27個機器學習圖表翻譯
Infographics are crucial for presenting information in a more digestible fashion to the audience. With their usage being expanding to many (if not all) professions like journalism, science, and research, advertisements, business, the research on automating the process of generating beautiful and user-centric infographics has been the latest features of the data visualization community.
信息圖表對于以更易消化的方式向觀眾展示信息至關重要。 隨著它們的使用擴展到許多(如果不是全部)行業,例如新聞,科學,研究,廣告,商業,關于自動生成美觀和以用戶為中心的信息圖表的過程的研究已成為數據可視化社區的最新功能。
In this series of posts, we will discuss 5 pioneering research papers focusing on automating the process of generating beautiful infographics for different types of data.
在本系列文章中,我們將討論5項開拓性研究論文,這些論文專注于針對不同類型的數據自動生成漂亮的信息圖表的過程。
Presently, there are many, very powerful design software and code libraries supporting infographic generation from data. The list below mentions some of these tools and libraries that you might want to check out. However, when it comes to designing infographics, the process is not straightforward. To create a very engaging piece of art, it requires expensive labor and is generally very time-consuming. Every small piece of information, from selecting what topics are to be highlighted, to all the way for choosing color combinations, the skillset required to create an infographic is also very diverse.
當前,有許多非常強大的設計軟件和代碼庫支持從數據生成信息圖。 下面的列表提到了您可能需要檢出的一些工具和庫。 但是,在設計信息圖表時,過程并不簡單。 為了制造出非常吸引人的藝術品,這需要昂貴的勞動并且通常非常耗時。 從選擇要突出顯示的主題到選擇顏色組合的所有小信息,創建信息圖所需的技能也非常多樣化。
Softwares Supporting Infographic Generation
支持信息圖生成的軟件
- Microsoft Powerpoint (Design Ideas) Microsoft Powerpoint(設計思路)
- Microsoft PowerBI — For developing data visualization dashboards Microsoft PowerBI —用于開發數據可視化儀表板
- Adobe Illustrator Adobe Illustrator的
- Tableau 畫面
Javascript packages to help create infographics
Javascript包可幫助創建信息圖表
- D3.js D3.js
- Highcharts.js Highcharts.js
自動化的信息圖表設計 (Automated Infographics Design)
Recent research in Information Visualization has seen increased interest in automating/semi-automating the complicated process of infographics generation. However, the main purpose of this research has not been to completely take control away from humans, but instead, focus on developing techniques to support designers in the decision-making process. To study this research, we have divided the papers broadly into 5 categories:
