數據可視化簡介 (Introduction to Data Visualization)
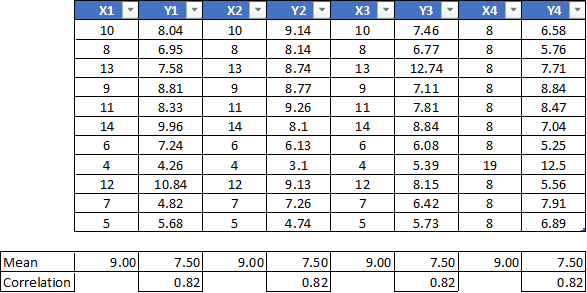
Data visualization is the process of creating interactive visuals to understand trends, variations, and derive meaningful insights from the data. Data visualization is used mainly for data checking and cleaning, exploration and discovery, and communicating results to business stakeholders. Most of the data scientists pay little attention to graphs and focuses only on the numerical calculations which at times can be misleading. To understand the importance of visualization let’s take a look at Anscombe’s Data Quartet in Figures 1 and 2 below.
數據可視化是創建交互式視覺效果以了解趨勢,變化并從數據中獲得有意義的見解的過程。 數據可視化主要用于數據檢查和清理,探索和發現以及將結果傳達給業務涉眾。 大多數數據科學家很少關注圖形,而只關注于有時會引起誤解的數值計算。 為了理解可視化的重要性,讓我們在下面的圖1和圖2中查看Anscombe的Data Quartet。
The same data points, when represented using visualization in Figure 2 below, depicts a different trend altogether.
當使用下面的圖2中的可視化表示相同的數據點時,它們總共描述了不同的趨勢。

It is important to visualize the data before any calculations are carried out. The visual representation can convey much more information when compared to descriptive statistics.
在執行任何計算之前,對數據進行可視化非常重要。 與描述性統計數據相比,視覺表示可以傳達更多的信息。
數據可視化的作用 (Role of Data Visualization)
Multiple Business Intelligence Tools (BI) are currently ruling the market with each having its pros and cons. The concept of self-service dashboards was devised to allow stakeholders with little or no knowledge of data science, work independently on data, and derive some findings that might assist their day to day business decisions. We will look at some of the applications of data visualization using Tableau or Python in the examples below.
目前,多種商業智能工具(BI)統治著市場,每種都有其優缺點。 自助服務儀表板的概念旨在使幾乎不了解數據科學或根本不了解數據科學的利益相關者,獨立地處理數據并得出一些有助于其日常業務決策的發現。 在下面的示例中,我們將介紹一些使用Tableau或Python進行數據可視化的應用程序。
數據檢查與清理 (Data Checking and Cleaning)
Data visualization can be used to look for obvious errors in the dataset including nulls, random values, distinct records, the format of dates, sensibility of spatial data, and string and character encoding.
數據可視化可用于查找數據集中的明顯錯誤,包括空值,隨機值,不同的記錄,日期格式,空間數據的敏感性以及字符串和字符編碼。

資料分配 (Data Distribution)
Data visualization can be used to understand the distribution of the data, look for central tendencies (mean, median, and mode), understand the presence of outliers using a boxplot, check for skewness, and ever understand the impact of winsorization on data distribution. Figure 4 below illustrates how box plots can be developed to understand the presence of outliers.
數據可視化可用于了解數據的分布,尋找中心趨勢(均值,中位數和眾數),使用箱線圖了解異常值,檢查偏斜度,以及了解Winsorization對數據分布的影響。 下面的圖4說明了如何繪制箱形圖以了解異常值的存在。

模型假設 (Model Assumptions)
Linear regression and other classification models follow certain underlying assumptions like data has to be normally distributed, the correlation between different independent variables shouldn’t exist, homoscedasticity of error terms, and many more. Hence visualizations are a key to validating some of these assumptions as well.
線性回歸和其他分類模型遵循某些基本假設,例如數據必須正態分布,不應該存在不同自變量之間的相關性,誤差項的均方差等等。 因此,可視化也是驗證其中一些假設的關鍵。

人在環分析 (Human-in-the-Loop Analytics)
Data scientists often use humans in the loop analytics to get a look and feel of the data, make a hypothesis, run appropriate analytics to validate the hypothesis, and repeat the process till conclusive evidence is determined. E.g. in Python a very popular package Seaborn has a function called pair plot. Pair plots are very useful in determining the relationship between dependent and independent variables. The idea of the visualization is to get a better understanding of the directional sense of if some of the independent variables impact the model results or not.
數據科學家經常在循環分析中使用人工來獲得數據的外觀和感覺,做出假設,運行適當的分析以驗證假設,并重復該過程直到確定結論性證據為止。 例如,在Python中,一個非常受歡迎的軟件包Seaborn具有一個稱為結對圖的函數。 配對圖對于確定因變量和自變量之間的關系非常有用。 可視化的想法是更好地理解方向性,即某些自變量是否影響模型結果。

