1. 架構原理

1)StoreFile
保存實際數據的物理文件,StoreFile以HFile的形式存儲在HDFS上。每個Store會有一個或多個StoreFile(HFile),數據在每個StoreFile中都是有序的。
2)MemStore
寫緩存,由于HFile中的數據要求是有序的,所以數據是先存儲在MemStore中,排好序后,等到達刷寫時機才會刷寫到HFile,每次刷寫都會形成一個新的HFile。
3)WAL
由于數據要經MemStore排序后才能刷寫到HFile,但把數據保存在內存中會有很高的概率導致數據丟失,為了解決這個問題,數據會先寫在一個叫做Write-Aheadlogfile的文件中,然后再寫入MemStore中。所以在系統出現故障的時候,數據可以通過這個日志文件重建。
2. 寫流程
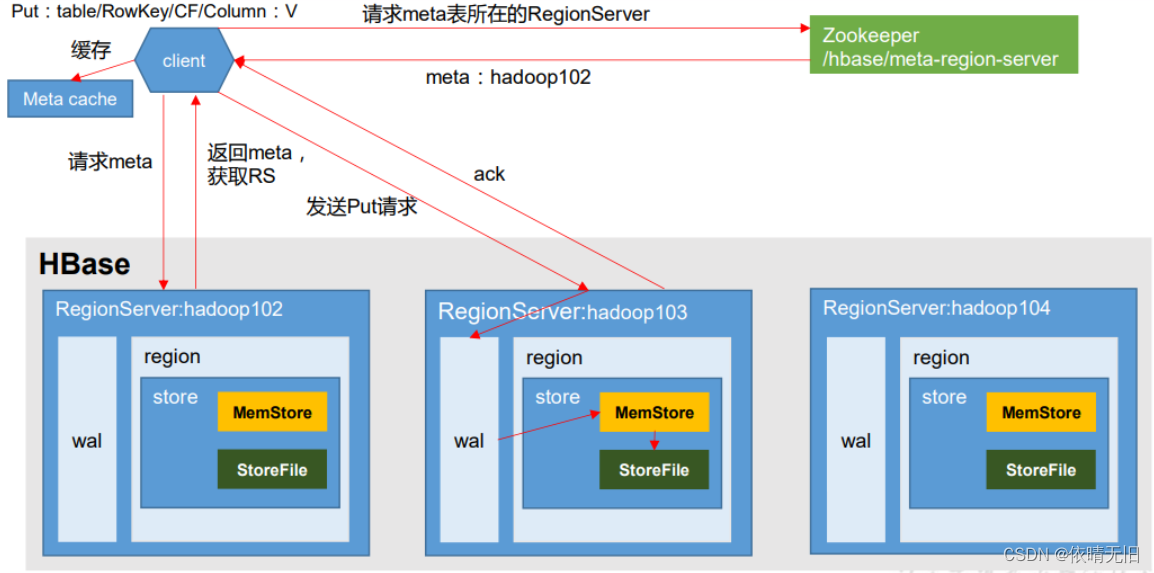
寫流程:
1)Client先訪問zookeeper,獲取hbase:meta表位于哪個RegionServer。
2)訪問對應的RegionServer,獲取hbase:meta表,根據讀請求的namespace:table/rowkey,查詢出目標數據位于哪個RegionServer中的哪個Region中。并將該table的region信息以及meta表的位置信息緩存在客戶端的metacache,方便下次訪問。
3)與目標RegionServer進行通訊;
4)將數據順序寫入(追加)到WAL;
5)將數據寫入對應的MemStore,數據會在MemStore進行排序;
6)向客戶端發送ack;
7)等達到MemStore的刷寫時機后,將數據刷寫到HFile。
3.?MemStoreFlush
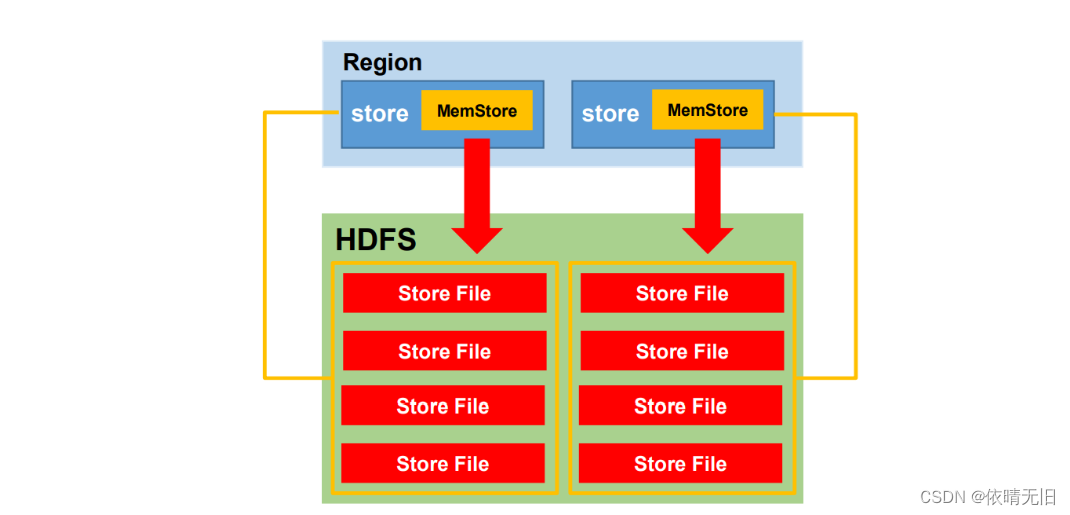
MemStore刷寫時機(要記住開始往memstore和停止mestore刷寫的時機。):
-
單個Store來看 memstroe 的大小達到了hbase.hregion.memstore.flush.size(默認值128M),其所在region的所有memstore都會刷寫。當memstore的大小達到了hbase.hregion.memstore.flush.size(默認值128M)* hbase.hregion.memstore.block.multiplier(默認值4)時,會阻止繼續往該memstore寫數據。
