azure第一個月
Luuk van der Velden and Rik Jongerius
盧克·范德·費爾登(Luuk van der Velden)和里克 ·瓊格里烏斯( Rik Jongerius)
目標 (Goal)
MLOps seeks to deliver fresh and reliable AI products through continuous integration, continuous training and continuous delivery of machine learning systems. When new data becomes available, we update the AI model and deploy it (if improved) with DevOps practices. Azure DevOps pipelines support such practices and is our platform of choice. AI or Machine Learning is however focused around AzureML, which has its own pipeline and artifact system. Our goal is to combine DevOps with AzureML pipelines in an end-to-end solution. We want to continuously train models and conditionally deploy them on our infrastructure and applications. More specifically, our goal is to continuously update a PyTorch model running within an Azure function.
MLOps尋求通過持續集成,持續培訓和持續交付機器學習系統來交付新鮮且可靠的AI產品。 當有新數據可用時,我們將更新AI模型,并通過DevOps實踐進行部署(如果有改進)。 Azure DevOps管道支持此類做法,并且是我們的首選平臺。 但是,AI或機器學習的重點是AzureML ,它具有自己的管道和工件系統。 我們的目標是在端到端解決方案中將DevOps與AzureML管道結合起來。 我們希望不斷訓練模型并將其有條件地部署到我們的基礎架構和應用程序中。 更具體地說,我們的目標是不斷更新在Azure函數中運行的PyTorch模型。
解決方案概述 (Solution overview)
The following diagram shows our target solution. Three triggers are shown at the top. Changes to the infrastructure-as-code triggers the Terraform infrastructure pipeline. Changes to the Python code of the function triggers the Azure function deploy pipeline. Finally, new data on a schedule triggers the model training pipeline, which does a conditional deploy of the function with the new model if it performs better.
下圖顯示了我們的目標解決方案。 頂部顯示三個觸發器。 對基礎架構即代碼的更改觸發了Terraform基礎架構管道。 對函數的Python代碼的更改將觸發Azure函數部署管道。 最后,時間表上的新數據會觸發模型訓練管道,如果新模型性能更好,則有條件地使用新模型進行功能部署。

