簡介:為什么我寫這篇文章 (Intro: why I wrote this post)
Many state-of-the-art results in NLP problems are achieved by using DL (deep learning), and probably you want to use deep learning style to solve NLP problems as well. While there are a lot of materials discussing how to choose and train the “best” neural network architecture, like, an RNN, selecting and configuring a suitable neural network is just one part of solving a practical NLP problem. The other import part, but often being underestimated, is model preparation. NLP tasks usually require special data treatment in the model preparation stage. In other words, there is a lot of things to do before we can throw the data in the neural networks to train. Unfortunately, there are not many tutorials giving detailed guidance on model preparation.
通過使用DL(深度學習)可以解決NLP問題的許多最新成果,并且您可能還希望使用深度學習樣式來解決NLP問題。 盡管有很多材料討論如何選擇和訓練“最佳”神經網絡體系結構,例如RNN,但是選擇和配置合適的神經網絡只是解決實際NLP問題的一部分。 另一個重要的部分是模型準備,但經常被低估。 NLP任務通常在模型準備階段需要特殊的數據處理。 換句話說,在將數據放入神經網絡進行訓練之前,還有很多事情要做。 不幸的是,沒有多少教程提供有關模型準備的詳細指導。
Besides, the packages or APIs to support the state-of-the-art NLP theories and algorithms are usually released very recently and are updating at a rapid speed. (e.g., TensorFlow was first released in 2015, PyTorch in 2016, and spaCy in 2015.) To achieve a better performance, many times, you might have to integrate several packages in your deep learning pipeline, while preventing them from crashing with each other.
此外,支持最新的NLP理論和算法的軟件包或API通常是在最近才發布的,并且更新速度很快。 (例如,TensorFlow于2015年首次發布,PyTorch于2016年發布,spaCy于2015年發布。)要獲得更好的性能,很多時候,您可能必須將多個軟件包集成到深度學習管道中,同時防止它們相互崩潰。
That’s why I decided to write this article to give you a detailed tutorial.
這就是為什么我決定寫這篇文章為您提供詳細教程的原因。
- I will walk you through the model preparation pipelines from tokenizing raw data to configuring the Tensorflow Embedding so that your neural networks are ready for the training. 我將引導您完成模型準備流程,從標記原始數據到配置Tensorflow嵌入,以便您的神經網絡已準備好進行訓練。
- The example code will help you to have a solid understanding of the model preparation steps. 示例代碼將幫助您深入了解模型準備步驟。
- In the tutorial, I will choose the popular packages and APIs that specialize in NLP and advise for parameter default settings to make sure you will have a good start on the NLP deep learning journey. 在本教程中,我將選擇專門針對NLP的流行軟件包和API,并建議您使用參數默認設置,以確保您在NLP深度學習之旅中有一個良好的開端。
對本文的期望 (What to expect in this article)
- We will walk through the NLP model preparation pipeline using TensorFlow 2.X and spaCy. The four main steps in the pipelines are tokenization, padding, word embeddings, embedding layer setups. 我們將使用TensorFlow 2.X和spaCy逐步完成NLP模型準備流程。 流水線中的四個主要步驟是標記化,填充,單詞嵌入,嵌入層設置。
- The motivation (why we need this) and intuition (how it works) will be introduced, so don’t worry if you are new to NLP or deep learning. 將會介紹動機(為什么我們需要這樣做)和直覺(它如何工作),因此,如果您不熟悉NLP或深度學習,請不要擔心。
- I will mention some common issues during model preparation and potential solutions. 我將在模型準備和潛在解決方案中提及一些常見問題。
There is a notebook you can play with, available on Colab and Github. While we are using a toy dataset in the example (taken as a piece from the IMDB movie review dataset), the code can apply to a larger and more practical dataset.
在Colab和Github上有一個可以玩的筆記本。 盡管在示例中使用玩具數據集(摘自IMDB電影評論數據集 ),但是代碼可以應用于更大,更實用的數據集。
Without further ado, let’s start with the first step.
事不宜遲,讓我們從第一步開始。
代幣化 (Tokenization)
什么是令牌化? (What is tokenization?)
In NLP, Tokenization means to brake the raw text into unique unites (a.k.a., tokens). A token can be sentences, phrases, or words. Each token has a unique token-id. The purpose of tokenization is that we can use those tokens (or token-id) to represent the original text. Here is an illustration.
在NLP中, 令牌化意味著將原始文本制動為唯一的單位(也稱為令牌)。 令牌可以是句子,短語或單詞。 每個令牌都有唯一的令牌ID。 標記化的目的是我們可以使用這些標記(或標記ID)來表示原始文本。 這是一個例子。

