批梯度下降 隨機梯度下降
In this article, I am going to discuss the Gradient Descent algorithm. The next article will be in continuation of this article where I will discuss optimizers in neural networks. For understanding those optimizers it’s important to get a deep understanding of Gradient Descent.
在本文中,我將討論梯度下降算法。 下一篇文章將是本文的繼續,我將在其中討論神經網絡中的優化器。 為了了解這些優化器,對Gradient Descent的深入了解很重要。
內容- (Content-)
- Gradient Descent 梯度下降
- Choice of Learning Rate 學習率選擇
- Batch Gradient Descent 批次梯度下降
- Stochastic Gradient Descent 隨機梯度下降
- Mini Batch Gradient Descent 迷你批次梯度下降
- Conclusion 結論
- Credits 學分
梯度下降- (Gradient Descent-)
Gradient Descent is a first-order iterative optimization algorithm for finding the local minimum of a differentiable function. To get the value of the parameter that will minimize our objective function we iteratively move in the opposite direction of the gradient of that function or in simple terms in each iteration we move a step in direction of steepest descent. The size of each step is determined by a parameter which is called Learning Rate. Gradient Descent is the first-order algorithm because it uses the first-order derivative of the loss function to find minima. Gradient Descent works in space of any number of dimensions.
梯度下降是用于找到可微函數的局部最小值的一階迭代優化算法。 為了獲得將目標函數最小化的參數值,我們迭代該函數的梯度的相反方向,或者在每次迭代中簡單地說,我們都沿最陡的下降方向移動一步。 每個步驟的大小由稱為學習率的參數確定。 梯度下降法是一階算法,因為它使用損失函數的一階導數來找到最小值。 漸變下降可在任意尺寸的空間中工作。

Steps in Gradient Descent-
梯度下降步驟-
- Initialize the parameters(weights and bias) randomly. 隨機初始化參數(權重和偏差)。
- Choose the learning rate (‘η’). 選擇學習率('η')。
- Until convergence repeat this- 在收斂之前,請重復此操作-

Where ‘w?’ is the parameter whose value we have to find, ‘η’ is the learning rate and L represents cost function.
其中“w?”是我們必須找到其值的參數,“η”是學習率,L表示成本函數。
By repeat until convergence we mean, repeat until the old value of weight is not approximately equal to its new value ie repeat until the difference between the old value and the new value is very small.
重復直到收斂,我們的意思是,重復直到權重的舊值不等于其新值為止,即重復直到權重的舊值與新值之間的差很小。
Another important thing to be kept in mind is that that all weights need to be updated simultaneously as updating a specific parameter before calculating another one will yield a wrong implementation.
要記住的另一件重要事情是,所有權重都需要同時更新,因為在計算另一個參數之前更新特定參數會產生錯誤的實現。

學習率選擇(η)- (Choice of Learning Rate(η)-)
Choosing an appropriate value of learning is very important because it helps in determining how much we have to descent in each iteration. If the learning rate is too small, the descent will be small and hence there will be a delayed or no convergence on the other hand if the learning rate is too large, then gradient descent will overshoot the minimum point and will ultimately fail to converge.
選擇適當的學習價值非常重要,因為它有助于確定我們在每次迭代中必須下降多少。 如果學習速率太小,則下降將很小,因此,如果學習速率太大,則將延遲或沒有收斂,則梯度下降將超過最小點,最終將無法收斂。
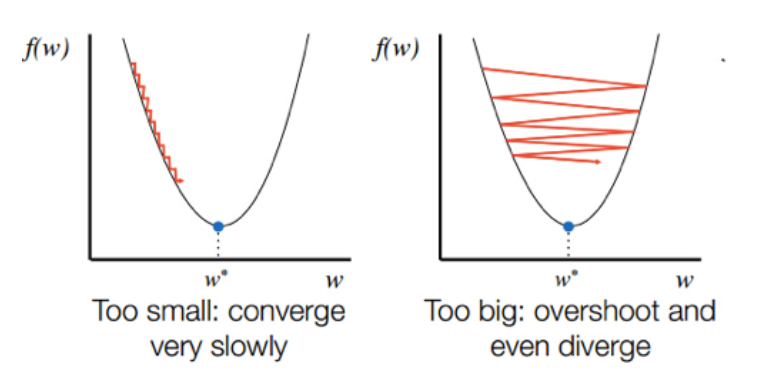
To check this, the best thing is to calculate cost function at each iteration and then plot it with respect to the number of iterations. If cost ever increases we need to decrease the value of the learning rate and if the cost is decreasing at a very slow rate then we need to increase the value of the learning rate.
為了檢查這一點,最好的辦法是在每次迭代中計算成本函數,然后相對于迭代次數對其進行繪制。 如果成本增加,我們需要降低學習率的值,如果成本以非常緩慢的速度下降,那么我們需要提高學習率的值。

