【Image captioning】ruotianluo/self-critical.pytorch之1—數據集的加載與使用
作者:安靜到無聲 個人主頁
數據加載程序示意圖
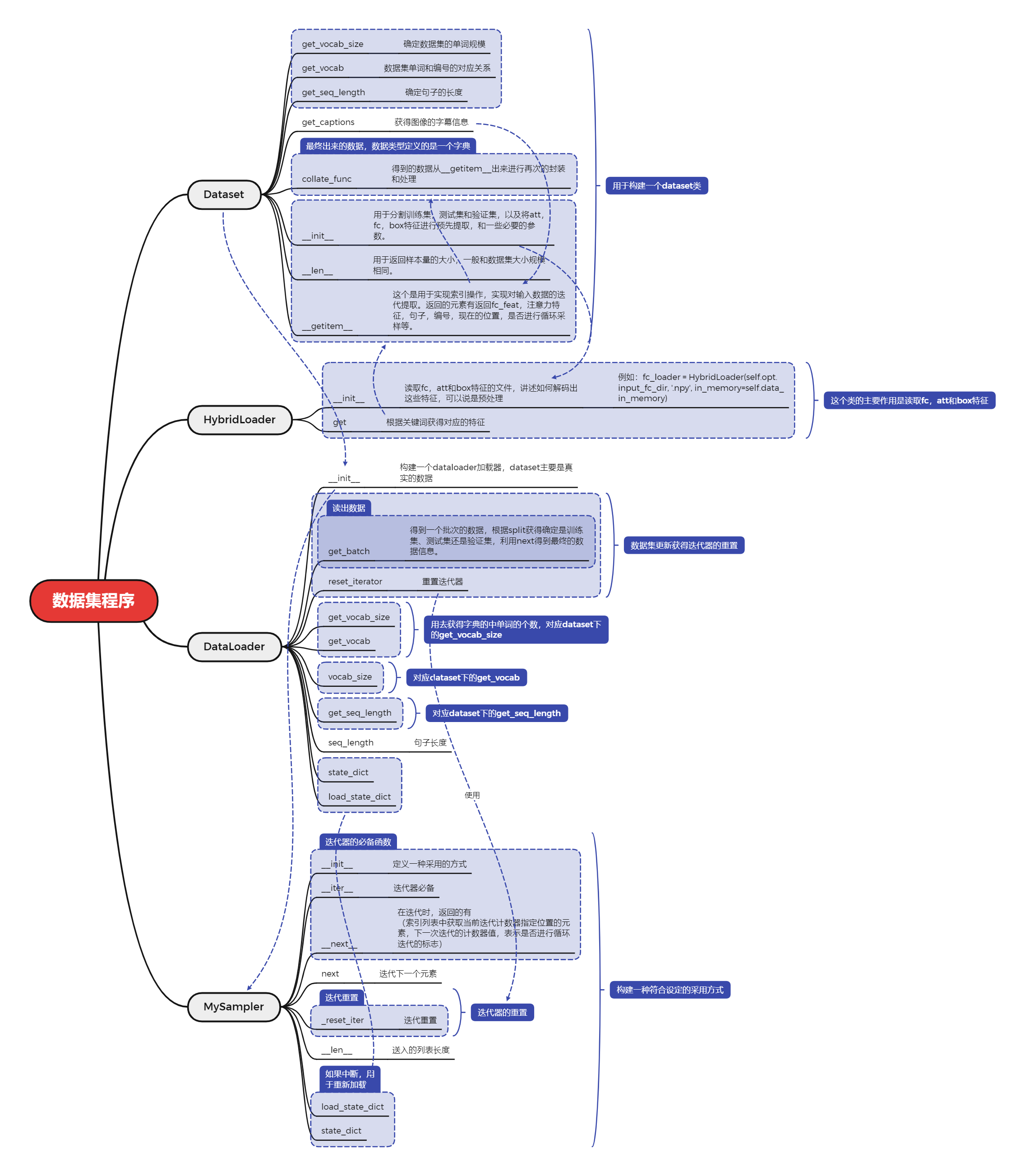
使用方法
示例代碼
#%%from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriterimport numpy as npimport time
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' ##from six.moves import cPickle
import traceback
from collections import defaultdictimport captioning.utils.opts as opts
import captioning.models as models
from captioning.data.dataloader import *
import skimage.io
import captioning.utils.eval_utils as eval_utils
import captioning.utils.misc as utils
from captioning.utils.rewards import init_scorer, get_self_critical_reward
from captioning.modules.loss_wrapper import LossWrapperimport sys
sys.path.append("..")
