注:
文章中所有的圖片均來自臺灣大學林軒田《機器學習基石》課程。
筆記原作者:紅色石頭
微信公眾號:AI有道
上節課主要介紹了非線性分類模型,通過非線性變換,將非線性模型映射到另一個空間,轉換為線性模型,再來進行分類,分析了非線性變換可能會使計算復雜度增加。本節課介紹這種模型復雜度增加帶來機器學習中一個很重要的問題:過擬合(overfitting)。
一、What is Overfitting
首先,我們通過一個例子來介紹什么bad generalization。假設平面上有5個點,目標函數\(f(x)\)是2階多項式,如果hypothesis是二階多項式加上一些小的noise的話,那么這5個點很靠近這個hypothesis, \(E_{in}\)很小。如果hypothesis是4階多項式,那么這5點會完全落在hypothesis上,\(E_{in}=0\) 。雖然4階hypothesis的\(E_{in}\)比2階hypothesis的要好很多,但是它的\(E_{out}\)很大。因為根據VC Bound理論,階數越大,即VC Dimension越大,就會讓模型復雜度更高, \(E_{out}\)更大。我們把這種\(E_{in}\)很小, \(E_{out}\)很大的情況稱之為bad generation,即泛化能力差。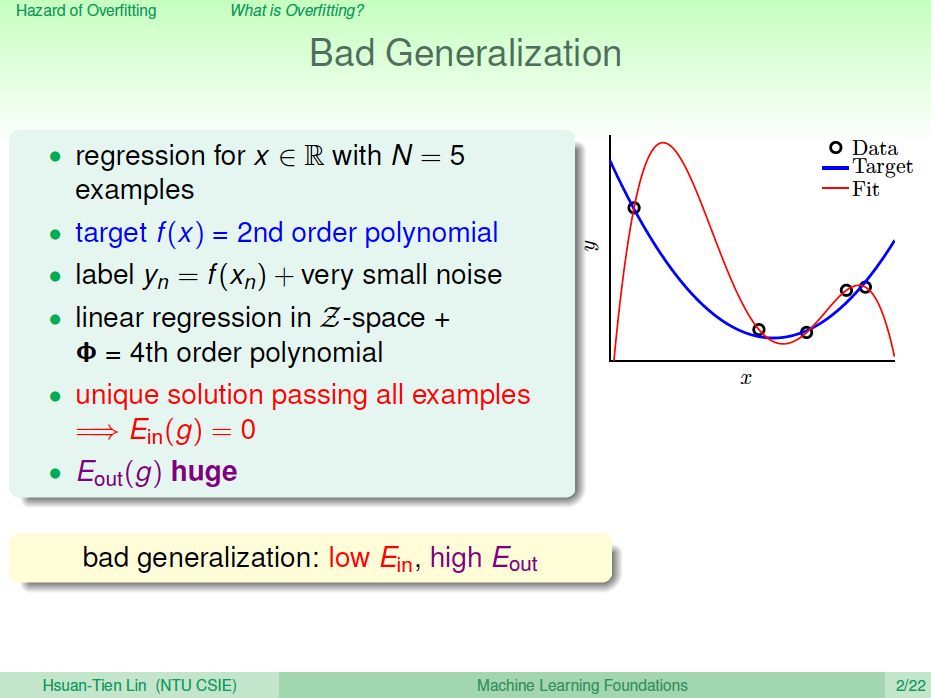
回過頭來看一下VC曲線:
hypothesis的階數越高,表示VC Dimension越大。隨著VC Dimension增大, \(E_{in}\)是一直減小的,而\(E_{out}\)先減小后增大。在\(d^*\)位置,\(E_{out}\)取得最小值。在\(d^*_{VC}\)右側,隨著VC Dimension越來越大,\(E_{in}\)越來越小,接近于0, \(E_{out}\)越來越大。