# 在對數據進行分析時,主要細分為明確目標、應用思維和如下8個具體步驟:
1、讀取數據
2、清洗數據
3、操作數據
4、轉換數據
5、整理數據
6、分析數據
7、展現數據
8、總結報告
接下來將介紹使用python來具體處理數據,包括上面幾個步驟的實現,以及給出具體的操作例子。
需要記住的是使用python處理數據所用到的 具體函數、方法。
#一、python讀取數據
''''''
1、簡要
2、如何從Excel文件中讀取數據
3、如何從MySQL數據庫中讀取數據
4、如何從網頁中讀取數據
''''''
1、簡要
讀取數據時數據分析的第一步,相對來說比較簡單,讀取數據類型可以大致分為幾類,一般用到的都是從 excel表、數據庫、網頁中進行讀取。
我們使用python中的pandas庫來實現讀取操作。
2、如何從Excel文件中讀取數據
Python代碼如下:
讀取數據之前需要導入pandas庫
#導入pandas庫
import pandas as pd
#導入Excel文件
df = pd.read_excel('文件名.xlsx')
3、如何從MySQL數據庫中讀取數據
讀取數據之前需要安裝pymysql模塊
# 安裝pymysql模塊(在終端操作)
pip install pymysql
#安裝后,讀取操作代碼如下:
import pandas as pd
import pymysql
# 創建數據庫連接
conn = pymysql.connect(host='', user='', passwd='', database='')
# 創建游標
cursor = conn.cursor()
# 寫SQL語句
sql = "select * from 表名"
#讀取數據
df = pd.read_sql(sql,conn)
df.head()
# 關閉游標
cursor.close()
# 關閉連接
conn.close()
4、如何從網頁中讀取數據
訪問網頁時需要用到ssl模塊,解決證書不受信任問題
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 網址
url = 'http://s.askci.com/stock/a/?reportTime=2019-03-31&pageNum=1'
#讀取網頁中表格數據
dfs = pd.read_html(url)
#二、python清洗數據
'''
1、如何查找異常
2、如何排除重復
3、如何刪除缺失
4、如何補全缺失
5、應用案例
'''
下面使用待清洗的撲克牌作為示例,來完成以上操作。
import numpy as np
import andas as pd
pd.set_option('max_rows',10)
df = df.read_excel("待清洗的撲克牌.xlsx")
df
返回結果如下:
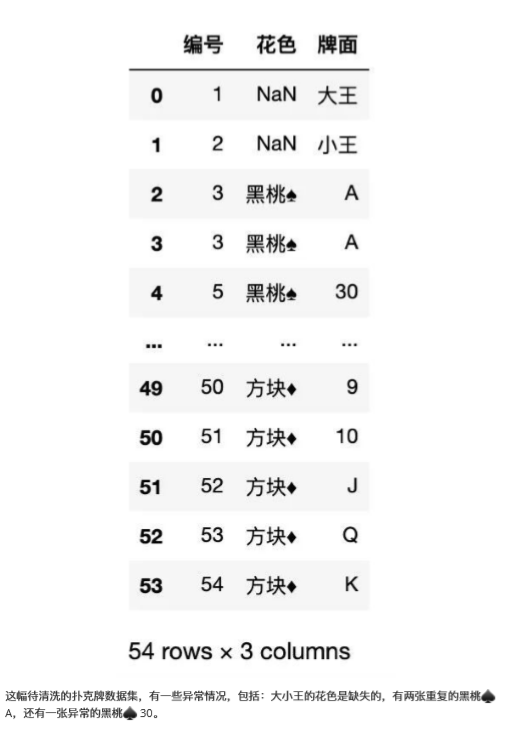
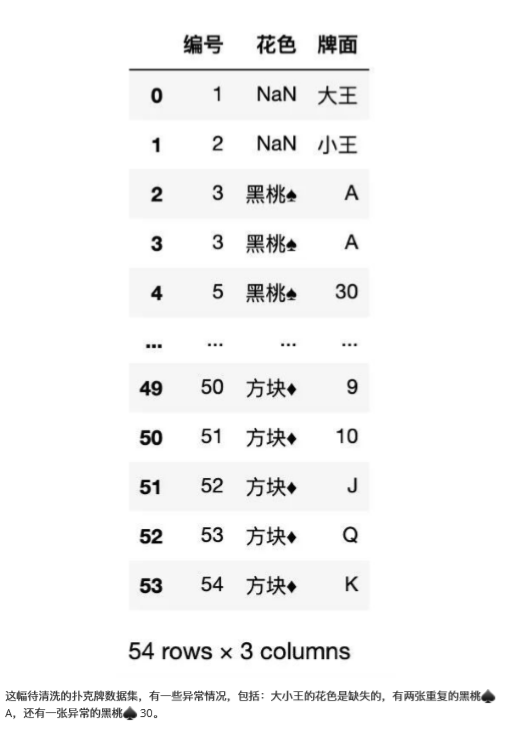
1、如何查找異常
在清洗數據之前需要把異常的數據查找出來,觀察異常數據特征,然后確定清洗方法。
一般查找數據異常方式:
查找某一列缺失
查找重復的行列
查找某一列的唯一值
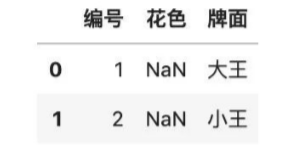
#查找花色缺失的行
df[df.花色.isnull()]
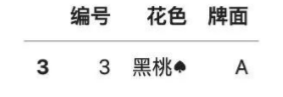
# 查找完全重復的行
df[df.duplicated()]
# 查找某一列重復的行
df[df.編號.duplicated()]

