目錄
- 一、數據重塑
- 1.1 透視
- 1.2 透視表
- 1.3 堆棧/反堆棧
- 1.3 融合
- 二、迭代
- 三、高級索引
- 3.1 基礎選擇
- 3.2 通過isin選擇
- 3.3 通過Where選擇
- 3.4 通過Query選擇
- 3.5 設置/取消索引
- 3.6 重置索引
- 3.6.1 前向填充
- 3.6.2 后向填充
- 3.7 多重索引
- 四、重復數據
- 五、數據分組
- 5.1 聚合
- 5.2 轉換
- 六、缺失值
- 七、合并數據
- 7.1 合并-Merge
- 7.2 連接-Join
- 7.3 拼接-Concatenate
- 7.3.1 縱向拼接
- 7.3.2 橫向/縱向拼接
- 八、日期
- 九、可視化
pandas 是一個功能強大的 Python 數據分析庫,為數據處理和分析提供了高效且靈活的工具。它是在 NumPy 的基礎上構建的,為處理結構化數據(如表格數據)和時間序列數據提供了豐富的數據結構和數據操作方法。
pandas 提供了兩種主要的數據結構:Series 和 DataFrame。Series 是一維標記型數組,類似于帶標簽的列表,可以存儲不同類型的數據。DataFrame 是二維的表格型數據結構,類似于關系型數據庫中的表格,它由多個 Series 組成,每個 Series 都有一個共同的索引。這使得 pandas 在處理和分析數據時非常方便和高效。
使用 pandas,我們就可以輕松地進行數據導入、數據清洗、數據轉換、數據篩選和數據分析等操作。它提供了豐富的函數和方法,如索引、切片、聚合、合并、排序、統計和繪圖等,使得數據分析變得簡單而直觀。
一、數據重塑
1.1 透視
??假設我們有一個 DataFrame df2,其中包含了 'Date’、‘Type’ 和 ‘Value’ 這三列數據。想要將 ‘Type’ 列的唯一值作為新 DataFrame 的列,‘Date’ 列作為新 DataFrame 的索引,并將 ‘Value’ 列中對應的值填充到新 DataFrame 的相應位置上。
??即 將行變為列 ,我們可以這么實現代碼:
>>> df3= df2.pivot(index='Date',columns='Type', values='Value')
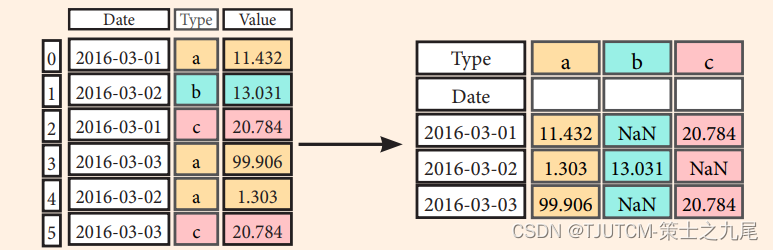
??下面來對pivot() 函數的參數做一下說明:
??index:指定作為新 DataFrame 索引的列名,這里是 ‘Date’ 列。
??columns:指定作為新 DataFrame 列的列名,這里是 ‘Type’ 列的唯一值。
??values:指定填充到新 DataFrame 中的值的列名,這里是 ‘Value’ 列。
1.2 透視表
??使用了 pd.pivot_table() 函數來 創建一個透視表。pivot_table() 函數可以幫助我們在 pandas 中進行數據透視操作,并實現將一個 DataFrame 中的值按照指定的行和列進行聚合。
??即 將行變為列,我們可以這么實現:
>>> df4 = pd.pivot_table(df2,values='Value',index='Date',columns='Type'])
??下面來解釋一下里面出現的各參數的含義:
??其中,‘df2’ 是原始的 DataFrame,‘Value’ 是要聚合的數值列名,‘Date’ 是新 DataFrame 的索引列名,而 ‘Type’ 是新 DataFrame 的列名。
??pd.pivot_table() 函數會將 df2 中的數據按照 ‘Date’ 和 ‘Type’ 進行分組,并計算每個組中 ‘Value’ 列的聚合值(默認為均值)。然后,將聚合后的結果填充到新的 DataFrame df4 中,其中 每一行表示一個日期,每一列表示一個類型 。
??如果在透視表操作中存在重復的索引/列組合,pivot_table() 函數將會使用默認的聚合方法(均值)進行合并。如果我們想要使用其他聚合函數,可以通過傳遞 aggfunc 參數來進行設置,例如 aggfunc=‘sum’ 表示求和。
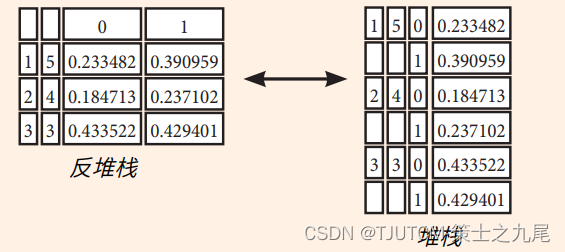
1.3 堆棧/反堆棧