Tokenization usually includes two stages:
令牌化通常包括兩個階段:
stage1: create a token dictionary, in this stage,
stage1:在此階段創建令牌字典,
- Select token candidates (usually words) by first separating the raw text into sentences, then breaking down sentences into words. 首先將原始文本分成句子,然后將句子分解為單詞,從而選擇標記候選項(通常是單詞)。
- Certain preprocessing should be involved, e.g., lowercasing, punctuation removal, etc. 應該涉及某些預處理,例如下套管,標點符號去除等。
- Note that tokes should be unique and assign to different token-ids, e.g., ‘car’ and ‘cars’ are different tokens, as well as ‘CAR’ and ‘car’. The chosen token and the associated token-ids will create a token dictionary. 請注意,代幣應該是唯一的,并分配給不同的令牌ID,例如,“ car”和“ cars”是不同的令牌,以及“ CAR”和“ car”。 所選令牌和關聯的令牌ID將創建一個令牌字典。
stage2: text representation, in this stage,
stage2:在此階段的文字表示,
- Represent the original text with the tokens (or the associated token-ids) by referring to the token dictionary. 通過引用令牌字典,用令牌(或關聯的令牌ID)表示原始文本。
- Sometimes the tokens are partially selected for text representation (e.g., only select the most frequent tokens.); thus, the final tokenized sequence will only include such chosen tokens. 有時,部分標記被選擇用于文本表示(例如,僅選擇最頻繁的標記)。 因此,最終的標記化序列將僅包括這樣選擇的標記。
在TensorFlow中 (In TensorFlow)
We will take a piece of IMDB movie review dataset to demonstrate the pipeline.
我們將使用一個IMDB電影評論數據集來演示管道。
from tensorflow.keras.preprocessing.text import Tokenizertokenizer = Tokenizer()
tokenizer.fit_on_texts(raw_text)
train_sequences = tokenizer.texts_to_sequences(raw_text) #Converting text to a vector of word indexes
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
print('1st token-id sequnce', train_sequences[0])>>Found 212 unique tokens.
>>1st token-id sequnce [21, 4, 2, 12, 22, 23, 50, 51, 13, 2, 52, 53, 54, 24, 6, 2, 55, 56, 57, 7, 2, 58, 59, 4, 25, 60]Now, let’s take a look at what we get from the tokenization step.
現在,讓我們看一下從標記化步驟中得到的結果。
a token dictionary
令牌字典
# display the token dictionary (from most freqent to rarest)
# these are the 2 useful attributes, (get_config will show the rest)
print(tokenizer.word_index)
print(tokenizer.word_counts)
# tokenizer.get_config()>>{'the': 1, 'a': 2, 'and': 3, 'of': 4, 'to': 5, 'with': 6, 'is': 7, 'this': 8, 'by': 9, 'his': 10, 'movie': 11, 'man': 12, 'for': 13, ...
>>OrderedDict([('story', 2), ('of', 8), ('a', 11), ('man', 3), ('who', 2), ('has', 2), ('unnatural', 1), ('feelings', 1), ('for', 3), ('pig', 1), ('br', 1), ('starts', 1), ('out', 2), ('with', 6), ...Explanation:
說明:
The tokenizer counts the number of each word (tokens) and ranks the tokens by the counts. e.g., ‘the’ is the most frequent token in the corpus, so rank as no.1, associated the token-id as “1”. This ranking is described in a dictionary. We can use the
tokenizer.word_indexattribute to review the distortionary.分詞器對每個單詞(令牌)的數量進行計數,并根據計數對令牌進行排名。 例如,“ the”是語料庫中最常見的標記,因此排名為1,將標記ID關聯為“ 1”。 該排名在字典中描述。 我們可以使用
tokenizer.word_index屬性來檢查失真。We can use
tokenizer.word_countsto check the counts associated with each token.我們可以使用
tokenizer.word_counts來檢查與每個令牌關聯的計數。
Important note: When using TensorFlow Tokenizer, 0-token-id is reserved to empty-token, i.e., the token-id starts at 1,
重要說明:使用TensorFlow Tokenizer時,0-token-id保留為空令牌,即,token-id從1開始
token-ids sequences
令牌ID序列
# compare the number of tokens and tokens after cut-off
train_sequences = tokenizer.texts_to_sequences(raw_text) #Converting text to a vector of word indexes
# print(len(text_to_word_sequence(raw_text[0])), len(train_sequences[0]))
print(raw_text[0])
print(text_to_word_sequence(raw_text[0]))
print()
tokenizer.num_words = None # take all the tokens
print(tokenizer.texts_to_sequences(raw_text)[0])
tokenizer.num_words = 50 # take the top 50-1 tokens
print(tokenizer.texts_to_sequences(raw_text)[0])>>Story of a man who has unnatural feelings for a pig. <br> Starts out with a opening scene that is a terrific example of absurd comedy.
>>['story', 'of', 'a', 'man', 'who', 'has', 'unnatural', 'feelings', 'for', 'a', 'pig', 'br', 'starts', 'out', 'with', 'a', 'opening', 'scene', 'that', 'is', 'a', 'terrific', 'example', 'of', 'absurd', 'comedy']>>[21, 4, 2, 12, 22, 23, 50, 51, 13, 2, 52, 53, 54, 24, 6, 2, 55, 56, 57, 7, 2, 58, 59, 4, 25, 60]
>>[21, 4, 2, 12, 22, 23, 13, 2, 24, 6, 2, 7, 2, 4, 25]Explanation:
說明:
We use
train_sequences = tokenizer.texts_to_sequences(raw_text)to convert text to a vector of word indexes/ids. The converted sequences will be fitted into the next step in the pipeline.我們使用
train_sequences = tokenizer.texts_to_sequences(raw_text)將文本轉換為單詞索引/ id的向量。 轉換后的序列將被安裝到管道的下一步中。When there are too many tokens, storage and computation can be expensive. We can use the
num_wordsparameter to determine how many tokens are used to represent the text. In the example, since we set the parameternum_words=50, which means we will take the top 50-1=49 tokens. In other words, tokens like “unnatural: 50”, “feelings: 51” would not appear in the final tokenized sequence.當令牌太多時,存儲和計算可能會很昂貴。 我們可以使用
num_words參數來確定使用多少標記來表示文本。 在此示例中,由于我們設置了參數num_words=50,這意味著我們將使用前50-1 = 49個令牌。 換句話說,諸如“非自然:50”,“感覺:51”之類的標記不會出現在最終的標記化序列中。By default,
num_words=None, which means it will take all the tokens.默認情況下,
num_words=None,這意味著它將獲取所有令牌。- Tips: you can set num_words anytime without re-fit the tokenizer. 提示:您可以隨時設置num_words,而無需重新安裝令牌生成器。
NOTES: There is no simple answer to what should be num_words value. But here is my suggestion: to build a pipeline, you can start with a relatively small number, say, num_words=10,000, and come back to modify it after further analysis. (I found this stack overflow post shares some insightful ideas on how to choose the num_words value. Also, check the document of Tokenizer for other parameter settings.)
注意:沒有簡單的答案應為num_words值。 但是我的建議是:建立一個管道,您可以從一個相對較小的數字開始,例如num_words = 10,000,然后在進一步分析之后再修改它。 (我發現此堆棧溢出文章分享了一些有關如何選擇num_words值的深刻見解。此外,請檢查Tokenizer文檔中的其他參數設置。)