1個DevOps基礎架構管道 (1 DevOps infrastructure pipeline)
Within a DevOps pipeline we can organize almost any aspect of the Azure cloud. They allow repeatable and reproducible infrastructure and application deployment. Some of the key features are:
在DevOps管道中,我們幾乎可以組織Azure云的任何方面。 它們允許可重復和可復制的基礎架構和應用程序部署。 一些關鍵功能包括:
- Support to automate almost all Azure Services 支持自動化幾乎所有Azure服務
- Excellent secret management 出色的秘密管理
- Integration with Azure DevOps for team collaboration and planning 與Azure DevOps集成以進行團隊協作和規劃
1.1管道作業,步驟和任務 (1.1 Pipeline jobs, steps and tasks)
DevOps pipelines are written in YAML and have several possible levels of organization: stages, jobs, steps. Stages consist of multiple jobs and jobs consist of multiple steps. Here we focus on jobs and steps. Each job can include a condition for execution and each of its steps contains a task specific to a certain framework or service. For instance, a Terraform task to deploy infrastructure or an Azure KeyVault task to manage secrets. Most tasks need a service connection linked to our Azure subscription to be allowed to access and alter our resources. In our case, we appropriate the authentication done by the Azure CLI task to run Python scripts with the right credentials to interact with our AzureML workspace.
DevOps管道使用YAML編寫,具有幾種可能的組織級別:階段,作業,步驟。 階段包含多個作業,而作業包含多個步驟。 在這里,我們專注于工作和步驟。 每個作業都可以包含執行條件,并且每個步驟都包含特定于某個框架或服務的任務。 例如,用于部署基礎結構的Terraform任務或用于管理機密的Azure KeyVault任務 。 大多數任務需要鏈接到我們的Azure訂閱的服務連接,才能訪問和更改我們的資源。 在我們的案例中,我們使用由Azure CLI任務完成的身份驗證來運行具有正確憑據的Python腳本,以與我們的AzureML工作區進行交互。
1.2基礎架構即代碼 (1.2 Infrastructure as code)
There are good arguments to use tools such as Terraform and Azure Resource Manager to manage our infrastructure, which we will try not to repeat here. Important for us, these tools can be launched repeatedly from our DevOps pipeline and always lead to the same resulting infrastructure (idempotence). So, we can launch the infrastructure pipeline often not only when there are changes to the infrastructure-as-code. We use Terraform to manage our infrastructure, which requires the appropriate service connection.
使用Terraform和Azure資源管理器之類的工具來管理我們的基礎結構有很多理由,我們將在這里不再贅述。 對我們而言重要的是,這些工具可以從我們的DevOps管道中反復啟動,并始終導致相同的基礎架構(冪等)。 因此,我們不僅可以在對基礎架構代碼進行更改的情況下,經常啟動基礎架構管道。 我們使用Terraform來管理我們的基礎架構,這需要適當的服務連接。
The following Terraform definition (Code 1) will create a function app service with its storage account and Standard app service plan. We have included it as the documented Linux example did not work for us. For full serverless benefits we were able to deploy on a consumption plan (elastic), but the azurerm provider for Terraform seems to have an interfering bug that prevented us from including it here. For brevity, we did not include the DevOps pipelines steps for applying Terraform and refer to the relevant documentation.
以下Terraform定義(代碼1)將使用其存儲帳戶和標準應用程序服務計劃創建功能應用程序服務。 我們將其包括在內,因為已記錄的Linux示例對我們不起作用。 為了獲得無服務器的全部收益,我們可以在使用計劃(彈性)上進行部署,但是Terraform的azurerm提供程序似乎存在一個干擾性錯誤,使我們無法在其中包含它。 為簡便起見,我們沒有包括應用Terraform的DevOps管道步驟,而是參考相關文檔 。
# Code 1: terraform function app infrastructure
resource "azurerm_storage_account" "torch_sa" {
name = "sa-function-app"
resource_group_name = data.azurerm_resource_group.rg.name
location = data.azurerm_resource_group.rg.location
account_tier = "Standard"