即當VC Dimension很大的時候,這種對訓練樣本擬合過分好的情況稱之為過擬合(overfitting)。另一方面,在\(d^*_{VC}\)左側,隨著VC Dimension越來越小,\(E_{in}\)和\(E_{out}\)都越來越大,這種情況稱之為欠擬合(underfitting),即模型對訓練樣本的擬合度太
差,VC Dimension太小了。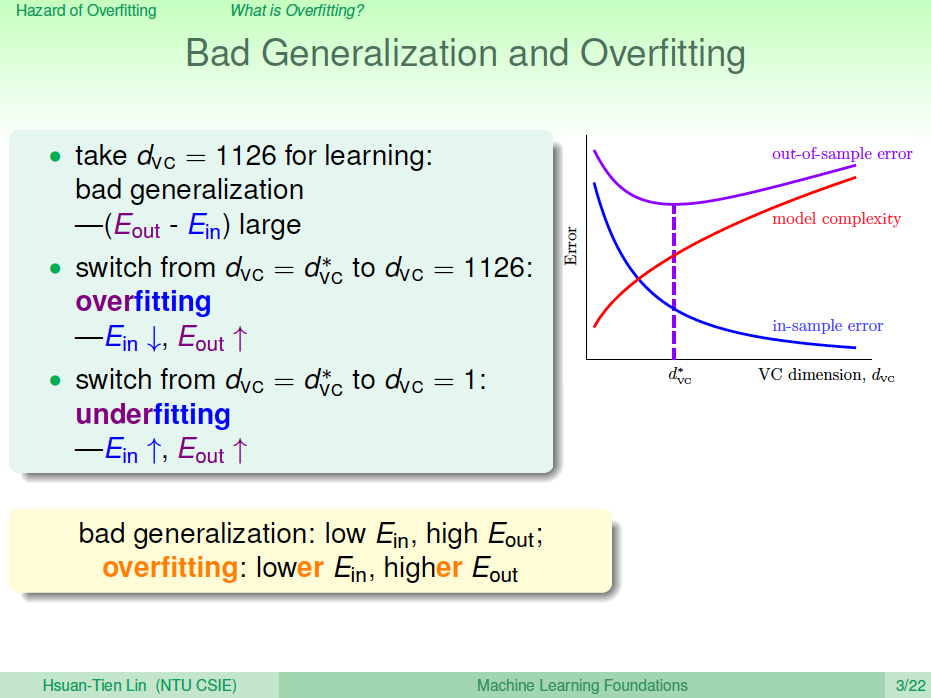
bad generation和overfitting的關系可以理解為:overfitting是VC Dimension過大的一個過程,bad generation是overfitting的結果。
一個好的fit, \(E_{in}\)和\(E_{out}\)都比較小,盡管\(E_{in}\)沒有足夠接近零;而對overfitting來說,\(E_{in}\approx 0\),但是\(E_{out}\)很大。那么,overfitting的原因有哪些呢?
舉個開車的例子,把發生車禍比作成overfitting,那么造成車禍的原因包括:
- 車速太快(VC Dimension 太大)
- 道路崎嶇(noise)
- 對路況的了解程度(訓練樣本數量\(N\)不夠)
也就是說,VC Dimension、noise、\(N\)這三個因素是影響過擬合現象的關鍵。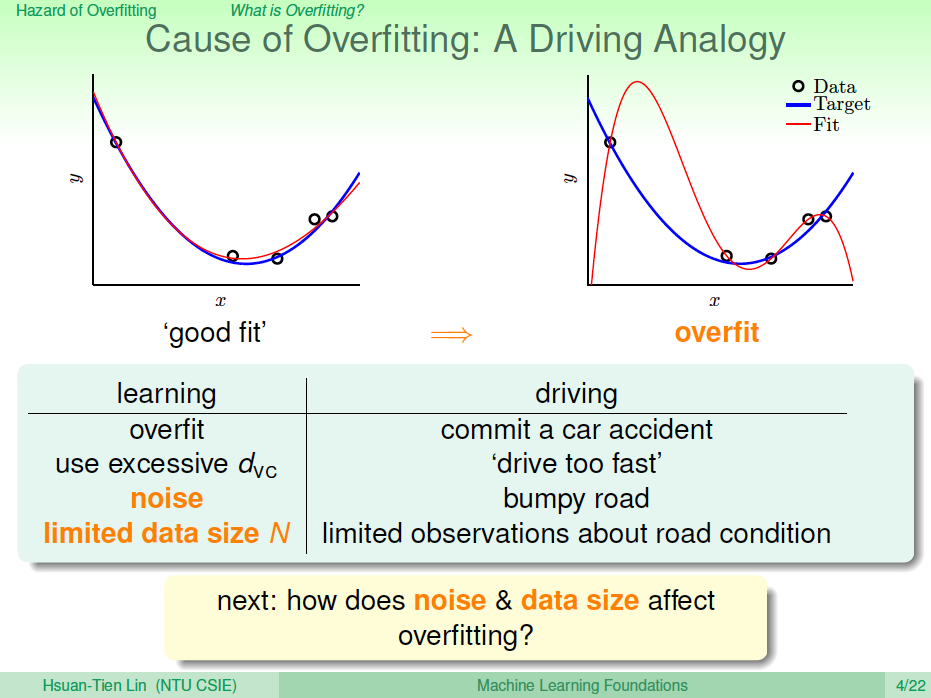
二、The Role of Noise and Data Size