問題:OOV (An issue: OOV)
Let’s take a look at a common issue in tokenization that is very harmful to both deep learnings and traditional MLs and how we can deal with it. Consider the following example, to tokenize the sequence [‘Storys of a woman…’].
讓我們看一下令牌化中的一個常見問題,它對深度學習和傳統ML都非常有害,以及我們如何處理它。 考慮以下示例,以標記序列[“女人的故事……”]。
test_sequence = ['Storys of a woman...']
print(test_sequence)
print(text_to_word_sequence(test_sequence[0]))
print(tokenizer.texts_to_sequences(test_sequence))>>['Storys of a woman...']
>>['storys', 'of', 'a', 'woman']
>>[[4, 2]]Since the corpus used for training doesn’t consist of words “storys” or “woman”, these words are not included in the token dictionary either. This is out of vocabulary (OOV) issue. While OOV is hard to avoid, there is some solution to mitigate the problems:
由于用于訓練的語料庫不包含“故事”或“女人”一詞,因此這些詞也不包含在令牌詞典中。 這是詞匯(OOV)問題。 盡管很難避免OOV,但是有一些解決方案可以緩解這些問題:
- A rule of thumb is to train on a relatively big corpus so that the dictionary created can cover more words, thus not consider them as new words can cast away. 經驗法則是在一個相對較大的語料庫上進行訓練,以便創建的詞典可以覆蓋更多的單詞,因此不認為它們會丟棄新單詞。
Set the parameter
oov_token=to capture the OOV phenomenon. Note that this method only notifies you OOV has happened somewhere, but it will not solve the OOV problem. Check the Kerras document for more details.設置參數
oov_token=以捕獲OOV現象。 請注意,此方法僅通知您OOV發生在某處,但不能解決OOV問題。 查看Kerras文檔以獲取更多詳細信息。Perform text preprocessing before tokenization. e.g., ‘storys’ can be spelling-corrected or signalized to ‘story’, which is included in the token dictionary. There are NLP packages offer more robust algorithms for tokenization and preprocessing. Some good options for tokenization are spaCy and Gensim.
在標記化之前執行文本預處理。 例如,“故事”可以進行拼寫更正或發信號給“故事”,該故事包含在令牌字典中。 NLP軟件包為令牌化和預處理提供了更強大的算法。 spaCy和Gensim是標記化的一些不錯的選擇。
Adopt (and fine-tune) a pre-trained tokenizer (or transformers), e.g., Huggingface’s PretrainedTokenizer.
采用(并微調)預訓練的令牌生成器(或轉換器),例如Huggingface的PretrainedTokenizer 。
簡短討論:艱難的開始? (Short discussion: a tough start?)
The idea of tokenization might seem very simple, but sooner or later, you will realize tokenization can be much more complicated than it seems in this example. The complexity mainly comes from various preprocessing methods. Some of the common practices of preprocessing are lowercasing, removal of punctuation, word singularization, stemming, and lemmatization. Besides, we have optional preprocessing steps, such as test normalization (e.g., digit to text, expand abbreviation), language identification, and code-mixing and translation; as well as advanced preprocessing, like, [Part-of-speech tagging](Part-of-speech tagging) (a.k.a., POS tagging), parsing, and coreference resolution. Depends on what preprocessing steps to take, the tokens can be different, thus the tokenized texts.
令牌化的概念可能看起來很簡單,但是遲早您會意識到,令牌化可能比此示例中看起來要復雜得多。 復雜度主要來自各種預處理方法。 預處理的一些常見做法是降低大小寫,刪除標點,單詞單數化, 詞干化和詞形化 。 此外,我們還有可選的預處理步驟,例如測試規范化 (例如,數字到文本,擴展縮寫), 語言識別以及代碼混合和翻譯 ; 以及高級預處理,例如[詞性標記](詞性標記)(又名POS標記), 解析和共指解析 。 根據要采取的預處理步驟,令牌可能會有所不同,因此令牌化的文本也會有所不同。
Don’t worry if you don’t know all these confusing names above. Indeed, it is very overwhelming to determine which preprocessing method(s) to include in the NLP pipeline. For instance, it is not an easy decision to make which tokens to include in the text presentation. Integrating a large number of token candidates are storage and computationally expensive. And it is not very clear which tokens are more important: the most appear words like “the”, “a” are not very informative for text representation, and that’s why we need to handle stop words in preprocessing.
如果您不知道上面所有這些令人困惑的名稱,請不要擔心。 確實,確定要在NLP管道中包括哪種預處理方法非常困難。 例如,要確定要在文本表示中包含哪些標記并不是一個容易的決定。 集成大量令牌候選者是存儲空間并且在計算上是昂貴的。 尚不清楚哪個標記更重要:出現最多的單詞(如“ the”,“ a”)對于文本表示而言不是很有幫助,這就是為什么我們需要在預處理中處理停用詞 。
Though arguably, we have good news here: deep learnings requires relatively less preprocessing than conventional machine learning algorithms. The reason is that deep learnings can take advantage of the neural network architecture for feature extraction that conventional ML models perform in the preprocessing and feature engineering stages. So, here we can keep the tokenization step simple and come back later if more preprocessing and/or postprocessing are desired.
雖然可以說是個好消息,但與傳統的機器學習算法相比,深度學習所需的預處理相對較少。 原因是深度學習可以利用神經網絡架構進行特征提取,而傳統的ML模型則在預處理和特征工程階段執行這些特征提取。 因此,這里我們可以使標記化步驟保持簡單,如果需要更多的預處理和/或后處理,可以稍后再返回。
令牌化準備 (Tokenization warp-up)
While most of the deep learning tutorials still use a list or np.array to store the data, I find it more controllable and scalable using DataFrame (e.g., Pandas, or PySpark) to do the work. This step is optional, but I recommend you do it. Here is the example code.
盡管大多數深度學習教程仍使用列表或np.array來存儲數據,但我發現使用DataFrame(例如Pandas或PySpark)進行工作時,它可控性和可伸縮性更高。 此步驟是可選的,但我建議您這樣做。 這是示例代碼。
# store in dataframe
df_text = pd.DataFrame({'raw_text': raw_text})
df_text.head()# updata df_text
df_text['train_sequence'] = df_text.raw_text.apply(lambda x: tokenizer.texts_to_sequences([x])[0])
df_text.head()>> raw_text train_sequence
0 Story of a man who has unnatural feelings for ... [21, 4, 2, 12, 22, 23, 13, 2, 24, 6, 2, 7, 2, ...
1 A formal orchestra audience is turned into an ... [2, 26, 7, 27, 14, 9, 1, 4, 28]
2 Unfortunately it stays absurd the WHOLE time w... [15, 25, 1, 29, 6, 15, 30]
3 Even those from the era should be turned off. ... [1, 16, 17, 27, 30, 1, 5, 2]
4 On a technical level it's better than you migh... [31, 2, 28, 6, 32, 9, 33]That’s what you need to know about tokenization. Let’s move on to the next step: padding.
這就是您需要了解的關于令牌化的知識。 讓我們繼續下一步:填充。
填充 (Padding)
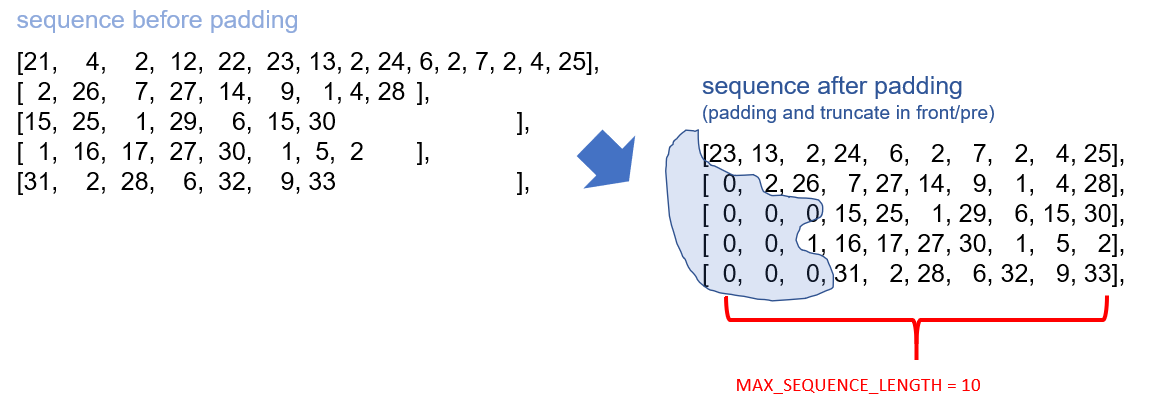
Most (if not all) of the neural networks require the input sequence data with the same length, and that’s why we need padding: to truncate or pad sequence (normally pad with 0s) into the same length. Here is an illustration of padding.