account_replication_type = "LRS"
}resource "azurerm_app_service_plan" "torch_asp" {
name = "asp-function-app"
location = data.azurerm_resource_group.rg.location
resource_group_name = data.azurerm_resource_group.rg.name
kind = "Linux"
reserved = truesku {
tier = "Standard"
size = "S1"
}
}resource "azurerm_function_app" "torch" {
name = "function-app"
location = data.azurerm_resource_group.rg.location
resource_group_name = data.azurerm_resource_group.rg.name
storage_account_name = azurerm_storage_account.torch_sa.name
storage_account_access_key = azurerm_storage_account.torch_sa.primary_access_key
app_service_plan_id = azurerm_app_service_plan.torch_asp.id
storage_connection_string =
os_type = "linux"
version = "~3"
app_settings = {
FUNCTIONS_EXTENSION_VERSION = "~3"
FUNCTIONS_WORKER_RUNTIME = "python"
FUNCTIONS_WORKER_RUNTIME_VERSION = "3.8"
APPINSIGHTS_INSTRUMENTATIONKEY = "<app_insight_key>"
}
site_config {
linux_fx_version = "PYTHON|3.8"
}
}2 AzureML管道 (2 AzureML pipeline)
AzureML is one of the ways to do data science on Azure, besides Databricks and the legacy HDInsight cluster. We use the Python SDK for AzureML to create and run our pipelines. Setting up an AzureML development environment and running of training code on AMLCompute targets I explain here. In part 2 of that blog I describe the AzureML Environment and Estimator, which we use in the following sections. The AzureML pipeline combines preprocessing with estimators and allows data transfer with PipelineData objects.
除Databricks和舊版HDInsight群集外,AzureML是在Azure上進行數據科學的方法之一。 我們使用適用于AzureML的Python SDK創建和運行我們的管道。 設置AzureML開發環境并在AMLCompute目標上運行訓練代碼,我在這里進行解釋。 在該博客的第2部分中,我描述了AzureML環境和估計器,我們將在以下各節中使用它們。 AzureML管道將預處理與估計器結合在一起,并允許通過PipelineData對象進行數據傳輸。
Some benefits are:
一些好處是:
- Reproducible AI 可重現的AI
- Reuse data pre-processing steps 重用數據預處理步驟
- Manage data dependencies between steps 管理步驟之間的數據依存關系
- Register AI artifacts: model and data versions 注冊AI工件:模型和數據版本
2.1管道創建和步驟 (2.1 Pipeline creation and steps)
Our Estimator wraps a PyTorch training script and passes command line arguments to it. We add an Estimator to the pipeline by wrapping it with the EstimatorStep class (Code 2).
我們的估算器包裝了一個PyTorch訓練腳本,并將命令行參數傳遞給它。 通過將EstimatorStep類(代碼2)包裝起來,可以將Estimator添加到管道中。
# Code 2: wrap estimator in pipeline step
from azureml.core import Workspace
from azureml.pipeline.steps import EstimatorStep
from tools import get_compute
from model import train_estimator
workspace = Workspace.from_config()
model_train_step = EstimatorStep(
name="train model",
estimator=train_estimator,
estimator_entry_script_arguments=[],
compute_target=get_compute(workspace, CLUSTER_NAME),
)To create an AzureML pipeline we need to pass in the Experiment context and a list of steps to run in sequence (Code 3). The goal of our current Estimator is to register an updated model with the AzureML workspace.
若要創建AzureML管道,我們需要傳遞“實驗”上下文和按順序運行的步驟列表(代碼3)。 當前的Estimator的目標是向AzureML工作區注冊更新的模型。
# Code 3: create and run azureml pipeline
from azureml.core import Experiment, Workspace
from azureml.pipeline.core import Pipelinedef run_pipeline():
workspace = Workspace.from_config()
pipeline = Pipeline(
workspace=workspace,
steps=[model_train_step, model_evaluation_step]
)
pipeline_run = Experiment(
