mysql的存儲引擎
三種存儲方式
**InnoDB **(默認)
一個文件存儲表結構,一個存儲數據和目錄(索引)
# 一個文件 book_name | author| press | price | pub_date frm文件 frame的縮寫
# 另一個文件(數據+ 目錄)
# | 倚天屠龍記 | egon | 北京工業地雷出版社 | 70.00 | 2019-07-01 |
# | 九陽神功 | alex | 人民音樂不好聽出版社 | 5.00 | 2018-07-04 |
# | 降龍十巴掌 | egon | 知識產權沒有用出版社 | 20.00 | 2019-07-05 |
# | 葵花寶典 | yuan | 知識產權沒有用出版社 | 33.00 | 2019-08-02 |
# | 彭于晏的枕邊故事 | 彭于晏 | py26期出版社 | 80.00 | 2020-10-30 |
memory
一個文件存儲數據結構,數據存儲在內存(差的快,早期都是這種存儲方式,現在有redis了)
MyIsam
一個文件表結構,一個存儲數據,還有一個放目錄(索引)
# 一個文件 book_name | author| press | price | pub_date frm文件 frame的縮寫
# 另一個文件(數據)
# 另一個文件(目錄)
數據庫中數據的存儲方式
實際的數據庫中數據的存儲方式
平衡樹 balance tree b-tree
b+樹 :能夠更好的降低樹的高度,并且對范圍查詢比較友好
myisam/innodb存儲引擎 : 索引結構都是通過b+樹實現的
每一個字段都可以創建索引
對于一個字段創建的索引在當前字段作為條件的時候可以起到加速作用
索引分兩類 :
# 聚集索引(聚簇索引) :數據和索引存在一顆樹上
# 輔助索引(非聚集索引/非聚簇索引) :數據和索引不存在一顆樹上
你必須要在innodb中的所有表都要主動創建主鍵,主鍵就是最好的索引
myisam和innodb在索引上的不同
# myisam中所有的索引都是輔助索引
# innodb中主鍵是聚集索引,其他都是輔助索引
平衡樹
用到平衡樹的算法,會算取中間范圍,讓樹不會成為歪脖樹。所以每次添加索引需要時間長點,他在構造以索引為主的平衡樹
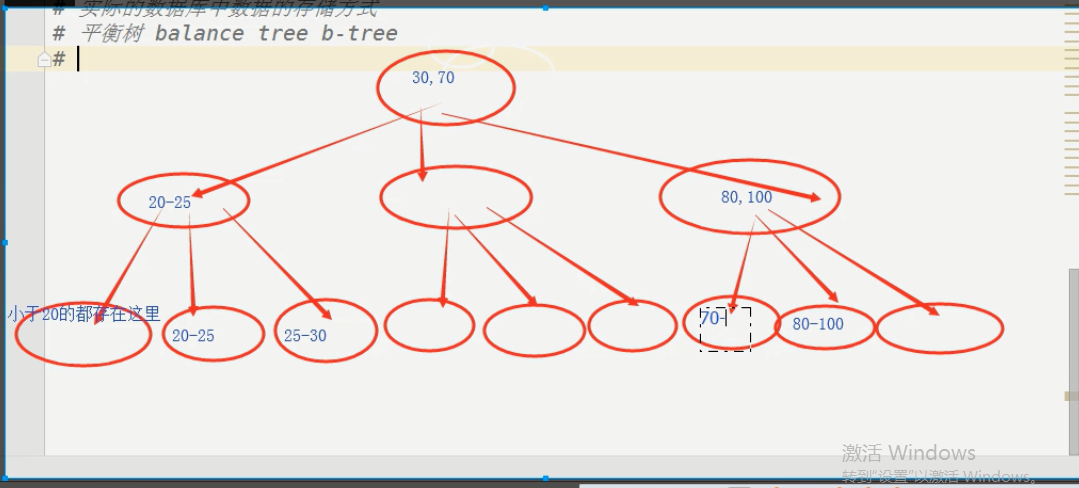
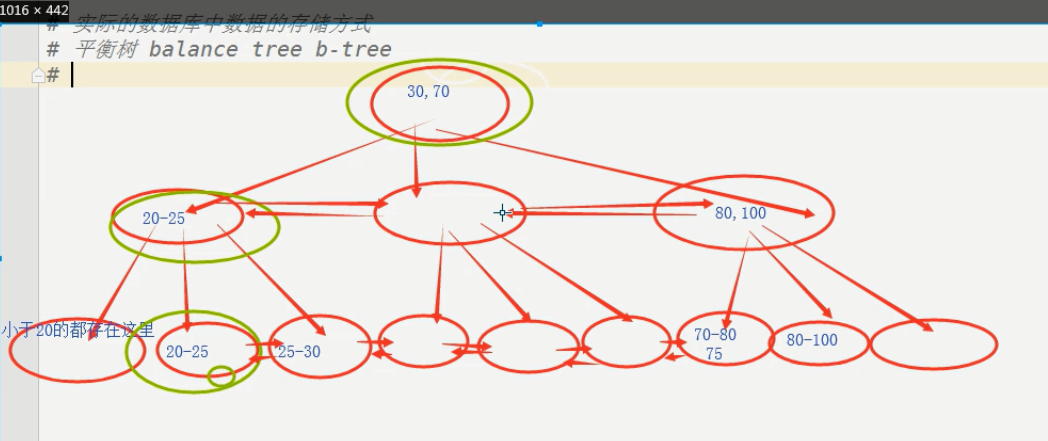
B+樹
B+樹就是平衡樹的升級版,將各個節點也可以鏈式連接起來,這樣查找的時候,(20 between 70)就不用回到起點從新查找。就可以縱向查找了
索引
索引的優點 : 加速查詢效率
索引的缺點 : 拖慢寫的速度,占用更多的硬盤(解決辦法分布式讀寫分離)
# create index 索引名 on 表名(字段名);
# create index ind_id on s1(id);
# drop index 索引名 on 表名;
# drop index ind_id on s1;
# 查看
# show create table s1;
正確的使用索引