import time
#%%opt = opts.parse_opt()
opt.input_json = '/home/lihuanyu/code/07ImageCaptioning/data/cocotalk.json'
opt.input_label_h5 = '/home/lihuanyu/code/07ImageCaptioning/data/cocotalk_label.h5'
opt.input_fc_dir = '/home/lihuanyu/code/07ImageCaptioning/data/cocotalk_fc'
opt.input_att_dir = '/home/lihuanyu/code/07ImageCaptioning/data/cocotalk_att'
opt.batch_size = 1
opt.train_only = 1opt.use_att = True
opt.use_att = True
opt.use_box = 0#%%
print(opt.input_json)
print(opt.batch_size) #批量化為16
loader = DataLoader(opt) # 數據加載
#打印字內容
#print(loader.get_vocab()) #返回字典
for i in range(2):data = loader.get_batch('train')print('———————————————————※輸入的信息特征※——————————————————') #[1,2048] 全連接特征print('全連接特征【fc_feats】的形狀:', data['fc_feats'].shape) #[1,2048] 全連接特征print('全連接特征【att_feats】的形狀:', data['att_feats'].shape) #[1,2048] 注意力特征print('att_masks', data['att_masks'])print('含有的信息infos:', data['infos']) #infos [{'ix': 117986, 'id': 495956, 'file_path': 'train2014/COCO_train2014_000000495956.jpg'}]print('———————————————————※標簽信息※——————————————————') #[1,2048] 全連接特征print('labels', data['labels']) #添加了一些0print('gts:', data['gts']) #沒有添加的原始句子print('masks', data['masks'])print('———————————————————※記錄遍歷的位置※——————————————————') #[1,2048] 全連接特征print('bounds', data['bounds'])time.sleep(1)print(data.keys())
輸出結果:
Hugginface transformers not installed; please visit https://github.com/huggingface/transformers
meshed-memory-transformer not installed; please run `pip install git+https://github.com/ruotianluo/meshed-memory-transformer.git`
Warning: coco-caption not available
cider or coco-caption missing
/home/lihuanyu/code/07ImageCaptioning/data/cocotalk.json
1
是否使用【注意力特征[use_fc]】: True
是否使用【注意力特征[use_att]】: True
是否在注意力特征中使用【檢測框特征[use_box]】: 0
DataLoader loading json file: /home/lihuanyu/code/07ImageCaptioning/data/cocotalk.json
vocab size is 9487
DataLoader loading h5 file: /home/lihuanyu/code/07ImageCaptioning/data/cocotalk_fc /home/lihuanyu/code/07ImageCaptioning/data/cocotalk_att data/cocotalk_box /home/lihuanyu/code/07ImageCaptioning/data/cocotalk_label.h5
max sequence length in data is 16
read 123287 image features
assigned 82783 images to split train(訓練集有多少圖片)
assigned 5000 images to split val(驗證集有多少圖片)
assigned 5000 images to split test(測試集有多少圖片)
———————————————————※輸入的信息特征※——————————————————
全連接特征【fc_feats】的形狀: torch.Size([1, 2048])
全連接特征【att_feats】的形狀: torch.Size([1, 196, 2048])
att_masks None
含有的信息infos: [{'ix': 60494, 'id': 46065, 'file_path': 'train2014/COCO_train2014_000000046065.jpg'}]
