??回顧使用requests如何實現自動登錄一文中,提到好多網站在我們登錄過后,在之后的某段時間內訪問該網頁時,不會給出請登錄的提示,時間到期后就會提示請登錄!這樣在使用爬蟲訪問網頁時還要登錄,打亂我們的節奏,并詳細介紹了使用requests爬取網頁時為實現自動登錄獲取鍵Cookie對應的值的過程。
??那么selenium如何實現自動登錄呢?又如何獲取鍵Cookie對應的值呢?
??開始之前我們先把項目創建好,如下:文件夾Day19下創建一個files文件夾用于存儲爬取到的Cookie對應的值
一、selenium獲取鍵Cookie對應的值
01_selenium獲取cookie
from selenium.webdriver import Chrome# 1. 創建瀏覽器打開需要自動登錄的網頁
b = Chrome()
url = 'https://www.zhihu.com'
b.get(url)# 2. 留足夠長的時間給人工完成登錄
#(完成登錄的時候必須保證瀏覽器對象指向的窗口能夠看到登錄成功的效果)# 進入網頁后會有登錄提示,手動掃碼登錄成功后,回到pycharm的輸出區輸入任意
# 字符給input,方便我們知道執行到什么地方了
input('已經完成登錄:')# 3. 獲取瀏覽器cookie保存到本地文件
cookies = b.get_cookies()
with open('files/zhihu.txt', 'w', encoding='utf-8') as f:f.write(str(cookies))
完成登錄的時候必須保證瀏覽器對象指向的窗口能夠看到登錄成功的效果是針對如下情況:
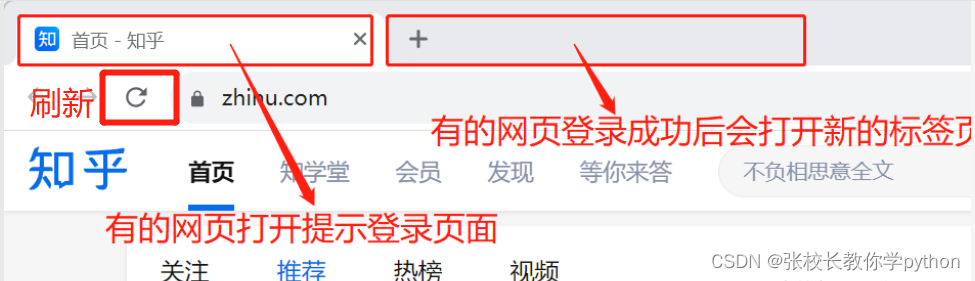
??因為第一步創建瀏覽器是打開網頁指向的是第一個標簽頁,要保證的是如果出現上述情況,我們希望是指向第二個頁面,爬蟲才能檢測到我們已經登錄成功了。可以在登錄成功頁面(第二個頁面)刷新一下即可
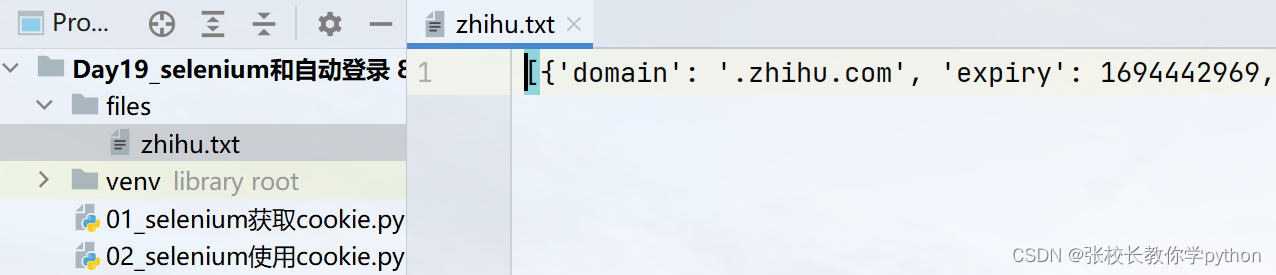
將獲取到的值存儲進csv文件中后,我們可以點擊files文件查看
二、selenium實現自動登錄
02_selenium使用cookie
# 1. 從本地的cookie文件中獲取cookie
with open('files/zhihu.txt', encoding='utf-8') as f:cookies = eval(f.read())# 2. 添加cookie
for x in cookies:b.add_cookie(x)# 3.重新打開網頁
b.get('https://www.zhihu.com')# 為了不讓程序停止,給一個input指令
input()







)






)

引入aar包報錯問題)

)