大多數(如果不是全部)神經網絡都要求輸入序列數據具有相同的長度,這就是為什么我們需要填充:將序列(通常填充為0)截斷或填充為相同的長度。 這是填充的說明。
Let’s look at the following example code to perform padding in TensorFlow.
讓我們看下面的示例代碼,在TensorFlow中執行填充。
from tensorflow.keras.preprocessing.sequence import pad_sequences# before padding
print(type(train_sequences))
train_sequences
>> <class 'list'>
>> [[21, 4, 2, 12, 22, 23, 13, 2, 24, 6, 2, 7, 2, 4, 25],
[2, 26, 7, 27, 14, 9, 1, 4, 28],
[15, 25, 1, 29, 6, 15, 30],
[1, 16, 17, 27, 30, 1, 5, 2],
[31, 2, 28, 6, 32, 9, 33],
...MAX_SEQUENCE_LENGTH = 10 # length of the sequence
trainvalid_data_pre = pad_sequences(train_sequences, maxlen=MAX_SEQUENCE_LENGTH,
padding='pre',
truncating='pre',)
trainvalid_data_pre>>array([[23, 13, 2, 24, 6, 2, 7, 2, 4, 25],
[ 0, 2, 26, 7, 27, 14, 9, 1, 4, 28],
[ 0, 0, 0, 15, 25, 1, 29, 6, 15, 30],
[ 0, 0, 1, 16, 17, 27, 30, 1, 5, 2],
[ 0, 0, 0, 31, 2, 28, 6, 32, 9, 33],
...Explanation:
說明:
- Before padding, the token-represented sequences have different lengths; after padding, they are all in the same length. 在填充之前,令牌表示的序列具有不同的長度。 填充后,它們的長度都相同。
- The parameter “maxlen” defines the length of the padded sequences. When the length of the tokenized sequence is larger than the “maxlen”, the tokens of the sequence after “maxlen” would be truncated; when the length of the tokenized sequence is smaller than the “maxlen”, it would be padded with “0”. 參數“ maxlen”定義填充序列的長度。 當標記化序列的長度大于“ maxlen”時,“ maxlen”之后的序列標記將被截斷; 當標記化序列的長度小于“ maxlen”時,將用“ 0”填充。
- The positions to truncate and pad the sequence are determined by “padding=” and “truncating=”, respectively. 截斷和填充序列的位置分別由“ padding =”和“ truncating =”確定。
討論與技巧 (Discussion and tips)
Pre or post?
之前還是之后?
By default, the pad_sequences parameters are set to padding=’pre’, truncating=’pre’. However, according to TensorFlow documentation, it is recommended “using ‘post’ padding when working with RNN layers”. (It is suggested that in English, the most important information appears at the beginning. So truncating or pad sequence after can better represent the original text.) Here is the example code.
默認情況下,pad_sequences參數設置為padding ='pre',截斷='pre'。 但是,根據TensorFlow文檔 ,建議“在使用RNN圖層時使用'post'填充”。 (建議用英語將最重要的信息顯示在開頭。因此,將其截斷或填充順序可以更好地表示原始文本。)以下是示例代碼。
MAX_SEQUENCE_LENGTH = 10
trainvalid_data_post = pad_sequences(train_sequences, maxlen=MAX_SEQUENCE_LENGTH,
padding='post',
truncating='post',)
trainvalid_data_post
>>array([[21, 4, 2, 12, 22, 23, 13, 2, 24, 6],
[ 2, 26, 7, 27, 14, 9, 1, 4, 28, 0],
[15, 25, 1, 29, 6, 15, 30, 0, 0, 0],
[ 1, 16, 17, 27, 30, 1, 5, 2, 0, 0],
[31, 2, 28, 6, 32, 9, 33, 0, 0, 0],
...About maxlen.
關于麥克斯倫。
Another question is, what should be the maxlen value. The trade-off here is larger maxlen value leads to sequences that maintain more information but takes more storage space and more computationally expensive, while smaller maxlen value can save storage space but result in loss of information.
另一個問題是,maxlen值應該是多少。 這里需要權衡的是,最大maxlen值會導致序列維護更多的信息,但會占用更多的存儲空間,并且會占用更多計算量,而較小的maxlen值可以節省存儲空間,但會導致信息丟失。
- At the pipeline building stage, we can choose the mean or median as maxlen. And it works well when the lengths of sequences do not vary too much. 在管道構建階段,我們可以選擇平均值或中位數作為maxlen。 當序列的長度變化不大時,它會很好地工作。
- If the lengths of sequences vary in a big range, then it is a case-by-case decision, and some trial-and-errors are desired. e.g., for RNN architecture, we can choose a maxlen value towards the higher end (i.e., large maxlen) and utilize Masking (we will see Masking later) to mitigate storage and computation waste. Note that padding sequences with 0s will introduce noises into the model if not handled properly. It is not a very good idea to use a very large maxlen value. If you are not sure what NN architecture to use, better stick with mean or median of the unpadded sequences. 如果序列的長度在較大范圍內變化,則這是逐案決策,并且需要一些反復試驗。 例如,對于RNN架構,我們可以選擇一個較高的maxlen值(即較大的maxlen),并利用Masking(我們將在稍后看到Masking)來減輕存儲和計算浪費。 請注意,如果處理不當,填充序列為0會將噪聲引入模型。 使用很大的maxlen值不是一個好主意。 如果不確定使用哪種NN體系結構,最好堅持使用未填充序列的均值或中值。
Since we store the token sequence data in a data frame, getting sequence length stats are very straightforward, here is the example code:
由于我們將令牌序列數據存儲在數據幀中,因此獲得序列長度統計信息非常簡單,這是示例代碼:
# ckeck sequence_length stats
df_text.train_sequence.apply(lambda x: len(x))
print('sequence_length mean: ', df_text.train_sequence.apply(lambda x: len(x)).mean())
print('sequence_length median: ', df_text.train_sequence.apply(lambda x: len(x)).median())>> sequence_length mean: 9.222222222222221
>> sequence_length median: 8.5Sequence padding should be an easy piece. Let’s move on to the next step, preparing the word2vec word embeddings.
序列填充應該很容易。 讓我們繼續下一步,準備word2vec詞嵌入。
Word2vec詞嵌入 (Word2vec word embeddings)
直覺 (Intuition)
Word embeddings build the bridge between human understanding of languages and of a machine. It is essential for many NLP problems. And you might have heard the names “word2vec”, “GloVe”, and “FastText”.
單詞嵌入在人類對語言和機器的理解之間架起了橋梁。 對于許多NLP問題,這是必不可少的。 你可能聽說過的名字“ word2vec ”,“ 手套 ”和“ FastText ”。
Don’t worry if you are not familiar with word embeddings. I will give a brief introduction of word embedding that should provide enough intuition and apply word embedding in TensorFlow.
如果您不熟悉單詞嵌入,請不要擔心。 我將簡要介紹單詞嵌入,它應該提供足夠的直覺并在TensorFlow中應用單詞嵌入。
First, let’s understand some key concepts:
首先,讓我們了解一些關鍵概念:
Embedding: For the set of words in a corpus, embedding is a mapping between vector space coming from distributional representation to vector space coming from distributed representation.
嵌入 :對于語料庫中的一組單詞,嵌入是從分布表示形式到矢量空間到從分布式表示形式到矢量空間之間的映射。
Vector semantics: This refers to the set of NLP methods that aim to learn the word representations based on the distributional properties of words in a large corpus.
