Note: The methodology behind the approach discussed in this post stems from a collaborative publication between myself and Irene Anthi.
注意: 本文討論的方法背后的方法來自 我本人和 Irene Anthi 之間 的 合作出版物 。
介紹 (INTRODUCTION)
Spam SMS text messages often show up unexpectedly on our phone screens. That’s aggravating enough, but it gets worse. Whoever is sending you a spam text message is usually trying to defraud you. Most spam text messages don’t come from another phone. They often originate from a computer and are delivered to your phone via an email address or an instant messaging account.
垃圾短信經常在我們的手機屏幕上意外顯示。 這足夠令人討厭,但情況變得更糟。 誰向您發送垃圾短信通常是在欺騙您。 大多數垃圾短信不是來自其他手機。 它們通常來自計算機,并通過電子郵件地址或即時消息傳遞帳戶傳遞到您的手機。
There exists several security mechanisms for automatically detecting whether an email or an SMS message is spam or not. These approaches often rely on machine learning. However, the introduction of such systems may also be subject to attacks.
存在幾種用于自動檢測電子郵件或SMS消息是否為垃圾郵件的安全機制。 這些方法通常依賴于機器學習。 但是,引入此類系統也可能會受到攻擊。
The act of deploying attacks towards machine learning based systems is known as Adversarial Machine Learning (AML). The aim is to exploit the weaknesses of the pre-trained model which may have “blind spots” between the data points it has seen during training. More specifically, by automatically introducing slight perturbations to the unseen data points, the model may cross a decision boundary and classify the data as a different class. As a result, the model’s effectiveness can significantly be reduced.
向基于機器學習的系統部署攻擊的行為稱為對抗機器學習(AML)。 目的是利用預訓練模型的弱點,該弱點在訓練過程中看到的數據點之間可能有“盲點”。 更具體地,通過自動向看不見的數據點引入輕微的擾動,模型可以越過決策邊界并將數據分類為不同的類別。 結果,該模型的有效性會大大降低。
In the context of SMS spam detection, AML can be used to manipulate textual data by including perturbations to cause spam data to be classified as being not spam, consequently bypassing the detector.
在SMS垃圾郵件檢測的上下文中,AML可以通過包含擾動來操縱文本數據,從而使垃圾郵件數據被歸類為非垃圾郵件,從而繞過檢測器,從而可以操縱文本數據。
數據集和數據預處理 (DATASET AND DATA PRE-PROCESSING)
The SMS Spam Collection is a set of SMS tagged messages that have been collected for SMS spam research. It contains a set of 5,574 English SMS text messages which are tagged according to whether they are spam (425 message) or not-spam (3,375).
SMS垃圾郵件收集是已收集用于SMS垃圾郵件研究的一組SMS標記郵件。 它包含一組5574條英文SMS文本消息,這些消息根據是垃圾郵件(425條消息)還是非垃圾郵件(3375條)進行了標記。
Let’s first cover the pre-processing techniques we need to consider before we dive into applying any kind of machine learning techniques. We’ll perform pre-processing techniques that are standard for most Natural Language Processing (NLP) problems. These include:
首先,我們將介紹在應用任何類型的機器學習技術之前需要考慮的預處理技術。 我們將執行大多數自然語言處理(NLP)問題的標準預處理技術。 這些包括:
- Convert the text to lowercase. 將文本轉換為小寫。
- Remove punctuation. 刪除標點符號。
- Remove additional white space. 刪除其他空格。
- Remove numbers. 刪除數字。
- Remove stop words such as “the”, “a”, “an”, “in”. 刪除停用詞,例如“ the”,“ a”,“ an”,“ in”。
- Lemmatisation. 合法化。
- Tokenisation. 令牌化。
Python’s Natural Language Tool Kit (NLTK) can handle these pre-processing requirements. The output should now look something to the following:
Python的自然語言工具包(NLTK)可以處理這些預處理要求。 現在,輸出應類似于以下內容:
詞嵌入 (WORD EMBEDDINGS)