為了盡可能詳細地解釋overfitting,我們進行這樣一個實驗,試驗中的數據集不是很大。首先,在二維平面上,一個模型的分布由目標函數\(f(x)\)(\(x\)的10階多項式)加上一些noise構成,下圖中,離散的圓圈是數據集,目標函數是藍色的曲線。數據沒有完全落在曲線上,是因為加入了noise。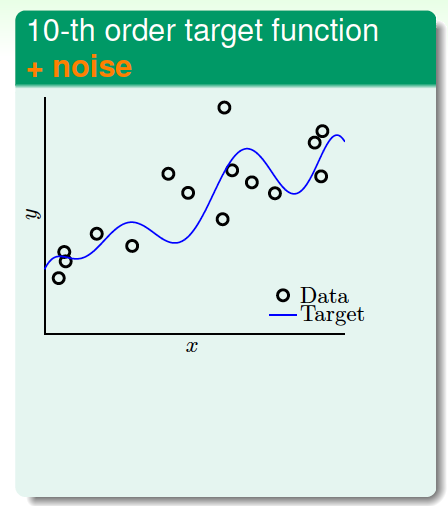
然后,同樣在二維平面上,另一個模型的分布由目標函數\(f(x)\)(\(x\)的50階多項式)構成,沒有加入noise。下圖中,離散的圓圈是數據集,目標函數是藍色的曲線。可以看出由于沒有noise,數據集完全落在曲線上。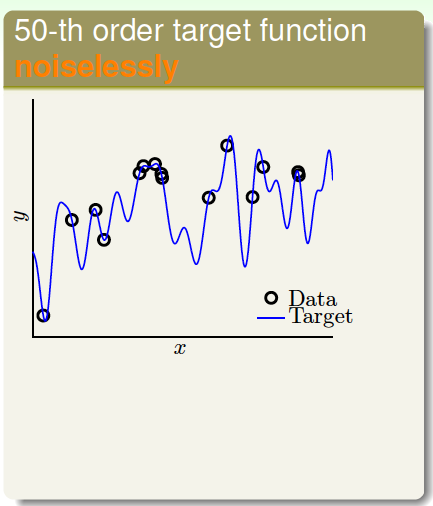
現在,有兩個學習模型,一個是2階多項式,另一個是10階多項式,分別對上面兩個問題進行建模。首先,對于第一個目標函數是10階多項式包含noise的問題,這兩個學習模型的效果如下圖所示:
由上圖可知,2階多項式的學習模型\(E_{in}=0.050\),\(E_{out}=0.127\);10階多項式的學習模型\(E_{in}=0.034\),\(E_{out}=9.00\) 。雖然10階模型的\(E_{in}\)比2階的\(E_{in}\)小,但是其\(E_{out}\)要比2階的大得多,而2階的\(E_{in}\)和\(E_{out}\)相差不大,很明顯用10階的模型發生了過擬合。
然后,對于第二個目標函數是50階多項式沒有noise的問題,這兩個學習模型的效果如下圖所示:
可以看到,用10階的模型仍然發生了明顯的過擬合。
上面兩個問題中,10階模型都發生了過擬合,反而2階的模型卻表現得相對不錯。這好像違背了我們的第一感覺,比如對于目標函數是10階多項式,加上noise的模型,按道理來說應該是10階的模型更能接近于目標函數,因為它們階數相同。但是,事實卻是2階模型泛化能力更強。這種現象產生的原因,從哲學上來說,就是“以退為進”。有時候,簡單的學習模型反而能表現的更好。