#查找牌面所有唯一值
df.牌面.unique()
返回結果如下:
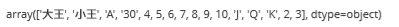
根據常識可以得出,'30'為異常值。
#查找牌面包含30的異常值
df[df.牌面.isin(['30'])]

2、如何排除重復
使用drop_duplicates()函數,在排除重復后會得到新的返回值。
#排除完全重復的行,默認保留第一行
df.drop_duplicates()
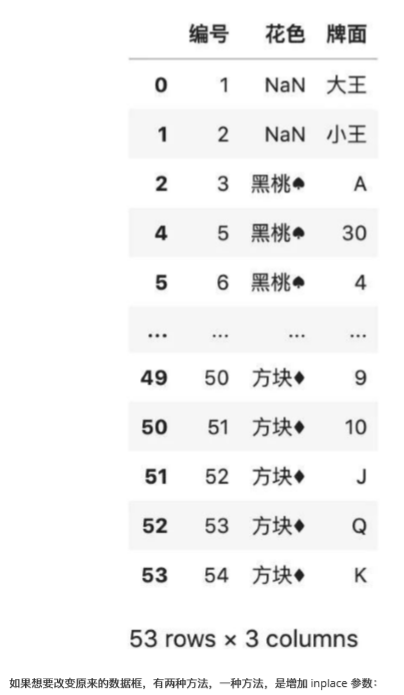
# 按照莫一列排除重復,默認保留第一行
df.drop_duplicates(['花色'])
# 按照莫一列排除重復,默認保留最后一行
df.drop_duplicates(['花色'],keep = 'last')
3、如何刪除缺失
使用dropna()默認刪除包含缺失的行
使用撲克牌中不重復的花色為例
color =??df.drop_duplicates(['花色'])
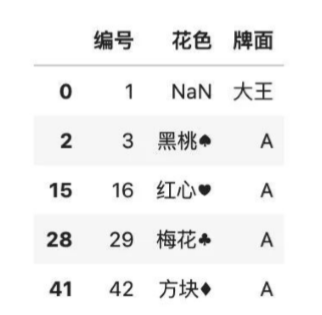
#刪除花色缺失的行
color.dropna()
#刪除整行全部為空的行,需要指定how參數
color.dropna(how='all')
#刪除包含缺失值的列
color.dropna(axis = 1)
4、如何補全缺失
# 使用fillna()函數可以將缺失值填充成制定的值。
color.fillna('joker')
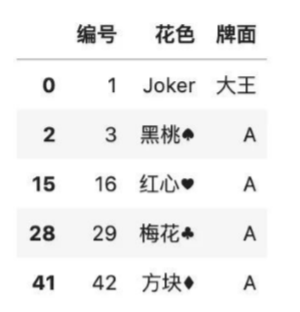
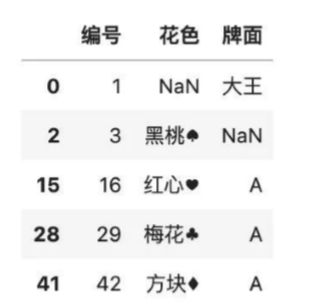
# 使用臨近值填充需要指定method參數
#用后面的值填充
color.fillna(method= 'bfill')
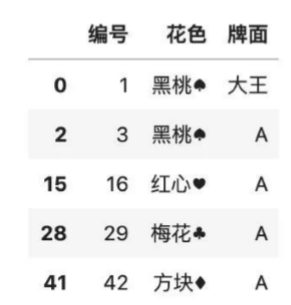
# 按字典填充
# 先制定一個缺失值
color.loc[2,'牌面'] = np.nan
color
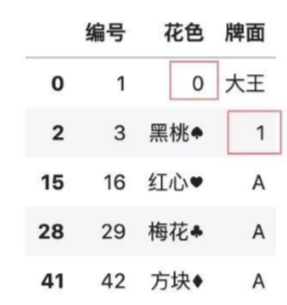
#按列自定義補全缺失值
color.fillna({'花色':0,'牌面':1})
5、應用案例
import numpy as np
import pandas as pd
# 設置最多顯示10行
pd.set_option('max_rows',10)
#從Excel文件中讀取原始數據
df = pd.read_excel('待清洗的撲克牌'.xlsx)
#補全缺失值
df = pd.fillna('joker')
#排除重復值
df = pd.drop_duplicates()
# 修改異常值
df.loc[4,'牌面'] = 3
# 增加一張缺少的牌
df = df.append({'編號':4,'花色':'黑桃?','牌面':2},ignore_index = True)
#按編號排序
df = df.sort_values('編號')
# 重置索引
df = df.reset_index()
# 刪除多余的列
df = df.drop(['index'],axis = 1)
#清洗好的數據保存到excel文件中
df.to_excel('清洗好的撲克牌'.xlsx,index = False)
df
上圖為完整的撲克牌數據。









SVN搭建)
)





和append的區別)

(二)——編寫第一個自定義SRP)
