We have to represent every bit of data in numerical values to be processed and analyzed by machine learning and deep learning models. However, strings do not usually come in a nice and clean format and require a lot preprocessing.
我們必須以數值表示數據的每一位,以便通過機器學習和深度學習模型進行處理和分析。 但是,字符串通常不會采用簡潔的格式,并且需要大量預處理。
Pandas provides numerous functions and methods to process textual data. In this post, we will focus on data types for strings rather than string operations. Using appropriate data types is the first step to make most out of Pandas. There are currently two data types for textual data, object and StringDtype.
熊貓提供了多種功能和方法來處理文本數據。 在本文中,我們將重點介紹字符串的數據類型,而不是字符串操作。 使用適當的數據類型是充分利用Pandas的第一步。 當前,文本數據有兩種數據類型: object和StringDtype。
Before pandas 1.0, only “object” datatype was used to store strings which cause some drawbacks because non-string data can also be stored using “object” datatype. Pandas 1.0 introduces a new datatype specific to string data which is StringDtype. As of now, we can still use object or StringDtype to store strings but in the future, we may be required to only use StringDtype.
在pandas 1.0之前,僅使用“對象”數據類型來存儲字符串,這會導致一些缺點,因為非字符串數據也可以使用“對象”數據類型來存儲。 Pandas 1.0引入了特定于字符串數據的新數據類型StringDtype 。 到目前為止,我們仍然可以使用object或StringDtype來存儲字符串,但是將來,可能會要求我們僅使用StringDtype。
One important thing to note here is that object datatype is still the default datatype for strings. To use StringDtype, we need to explicitly state it.
這里要注意的一件事是對象數據類型仍然是字符串的默認數據類型。 要使用StringDtype,我們需要明確聲明它。

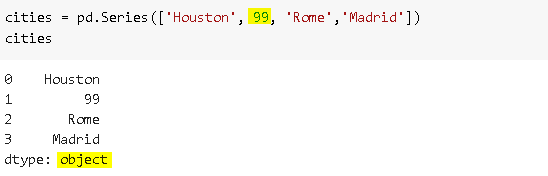
We can pass “string” or pd.StringDtype() argument to dtype parameter to select string datatype.
我們可以將“ string ”或pd.StringDtype()參數傳遞給dtype參數以選擇字符串數據類型。

We can also convert from “object” to “string” data type using astype function:
我們還可以使用astype函數將“ object”數據類型轉換為“ string”數據類型:

Although the default type is “object”, it is recommended to use “string” for a few reasons.
盡管默認類型為“對象”,但出于一些原因,建議使用“字符串”。
- Object data type has a broader scope and allows to store pretty much anything. Thus, even if we have non-strings in a place that is supposed to be a string, we don’t get any error. 對象數據類型的范圍更廣,可以存儲幾乎所有內容。 因此,即使我們在應該是字符串的地方放置了非字符串,也不會出現任何錯誤。
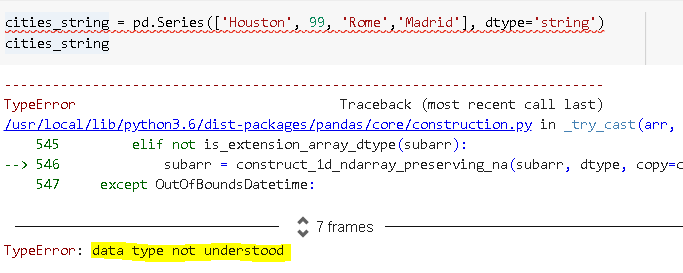
- It is always better to have a dedicated data type. For instance, if we try to the example above with “string” data type, we get a TypeError. 最好使用專用的數據類型。 例如,如果我們嘗試上面的示例使用“字符串”數據類型,則會得到TypeError。
Having a dedicated data type allows for data type specific operations. For instance, we cannot use select_dtypes to choose only text columns if “object” data type is used. Select_dtypes(include=”object”) will return any column with object data type. On the other hand, if we use “string” data type for textual data, select_dtypes(include=”string”) will give just what we need.
具有專用數據類型允許進行特定于數據類型的操作。 例如,如果使用“對象”數據類型,則不能使用select_dtypes僅選擇文本列。 Select_dtypes(include =“ object”)將返回任何具有對象數據類型的列。 另一方面,如果我們對文本數據使用“字符串”數據類型,則select_dtypes(include =“ string”)會滿足我們的需求。
“String” data type is not superior to “object” in terms of performance as of now. However, it is expected, with future enhancements, the performance of “string” data type will be increased and the memory consumption will be decreased. Thus, we should already be using “string” instead of “object” for textual data.
到目前為止,就性能而言,“字符串”數據類型并不優于“對象”。 但是,可以預料,隨著將來的增強,“字符串”數據類型的性能將得到提高,內存消耗將減少。 因此,我們應該已經在文本數據中使用“字符串”而不是“對象”。
Thank you for reading. Please let me know if you have any feedback.
感謝您的閱讀。 如果您有任何反饋意見,請告訴我。
翻譯自: https://towardsdatascience.com/why-we-need-to-use-pandas-new-string-dtype-instead-of-object-for-textual-data-6fd419842e24
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392143.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392143.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392143.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

遞歸方程組解的漸進階的求法——代入法

【轉載】C# 理解泛型

javascript 作用_JavaScript承諾如何從內到外真正發揮作用

linux 文件理解,對linux中文件系統的理解
)
編譯原理—語法分析器(Java)

老筆記整理四:字符串的完美度

nlp構建_使用NLP構建自殺性推文分類器


Elastic Stack 安裝

區塊鏈去中心化分布式_為什么漸進式去中心化是區塊鏈的最大希望
)
編譯原理—語義分析(Java)


linux vi行尾總是顯示顏色,【轉載】Linux 下使用 vi 沒有顏色的解決辦法

時間序列分析 lstm_LSTM —時間序列分析

關于計算圓周率PI的經典程序
)
華為產品技術學習筆記之路由原理(一)

Linux網絡配置:設置IP地址、網關DNS、主機名
高級語言分析器前端(Java))
編譯原理—小型(簡化)高級語言分析器前端(Java)
簡介)
linux boot菜單列表,Bootstrap 下拉菜單(Dropdowns)簡介
