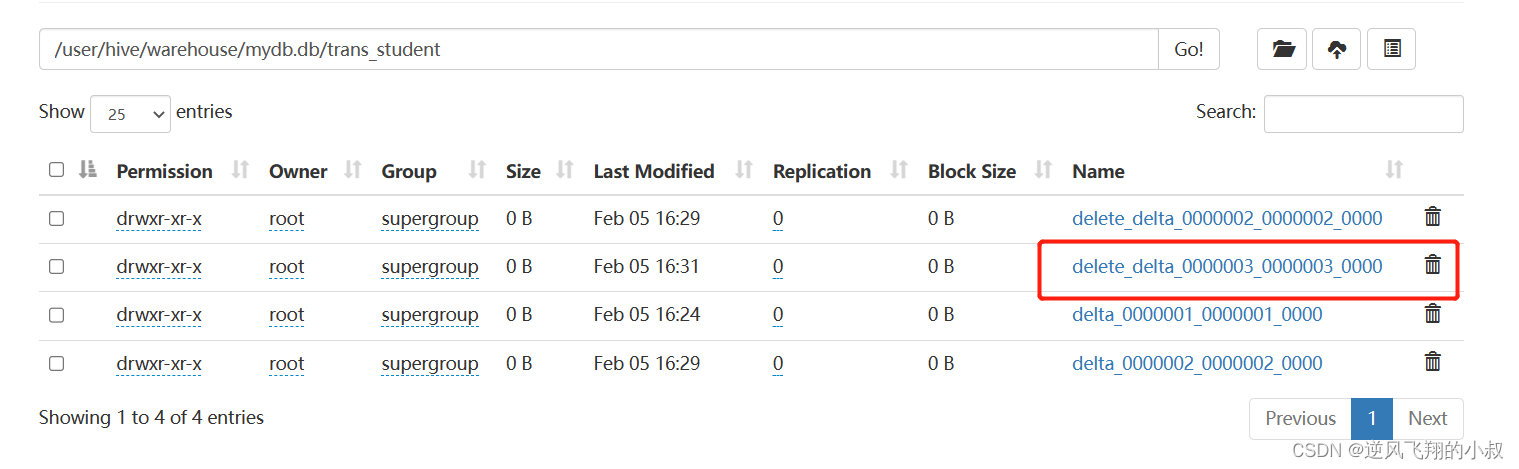
刪除數據
delete from trans_student where id =1;

執行完成后,檢查hdfs目錄又多了一個delete_delta文件;
redis.get報錯com.alibaba.fastjson.JSONException: autoType is not support)



)




)