向量語義:這是指一組NLP方法,旨在基于大型語料庫中單詞的分布特性來學習單詞表示。
Let’s see some solid examples using spaCy’s pre-trained embedding models.
讓我們來看一些使用spaCy的預訓練嵌入模型的可靠示例。
import spacy
# if first use, download en_core_web_sm
nlp_sm = spacy.load("en_core_web_sm")
nlp_md = spacy.load("en_core_web_md")
# nlp_lg = spacy.load("en_core_web_lg")doc = nlp_sm("elephant")
print(doc.vector.size)
doc.vector
>>96
>>array([ 1.5506991 , -1.0745661 , 1.9747349 , -1.0160941 , 0.90996253,
-0.73704714, 1.465313 , 0.806101 , -4.716807 , 3.5754416 ,
1.0041305 , -0.86196965, -1.4205945 , -0.9292773 , 2.1418033 ,
0.84281194, 1.4268254 , 2.9627366 , -0.9015219 , 2.846716 ,
1.1348789 , -0.1520077 , -0.15381837, -0.6398335 , 0.36527258,
...Explanations:
說明:
- Use spaCy (a famous NLP package) to embed the word “elephant” to a 96-dimension vector. 使用spaCy(著名的NLP軟件包)將“大象”一詞嵌入到96維向量中。
- Based on which model to load, the vectors will have different dimensionality. (e.g., the dimension of “en_core_web_sm”, “en_core_web_md” and “en_core_web_lg are 96, 300, and 300, respectively.) 根據要加載的模型,向量將具有不同的維數。 (例如,“ en_core_web_sm”,“ en_core_web_md”和“ en_core_web_lg”的尺寸分別為96、300和300。)
Now the word “elephant” has been represented by a vector, so what? Don’t look away. Some magic is about to happen.🧙🏼?♂?
現在,“大象”一詞已由向量表示,那又如何呢? 不要移開視線。 一些魔術即將發生.🧙🏼?♂?
Since we can represent words using vectors, we can calculate the similarity (or distance) between words. Consider the following code.
由于我們可以使用向量表示單詞,因此我們可以計算單詞之間的相似度(或距離)。 考慮下面的代碼。
# demo1
word1 = "elephant"; word2 = "big"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )
word1 = "mouse"; word2 = "big"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )
word1 = "mouse"; word2 = "small"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )>>similariy elephant-big: 0.3589780131997766
>>similariy mouse-big: 0.17815787869074504
>>similariy mouse-small: 0.32656001719452826# demo2
word1 = "elephant"; word2 = "rock"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )
word1 = "mouse"; word2 = "elephant"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )
word1 = "mouse"; word2 = "rock"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )
word1 = "mouse"; word2 = "pebble"
print("similariy {}-{}: {}".format(word1, word2, nlp_md(word1).similarity(nlp_md(word2))) )>>similariy elephant-rock: 0.23465476998562218
>>similariy mouse-elephant: 0.3079661539409069
>>similariy mouse-rock: 0.11835070985447328
>>similariy mouse-pebble: 0.18301520085660278Comments:
注釋:
- In test1: “elephant” is more similar to “large” than “mouse” is to “large”; while “mouse” is more similar to “small” than “elephant is to “small”. This matches our common sense when referring to the usual sizes of an elephant and a mouse. 在test1中:“大象”更像“大”,而不是“鼠標”更像“大”; 而“鼠標”更類似于“小”,而不是“大象”類似于“小”。 當提到大象和老鼠的通常大小時,這符合我們的常識。
- In test2: “elephant” is less similar to “rock” than “elephant” itself to “mouse”; similarly, “mouse” is less similar to “rock” than “mouse” itself to “elephant”. This probably can be explained by both “elephant” and “mouse” are animals, while “rock” has no life. 在test2中:“大象”與“搖滾”的相似度小于“大象”本身與“鼠標”的相似度; 類似地,“鼠標”與“搖滾”的相似度小于“鼠標”本身與“大象”的相似度。 “大象”和“老鼠”都是動物,而“石頭”沒有生命,這可能可以解釋。
- The vectors in test2 not only represents the concept of liveness but also the concept of size: the word “rock” is normally used described an object that has size closer to an elephant to a mouse, thus “rock” is more similar to “elephant” than to “mouse”. Similarly, “pebble” is usually used to describe something smaller than “rock”; thus the similarity between “pebble” and “mouse” is greater than “rock” and “mouse”. test2中的向量不僅代表活潑的概念,還代表大小的概念:通常使用“巖石”一詞來描述一個對象,該對象的大小更接近于鼠標,因此,“巖石”更類似于“大象”。而不是“鼠標”。 同樣,“卵石”通常用于描述小于“巖石”的事物。 因此,“卵石”和“鼠標”之間的相似度大于“巖石”和“鼠標”。
- Note that the similarity between words might not always match the one in your head. One reason is the similarity is just a metric (i.e., a scalar) to indicate the relationship between two vectors; so much information has lost when similarity collapses the high-dimensional vectors into a scalar. Also, one word can have several meanings. e.g., the word bank can be either related to finance or rivers; without context, it is hard to say what kinds of banks we are talking about. After all, language is a concept that open to interpretation. 請注意,單詞之間的相似性可能并不總是與您頭腦中的相似。 原因之一是相似度只是表示兩個向量之間關系的度量(即標量)。 當相似度將高維向量分解為標量時,會丟失大量信息。 同樣,一個單詞可以具有多種含義。 例如,“銀行”一詞可以與金融或河流有關; 沒有上下文,很難說我們在談論哪種類型的銀行。 畢竟,語言是一個易于解釋的概念。
不要掉進兔子洞 (Don’t fall in the rabbit hole)
Word2Vec is very powerful, and it is a pretty new concept (Word2vec was created and published in 2013). There is so much more to talk about, things like
Word2Vec非常強大,它是一個相當新的概念(Word2vec于2013年創建并發布)。 還有更多要談論的東西,例如
- You may wonder how the values are assigned in the vectors. What is Skip-gram? What is CBOW? 您可能想知道如何在向量中分配值。 什么是Skip-gram? 什么是CBOW?
There are other word embedding models, like “GloVe”, and “FastText”. What is the difference? Which one(s) should we use?
還有其他的字嵌入模型,像“ 手套 ”和“ FastText ”。 有什么區別? 我們應該使用哪一個?
Word embedding is a very exciting topic, but don’t get stuck here. For readers who are new to word embeddings, the most important thing is to understand
詞嵌入是一個非常令人興奮的話題,但不要卡在這里。 對于不熟悉單詞嵌入的讀者,最重要的是要了解
- What word embeddings do: convert word to vectors. 單詞嵌入的作用是:將單詞轉換為向量。
- Why we need these embedding vectors: so that a machine can do amazing things; calculating the similarity between words is one of them, but there is definitely more. 為什么需要這些嵌入向量:機器可以做奇妙的事情; 計算單詞之間的相似度是其中之一,但肯定還有更多。
- OOV is still a problem for word embeddings. Consider the following code: OOV仍然是單詞嵌入的問題。 考慮以下代碼:
print(nlp_md("elephan")[0].has_vector)
print(nlp_md("elephan")[0].is_oov)
nlp_md("elephan").vector>>False
>>True
>>array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