這里說一下,mysql只能命中一個索引,當你創建多個索引的時候,他在執行語句時,會先走分析器,分析使用什么索引最快,就是平衡樹結構更健康。如果你想看mysql分析結果。在查詢語句前加上explain
# 1.對哪個字段創建了索引,條件就使用那個字段
# 2.條件列不能參與計算,不能調用函數
# 3.如果列中重復值多,那么不適合創建索引(性別)(1/10)
# 4.盡量不使用范圍查詢,范圍越小效率越高
# 5.使用like 'a%'
# 6.and 相連的多個條件 如果有一個索引都可以被命中
# 7.or 相連的多個條件 必須都有索引才能命中
# 8.聯合索引和最左前綴原則(不能使用范圍,從使用了范圍的那個字段之后的所有條件都無法命中索引,條件之間只能用and不能用or)
# create index mix_ind on s1(id,email,name);
# 可以命中索引
# select * from s1 where id = 2000000 and email='eva2000000@oldboy' and name='eva';
# select * from s1 where id = 2000000 and name='eva';
# select * from s1 where id = 2000000 and email='eva2000000@oldboy';
# select * from s1 where id = 2000000;
# 2000000 eva jingliyang@xxx
# 不能命中索引
# select * from s1 where email='eva2000000@oldboy';
# select * from s1 where name='eva';
# select * from s1 where id = 1000000 and email like 'eva2000000@oldboy';
聯合索引就是用多個字段當索引,以主鍵為第一個(id)開始分大小,id分完按照下一個email開始分,進行排序,形成樹
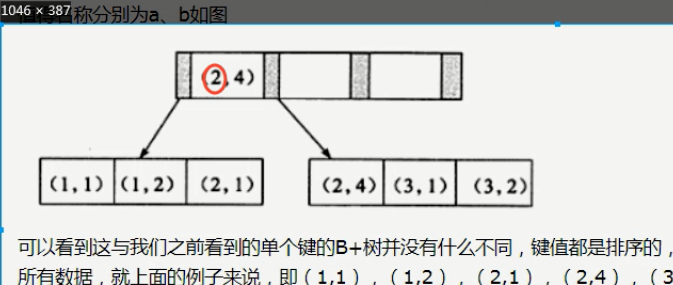
索引合并
意思是:創建的時候是2個單獨的索引,但是在使用的時候臨時合并成一個。
以下是查看mysql分析查看的結果,Mysql把2個獨立的索引合并成了一個使用,為了更快捷的查看以下圖片中的語句。

索引覆蓋
'Using Index'的意思是“覆蓋索引”,它是使上面sql性能提升的關鍵
一個包含查詢所需字段的索引稱為“覆蓋索引”
MySQL只需要通過索引就可以返回查詢所需要的數據,而不必在查到索引之后進行回表操作,減少IO,提高了效率
以下例子

上圖,首先我們要知道。innodb中主鍵是聚集索引,其他都是輔助索引
加入上表不是以id為主鍵的表,所以id是輔助索引,當你查詢的時候,需要通過id找到主鍵,在從聚集索引中查找在輔助索引中找到的主鍵,此時需要回表。
而我查詢的只是索引。不需要回表,因為已經查到了。這就是索引覆蓋
MySQL只需要通過索引就可以返回查詢所需要的數據,而不必在查到索引之后進行回表操作,減少IO,提高了效率













—異常和異常處理)


——自定義循環標簽)


 匿名塊)