數組交集
- 349. 兩個數組的交集
- 排序+雙指針
- 數組實現哈希表
- unordered_set
- unordered_map
- 350. 兩個數組的交集Ⅱ
- 排序 + 雙指針
- 數組實現哈希表
- unordered_map
349. 兩個數組的交集
題目鏈接:349. 兩個數組的交集
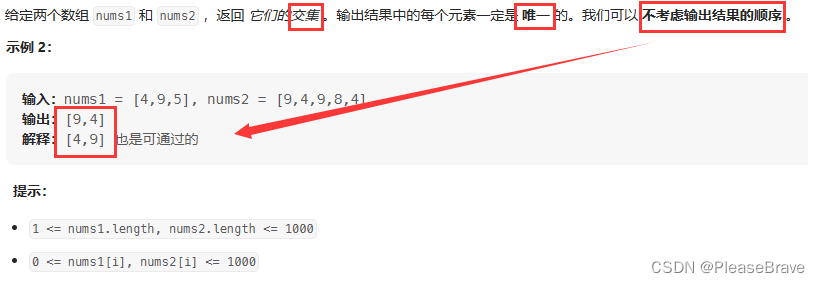
題目內容如下,理解題意:①交集中每個元素是唯一的,只能出現一次,所以本題要找的是同時出現在數組nums1和nums2中的元素,但是并不關心他們出現的次數;②輸出結果的順序不用考慮,也就是只要找到了同時出現在nums1和nums2中的元素就行,可以給數組排序(打亂了原本的順序)再去查找、可以用map、set(其中key是無序的)……
這個題目暴力求解是可以的,暴力求解兩層循環,將nums1和nums2的元素逐個對比,時間復雜度是O(m*n),因為nums1和nums2的長度都<=1000,所以最終也是能夠運行的。
考慮更優的解法,直接一遍遍歷nums1和nums2就好了。以下詳述各解法:
排序+雙指針
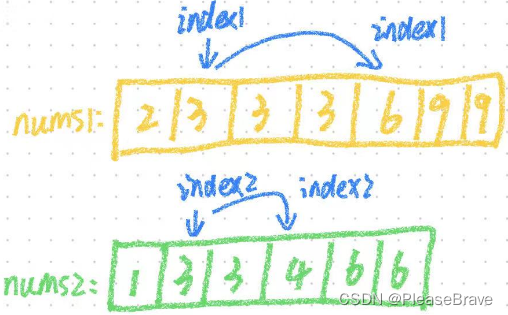
解法Ⅰ,對nums1和nums2排序后,從頭開始遍歷兩個數組(下標用index1和index2),并將nums1[index1] = nums2[index2]的元素加入結果數組中。
存在的問題是:因為nums1和nums2中存在重復元素,如果找到了nums1[index1] = nums2[index2],且在nums1中,nums1[index1] 有重復,即nums1[index1+1] = nums1[index1] ,且在nums2中,nums2[index2]有重復,即nums2[index2+1] = nums2[index2]。那么直接對index++和index2++,會向結果數組中添加重復的元素。
解決:找到nums1[index1] = nums2[index2]后,index1++直到找到與之不同的下一個元素(就是跳過中間的相同的元素);index2++同樣。
代碼實現(C++):
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {vector<int> ans;sort(nums1.begin(),nums1.end());//先給nums1和nums2都排序sort(nums2.begin(),nums2.end());//排序后雙指針(index1和index2遍歷nums1和nums2for(int index1 = 0, index2 = 0; index1 < nums1.size() && index2 < nums2.size();){if(nums1[index1] == nums2[index2]){ans.emplace_back(nums1[index1]); //如果找到在兩個數組中出現的元素,加入到結果數組中//之后直接跳過和當前元素相同的一截,避免有可能向ans中重復添加該元素的可能do{index1++;}while(index1 < nums1.size() && nums1[index1] == nums1[index1 - 1]);do{index2++;}while(index2 < nums2.size() && nums2[index2] == nums2[index2 - 1]);}//如果不相等,更小的那個數向后移,同樣是跳過和當前元素相同的一截,避免重復的比較else if( nums1[index1] < nums2[index2]){do{index1++;}while(index1 < nums1.size() && nums1[index1] == nums1[index1 - 1]); }else{do{index2++;}while(index2 < nums2.size() && nums2[index2] == nums2[index2 -1]); }}return ans;}
};
數組實現哈希表
哈希表的好處體現在,它能夠快速查找一個元素是否存在,時間復雜度是O(1)。我們要找nums1和nums2中同時存在的元素,換句話——查找nums1中某個元素是否出現在了nums2中。那么就可以用哈希表。因為題目中,nums1和num2的長度以及其中的int元素的大小都給了限制(<=1000),那么可以用數組來實現哈希表。
直接定義長度為1001的int數組count_1和count_2,統計nums1中元素的次數和nums2中元素出現的次數,最后對比count_1和count_2的每位元素,如果同時不為0的話,將對應元素加入到ans中。
代碼如下(C++):
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {int count_1[1001] = {0}, count_2[1001] = {0};vector<int> ans;//分別統計nums1和nums2中元素出現情況for ( auto& num : nums1){count_1[num]=1;}for ( auto& num : nums2){ count_2[num]++;}for ( int i = 0; i <= 1000; i++){//在兩個數組中出現次數均>=1時,加入ans中if( count_1[i] && count_2[i])ans.emplace_back(i);}return ans;}
};
優化:上面需要用到兩個數組count_1和count_2來分別統計nums1、nums2中元素出現的情況,之后還要遍歷這倆數組。是否有可能只使用一個count數組,用兩次?——遍歷nums1的時候,出現的元素不統計次數,而是count[nums[i]]=1,標記該元素出現過;遍歷nums2的時候,如果count[nums2[j]] !=0就表示在兩個數組中同時存在;防止重復添加,再將count[nums2[j]]=0;
代碼實現(C++):
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {int count[1001] = {0};vector<int> ans;//統計nums1中元素的出現情況for ( auto& num : nums1){count[num]=1;}//遍歷nums2for ( auto& num : nums2){if(count[num]){ //同時判斷nums2中的元素在nums1中是否出現count[num]=0;ans.emplace_back(num);}} return ans;}