Word embedding is one of the most popular representation of text vocabulary. It is capable of capturing the context of a word in a document, its semantic and syntactic similarity to its surrounding words, and its relation with other words.
詞嵌入是最流行的文本詞匯表示形式之一。 它能夠捕獲文檔中單詞的上下文,與周圍單詞的語義和句法相似性以及與其他單詞的關系。
But how are word embeddings captured in context? Word2Vec is one of the most popular technique to learn word embeddings using a two-layer Neural Network. The Neural Network takes in the corpus of text, analyses it, and for each word in the vocabulary, generates a vector of numbers that encode important information about the meaning of the word in relation to the context in which it appears.
但是如何在上下文中捕獲單詞嵌入呢? Word2Vec是使用兩層神經網絡學習單詞嵌入的最流行技術之一。 神經網絡接受文本的語料庫,對其進行分析,然后為詞匯表中的每個單詞生成一個數字矢量,該矢量編碼有關單詞含義與單詞出現上下文相關的重要信息。
There are two main models: the Continuous Bag-of-Words model and the Skip-gram model. The Word2Vec Skip-gram model is a shallow Neural Network with a single hidden layer that takes in a word as input and tries to predict the context of the words that surround it as an output.
有兩個主要模型:連續詞袋模型和Skip-gram模型。 Word2Vec跳過語法模型是一個淺層神經網絡,具有單個隱藏層,該隱藏層將單詞作為輸入,并嘗試預測圍繞它的單詞的上下文作為輸出。
In this case, we will be using Gensim’s Word2Vec for creating the model. Some of the important parameters are as follows:
在這種情況下,我們將使用Gensim的Word2Vec創建模型。 一些重要參數如下:
- size: The number of dimensions of the embeddings. The default is 100. size:嵌入的尺寸數。 默認值為100。
- window: The maximum distance between a target word and the words around the target word. The default window is 5. 窗口:目標詞與目標詞周圍的詞之間的最大距離。 默認窗口是5。
- min_count: The minimum count of words to consider when training the model. Words with occurrence less than this count will be ignored. The default min_count is 5. min_count:訓練模型時要考慮的最小單詞數。 出現次數少于此次數的單詞將被忽略。 默認的min_count為5。
- workers: The number of partitions during training. The default workers is 3. 工人:培訓期間的分區數。 默認工作線程為3。
- sg: The training algorithm, either Continuous Bag-of-Words (0) or Skip-gram (1). The default training algorithm is Continuous Bag-of-Words. sg:訓練算法,連續單詞袋(0)或跳過語法(1)。 默認的訓練算法是“連續詞袋”。
Next, we’ll see how to use the Word2Vec model to generate the vector for the documents in the dataset. Word2Vec vectors are generated for each SMS message in the training data by traversing through the dataset. By simply using the model on each word of the text messages, we retrieve the word embedding vectors for those words. We then represent a message in the dataset by calculating the average over all of the vectors of words in the text.
接下來,我們將看到如何使用Word2Vec模型為數據集中的文檔生成向量。 通過遍歷數據集,為訓練數據中的每個SMS消息生成Word2Vec向量。 通過簡單地在文本消息的每個單詞上使用模型,我們檢索了這些單詞的單詞嵌入向量。 然后,我們通過計算文本中所有單詞向量的平均值來表示數據集中的一條消息。
模型訓練和分類 (MODEL TRAINING AND CLASSIFICATION)
Let’s first encode our target labels spam and not_spam. This involves converting the categorical values to numerical values. We’ll then assign the features to the variable X and the target labels to the variable y. Lastly, we’ll split the pre-processed data into two datasets.
首先讓我們對目標標簽spam和not_spam進行編碼。 這涉及將分類值轉換為數值。 然后,我們將要素分配給變量X ,將目標標簽分配給變量y 。 最后,我們將預處理后的數據分為兩個數據集。
Train dataset: For training the SMS text categorisation model.
訓練數據集:用于訓練SMS文本分類模型。
Test dataset: For validating the performance of the model.
測試數據集:用于驗證模型的性能。