———————————————————※標簽信息※——————————————————
labels tensor([[[ 0, 1, 271, 17, 7068, 35, 98, 6, 1, 102, 3,912, 0, 0, 0, 0, 0, 0],[ 0, 995, 2309, 2308, 609, 6, 1, 271, 119, 912, 0,0, 0, 0, 0, 0, 0, 0],[ 0, 2309, 9487, 179, 98, 6, 1, 46, 271, 0, 0,0, 0, 0, 0, 0, 0, 0],[ 0, 182, 35, 995, 7068, 6, 1, 271, 3, 60, 678,32, 14, 29, 0, 0, 0, 0],[ 0, 995, 915, 17, 2309, 3130, 6, 1, 46, 271, 0,0, 0, 0, 0, 0, 0, 0]]])
gts: [array([[ 1, 271, 17, 7068, 35, 98, 6, 1, 102, 3, 912,0, 0, 0, 0, 0],[ 995, 2309, 2308, 609, 6, 1, 271, 119, 912, 0, 0,0, 0, 0, 0, 0],[2309, 9487, 179, 98, 6, 1, 46, 271, 0, 0, 0,0, 0, 0, 0, 0],[ 182, 35, 995, 7068, 6, 1, 271, 3, 60, 678, 32,14, 29, 0, 0, 0],[ 995, 915, 17, 2309, 3130, 6, 1, 46, 271, 0, 0,0, 0, 0, 0, 0]], dtype=uint32)]
masks tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,0.]]])
———————————————————※記錄遍歷的位置※——————————————————
bounds {'it_pos_now': 1, 'it_max': 82783, 'wrapped': False}
dict_keys(['fc_feats', 'att_feats', 'att_masks', 'labels', 'masks', 'gts', 'bounds', 'infos'])
———————————————————※輸入的信息特征※——————————————————
全連接特征【fc_feats】的形狀: torch.Size([1, 2048])
全連接特征【att_feats】的形狀: torch.Size([1, 196, 2048])
att_masks None
含有的信息infos: [{'ix': 106440, 'id': 151264, 'file_path': 'train2014/COCO_train2014_000000151264.jpg'}]
———————————————————※標簽信息※——————————————————
labels tensor([[[ 0, 1, 230, 6, 14, 230, 237, 32, 1086, 627, 0,0, 0, 0, 0, 0, 0, 0],[ 0, 1, 6035, 230, 35, 274, 127, 225, 1598, 335, 1,940, 0, 0, 0, 0, 0, 0],[ 0, 1, 230, 35, 900, 32, 307, 756, 61, 607, 0,0, 0, 0, 0, 0, 0, 0],[ 0, 1, 230, 35, 98, 79, 1, 230, 224, 0, 0,0, 0, 0, 0, 0, 0, 0],[ 0, 1, 46, 1109, 230, 1596, 245, 1, 224, 0, 0,0, 0, 0, 0, 0, 0, 0]]])
gts: [array([[ 1, 230, 6, 14, 230, 237, 32, 1086, 627, 0, 0,0, 0, 0, 0, 0],[ 1, 6035, 230, 35, 274, 127, 225, 1598, 335, 1, 940,0, 0, 0, 0, 0],[ 1, 230, 35, 900, 32, 307, 756, 61, 607, 0, 0,0, 0, 0, 0, 0],[ 1, 230, 35, 98, 79, 1, 230, 224, 0, 0, 0,0, 0, 0, 0, 0],[ 1, 46, 1109, 230, 1596, 245, 1, 224, 0, 0, 0,0, 0, 0, 0, 0]], dtype=uint32)]
masks tensor([[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0.]]])
———————————————————※記錄遍歷的位置※——————————————————
bounds {'it_pos_now': 2, 'it_max': 82783, 'wrapped': False}
dict_keys(['fc_feats', 'att_feats', 'att_masks', 'labels', 'masks', 'gts', 'bounds', 'infos'])
推薦專欄
🔥 手把手實現Image captioning
💯CNN模型壓縮
💖模式識別與人工智能(程序與算法)
🔥FPGA—Verilog與Hls學習與實踐
💯基于Pytorch的自然語言處理入門與實踐


的設計與開發)


的嶄新前景)














C++實現)