-
從regionerServer中來看regionserver中memstore的總大小達到java_heapsize*hbase.regionserver.global.memstore.size(默認值0.4)*hbase.regionserver.global.memstore.size.lower.limit(默認值0.95),region會按照其所有memstore的大小順序(由大到小)依次進行刷寫。直到regionserver中所有memstore的總大小減小到上述值以下。當 regionserver 中 memstore 的總大小達到 java_heapsize*hbase.regionserver.global.memstore.size(默認值0.4)時,會阻止繼續往所有的memstore寫數據。
-
到達自動刷寫的時間,也會觸發memstoreflush。自動刷新的時間間隔由該屬性進行配置hbase.regionserver.optionalcacheflushinterval(默認1小時)。
-
當 WAL 文件的數量超過 hbase.regionserver.max.logs,region 會按照時間順序依次進 行刷寫,直到 WAL 文件數量減小到 hbase.regionserver.max.log 以下(該屬性名已經廢棄, 現無需手動設置,最大值為 32)。
4. 讀流程
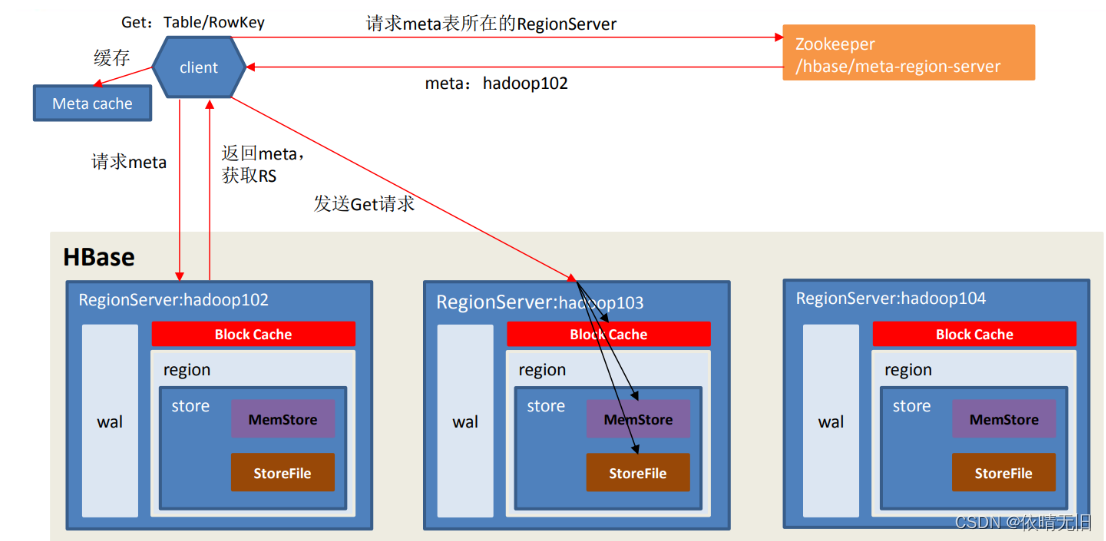
讀流程 :發送Get請求,磁盤和內存一起讀,為了加速磁盤的讀速度,加了一個Block Cache
1)Client 先訪問 zookeeper,獲取 hbase:meta 表位于哪個 Region Server。
2)訪問對應的 Region Server,獲取 hbase:meta 表,根據讀請求的 namespace:table/rowkey, 查詢出目標數據位于哪個 Region Server 中的哪個 Region 中。并將該 table 的 region 信息以 及 meta 表的位置信息緩存在客戶端的 meta cache,方便下次訪問。
3)與目標 Region Server 進行通訊;