To split the data into 2 such datasets, we’ll use Scikit-learn’s train test split method from the model selection function. In this case, we’ll split the data into 70% training and 30% testing.
要將數據分為兩個這樣的數據集,我們將使用Scikit-learn的模型選擇功能中的訓練測試拆分方法 。 在這種情況下,我們會將數據分為70%的訓練和30%的測試。
For the sake of this post, we’ll use a Decision Tree classifier. In reality, you’d want to evaluate a variety of classifiers using cross-validation to determine which is the best performing. The “no free lunch” theorem suggests that there is no universally best learning algorithm. In other words, the choice of an appropriate algorithm should be based on its performance for that particular problem and the properties of data that characterise the problem.
為了這篇文章的緣故,我們將使用Decision Tree分類器。 實際上,您想使用交叉驗證來評估各種分類器,以確定哪個是性能最好的分類器。 “沒有免費的午餐”定理表明,沒有普遍適用的最佳學習算法。 換句話說,適當算法的選擇應基于針對特定問題的性能以及表征該問題的數據的屬性。
Once the model is trained, we can evaluate its performance when it tries to predict the target labels of the test set. The classification report shows that the model can predict the test samples with a high weighted-average F1-score of 0.94.
訓練模型后,我們可以在嘗試預測測試集的目標標簽時評估其性能。 分類報告顯示,該模型可以預測具有0.94的高加權平均F1分數的測試樣本。
生成對抗性樣本 (GENERATING ADVERSARIAL SAMPLES)
A well known use case of AML is in image classification. This involves adding noise that may not be perceptible to the human eye which also fools the classifier.
AML的一個眾所周知的用例是圖像分類。 這涉及增加人眼無法察覺的噪聲,這也會使分類器蒙蔽。
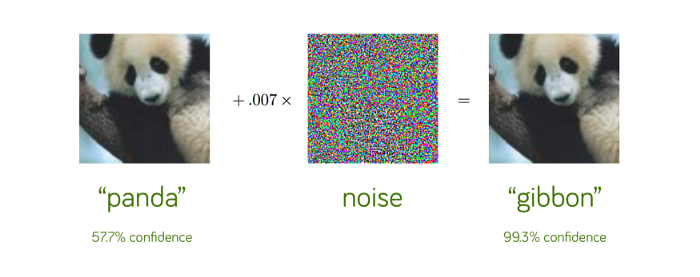
There are various methods by which adversarial samples can be generated. Such methods vary in complexity, the speed of their generation, and their performance. An unsophisticated approach towards crafting such samples is to manually perturb the input data points. However, manual perturbations are slow to generate and evaluate by comparison with automatic approaches.
有多種方法可以生成對抗性樣本。 此類方法的復雜性,生成速度和性能各不相同。 制作此類樣本的簡單方法是手動擾動輸入數據點。 但是,與自動方法相比,手動擾動的生成和評估速度較慢。
One of the most popular technique towards automatically generating perturbed samples include the Jacobian-based Saliency Map Attack (JSMA). The methods rely on the methodology, that when adding small perturbations to the original sample, the resulting sample can exhibit adversarial characteristics in that the resulting sample is now classified differently by the targeted model.
自動生成擾動樣本的最流行技術之一是基于雅可比的顯著性圖攻擊(JSMA)。 該方法依賴于該方法,即在向原始樣本添加較小擾動時,所得樣本可以表現出對抗性特征,因為所得樣本現在通過目標模型進行了不同分類。
The JSMA method generates perturbations using saliency maps. A saliency map identifies which features of the input data are the most relevant to the model decision being one class or another; these features, if altered, are most likely affect the classification of the target values. More specifically, an initial percentage of features (gamma) is chosen to be perturbed by a (theta) amount of noise. Then, the model establishes whether the added noise has caused the targeted model to misclassify or not. If the noise has not affected the model’s performance, another set of features is selected and a new iteration occurs until a saliency map appears which can be used to generate an adversarial sample.
JSMA方法使用顯著圖生成擾動。 顯著性圖標識輸入數據的哪些特征與一個或另一個類別的模型決策最相關; 這些功能(如果更改)很可能會影響目標值的分類。 更具體地說,特征的初始百分比(γ)被選擇為被θ量的噪聲所干擾。 然后,模型確定添加的噪聲是否導致目標模型分類錯誤。 如果噪聲沒有影響模型的性能,則選擇另一組特征并進行新的迭代,直到出現顯著圖,該顯著圖可用于生成對抗性樣本。