workspace, EXPERIMENT_NAME).submit(pipeline)
pipeline_run.wait_for_completion()2.2模型工件 (2.2 Model artifacts)
PyTorch (and other) models can be serialized and registered with the AzureML workspace with the Model class. Registering a model uploads it to centralized blob storage and allows it to be published wrapped in a Docker container to Azure Docker instances and Azure Kubernetes Service. We wanted to keep it simple and treat the AzureML model registration as an artifact storage. Our estimator step loads an existing PyTorch model and trains it on the newly available data. This updated model is registered under the same name every time the pipeline runs (code 4). The model version is auto incremented. When we retrieve our model without specifying a version it will grab the latest version. With each model iteration we decide whether we want to deploy the latest version.
可以使用Model類將PyTorch(及其他)模型序列化并注冊到AzureML工作區中。 注冊模型會將其上傳到集中式Blob存儲,并允許將其包裝在Docker容器中發布到Azure Docker實例和Azure Kubernetes服務。 我們希望保持簡單,將AzureML模型注冊視為工件存儲。 我們的估算器步驟會加載現有的PyTorch模型,并在新的可用數據上對其進行訓練。 每次管道運行時,此更新的模型都以相同的名稱注冊(代碼4)。 型號版本自動增加。 當我們檢索模型而未指定版本時,它將獲取最新版本。 每次模型迭代時,我們都會決定是否要部署最新版本。
# Code 4: inside an azureml pipeline step
import torch
from azureml.core import RunMODEL_PATH = "./outputs/model.p"updated_model = train_model(model, data)
torch.save(updated_model, MODEL_PATH)run_context = Run.get_context()
run_context.upload_file(model_path, model_path)run_context.register_model(
model_name="pytorch_model",
model_path=model_path,
description=f"updated model: {run_context.run_id}",
)3結合AzureML和DevOps管道 (3 Combining AzureML and DevOps pipelines)
3.1以DevOps管道為中心的架構 (3.1 DevOps pipeline centric architecture)
In our approach to MLOps / Continuous AI the DevOps pipeline is leading. It has better secrets management and broader capabilities than the AzureML pipeline. When new data is available the DevOps pipeline starts the AzureML pipeline and waits for it to finish with a conditional decision whether to deploy the model. This decision is based on the performance of the model compared to the previous best model. We schedule the model DevOps pipeline at regular intervals when new data is expected using the cron trigger.
在我們的MLOps /連續AI方法中,DevOps管道處于領先地位。 與AzureML管道相比,它具有更好的秘密管理和更廣泛的功能。 當有新數據可用時,DevOps管道將啟動AzureML管道并等待其完成,并附有條件決定是否部署模型。 該決策基于與之前最佳模型相比模型的性能。 當使用cron觸發器期望新數據時,我們會定期調度模型DevOps管道。
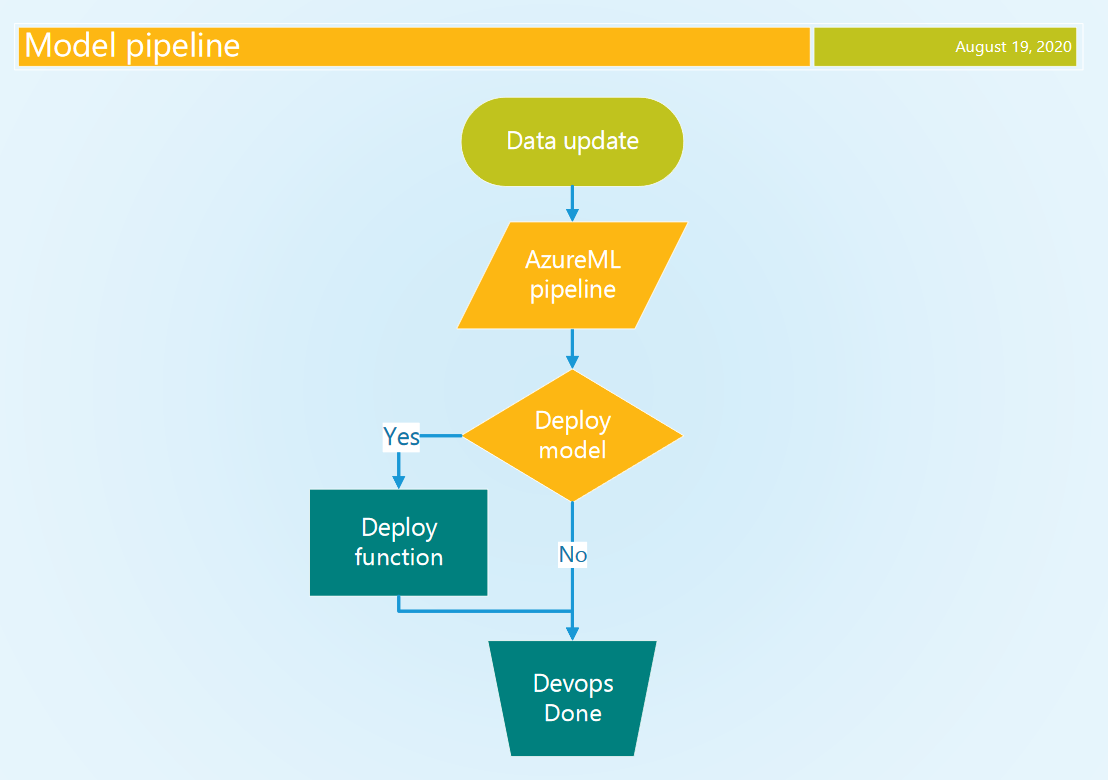
3.2從DevOps啟動AzureML (3.2 Launching AzureML from DevOps)
An Azure CLI task authenticates the task with our service connection, which has access to our AzureML Workspace. This access is used by the Python script to create the Workspace and Experiment context to allow us to run the Pipeline using the AzureML SDK. We wait for the AzureML pipeline to complete, with a configurable timeout. The overall DevOps timeout is 2 hours. The implications of this are discussed at the end of the blog. A basic Python script is shown (Code 5) that starts the AzureML pipeline from Code 3.
Azure CLI任務通過我們的服務連接對任務進行身份驗證,該服務連接可以訪問我們的AzureML工作區。 Python腳本使用此訪問權限來創建工作區和實驗上下文,以允許我們使用AzureML SDK運行管道。 我們等待AzureML管道完成,并且具有可配置的超時。 DevOps的總體超時為2小時。 博客末尾討論了其含義。 顯示了一個基本的Python腳本(代碼5),該腳本從代碼3啟動AzureML管道。