??stack() 和 unstack() 是 pandas 中用于處理層次化索引的函數,可以在 多級索引的 DataFrame 中透視行和列標簽。
>>> stacked = df5.stack()
# 透視列標簽
# 使用 stack() 函數將列標簽透視,即將列標簽轉換為行索引,并將相應的數據堆疊起來。這樣可以創建一個具有多級索引的 Series
>>> stacked.unstack()
# 透視索引標簽
# 上述代碼則使用 unstack() 函數將索引標簽透視,即將行索引轉換為列標簽,并將相應的數據重新排列。這樣可以還原出原始的 DataFrame 結構
1.3 融合
??我們需要 將指定的列轉換為一個觀察值列時,可以使用 pd.melt() 函數來將一個 DataFrame 進行融合操作(melt)。
??將列轉為行:
>>> pd.melt(df2,id_vars=["Date"],value_vars=["Type","Value"],value_name="Observations")

??其中,df2 是原始的 DataFrame,id_vars=[“Date”] 表示保持 ‘Date’ 列不融合,作為 標識變量(也就是保持不動的列)。value_vars=[“Type”, “Value”] 指定要融合的列為 ‘Type’ 和 ‘Value’。value_name=“Observations” 表示新生成的觀察值列的名稱為 ‘Observations’。
??pd.melt() 函數會將指定的列進行融合操作,并創建一個新的 DataFrame。融合后的 DataFrame 中會包含四列,分別是融合后的標識變量(‘Date’)、融合的列名(‘variable’)、融合的值(‘Observations’)以及原始 DataFrame 中對應的觀察值。
二、迭代
??df.iteritems()是一個 DataFrame 的迭代器方法,用于按列迭代 DataFrame。它返回一個生成器,每次迭代生成一個包含列索引和對應列的序列的鍵值對。
??df.iterrows() 也是一個 DataFrame 的迭代器方法,用于按行迭代 DataFrame。它返回一個生成器,每次迭代生成一個包含行索引和對應行的序列的鍵值對。
>>> df.iteritems()
# (列索引,序列)鍵值對
>>> df.iterrows()
# (行索引,序列)鍵值對
??下面是一些基本操作:
for column_index, column in df.iteritems():# 對每一列進行操作print(column_index) # 打印列索引print(column) # 打印列的序列for index, row in df.iterrows():# 對每一行進行操作print(index) # 打印行索引print(row) # 打印行的序列
三、高級索引
3.1 基礎選擇
??DataFrame 中基于條件選擇列的操作如下,都是一些基本的操作:
>>> df3.loc[:,(df3>1).any()]
# 選擇任一值大于1的列
>>> df3.loc[:,(df3>1).all()]
# 選擇所有值大于1的列
>>> df3.loc[:,df3.isnull().any()]
# 選擇含 NaN值的列
>>> df3.loc[:,df3.notnull().all()]
# 選擇含 NaN值的列
3.2 通過isin選擇
??而在很多情況下,我們所需要做的不是僅僅通過基于條件選擇列這么簡單的操作,所以還有必要學習 DataFrame 的進一步選擇和篩選操作。
>>> df[(df.Country.isin(df2.Type))]
# 選擇為某一類型的數值
>>> df3.filter(items=”a”,”b”])
# 選擇特定值
>>> df.select(lambda x: not x%5)
# 選擇指定元素
3.3 通過Where選擇
??where()是Pandas Series對象中的一個方法,也可以用于選擇滿足條件的子集。
>>> s.where(s > 0)
# 選擇子集
3.4 通過Query選擇
>>> df6.query('second > first')