下面從learning curve來分析一下具體的原因,learning curve描述的是\(E_{in}\)和\(E_{out}\)隨著數據量\(N\)的變化趨勢。下圖中左邊是2階學習模型的learning curve,右邊是10階學習模型的learning curve。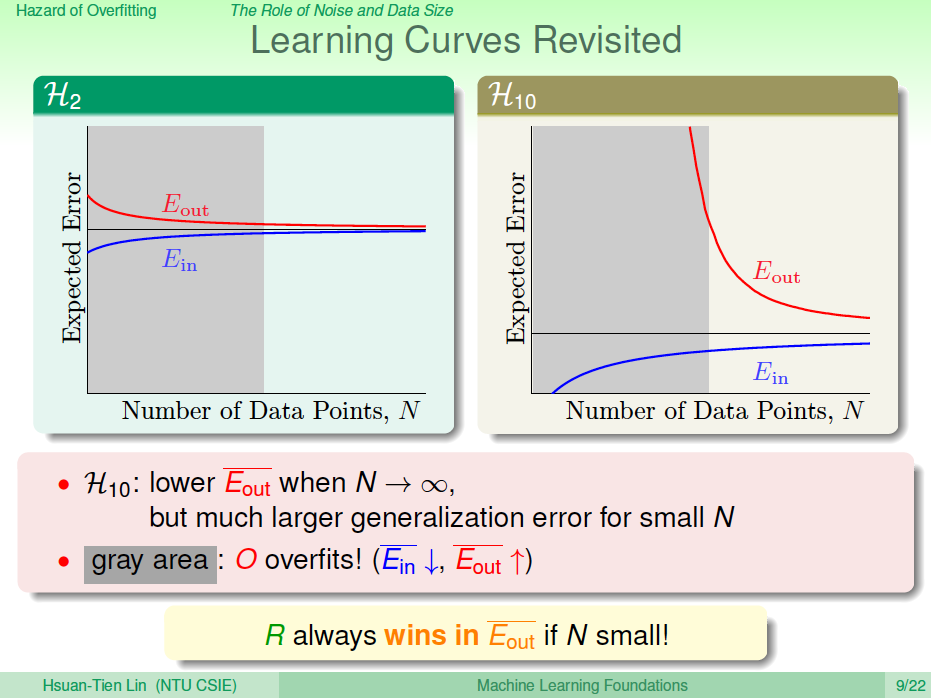
在learning curve中,橫軸是樣本數量\(N\),縱軸是Error。\(E_{in}\)和\(E_{out}\)可表示為:\[E_{in}=noiselevel *(1-\frac{d+1}{N})\] \[E_{out}=noiselevel *(1+\frac{d+1}{N})\] 其中\(d\)為模型階次,左圖中\(d=2\),右圖中\(d=10\)。
本節的實驗問題中,數據量\(N\)不大,即對應于上圖中的灰色區域。左圖的灰色區域中,因為\(d=2\), \(E_{in}\)和\(E_{out}\)相對來說比較接近;右圖中的灰色區域中,\(d=10\),根據\(E_{in}\)和\(E_{out}\)的表達式, \(E_{in}\)很小,而\(E_{out}\)很大。這就解釋了之前2階多項式模型的\(E_{in}\)更接近\(E_{out}\),泛化能力更好。
值得一提的是,如果數據量\(N\)很大的時候,上面兩圖中\(E_{in}\)和\(E_{out}\)都比較接近,但是對于高階模型,z域中的特征很多的時候,需要的樣本數量\(N\)很大,且容易發生維度災難。
另一個例子中,目標函數是50階多項式,且沒有加入noise(noiselevel很小)。這種情況下,我們發現仍然是2階的模型擬合的效果更好一些,明明沒有noise,為什么是這樣的結果呢?