# Code 5: calling our run function form Code 3
from aml_pipeline.pipeline import run_pipelinerun_pipeline()This script is launched from an AzureCLI task (Code 6) for the required authentication. Note: It is not ideal that we need an account with rights on the Azure subscription level to interact with AzureML even for the most basic operations, such as downloading a model.
此腳本從AzureCLI任務(代碼6)啟動,用于所需的身份驗證。 注意:甚至對于最基本的操作(例如下載模型),我們都需要一個具有Azure訂閱級別權限的帳戶來與AzureML交互是不理想的。
# Code 6: launch the azureml pipeline with a devops task
- task: AzureCLI@2
name: 'amlTrain'
displayName: 'Run AzureML pipeline'
inputs:
azureSubscription: $(serviceConnection)
scriptType: bash
scriptLocation: inlineScript
inlineScript: 'python run_azure_pipeline.py'
workingDirectory: '$(System.DefaultWorkingDirectory)/aml_pipeline'3.3在DevOps中進行條件模型部署 (3.3 Conditional model deployment in DevOps)
An updated model trained with the latest data will not perform better by definition. We want to decide whether to deploy the latest model based on its performance. Thus, we want to communicate our intent to deploy the model from AzureML to the DevOps pipeline. To output a variable to the DevOps context we need to write a specific string to the stdout of our Python script.
從定義上講,使用最新數據訓練的更新模型不會表現更好。 我們要根據性能來決定是否部署最新模型。 因此,我們希望傳達將模型從AzureML部署到DevOps管道的意圖。 要將變量輸出到DevOps上下文,我們需要在Python腳本的stdout中寫入特定的字符串。
In our implementation each step in the AzureML pipeline can trigger a deployment by creating the following local empty file “outputs/trigger”. The “outputs” directory is special and Azure uploads its content automatically to the central blob storage accessible through the PipelineRun object and ML studio. After the AzureML pipeline is completed we inspect the steps in the PipelineRun for the existence of the trigger file (Code 7). Based on this an output variable is written to the DevOps context as a Task output variable (Code 7).
在我們的實現中,AzureML管道中的每個步驟都可以通過創建以下本地空文件“輸出/觸發器”來觸發部署。 “輸出”目錄很特殊,Azure將其內容自動上傳到可通過PipelineRun對象和ML Studio訪問的中央Blob存儲。 在AzureML管道完成之后,我們檢查PipelineRun中的步驟是否存在觸發文件(代碼7)。 基于此,將輸出變量作為Task輸出變量(代碼7)寫入DevOps上下文。
# Code 7: expanded run function with devops output variable
def run_pipeline():
workspace = Workspace.from_config()
pipeline = Pipeline(
workspace=workspace,
steps=[model_train_step, model_evaluation_step]
)
pipeline_run = Experiment(
workspace, EXPERIMENT).submit(pipeline)
pipeline_run.wait_for_completion()
deploy_model = False
steps = pipeline_run.get_steps()
for step in steps:
if "outputs/trigger" in step.get_file_names():
deploy_model = True
if deploy_model:
print("Trigger model deployment.")
print("##vso[task.setvariable variable=deployModel;isOutput=true]yes") else:
print("Do not trigger model deployment.")
print("##vso[task.setvariable variable=deployModel;isOutput=true]no")4將模型和代碼部署到Azure功能 (4 Deploy model and code to an Azure function)
4.1條件DevOps部署作業 (4.1 Conditional DevOps deploy job)
We have trained a new model and want to deploy it. We need a DevOps job to take care of the deployment, which runs conditionally on the output of our AzureML training pipeline. We can access the output variable described above and perform an equality check within the jobs’ condition clause. Code 8 below shows how we access the task output variable from the previous train job in the condition of the deploy job.