# 查詢DataFrame
??df6.query(‘second > first’) 是 DataFrame 對象中的一個查詢操作,查詢 DataFrame df6 中滿足條件 “second > first” 的行。其中,“second” 和 “first” 是列名,表示要比較的兩個列。只有滿足條件的行會被選中并返回為一個新的 DataFrame。
3.5 設置/取消索引
>>> df.set_index('Country')
# 設置索引
>>> df4 = df.reset_index()
# 取消索引
>>> df = df.rename(index=str,columns={"Country":"cntry","Capital":"cptl","Population":"ppltn"})
# 重命名DataFrame列名
3.6 重置索引
??有時候我們需要重新索引 Series。
??將 Series s 的索引重新排列為 [‘a’, ‘c’, ‘d’, ‘e’, ‘b’],并返回一個新的 Series。如果 原來的索引中不存在某個新索引值,對應的值將被設置為 NaN(缺失值)。
>>> s2 = s.reindex(['a','c','d','e','b'])
3.6.1 前向填充
>>> df.reindex(range(4), method='ffill')Country Capital Population0 Belgium Brussels 111908461 India New Delhi 13031710352 Brazil Brasília 2078475283 Brazil Brasília 207847528
3.6.2 后向填充
>>> s3 = s.reindex(range(5), method='bfill')0 3 1 32 33 34 3
3.7 多重索引
>>> arrays = [np.array([1,2,3]),
np.array([5,4,3])]
>>> df5 = pd.DataFrame(np.random.rand(3, 2), index=arrays)
>>> tuples = list(zip(*arrays))
>>> index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
>>> df6 = pd.DataFrame(np.random.rand(3, 2), index=index)
>>> df2.set_index(["Date", "Type"])
四、重復數據
>>> s3.unique()
# 返回唯一值
>>> df2.duplicated('Type')
# 查找重復值
>>> df2.drop_duplicates('Type', keep='last')
# 去除重復值
>>> df.index.duplicated()
# 查找重復索引
五、數據分組
5.1 聚合
>>> df2.groupby(by=['Date','Type']).mean()
>>> df4.groupby(level=0).sum()
>>> df4.groupby(level=0).agg({'a':lambda x:sum(x)/len(x),
'b': np.sum})
5.2 轉換
>>> customSum = lambda x: (x+x%2)
>>> df4.groupby(level=0).transform(customSum)
六、缺失值
>>> df.dropna()
# 去除缺失值NaN
>>> df3.fillna(df3.mean())
# 用預設值填充缺失值NaN
>>> df2.replace("a", "f")
# 用一個值替換另一個值
七、合并數據

7.1 合并-Merge
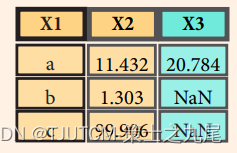
>>> pd.merge(data1, data2, how='left', on='X1')
??將 data1 和 data2 兩個 DataFrame 按照它們的 ‘X1’ 列進行左連接,并返回一個新的 DataFrame。左連接保留 data1 的所有行,并將 data2 中符合條件的行合并到 data1 中。如果 data2 中沒有與 data1 匹配的行,則對應的列值將被設置為 NaN(缺失值)。
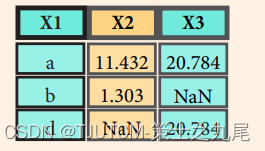