Apart from choosing the right value of learning rate another thing that can be done to optimize gradient descent is to normalize the data to a specific range. For this, we can use any kind of standardization technique like min-max standardization, mean-variance standardization, etc. If we don’t normalize our data then features with a large scale will dominate and gradient descent will take many unnecessary steps.
除了選擇正確的學習率值之外,可以做的另一種優化梯度下降的方法是將數據歸一化到特定范圍。 為此,我們可以使用任何類型的標準化技術,例如最小-最大標準化,均值-方差標準化等。如果不對數據進行標準化,則大規模特征將占主導地位,梯度下降將采取許多不必要的步驟。
Probably in your school mathematics, you must have come across a method of solving optimization problems by computing derivative and then equating it to zero then using the double derivative to check whether that point is the point of minima, maxima, or a saddle point. A question comes in mind why don’t we use that method in machine learning for optimization. The problem with that method is that its time complexity is very high and it will be very slow to implement if our dataset is large. Hence gradient descent is preferred.
可能是在學校數學中,您必須遇到一種解決優化問題的方法,方法是計算導數,然后將其等價為零,然后使用雙導數來檢查該點是最小值,最大值還是鞍點。 想到一個問題,我們為什么不在機器學習中使用該方法進行優化。 該方法的問題在于它的時間復雜度很高,如果我們的數據集很大,則實現起來將很慢。 因此,梯度下降是優選的。
Gradient descent finds minima of a function. If that function is convex then its local minima will be its global minima. However, if the function is not convex then, in that case, we might reach a saddle point. To prevent this from happening, there are some optimizations that we can apply to Gradient Descent.
梯度下降找到函數的最小值。 如果該函數是凸函數,則其局部最小值將是其全局最小值。 但是,如果函數不是凸函數,那么在這種情況下,我們可能會達到鞍點。 為了防止這種情況的發生,我們可以將某些優化應用于漸變下降。
Limitations of Gradient Descent-
梯度下降的局限性
- The convergence rate is slow in gradient descent. If we try to speed it by increasing the learning rate then we may overshoot local minima. 梯度下降時收斂速度慢。 如果我們嘗試通過提高學習率來加快速度,那么我們可能會超出局部最小值。
- If we apply Gradient Descent on a non-convex function we may end up at local minima or a saddle point. 如果在非凸函數上應用“梯度下降”,則可能會出現在局部最小值或鞍點處。
- For large datasets, memory consumption will be very high. 對于大型數據集,內存消耗將非常高。
Gradient Descent is the most common optimization technique used throughout machine learning. Let’s discuss some variations of Gradient Descent.
梯度下降是整個機器學習中最常用的優化技術。 讓我們討論梯度下降的一些變化。
批次梯度下降 (Batch Gradient Descent-)
Batch Gradient Descent is one of the most common versions of Gradient Descent. When we say Gradient Descent in general we are talking about batch gradient descent only. It works by taking all data points available in the dataset to perform computation and update gradients. It works fairly well for a convex function and gives a straight trajectory to the minimum point. However, it is slow and hard to compute for large datasets.
批梯度下降是梯度下降的最常見版本之一。 一般而言,當我們說“梯度下降”時,我們僅在談論批梯度下降。 它通過獲取數據集中所有可用的數據點來執行計算和更新漸變。 它對于凸函數非常有效,并為最小點給出了直線軌跡。 但是,對于大型數據集,它速度慢且難以計算。
Advantages-
優點-
- Gives a stable trajectory to the minimum point. 給出最小點的穩定軌跡。
- Computationally efficient for small datasets. 對于小型數據集,計算效率高。
Limitations-
局限性
- Slow for large datasets. 對于大型數據集,速度較慢。
隨機梯度下降 (Stochastic Gradient Descent-)
Stochastic Gradient Descent is a variation of gradient descent which considers only one point at a time to update weights. We will not calculate the total error for whole data in one step instead we will calculate the error of each point and use it to update weights. So basically it increases the number of updates but for each update, less computation will be required. It is based on the assumption that error at each point is additive. Since we are considering just one example at a time the cost will fluctuate and may not necessarily decrease at each step but in the long run, it will decrease. Steps in Stochastic Gradient Descent are-
隨機梯度下降是梯度下降的一種變化形式,一次僅考慮一個點來更新權重。 我們不會一步一步地計算整個數據的總誤差,而是會計算每個點的誤差并使用它來更新權重。 因此,基本上,它增加了更新的數量,但是對于每個更新,將需要較少的計算。 它基于以下假設:每個點的誤差都是累加的。 由于我們一次僅考慮一個示例,因此成本會有所波動,并且不一定會在每一步都降低,但從長遠來看,它將降低。 隨機梯度下降的步驟是-
- Initialize weights randomly and choose a learning rate. 隨機初始化權重并選擇學習率。
- Repeat until an approximate minimum is obtained- 重復直到獲得近似最小值-
- Randomly shuffle the dataset. 隨機隨機播放數據集。
- For each point in the dataset ie if there are m points then- 對于數據集中的每個點,即如果有m個點,則-