我們已經訓練了一個新模型,并希望部署它。 我們需要一個DevOps作業來處理部署,該部署有條件地在AzureML培訓管道的輸出上運行。 我們可以訪問上述輸出變量,并在作業的condition子句中執行相等性檢查。 下面的代碼8顯示了在部署作業的情況下,我們如何訪問上一個訓練作業的任務輸出變量。
# Code 8: Conditional deploy job based on train job output
- job: deploy_function
dependsOn: train
condition: eq(dependencies.train.outputs['amlTrain.deployModel'], 'yes')
...4.2檢索最新型號 (4.2 Retrieve the latest model version)
To retrieve the latest model from the AzureML Workspace we use an Azure CLI task to handle the required authentication. Within it we run a Python script, which attaches to our AzureML workspace and downloads the latest model within the directory that holds our function (Code 9). When we deploy our function this script is called to package our model with our Python code and requirements (Code 10, task 3). Each model release thus implies a function deploy.
為了從AzureML工作區檢索最新模型,我們使用Azure CLI任務來處理所需的身份驗證。 在其中,我們運行一個Python腳本,該腳本附加到我們的AzureML工作區,并在保存函數的目錄(代碼9)中下載最新模型。 部署函數時,將調用此腳本以將模型與Python代碼和要求打包在一起(代碼10,任務3)。 因此,每個模型版本都意味著功能部署。
# Code 9: retrieve latest model for devops deployment of function
import os
import shutilfrom azureml.core import Model, WorkspaceMODEL_NAME = "pytorch_model"workspace = Workspace.from_config()
model_path = Model.get_model_path(MODEL_NAME, _workspace=workspace)os.makedirs("./model", exist_ok=True)
shutil.copyfile(model_path, "./model/model.p")4.3將模型和代碼部署到我們的功能應用程序 (4.3 Deploy model and code to our function app)
The azure-functions-core-tools support local development and deployment to a Function App. For our deployment, the function build agent is used to install Python requirements and copy the package to the function App. There is a dedicated DevOps task for function deployments, which you can explore. For the moment we had a better experience installing the azure-functions-core-tools on the DevOps build agent (Ubuntu) and publishing our function with it (Code 10, step 5).
azure-functions-core-tools支持本地開發和部署到Function App。 對于我們的部署,功能構建代理用于安裝Python要求并將程序包復制到功能App。 您可以探索用于功能部署的專用DevOps 任務 。 目前,我們有更好的體驗在DevOps構建代理(Ubuntu)上安裝azure-functions-core-tools并與之一起發布我們的功能(代碼10,第5步)。
# Code 10: devops pipeline template for function deployment
parameters:
- name: serviceConnection
type: string
- name: workingDirectory
type: string
- name: funcAppName
type: stringsteps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.8'
- task: Bash@3
displayName: 'Install AzureML dependencies'
inputs:
targetType: inline
script: pip install azureml-sdk
- task: AzureCLI@2
displayName: 'package model with function'
inputs:
azureSubscription: ${{ parameters.serviceConnection }}
scriptType: bash
scriptLocation: inlineScript
inlineScript: 'python ../scripts/package_model.py'
workingDirectory: '${{ parameters.workingDirectory }}/torch_function'
- task: Bash@3
displayName: 'Install azure functions tools'
inputs:
targetType: inline
script: sudo apt-get update && sudo apt-get install azure-functions-core-tools-3
- task: AzureCLI@2
displayName: 'publish and build the function'
inputs:
azureSubscription: ${{ parameters.serviceConnection }}
scriptType: bash
scriptLocation: inlineScript
workingDirectory: '${{ parameters.workingDirectory }}/torch_function'
inlineScript: func azure functionapp publish ${{ parameters.funcAppName }} --python討論區 (Discussion)