實際上,我們忽略了一個問題:這種情況真的沒有noise嗎?其實,當模型很復雜的時候,即50階多項式的目標函數,無論是2階模型還是10階模型,都不能學習的很好,這種復雜度本身就會引入一種‘noise’。所以,這種高階無noise的問題,也可以類似于10階多項式的目標函數加上noise的情況,只是二者的noise有些許不同,下面一部分將會詳細解釋。
三、Deterministic Noise
下面我們介紹一個更細節的實驗來說明 什么時候要小心overfit會發生。假設我們產生的數據分布由兩部分組成:第一部分是目標函數\(f(x)\),\(Q_f\)階多項式;第二部分是噪聲\(\epsilon\),服從Gaussian分布。接下來我們分析的是noise強度不同對overfitting有什么樣的影響。總共的數據量是\(N\)。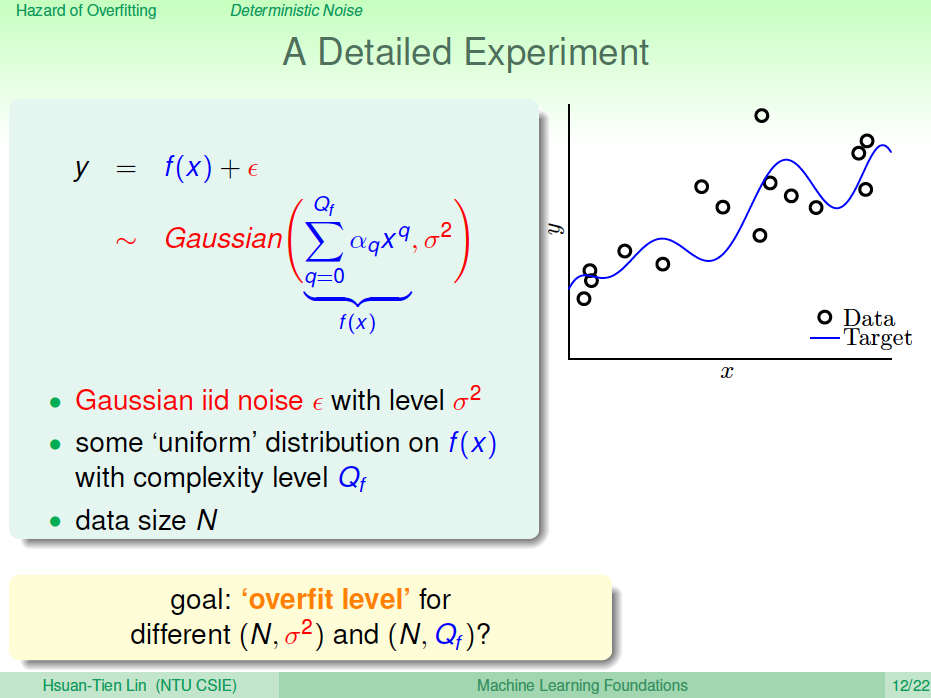
那么下面我們分析不同的\((N,\sigma^2)\)和\((N,Q_f)\)對overfit的影響。overfit可以量化為\(E_{out}-E_{in}\)。結果如下: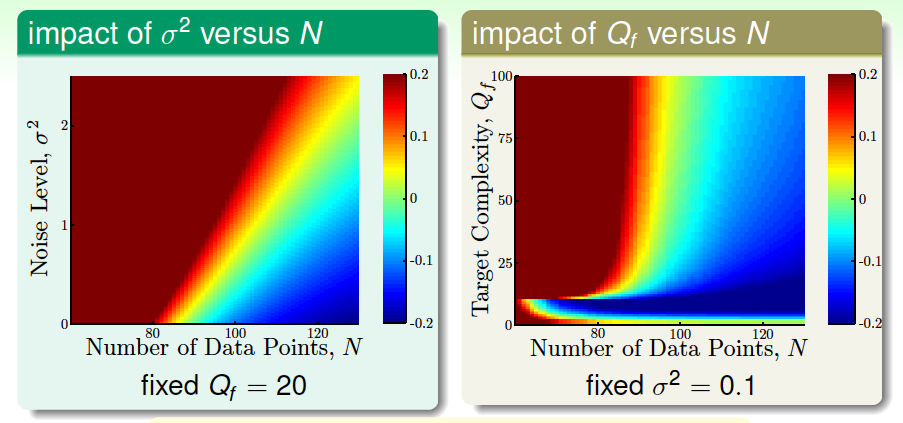
上圖中,紅色越深,代表overfit程度越高,藍色越深,代表overfit程度越低。先看左邊的圖,左圖中階數固定為20,橫坐標代表樣本數量\(N\),縱坐標代表噪聲水平\(\sigma^2\)。紅色區域集中在\(N\)很小或者\(\sigma^2\)很大的時候,也就是說\(N\)越大,\(\sigma^2\) 越小,越不容易發生overfit。右邊圖中,橫坐標代表樣本數量\(N\),縱坐標代表目標函數階數\(Q_f\)。紅色區域集中在\(N\)很小或者\(Q_f\)很大的時候,也就是說\(N\)越大,\(Q_f\) 越小,越不容易發生overfit。上面兩圖基本相似。
從上面的分析,我們發現\(\sigma^2\)對overfit是有很大的影響的,我們把這種noise稱之為stochastic noise。同樣地, \(Q_f\)即模型復雜度也對overfit有很大影響,而且二者影響是相似的,所以我們把這種稱之為deterministic noise。之所以把它稱為noise,是因為模型高復雜度帶來的影響。
總結一下,有四個因素會導致發生overfitting:
- data size \(N\) \(\downarrow\)
- stochastic noise \(\sigma^2\) \(\uparrow\)
- deterministic noise \(Q_f\) \(\uparrow\)
- excessive power \(\uparrow\)
我們剛才解釋了如果目標函數\(f(x)\)的復雜度很高的時候,那么跟有noise也沒有什么兩樣。因為目標函數很復雜,那么再好的hypothesis都會跟它有一些差距,我們把這種差距稱之為deterministic noise。deterministic noise與stochastic noise不同,但是效果一樣。其實deterministic noise類似于一個偽隨機數發生器,它不會產生真正的隨機數,而只產生偽隨機數。它的值與hypothesis有關,且固定點\(x\)的deterministic noise值是固定的。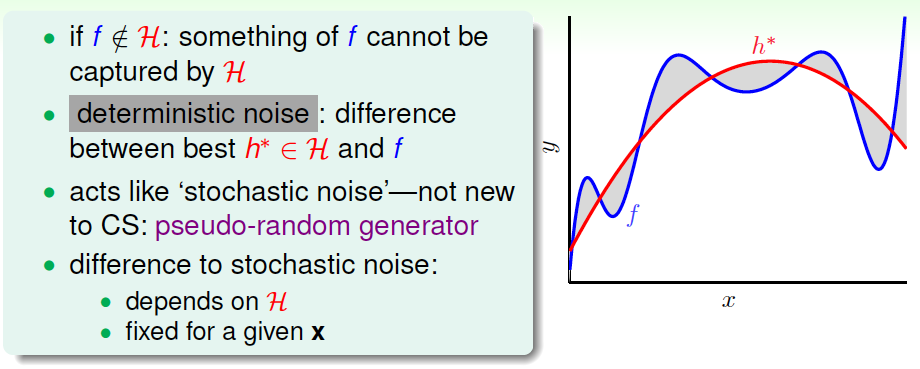