降維 (Dimension Reduction)
While working with multiple variables it is difficult to visualize the data in an n-dimension space. E.g. in a data set that has different customer attributes (say numerical) it is difficult to plot the customers considering all attributes. In scenarios like this, dimension reduction techniques like Principal Component Analysis (PCA) or Factor Analysis can be useful to bring down the attributes to fewer dimensions. PCA finds linear combinations of variables that best explain the observations whereas Factor analysis finds linear combinations of variables that best explain the relationship between the variables. The reduced dimension can then be plotted to analyze the customers in a 2D space.
使用多個變量時,很難在n維空間中可視化數據。 例如,在具有不同客戶屬性(例如數字)的數據集中,很難考慮所有屬性來繪制客戶。 在這種情況下,降維技術(例如主成分分析(PCA)或因子分析)可用于將屬性降低到更少的維度。 PCA找到最能解釋觀測結果的變量線性組合,而因子分析則找到最能解釋變量之間關系的變量線性組合。 然后可以繪制縮小的尺寸以分析2D空間中的客戶。
More information on how to recreate these charts in Python can be found here.
可在此處找到有關如何在Python中重新創建這些圖表的更多信息。
分析問題中的數據集類型 (Type of Datasets in Analytical Problems)
It is important to understand the type of datasets to determine the type of visualization that can be applied. E.g. when working with a tabular data a combination of bar graphs and line charts might be useful when compared to spatial data where a map with a density plot might communicate the result effectively. Before we take a deeper look into the type of visualization let’s understand some of the key data types that are commonly used.
重要的是了解數據集的類型,以確定可以應用的可視化類型。 例如,當與表格數據一起使用時,與空間數據相比,條形圖和折線圖的組合可能會很有用,在空間數據中,帶有密度圖的地圖可能會有效地傳達結果。 在深入研究可視化類型之前,讓我們了解一些常用的關鍵數據類型。
表格數據 (Tabular data)
Data organized in tables, a row for each data item, and a column for each of its attributes. E.g. Datasets that are available in Excel, CSV files, Pandas data frame, etc.
數據組織在表格中,每個數據項一行,其每個屬性列。 例如,Excel,CSV文件,Pandas數據框等中可用的數據集。
網絡數據 (Network data)
Nodes in the network are data items and links between the nodes are relations between. For example a social network.
網絡中的節點是數據項,節點之間的鏈接是它們之間的關系。 例如社交網絡。
空間數據: (Spatial data:)
Data which is naturally organized and understood in terms of its spatial location or extent. E.g. latitude and longitude of locations, geography information, suburbs, streets, etc.
根據空間位置或范圍自然組織和理解的數據。 例如,位置,地理信息,郊區,街道等的緯度和經度。
文字數據: (Textual data:)
This kind of data set consists of sequences of words and punctuation. E.g. twitter feed or customer complaints.
這種數據集由單詞和標點的序列組成。 例如Twitter提要或客戶投訴。
視覺詞匯 (Visual Vocabulary)
The figures below provide a picture of how different visualizations can be used to depict different scenarios in the data.
下圖提供了如何使用不同的可視化圖像描述數據中不同場景的圖片。




You can find examples of other visualizations here.
您可以在此處找到其他可視化示例。
跨數據類型的可視化效果 (Effectiveness of Visualization across Data Types)
The table below displays the effectiveness of different visuals across data types. To understand the table better we need to have a better understanding of how variables (attributes from the data) can be categorized into different data types. Categorical variables are the ones that don’t have any ordering e.g. Gender, Grades, Marital Status, Job Position, etc. Numerical Variables are segmented into Ordinal and Quantitative variables. Ordinal variables are categories that can be ranked. E.g. Satisfaction (Good, Bad, and Average), Potential (High, Medium, and Low), etc. Quantitative variables are the ones that can take any range of numeric values between -infinity to +infinity. E.g. Age, Salary, Revenue, Sales, etc.
下表顯示了跨數據類型的不同視覺效果的有效性。 為了更好地理解表,我們需要更好地了解如何將變量(來自數據的屬性)歸類為不同的數據類型。 分類變量是沒有任何排序的變量 ,例如性別,等級,婚姻狀況,工作職位等。 數字變量分為序數 變量和定量變量。 有序變量是可以排序的類別。 例如,滿意度(好,壞和平均),潛力(高,中和低)等。 定量變量是可以采用-infinity到+ infinity之間任意數值范圍的變量 。 例如年齡,薪水,收入,銷售等


結論 (Conclusion)
Data visualization forms the backbone of all analytical projects. It not only helps in gaining insights into the data but can be used as a tool for data pre-processing. Having the right set of visualizations for different data types and business scenarios is the key to effective communication of results.
數據可視化構成所有分析項目的基礎。 它不僅有助于獲得對數據的見解,而且可以用作數據預處理的工具。 為不同的數據類型和業務場景提供正確的可視化設置是有效傳達結果的關鍵。
About the Author: Advanced analytics professional and management consultant helping companies find solutions for diverse problems through a mix of business, technology, and math on organizational data. A Data Science enthusiast, here to share, learn and contribute; You can connect with me on Linked and Twitter;
作者簡介:高級分析專家和管理顧問,通過組織數據的業務,技術和數學相結合,幫助公司找到各種問題的解決方案。 數據科學愛好者,在這里分享,學習和貢獻; 您可以在 Linked 和 Twitter上 與我 聯系 ;
翻譯自: https://towardsdatascience.com/data-visualization-in-data-science-5681cbdde5bf
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391926.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391926.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391926.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
的兩個模式)
打針小說軟件測試,UPDATE注射(mysql+php)的兩個模式

前端速成班_在此速成班中學習Go
css-loader詳細使用說明)
手把手教你webpack3(6)css-loader詳細使用說明

shell遠程執行命令

Python調用C語言

多重線性回歸 多元線性回歸_了解多元線性回歸

tp703n怎么做無線打印服務器,TP-Link TL-WR703N無線路由器無線AP模式怎么設置

unity 克隆_使用Unity開發Portal游戲克隆
)
swift基礎學習(八)

pandas之groupby分組與pivot_table透視

js能否打印服務器端文檔,js打印遠程服務器文件

spring—JdbcTemplate使用

vanilla_如何在Vanilla JavaScript中操作DOM

NOIP201202尋寶

修改UITextField中的placeholder的字體

如何使用Python處理丟失的數據

MySQL—隔離級別

做虛擬化服務器的配資一致嘛,服務器虛擬化技術在校園網管理中的應用探討.pdf...

aws中部署防火墻_如何在AWS中設置自動部署