Shuffling the whole dataset is done to reduce variance and to make sure the model remains general and overfit less. By shuffling the data, we ensure that each data point creates an “independent” change on the model, without being biased by the same points before them.
對整個數據集進行混洗以減少方差,并確保模型保持通用性并減少過擬合。 通過對數據進行混排,我們確保每個數據點都在模型上創建“獨立”更改,而不會受到之前相同點的影響。

It’s clear from the above image that SGD will go to minima with a lot of fluctuations whereas GD will follow a straight trajectory.
從上圖可以清楚地看到,SGD會在波動很大的情況下達到最小值,而GD會遵循一條直線軌跡。
Advantages-
優點-
- It is easy to fit in memory as only one data point needs to be processed at a time. 它很容易裝入內存,因為一次只需要處理一個數據點。
- It updates weights more regularly as compared to batch gradient descent and hence it converges faster. 與批次梯度下降相比,它更定期地更新權重,因此收斂速度更快。
- It is computationally less expensive than batch gradient descent. 它在計算上比批量梯度下降便宜。
- It avoids local minima in case of non-convex function as randomness or noise introduced by stochastic gradient descent allows us to escape local minima and to reach a better minimum. 它避免了非凸函數的局部最小值,因為隨機梯度下降帶來的隨機性或噪聲使我們能夠逃脫局部最小值并達到更好的最小值。
Disadvantages-
缺點
- It is possible that SGD never reaches local minima and may oscillate around it due to a lot of fluctuations in each step. 由于每個步驟的波動很大,SGD可能永遠不會達到局部最小值,并可能在其附近振蕩。
- Each step of SGD is very noisy and gradient descent fluctuates in different directions. SGD的每個步驟都非常嘈雜,并且梯度下降沿不同方向波動。
So as discussed above SGD is a better idea than batch GD in case of large datasets but in SGD we have to compromise with accuracy. However, there are various variations of SGD which I will discuss in the next blog using which we can improve SGD to a great extent.
因此,如上所述,在數據集較大的情況下,SGD比批處理GD是更好的主意,但在SGD中,我們必須犧牲準確性。 但是,我將在下一個博客中討論SGD的各種變化,我們可以在很大程度上利用它們來改進SGD。
迷你批次梯度下降- (Mini Batch Gradient Descent-)
In Mini Batch Gradient Descent instead of using the complete dataset for calculating gradient, we choose only a mini-batch of it. The size of a batch is a hyperparameter and is generally chosen as a multiple of 32 eg 32,64,128,256 etc. Let’s see its equation-
在“小批量梯度下降”中,我們不使用完整的數據集來計算梯度,而是僅選擇一個小批量。 批的大小是一個超參數,通常選擇為32的倍數,例如32,64,128,256等。讓我們看一下它的方程式-
- Initialize weights randomly and choose a learning rate. 隨機初始化權重并選擇學習率。
- Repeat until convergence- 重復直到收斂-