A pre-trained MLP is used as the underlying model for the generation of adversarial samples. Here, we explore how different combinations of the JSMA parameters affect the performance of the originally trained Decision Tree.
預先訓練的MLP用作對抗性樣本生成的基礎模型。 在這里,我們探索JSMA參數的不同組合如何影響最初訓練的決策樹的性能。
評價 (EVALUATION)
To explore how different combinations of the JSMA parameters affect the performance of the trained Decision Tree, adversarial samples were generated from all spam data points present in the testing data by using a range of combinations of gamma and theta. The adversarial samples were then joined with the non-spam testing data points and presented to the trained model. The heat map reports the overall weighted-average F1-scores for all adversarial combinations of JSMA’s gamma and theta parameters.
為了探究JSMA參數的不同組合如何影響經過訓練的決策樹的性能,使用一系列伽瑪和theta組合從測試數據中存在的所有垃圾郵件數據點生成了對抗樣本。 然后將對抗性樣本與非垃圾郵件測試數據點合并,并提供給訓練有素的模型。 該熱圖報告了JSMA的γ和theta參數的所有對抗性組合的總體加權平均F1得分。
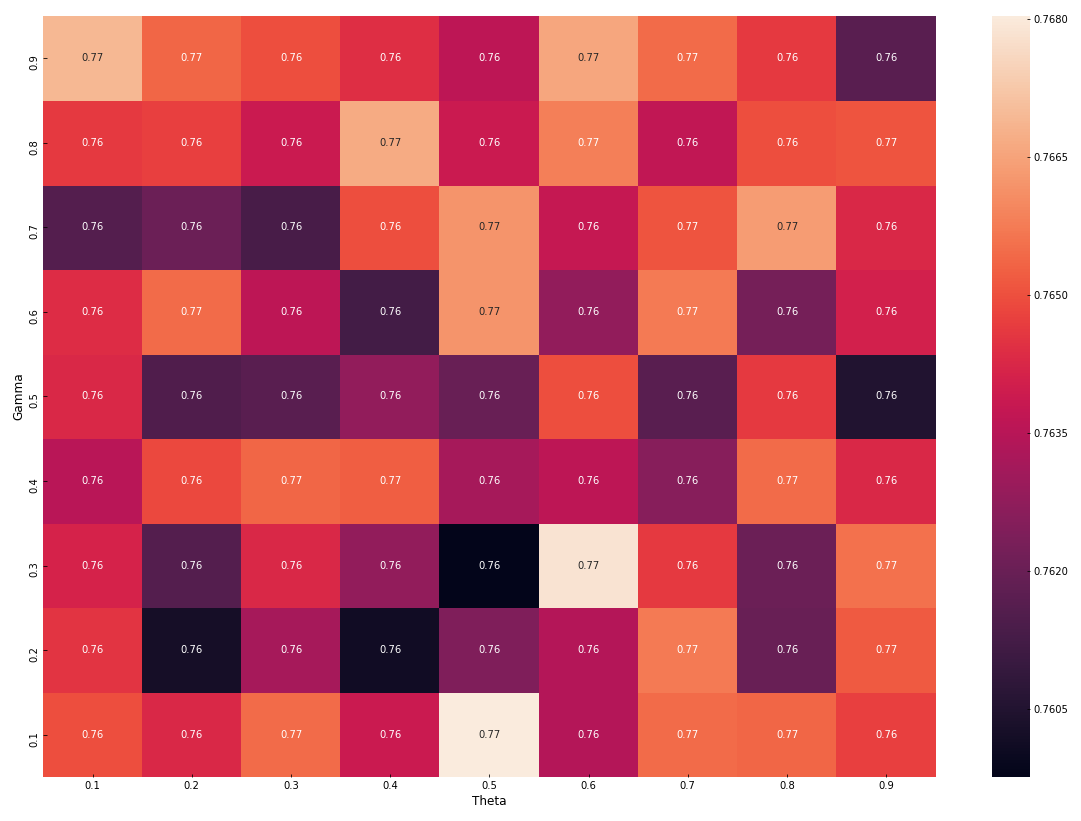
The classification performance of the Decision Tree model achieved a decrease in F1-scores across all of the gamma and theta parameters. When gamma= 0.3, theta= 0.5, the model’s classification performance decreased by 18 percentage points (F1-score = 0.759). In this case, based on this dataset, gamma= 0.3, theta= 0.5 would be the optimal parameter one would use to successfully reduce the accuracy of a machine learning based SMS spam detector.
決策樹模型的分類性能在所有gamma和theta參數上的F1得分均下降。 當gamma = 0.3,theta = 0.5時,模型的分類性能下降了18個百分點(F1分數= 0.759)。 在這種情況下,基于此數據集,gamma = 0.3,theta = 0.5將是用于成功降低基于機器學習的SMS垃圾郵件檢測器準確性的最佳參數。
結論 (CONCLUSION)
So, what have I learnt from this analysis?
那么,我從這項分析中學到了什么?
Due to their effectiveness and flexibility, machine learning based detectors are now recognised as fundamental tools for detecting whether SMS text messages are spam or not. Nevertheless, such systems are vulnerable to attacks that may severely undermine or mislead their capabilities. Adversarial attacks may have severe consequences in such infrastructures, as SMS texts may be modified to bypass the detector.
由于它們的有效性和靈活性,基于機器學習的檢測器現在被認為是檢測SMS文本消息是否為垃圾郵件的基本工具。 但是,這樣的系統容易受到攻擊的攻擊,這些攻擊可能會嚴重破壞或誤導其功能。 在這種基礎架構中,對抗性攻擊可能會帶來嚴重后果,因為可以修改SMS文本以繞過檢測器。
The next steps would be to explore how such samples can support the robustness of supervised models using adversarial training. This entails including adversarial samples into the training dataset, re-training the model, and evaluating its performance on all adversarial combinations of JSMA’s gamma and theta parameters.
下一步將是探索這些樣本如何使用對抗訓練來支持監督模型的魯棒性。 這需要將對抗性樣本包括到訓練數據集中,重新訓練模型,并在JSMA的γ和theta參數的所有對抗性組合上評估其性能。
For the full notebook, check out my GitHub repo below: https://github.com/LowriWilliams/SMS_Adversarial_Machine_Learning
對于完整的筆記本,請在下面查看我的GitHub存儲庫: https : //github.com/LowriWilliams/SMS_Adversarial_Machine_Learning
翻譯自: https://towardsdatascience.com/adversarial-attacks-on-sms-spam-detectors-12b16f1e748e
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392296.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392296.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392296.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