....Since the word “elephan” does not exist in the spaCy “en_core_web_md” model we have loaded earlier, spaCy returns a 0-vector. Again, treating OOV is not a trivial task. But we can use either .has_vector or .is_oov to capture the OOV phenomenon.
由于在我們之前加載的spaCy“ en_core_web_md”模型中不存在單詞“ elephan”,因此spaCy返回0向量。 再次,對待OOV不是一件容易的事。 但是我們可以使用.has_vector或.is_oov來捕獲OOV現象。
Hopefully, you have a pretty good understanding of word embedding now. Let’s come back to the main track and see how we can apply word embeddings in the pipeline.
希望您現在對單詞嵌入有了很好的理解。 讓我們回到主要軌道,看看如何在管道中應用單詞嵌入。
采用預先訓練的詞嵌入模型 (Adopt a pre-trained word embeddings model)
Pretrained Word Embeddings are the embeddings learned in one task that is used for solving another similar task. A pre-trained word embedding model is also called a transformer. Using a pre-trained word embedding models can save us the trouble to train one from scratch. Also, the fact that the pre-trained embedding vectors are generated from a large dataset usually leads to stronger generative capability.
預訓練詞嵌入是在一項任務中學習的嵌入,用于解決另一項相似任務。 預訓練的詞嵌入模型也稱為轉換器。 使用預訓練的詞嵌入模型可以節省我們從頭訓練一個詞的麻煩。 同樣,從大型數據集生成預訓練嵌入向量的事實通常會導致更強大的生成能力。
To apply a pre-trained word embedding model is a bit like searching in a dictionary, and we have seen such a process earlier using spaCy. (e.g., input the word “elephant” and spaCy returned an embedding vector. ) At the end of this step, we will create an “embedding matrix” with embedding vectors associated with each token. (The embedding matrix is what TensorFlow will use to connect a token sequence with the word embedding representation.)
應用預訓練的單詞嵌入模型有點像在字典中搜索,并且我們早些時候已經使用spaCy看到了這樣的過程。 (例如,輸入單詞“ elephant”,spaCy返回一個嵌入向量。)在此步驟的最后,我們將創建一個“嵌入矩陣”,其中包含與每個令牌關聯的嵌入向量。 (嵌入矩陣是TensorFlow用來將令牌序列與單詞嵌入表示連接的東西。)
Here is the code.
這是代碼。
# import pandas as pd
# nlp_sm = spacy.load("en_core_web_sm")
df_index_word = pd.Series(tokenizer.index_word)
# df_index_word
df_index_word_valid = df_index_word[:MAX_NUM_TOKENS-1]
df_index_word_valid = pd.Series(["place_holder"]).append(df_index_word_valid)
df_index_word_valid = df_index_word_valid.reset_index()
# df_index_word_valid.head()
df_index_word_valid.columns = ['token_id', 'token']
# df_index_word_valid.head()
df_index_word_valid['word2vec'] = df_index_word_valid.token.apply(lambda x: nlp_sm(x).vector)
df_index_word_valid['is_oov'] = df_index_word_valid.token.apply(lambda x: nlp_sm(x)[0].is_oov)
df_index_word_valid.at[0, "word2vec"] = np.zeros_like(df_index_word_valid.at[0, "word2vec"])
print(df_index_word_valid.head())>>
token_id token word2vec is_oov
0 0 NAN [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, ... True
1 1 the [-1.3546131, -1.7212939, 1.7044731, -2.8054314... True
2 2 a [-1.9769197, -1.5778058, 0.116705105, -2.46210... True
3 3 and [-2.8375597, 0.8632377, -0.69991976, -0.508865... True
4 4 of [-2.7217283, -2.1163979, -0.88265955, -0.72048... True# Embbeding matrix
embedding_matrix = np.array([vec for vec in df_index_word_valid.word2vec.values])
embedding_matrix[1:3]print(embedding_matrix.shape)
>>(50, 96)Explanation:
說明:
- We first used spaCy to find embedding vectors associated with each token (stored in a data frame). With some data wrangling, we created an embedding matrix (with TensorFlow convention, stored in np.array this time). 我們首先使用spaCy查找與每個令牌相關聯的嵌入向量(存儲在數據幀中)。 經過一些數據處理,我們創建了一個嵌入矩陣(使用TensorFlow約定,這次存儲在np.array中)。
- Rows of the embedding matrix: the total number of rows is 50, with the first row holds a zero-vector representing empty tokens, and the rest 50–1 tokens are the chosen tokens in the tokenization step. (Soon, you will see why we put a zero-vector at the first row in the next session when we set up an Embedding layer.) 嵌入矩陣的行數:總行數為50,第一行包含一個零向量,表示空令牌,其余50–1個令牌是在令牌化步驟中選擇的令牌。 (很快,您將看到為什么在設置嵌入層時在下一個會話的第一行中放置零向量的原因。)
- Columns of the embedding matrix: The word2vec dimensionality is 96 (when using “en_core_web_sm”), so the number of columns is 96. 嵌入矩陣的列:word2vec的維數是96(使用“ en_core_web_sm”時),因此列數是96。
Here we have the embedding matrix (i.e., a 2-d array) with the shape of (50, 96). This embedding matrix will be fed into TensorFlow embedding layers in the last step of this NLP model preparation pipeline.
這里我們有形狀為(50,96)的嵌入矩陣(即二維數組)。 在此NLP模型準備流程的最后一步中,此嵌入矩陣將被輸入到TensorFlow嵌入層中。
NOTES: You might notice that all the is_oov values are True. But you will still get non-zero embedding vectors. This happens using the spaCy “en_core_web_sm” model.
注意:您可能會注意到所有is_oov值均為True。 但是您仍然會得到非零的嵌入向量。 使用spaCy“ en_core_web_sm”模型會發生這種情況。
提示:如何在單詞嵌入中處理OOV (Tips: how to treat OOV in word embeddings)
Unlike “en_core_web_md”, which returns a zero-vector when the token is not in the embedding model, the way how “en_core_web_sm” works will make it always return some non-zero vectors. However, according to the spaCy documentary, the vectors returned by “en_core_web_sm” are not “as precise as” larger models like “en_core_web_md” or “en_core_web_lg”.
與“ en_core_web_md”(當令牌不在嵌入模型中時會返回零向量)不同,“ en_core_web_sm”的工作方式將使其始終返回一些非零向量。 但是,根據spaCy紀錄片 ,“ en_core_web_sm”返回的向量不如“ en_core_web_md”或“ en_core_web_lg”等較大模型精確。
Depends on the application, it is your decision to choose the “not-very-precise” embedding model but always give non-zero vectors or models return “more precise” vectors but sometimes zero-vectors when seeing OOVs.
取決于應用程序,您決定選擇“不是非常精確”的嵌入模型,但始終給出非零向量,或者模型在看到OOV時返回“更精確”向量,但有時返回零向量。
In the demo, I’ve chosen the “en_core_web_sm” model that always gives me some non-zero embedding vectors. A strategy could be by using vectors learned for subword fragments during training, similar to how people can often work out the gist of a word from familiar word-roots. Some people call this strategy “better something-not-precise than nothing-at-all”. (Though I am not sure how spaCy assigns non-zero values to OOVs.)