Here ‘b’ is batch size.
這里的“ b”是批量大小。
Advantages-
優點-
- Faster than batch version as it considers only a small batch of data at a time for calculating gradients. 比批處理版本快,因為它一次只考慮一小批數據來計算梯度。
- Computationally efficient and easily fits in memory. 計算效率高,可輕松放入內存。
- Less prone to overfitting due to noise. 不太容易因噪音而過擬合。
- Like SGD, it avoids local minima in case of non-convex function as randomness or noise introduced by mini-batch gradient descent allows us to escape local minima and to reach a better minimum. 像SGD一樣,它避免了非凸函數的局部最小值,因為由小批量梯度下降引起的隨機性或噪聲使我們能夠逃避局部最小值并達到更好的最小值。
- It can take advantage of vectorization. 它可以利用矢量化的優勢。
Disadvantages-
缺點
- Like SGD, Due to noise, mini-batch Gradient Descent also may not converge exactly at minima and may oscillate around it. 像SGD一樣,由于噪聲的原因,小批量梯度下降可能也無法完全收斂于最小值,并可能在其附近振蕩。
- Although computing each step in mini-batch gradient descent is faster than batch gradient descent due to a small set of points taken into consideration but in the long run, due to noise, it takes more steps to reach minima. 盡管由于考慮了少量點,所以在小批量梯度下降中計算每個步驟都比批量梯度下降要快,但從長遠來看,由于噪聲的原因,要達到最小值需要花費更多的步驟。
We can say SGD is also a mini-batch gradient algorithm with a batch size of 1.
我們可以說SGD也是一個小批量梯度算法,批大小為1。
If we particularly compare mini-batch gradient descent and SGD then its clear that SGD is noisier as compared to mini-batch gradient descent and hence it will fluctuate more to reach convergence. However, it is computationally less expensive and with some variations, it can perform much better.
如果我們特別比較小批量梯度下降和SGD,那么很明顯SGD與小批量梯度下降相比噪聲更大,因此它將波動更大以達到收斂。 但是,它在計算上更便宜,并且有一些變化,它可以執行得更好。
結論- (Conclusion-)
In this article, we discussed Gradient Descent along with its variations and some related terminologies. In the next article, we will discuss optimizers in neural networks.
在本文中,我們討論了“梯度下降”及其變體和一些相關術語。 在下一篇文章中,我們將討論神經網絡中的優化器。

學分 (Credits-)
https://towardsdatascience.com/batch-mini-batch-stochastic-gradient-descent-7a62ecba642a
https://towardsdatascience.com/batch-mini-batch-stochastic-gradient-descent-7a62ecba642a
https://towardsdatascience.com/difference-between-batch-gradient-descent-and-stochastic-gradient-descent-1187f1291aa1
https://towardsdatascience.com/difference-between-batch-gradient-descent-and-stochastic-gradient-descent-1187f1291aa1
https://medium.com/@divakar_239/stochastic-vs-batch-gradient-descent-8820568eada1
https://medium.com/@divakar_239/stochastic-vs-batch-gradient-descent-8820568eada1
https://en.wikipedia.org/wiki/Stochastic_gradient_descent
https://zh.wikipedia.org/wiki/Stochastic_gradient_descent
https://en.wikipedia.org/wiki/Gradient_descent
https://zh.wikipedia.org/wiki/漸變_下降

That’s all from my side. Thanks for reading this article. Sources for few images used are mentioned rest of them are my creation. Feel free to post comments, suggest corrections and improvements. Connect with me on Linkedin or you can mail me at sahdevkansal02@gmail.com. I look forward to hearing your feedback. Check out my medium profile for more such articles.
這就是我的全部。 感謝您閱讀本文。 提到的一些圖片來源都是我的創作。 隨時發表評論,提出更正和改進建議。 在Linkedin上與我聯系,或者您可以通過sahdevkansal02@gmail.com向我發送郵件。 期待收到您的反饋。 查看我的中檔,以獲取更多此類文章。
翻譯自: https://towardsdatascience.com/quick-guide-to-gradient-descent-and-its-variants-97a7afb33add
批梯度下降 隨機梯度下降
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391363.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391363.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391363.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

java作業 2.6

ubuntu 16.04 掛載新硬盤
 運行流程)
Go語言實戰 : API服務器 (2) 運行流程

Linux 命令 之查看程序占用內存

邏輯回歸 自由度_回歸自由度的官方定義

動畫電影的幕后英雄怎么說好_幕后編碼面試-好與壞


網絡對抗技術作業一 201421410031

生存分析簡介:Kaplan-Meier估計器


OD Linux發行版本
 服務器雛形)
Go語言實戰 : API服務器 (3) 服務器雛形

TCP/IP協議-1

http://nancyfx.org + ASPNETCORE

使用r語言做garch模型_使用GARCH估計貨幣波動率


python:校驗郵箱格式

cad2019字體_這些是2019年最有效的簡歷字體
 配置文件讀取及連接數據庫)
Go語言實戰 : API服務器 (4) 配置文件讀取及連接數據庫