>>> pd.merge(data1, data2, how='right', on='X1')
??右連接也是一種連接方式,其將 data1 和 data2 兩個 DataFrame 按照它們的 ‘X1’ 列進行右連接,并返回一個新的 DataFrame。保留 data2 的所有行,并將 data1 中符合條件的行合并到 data2 中。如果 data1 中沒有與 data2 匹配的行,則對應的列值將被設置為 NaN(缺失值)。

>>> pd.merge(data1, data2,how='inner',on='X1')
??將 data1 和 data2 兩個 DataFrame 按照它們的 ‘X1’ 列進行內連接,并返回一個新的 DataFrame就是所謂的內連接(inner join)。它 僅保留 data1 和 data2 中在 ‘X1’ 列上有匹配的行,并將它們合并到一起。
??參數中的 how=‘inner’ 表示使用內連接方式進行合并。其他可能的取值還有 ‘left’、‘right’ 和 ‘outer’,分別表示左連接、右連接和接下來要介紹的外連接。on=‘X1’ 表示使用 ‘X1’ 列作為合并鍵(即共同的列)。
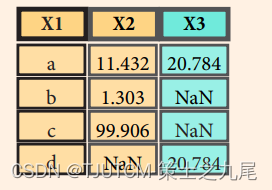
>>> pd.merge(data1, data2, how='outer',on='X1')
??將 data1 和 data2 兩個 DataFrame 按照它們的 ‘X1’ 列進行外連接,并返回一個新的 DataFrame。外連接(outer join)是一種合并方式,它會保留 data1 和 data2 中所有的行,并將它們根據 ‘X1’ 列的值進行合并。
??在外連接中,如果某個 DataFrame 中的行在另一個 DataFrame 中找不到匹配,那么對應的列值將被設置為 NaN(缺失值),表示缺失的數據。
7.2 連接-Join
>>> data1.join(data2, how='right')
7.3 拼接-Concatenate
7.3.1 縱向拼接
>>> s.append(s2)
7.3.2 橫向/縱向拼接
>>> pd.concat([s,s2],axis=1, keys=['One','Two'])
>>> pd.concat([data1, data2], axis=1, join='inner')
八、日期
>>> df2['Date']= pd.to_datetime(df2['Date'])
>>> df2['Date']= pd.date_range('2000-1-1', periods=6, freq='M')
>>> dates = [datetime(2012,5,1), datetime(2012,5,2)]
>>> index = pd.DatetimeIndex(dates)
>>> index = pd.date_range(datetime(2012,2,1), end, freq='BM')
九、可視化
Matplotlib 是一個用于繪制數據可視化圖形的 Python 庫。它提供了各種函數和工具,用于創建各種類型的圖表,包括線圖、散點圖、柱狀圖、餅圖等等。
??現在我們導入 Matplotlib 庫,并將其重命名為了 plt。這樣,我們就可以 使用 plt 對象來調用 Matplotlib 的函數和方法,以便創建和修改圖形了。
>>> import matplotlib.pyplot as plt
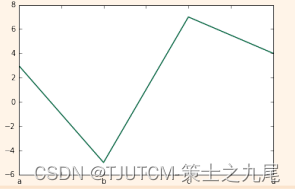
??現在,我們試試導入 Matplotlib 庫使用 Pandas 庫中 Series 對象的 .plot() 方法 和 Matplotlib 庫中的 plt.show() 函數 來生成并顯示數據的默認圖形。
>>> s.plot()
>>> plt.show()
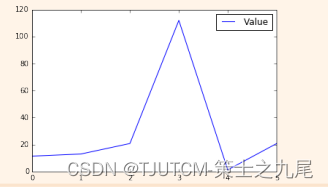
我們也可使用 Pandas 庫中 DataFrame 對象的 .plot() 方法 和 Matplotlib 庫 中的 plt.show() 函數 來生成并顯示數據的默認圖形。
>>> df2.plot()
>>> plt.show()


)
)

)