四、Dealing with Overfitting
現在我們知道了什么是overfitting,和overfitting產生的原因,那么如何避免overfitting呢?避免overfitting的方法主要包括:
- start from simple model (\(Q_f\))
- data cleaning/pruning (noise)
- data hinting (\(N\))
- regularization
- validation
這幾種方法類比于之前舉的開車的例子,對應如下:
regularization和validation我們之后的課程再介紹,本節課主要介紹簡單的data cleaning/pruning和data hinting兩種方法。
data cleaning/pruning就是對訓練數據集里label明顯錯誤的樣本進行修正(data cleaning),或者對錯誤的樣本看成是noise,進行剔除(data pruning)。data cleaning/pruning關鍵在于如何準確尋找label錯誤的點或者是noise的點,而且如果這些點相比訓練樣本\(N\)很小的話,這種處理效果不太明顯。
data hinting是針對\(N\)不夠大的情況,如果沒有辦法獲得更多的訓練集,那么data hinting就可以對已知的樣本進行簡單的處理、變換,從而獲得更多的樣本。舉個例子,數字分類問題,可以對已知的數字圖片進行輕微的平移或者旋轉,從而讓\(N\)豐富起來,達到擴大訓練集的目的。這種額外獲得的例子稱之為virtual examples。但是要注意一點的就是,新獲取的virtual examples可能不再是iid某個distribution。所以新構建的virtual examples要盡量合理,且是獨立同分布。
五、總結
本節課主要介紹了overfitting的概念,即當\(E_{in}\)很小,\(E_{out}\) 很大的時候,會出現overfitting。詳細介紹了overfitting發生的四個常見原因data size \(N\)、stochastic noise、deterministic noise和excessive power。解決overfitting的方法有很多,本節課主要介紹了data cleaning/pruning和data hinting兩種簡單的方法,之后的課程將會詳細介紹regularization和validation兩種更重要的方法。

優化器模式)

)





)


)

-視頻課程_Linux視頻-51CTO學院...)
)



![[Spark][Python]Spark 訪問 mysql , 生成 dataframe 的例子:](http://pic.xiahunao.cn/[Spark][Python]Spark 訪問 mysql , 生成 dataframe 的例子:)