php pdo 緩沖,PDO支持數據緩存_PHP教程

mooc課程下載_如何使用十大商學院的免費課程制作MOOC“ MBA”
)
leetcode 1584. 連接所有點的最小費用(并查集)

Nagios學習實踐系列

在Salesforce中處理Email的發送

kvm vnc的使用,鼠標漂移等

php深淺拷貝,JavaScript 中的深淺拷貝

使用Python進行地理編碼和反向地理編碼

java開發簡歷編寫_如何通過幾個簡單的步驟編寫出色的初級開發人員簡歷
)
leetcode 628. 三個數的最大乘積(排序)
![[Object-C語言隨筆之三] 類的創建和實例化以及函數的添加和調用!](http://pic.xiahunao.cn/[Object-C語言隨筆之三] 類的創建和實例化以及函數的添加和調用!)
[Object-C語言隨筆之三] 類的創建和實例化以及函數的添加和調用!

2024-AI人工智能學習-安裝了pip install pydot但是還是報錯

grafana 創建儀表盤_創建儀表盤前要問的三個問題

qq群 voiceover_如何在iOS上使用VoiceOver為所有人構建應用程序
)
IntelliJ IDEA代碼常用的快捷鍵(自查)
)
leetcode 1489. 找到最小生成樹里的關鍵邊和偽關鍵邊(并查集)
)
帶彩色字體的man pages(debian centos)

提取json對象中的數據,轉化為數組

java 同步塊的鎖是什么,java – 同步塊 – 鎖定多個對象