};
unordered_set
題意是要找交集,那么直接把數組變成集合,然后求兩個集合交集就好。實現上,將vector變成unordered_set,然后對比兩個unordered_set的key,找到重疊部分。
代碼實現(C++):
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//把vector轉化成unordered_setunordered_set<int> num_set1(nums1.begin(),nums1.end());unordered_set<int> num_set2(nums2.begin(),nums2.end());vector<int> ans;//遍歷兩個set,找交集;遍歷size小的if( num_set1.size() < num_set2.size()){for( auto& key : num_set1)if(num_set2.count(key))ans.emplace_back(key);}else{for( auto& key :num_set2)if(num_set1.count(key))ans.emplace_back(key);}return ans;}
};
unordered_map
最后也能用map來實現,遍歷nums1和nums2的同時,統計其中元素出現的次數,用unordered_map來存,key是數組中出現的元素,value是元素出現的次數; 之后找到兩個map中重合的key。
代碼(C++):
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_map<int,int> count_1, count_2; vector<int> ans;//用map統計數組中出現的元素及其次數for ( auto& num : nums1){count_1[num]++;}for ( auto& num : nums2){count_2[num]++;}if(count_1.size() < count_2.size()){for ( auto key_value : count_1)if(count_2.count(key_value.first))ans.emplace_back(key_value.first);}else{for ( auto key_value : count_2)if(count_1.count(key_value.first))ans.emplace_back(key_value.first);}return ans;}
};
350. 兩個數組的交集Ⅱ
題目鏈接:350. 兩個數組的交集Ⅱ
題目內容: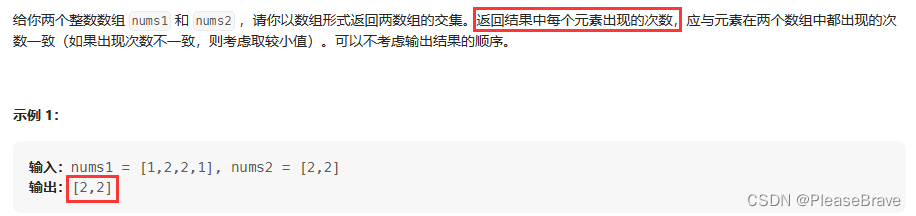
這道題和上一題唯一不同的點在于:在nums1和nums2中同時出現的元素,如果出現次數不止一次,都需要加入到結果中。即不僅要統計同時出現在nums1和nums2中的元素,還要統計他們各自出現的次數(C1和C2),并在結果數組ans中重復min (C1, C2) 次。以下代碼均在上一題基礎上做一點改動即可。
排序 + 雙指針
排序后數組元素逐個對比就好:雙指針index1和index2,每次對比nums1[index1]和nums2[index2]的關系后,直接index1++,index2++:
class Solution {
public:vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {vector<int> ans;sort(nums1.begin(),nums1.end());sort(nums2.begin(),nums2.end());for(int index1 = 0, index2 = 0; index1 < nums1.size() && index2 < nums2.size();){if(nums1[index1] == nums2[index2]){ans.emplace_back(nums1[index1]);//下標直接向后移動,這樣同時重復出現在兩個數組中的元素能夠重復添加index1++;index2++; }else if( nums1[index1] < nums2[index2]){index1++; }else{index2++; }}return ans;}
};數組實現哈希表
先用數組count統計nums1中出現的元素,及其次數;再遍歷nums2,同時出現在nums1中的元素,count[nums2[i]]- -,向結果數組ans中添加一次該元素。
class Solution {
public:vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {int count[1001] = {0};vector<int> ans;//統計出現的元素,以及次數for ( auto& num : nums1){count[num]++;}for ( auto& num : nums2){if(count[num]){//對于同時出現的元素,對其次數--,保證后續再出現該元素時,還能重復添加count[num]--;ans.emplace_back(num);} } return ans;}
};
unordered_map
只是將上面的數組換成了unordered_map。用數組實現哈希表適用于nums1和nums2都不大的,并且其中元素也不大的情況,當數組很大并且數組元素為int,大小沒有限制的時候,用map更合適(或者set)。
代碼如下:
class Solution {
public:vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {unordered_map<int,int> count;vector<int> ans;for(auto& num : nums1){count[num]++;}for(auto& num : nums2){if(count.count(num)){ans.emplace_back(num);count[num]--;//如果已經重復添加了min(c1,c2)次了,即便后續再出現也不能再添加了if(count[num]==0)count.erase(num);}}return ans;}
};












)

)



)