In this blog we present a pipeline architecture that supports Continuous AI on Azure with a minimal amount of moving parts. Other solutions we encountered add Kubernetes or Docker Instances for publishing the AzureML models for consumption by frontend facing functions. This is an option, but it might increase the engineering load on your team. We do think that adding Databricks could enrich our workflow with collaborative notebooks and more interactive model training, especially in the exploration phase of the project. The AzureML-MLFlow API allows you to register model from Databricks notebooks and hook into our workflow at that point.
在此博客中,我們介紹了一種管道架構,該架構支持Azure上的Continuous AI,并具有最少的活動部件。 我們遇到的其他解決方案添加了Kubernetes或Docker實例,用于發布AzureML模型以供面向前端的功能使用。 這是一個選項,但可能會增加團隊的工程負擔。 我們確實認為,添加Databricks可以通過協作筆記本和更多交互式模型培訓來豐富我們的工作流程,尤其是在項目的探索階段。 AzureML-MLFlow API允許您從Databricks筆記本中注冊模型,并在那時加入我們的工作流程。
完整的模型訓練 (Full model training)
Our focus is on model training for incremental updates with training times measured in hours or less. When we consider full model training measured in days, the pipeline architecture can be expanded to support non-blocking processing. Databricks could be a platform full model training on GPUs as described above. Another option is to run the AzureML pipeline withAzure Datafactory, which is suitable for long running orchestration of data intensive jobs. If the trained model is deemed viable a follow-up DevOps pipeline can be triggered to deploy it. A low-tech trigger option (with limited authentication options) is the http endpoint associated with each DevOps pipeline.
我們的重點是模型培訓,以進行增量更新,培訓時間以小時或更少為單位。 當我們考慮以天為單位衡量的完整模型訓練時,可以擴展管道體系結構以支持非阻塞處理。 如上所述,Databrick可以是在GPU上進行平臺全模型訓練的平臺。 另一個選擇是使用Azure Datafactory運行AzureML管道,這適用于長期運行的數據密集型業務編排。 如果認為經過訓練的模型可行,則可以觸發后續的DevOps管道進行部署。 技術含量低的觸發選項(具有有限的身份驗證選項)是與每個DevOps管道關聯的http端點 。
用例 (Use cases)
AI is not the only use case for our approach, but it is a significant one. Related use cases are interactive reporting applications running on streamlit, which can contain representations of knowledge that have to be updated. Machine Learning models, interactive reports and facts from the datalake work in tandem to inform management or customer and lead to action. Thank you for reading.
人工智能不是我們方法的唯一用例,但它是一個重要的案例。 相關用例是在streamlit上運行的交互式報告應用程序,其中可以包含必須更新的知識表示。 機器學習模型,交互式報告和來自Datalake的事實協同工作,以通知管理層或客戶并采取行動。 感謝您的閱讀。
Originally published at https://codebeez.nl.
最初發布在 https://codebeez.nl 。
翻譯自: https://towardsdatascience.com/mlops-a-tale-of-two-azure-pipelines-4135b954997
azure第一個月
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391801.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391801.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391801.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

firebase auth_如何使用auth和實時數據庫構建Firebase Angular應用

Mybatis—多表查詢

VS2008 開發設計MOSS工作流 URN 注意了

ArangoDB Foxx service 使用

編譯原理 數據流方程_數據科學中最可悲的方程式

@ConTrollerAdvice的使用

Mybatis—注解開發

道路工程結構計算軟件_我從軟件工程到產品管理的道路


![解決朋友圈壓縮_朋友中最有趣的朋友[已解決]](http://pic.xiahunao.cn/解決朋友圈壓縮_朋友中最有趣的朋友[已解決])
解決朋友圈壓縮_朋友中最有趣的朋友[已解決]


MapServer應用開發平臺示例
)
leetcode 995. K 連續位的最小翻轉次數(貪心算法)

kotlin數據庫_如何在Kotlin應用程序中使用Xodus數據庫

使用route add添加路由,使兩個網卡同時訪問內外網

基于JavaConfig配置的Spring MVC的構建

pymc3 貝葉斯線性回歸_使用PyMC3進行貝葉斯媒體混合建模,帶來樂趣和收益

webkit中對incomplete type指針的處理技巧
)