4)分別在 Block Cache(讀緩存),MemStore 和 Store File(HFile)中查詢目標數據,并將查到的所有數據進行合并。此處所有數據是指同一條數據的不同版本(time stamp)或者不同的類型(Put/Delete)。
5) 將從文件中查詢到的數據塊(Block,HFile 數據存儲單元,默認大小為 64KB)緩存到 Block Cache。
6)將合并后的最終結果返回給客戶端。
5.?StoreFile Compaction
由于memstore每次刷寫都會生成一個新的HFile,且同一個字段的不同版本(timestamp) 和不同類型(Put/Delete)有可能會分布在不同的 HFile 中,因此查詢時需要遍歷所有的 HFile。
為了減少 HFile 的個數,以及清理掉過期和刪除的數據,會進行 StoreFile Compaction。 Compaction 分為兩種,分別是 Minor Compaction 和 Major Compaction。Minor Compaction 會將臨近的若干個較小的 HFile 合并成一個較大的 HFile,但不會清理過期和刪除的數據。 Major Compaction 會將一個 Store 下的所有的 HFile 合并成一個大 HFile,并且會清理掉過期 和刪除的數據。

6.?Region Split
默認情況下,每個Table 起初只有一個 Region,隨著數據的不斷寫入,Region 會自動進行拆分。剛拆分時,兩個子 Region 都位于當前的 Region Server,但處于負載均衡的考慮, HMaster 有可能會將某個 Region 轉移給其他的 Region Server。
Region Split 時機:
1.當1個region中的某個Store下所有StoreFile的總大小超過hbase.hregion.max.filesize, 該 Region 就會進行拆分(0.94 版本之前)。
2.當 1 個 region 中 的 某 個 Store 下所有 StoreFile 的 總 大 小 超 過 Min(R^2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),該 Region 就會進行拆分,其 中 R 為當前 Region Server 中屬于該 Table 的個數(0.94 版本之后)。







)











 問題解決小記)