在演示中,我選擇了“ en_core_web_sm”模型,該模型始終為我提供一些非零的嵌入向量。 一種策略可以是通過使用在訓練期間為子詞片段學習的向量,類似于人們通常如何從熟悉的詞根中找出詞的要旨。 有人將此策略稱為“勝于所有,而不是精確”。 (盡管我不確定spaCy如何將非零值分配給OOV。)
最后,嵌入層設置 (Finally, Embedding layer setups)
So far, we have the padded token sequence to represent the original text data. Also, we have created an embedding matrix with each row associated with the tokens. Now it is time to set up the TensorFlow Embedding layers.
到目前為止,我們已經有了填充令牌序列來表示原始文本數據。 此外,我們還創建了一個嵌入矩陣,每一行都與令牌關聯。 現在是時候設置TensorFlow嵌入層了。
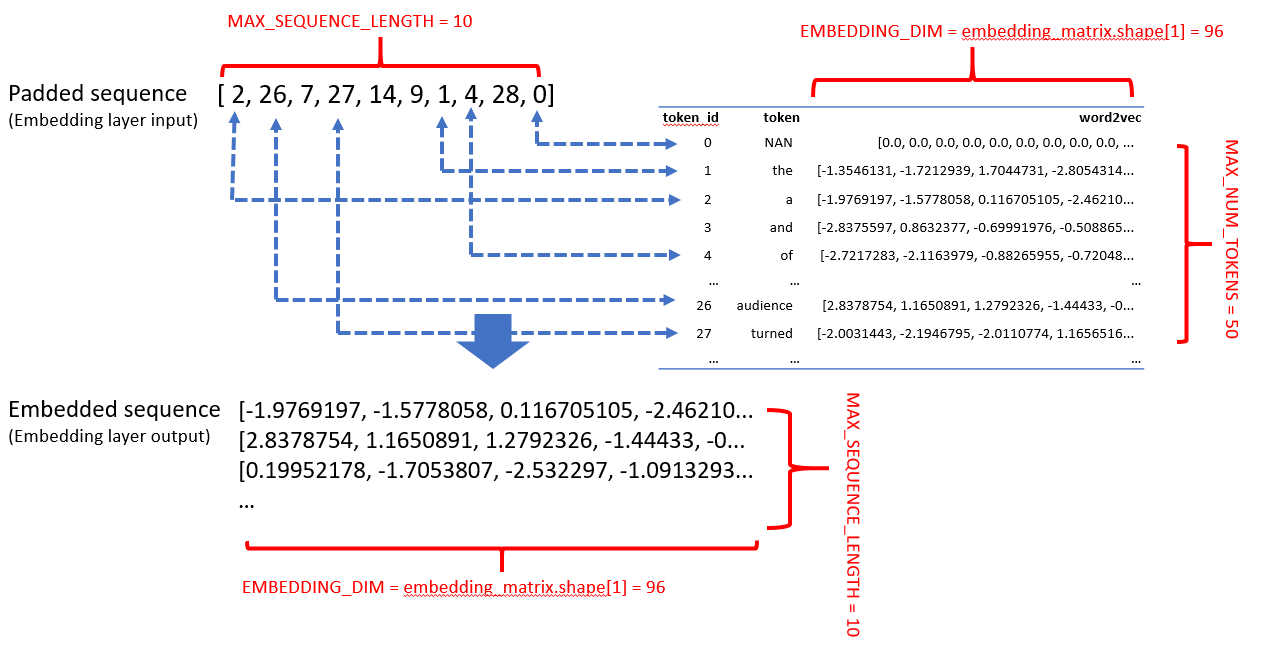
The Embedding layer mechanism is summarized in the following illustration.
下圖概述了嵌??入層機制。
Explanation:
說明:
Embedding layer builds the bridge between the token sequences (as input) and the word embedding representation (as output) through an embedding matrix (as weights).
嵌入層通過嵌入矩陣(作為權重)在令牌序列(作為輸入)和詞嵌入表示(作為輸出)之間建立橋梁。
Input of an Embedding layer: the padded sequence is fed in as input to the Embedding layer; each position of the padded sequence is designated to a token-id.
嵌入層的輸入 :將填充的序列作為輸入輸入到嵌入層; 填充序列的每個位置都指定一個令牌ID。
Weights of an Embedding layer: by looking up into the embedding matrix, the Embedding layer can find the word2vec representation of words(tokens) associated with the token-id. Note that padded sequence use zeros to indicate empty tokens resulting zero-embedding-vectors. That’s why we have saved the first row in the embedding matrix for the empty tokens.
嵌入層的權重 :通過查看嵌入矩陣,嵌入層可以找到與令牌ID相關聯的單詞(令牌)的word2vec表示形式。 請注意,填充序列使用零表示空令牌,從而產生零嵌入向量。 這就是為什么我們將第一行保存在空令牌的嵌入矩陣中。
Output of an Embedding layer: After going through the input padded sequences, the Embedding layer “replaces” the token-id with representative vectors(word2vec) and output embedded sequences.
嵌入層的輸出 :經過輸入的填充序列后,嵌入層用代表性向量(word2vec)“替換”令牌ID,并輸出嵌入序列。
Notes: The key to modern NLP feature extraction: If everything works, the output of the embedding layers should represent well of the original text, with all the features storing in the word embedding weights; this is the key idea of modern NLP feature extraction. You will see very soon, we can fine-tune this weights by setting trainable=True for embedding layers.
注意:現代NLP特征提取的關鍵: 如果一切正常,則嵌入層的輸出應很好地代表原始文本,所有特征都存儲在詞嵌入權重中; 這是現代NLP特征提取的關鍵思想。 您很快就會看到,我們可以通過設置trainable = True嵌入圖層來微調此權重。
Also note that, in this example, we explicitly specify the empty token’s word2vec as zero just for demonstration purposes. In fact, once the Embedding layer sees the 0-token-id, it will immediately assign a zero-vector to that position without looking into the embedding matrix.
還要注意,在此示例中,僅出于演示目的,我們將空令牌的word2vec明確指定為零。 實際上,一旦嵌入層看到0令牌ID,它將立即向該位置分配零向量,而無需查看嵌入矩陣。
在TensorFlow中 (In TensorFlow)
The following example code shows how embedding is done In TensorFlow,
以下示例代碼顯示了如何在TensorFlow中完成嵌入,
from tensorflow.keras.initializers import Constant
from tensorflow.keras.layers import Embedding# MAX_NUM_TOKENS = 50
EMBEDDING_DIM = embedding_matrix.shape[1]
# MAX_SEQUENCE_LENGTH = 10
embedding_layer = Embedding(input_dim=MAX_NUM_TOKENS,
output_dim=EMBEDDING_DIM,
embeddings_initializer=Constant(embedding_matrix),
input_length=MAX_SEQUENCE_LENGTH,
mask_zero=True,
trainable=False)Explanation:
說明:
- the dimensionality-related parameters are “input_dim”, “output_dim”, and “input_length”. You should have a good intuition of how to set up these parameters by referring to the illustration. 與維度相關的參數是“ input_dim”,“ output_dim”和“ input_length”。 通過參考插圖,您應該對如何設置這些參數有很好的認識。
When using a pre-trained word embedding model, we need to use tensorflow.keras.initializers.Constant to feed the embedding matrix into an Embedding layer. Otherwise, the weights of the embedding layers will be initialized with some random numbers, referring to as “training word embeddings from scratch”.
當使用預訓練詞嵌入模型時,我們需要使用tensorflow.keras.initializers.Constant將嵌入矩陣輸入到嵌入層中。 否則,將使用一些隨機數來初始化嵌入層的權重,這稱為“從頭開始訓練單詞嵌入”。
trainable=is set to False in this example, so that the weight of word2vec will not change during neural network training. This helps to prevent overfitting, especially when training on a relatively small dataset. But if you want to fine-tune the weights, you know what to do. (settrainable=True)在此示例中,
trainable=設置為False,因此word2vec的權重在神經網絡訓練期間不會改變。 這有助于防止過度擬合,尤其是在相對較小的數據集上進行訓練時。 但是,如果您想微調重量,您就會知道該怎么做。 (設置trainable=True)mask_zero=is another argument you should pay attention to. Masking is a way to tell sequence-processing layers that certain positions in an input are missing, and thus should be skipped when processing the data.” By setting the parametermask_zero=True, it not only speeds up the training but also gives a better representation of the original text.mask_zero=是您應注意的另一個參數。 屏蔽是一種告訴序列處理層輸入中某些位置丟失的方法,因此在處理數據時應將其跳過。” 通過設置mask_zero=True參數,不僅可以加快訓練速度,而且可以更好地表示原始文本。
We can check the output of the Embedding layer using a test case. The output Tensor of the Embedding layer should be in the shape [num_sequence, padded_sequence_length, embedding_vector_dim].
我們可以使用測試用例檢查Embedding層的輸出。 嵌入層的輸出張量應為[num_sequence,papped_sequence_length,embedding_vector_dim]形狀。
# output
embedding_output = embedding_layer(trainvalid_data_post)
# result = embedding_layer(inputs=trainvalid_data_post[0])
embedding_output.shape>>TensorShape([18, 10, 96])# check if tokens and embedding vectors mathch
print(trainvalid_data_post[1])
embedding_output[1]>>[21 4 2 12 22 23 13 2 24 6]
>><tf.Tensor: shape=(10, 96), dtype=float32, numpy=
array([[-1.97691965e+00, -1.57780576e+00, 1.16705105e-01,
-2.46210432e+00, 1.27643692e+00, 4.56989884e-01,
...
[ 2.83787537e+00, 1.16508913e+00, 1.27923262e+00,
-1.44432998e+00, -7.07145482e-02, -1.63411784e+00,
...And that’s it. You are ready to train your text data. (You can refer to the notebook to see training using RNN and CNN.)
就是這樣。 您已準備好訓練文本數據。 (您可以參考筆記本查看使用RNN和CNN進行的培訓。)
摘要 (Summary)
We have been through a long way to prepare data for NLP deep learning. Use the following checklist to test your understanding:
我們已經為NLP深度學習準備了很長的路要走。 使用以下清單來測試您的理解:
Tokenization: train on a corpus to create a token dictionary and represent the original text with tokens (or token-ids) by referring to the token dictionary created. In TensorFlow, we can use Tokenizer for tokenization.
令牌化:訓練語料庫以創建令牌字典,并通過引用創建的令牌字典來用令牌(或令牌ID)表示原始文本。 在TensorFlow中,我們可以使用Tokenizer進行令牌化。
- Preprocessing is often required in the tokenization process. While using Tensorflow’ s Tokenizer with its default settings helps to start the pipeline, it is almost always recommended to perform advanced preprocessing and/or postprocessing during tokenization. 在標記化過程中通常需要進行預處理。 雖然使用Tensorflow的Tokenizer及其默認設置有助于啟動管道,但幾乎始終建議在標記化過程中執行高級預處理和/或后處理。
- Out-of-vocabulary (OOV) is a common issue for tokenization. Potential solutions include training on a larger corpus or use a pre-trained tokenizer. 詞匯外(OOV)是令牌化的常見問題。 可能的解決方案包括在較大的語料庫上進行培訓,或使用預先訓練的令牌生成器。
- In the TensorFlow convention, 0-token-id is reserved to empty-tokens, while other NLP packages might assign tokens to 0-token-id. Watch out such confliction and adjust the token-id namings if desired. 在TensorFlow約定中,0-token-id保留給空令牌,而其他NLP軟件包可能將令牌分配給0-token-id。 注意這種沖突,并根據需要調整令牌ID的命名。
Padding: pad or truncate sequences to the same length, i.e., the padded sequences have the same number of tokens (including empty-tokens). In TensorFlow, we can use pad_sequences for padding.
填充:將序列填充或截短到相同的長度,即,填充的序列具有相同數量的令牌(包括空令牌)。 在TensorFlow中,我們可以使用pad_sequences進行填充。
- It is recommended to pad and truncate sequence after (set to “post”) for RNN architecture. 對于RNN體系結構,建議在之后填充和截斷序列(設置為“ post”)。
- The padded sequence length can be set to be the mean or median of the sequences before padding (or truncating). 填充序列的長度可以設置為填充(或截斷)之前序列的平均值或中間值。
Word embeddings: the tokens can be mapped to vectors by referring to an embedding model, e.g., word2vec. The embedding vectors possess information that both humans and a machine can understand. We can use spaCy “en_core_web_sm”, “en_core_web_md”, or “en_core_web_lg” for word embeddings.
詞嵌入:可以通過引用嵌入模型(例如word2vec)將令牌映射到向量。 嵌入向量擁有人類和機器都可以理解的信息。 我們可以使用spaCy“ en_core_web_sm”,“ en_core_web_md”或“ en_core_web_lg”進行詞嵌入。
- It is a good start to use pre-trained word embeddings models. There is no need to find the “perfect” pre-trained word embeddings model; just take one, to begin with. Since Tensorflow doesn’t have a word embeddings API yet, choose a package that can be applied easily in the deep learning pipeline. At this stage, it is more important to build the pipeline than achieve better performance. 使用預先訓練的詞嵌入模型是一個良好的開端。 無需找到“完美”的預訓練詞嵌入模型; 一開始就可以。 由于Tensorflow還沒有單詞嵌入API,因此選擇一個可以輕松應用于深度學習管道的軟件包。 在此階段,構建管道比獲得更好的性能更為重要。
- OOV is also an issue for word embeddings using pre-trained models. A potential solution to treat OOV is by using vectors learned for subword fragments during training. If available, such “guess” usually give better results than using zero-vectors for OOVs, which brings noise into the model. 對于使用預訓練模型的詞嵌入,OOV也是一個問題。 一種潛在的解決OOV的方法是在訓練過程中使用針對子詞片段學習的向量。 如果可用,這種“猜測”通常會比為OOV使用零向量提供更好的結果,這會給模型帶來噪聲。
Embedding layer in TensorFlow: to take advantage of the pre-trained word embeddings, the inputs of an Embedding layer in TensorFlow include padded sequences represented by token-ids, and an embedding matrix that stores embedding vectors associated with the tokens within the padded sequences. The output is a 3-d tensors with the shape of [num_sequence, padded_sequence_length, embedding_vector_dim].
TensorFlow中的嵌入層:為了利用預訓練的詞嵌入,TensorFlow中Embedding層的輸入包括由令牌ID表示的填充序列,以及一個存儲與填充序列中與令牌關聯的嵌入向量的嵌入矩陣。 輸出是具有[num_sequence,padded_sequence_length,embedding_vector_dim]形狀的3-d張量。
- There are many parameter settings for the Embedding layer. Use a toy dataset to make sure Embedding layers’ behavior matches your understanding. Special attention should be given to the shapes of the input and output tensors. 嵌入層有許多參數設置。 使用玩具數據集確保嵌入層的行為符合您的理解。 應特別注意輸入和輸出張量的形狀。
- We can fine-tune the embedding matrix by setting trainable=True. 我們可以通過設置trainable = True來微調嵌入矩陣。
- By setting mask_zero=True, it can speed up the training. Also, it is a better representation of the original text, especially when using RNN-type architecture. e.g., the machine will skip the zero-data and maintain the associated weight as 0s no matter what, even with trainable=True. 通過設置mask_zero = True,可以加快訓練速度。 同樣,它是原始文本的更好表示,尤其是在使用RNN類型的體系結構時。 例如,即使使用trainable = True,機器無論如何都將跳過零數據并保持關聯的權重為0。
I hope you like this post. See you next time.
希望您喜歡這篇文章。 下次見。
參考: (reference:)
Practical Natural Language Processing: A Comprehensive Guide to Building Real-world Nlp Systems-Oreilly & Associates Inc (2020)
實用的自然語言處理:構建實際Nlp系統的綜合指南-Oreilly&Associates Inc(2020)
Natural Language Processing in Action: Understanding, analyzing, and generating text with Python-Manning Publications (2019)
行動中的自然語言處理:使用Python-Manning出版物理解,分析和生成文本(2019)
Deep Learning with Python-Manning Publications (2018)
使用Python-Manning出版物進行深度學習(2018)
翻譯自: https://towardsdatascience.com/hands-on-nlp-deep-learning-model-preparation-in-tensorflow-2-x-2e8c9f3c7633
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392419.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392419.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392419.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


異步api_如何設計無服務器異步API

C# 序列化與反序列化json

學java 的要點_零基礎學Java,掌握Java的基礎要點

實驗人員考評指標_了解實驗指標
)
leetcode 188. 買賣股票的最佳時機 IV(dp)

kotlin編寫后臺_在Kotlin編寫圖書館的提示

1.Swift教程翻譯系列——關于Swift
)
核心技術java基礎_JAVA核心技術I---JAVA基礎知識(集合set)

nba數據庫統計_NBA板塊的價值-從統計學上講
)
leetcode 330. 按要求補齊數組(貪心算法)

【煉數成金 NOSQL引航 三】 Redis使用場景與案例分析

SQL Server需要監控哪些計數器 ---指尖流淌

akka 簡介_Akka HTTP路由簡介
)
leetcode 1046. 最后一塊石頭的重量(堆)

java2d方法_Java SunGraphics2D.fillRect方法代碼示例

js建立excel表格_建立Excel足球聯賽表格-傳統vs動態數組方法

postman+newman生成html報告

java jdk1.9新特性_JDK1.9-新特性