信息可視化的最新研究已經看到了對自動化/半自動化信息圖表生成過程的興趣。 但是,這項研究的主要目的并不是要完全擺脫對人類的控制,而是要著重于開發技術以在決策過程中為設計師提供支持。 為了研究這項研究,我們將論文大致分為5類:
- Timeline infographics design automation 時間線圖表設計自動化
- Icon design automation 圖標設計自動化
- Information flow based automation 基于信息流的自動化
- Text-based automation 基于文本的自動化
- Image Chart fusion automation 圖像圖表融合自動化
時間線圖表生成[1,2] (Timeline Infographics Generation [1,2])
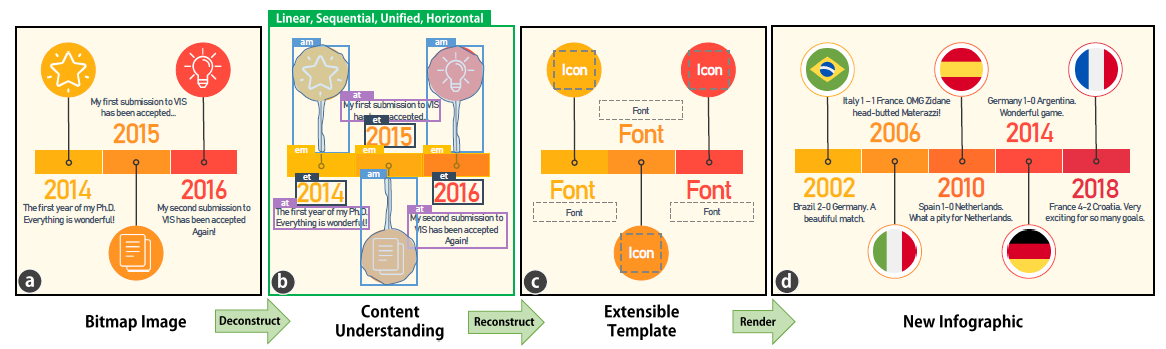
As the name suggests, these methods try to automatically design an infographic for time-based data. One of the approaches works directly on the bitmap images of an already existing timeline infographic to extract global and local information. Global information can be of the type: Orientation, Layout (Unified, Faceted, Segmented, etc. ) and Representation type (Radial, Linear, etc.). Similarly, local information is about the bounding boxes containing a piece of information in the infographic, for example, text boxes, icons, etc. These methods use already existing Convolutional Neural Networks to draw bounding boxes or segment the infographic for local information and also predict the values for global information via classification. After the template information is extracted, we can replace the old information with a new piece of information to get a new infographic automatically.
顧名思義,這些方法嘗試為基于時間的數據自動設計圖表。 一種方法直接在已經存在的時間線圖表的位圖圖像上工作,以提取全局和本地信息。 全局信息的類型可以是:方向,布局(統一,多面,分段等)和表示類型(徑向,線性等)。 類似地,本地信息與包含信息圖表中的一條信息的邊界框有關,例如文本框,圖標等。這些方法使用已經存在的卷積神經網絡繪制邊界框或對信息圖進行分段以獲取局部信息,并預測通過分類獲取全球信息的值。 提取模板信息后,我們可以將舊信息替換為新信息,以自動獲取新信息圖。
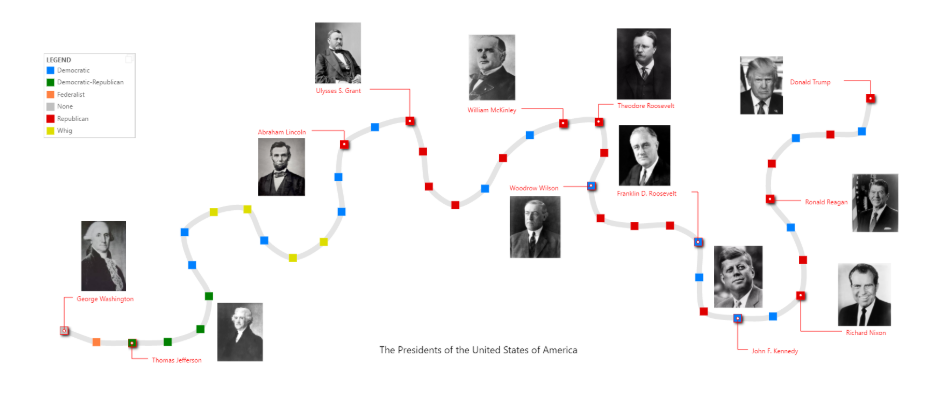
One the other hand, there exists a visualization dashboard called Timeline Storyteller [2] which directly takes the raw CSV/Excel sheet of timeline data and generates infographics which can be later customized by the users as per their design choices. The users can design infographics and animations with even very large time-series datasets and import pictures of their choice into these infographics as shown in the example. Try the timeline storyteller here.
另一方面,存在一個可視化儀表板,稱為時間線講故事[2],它直接獲取時間線數據的原始CSV / Excel工作表并生成信息圖表,這些信息以后可根據用戶的設計選擇進行定制。 用戶可以使用非常大的時間序列數據集設計圖表和動畫,并將他們選擇的圖片導入這些圖表,如示例所示。 在此處嘗試時間軸講故事的人。
圖標設計自動化[3] (Icon Design Automation [3])
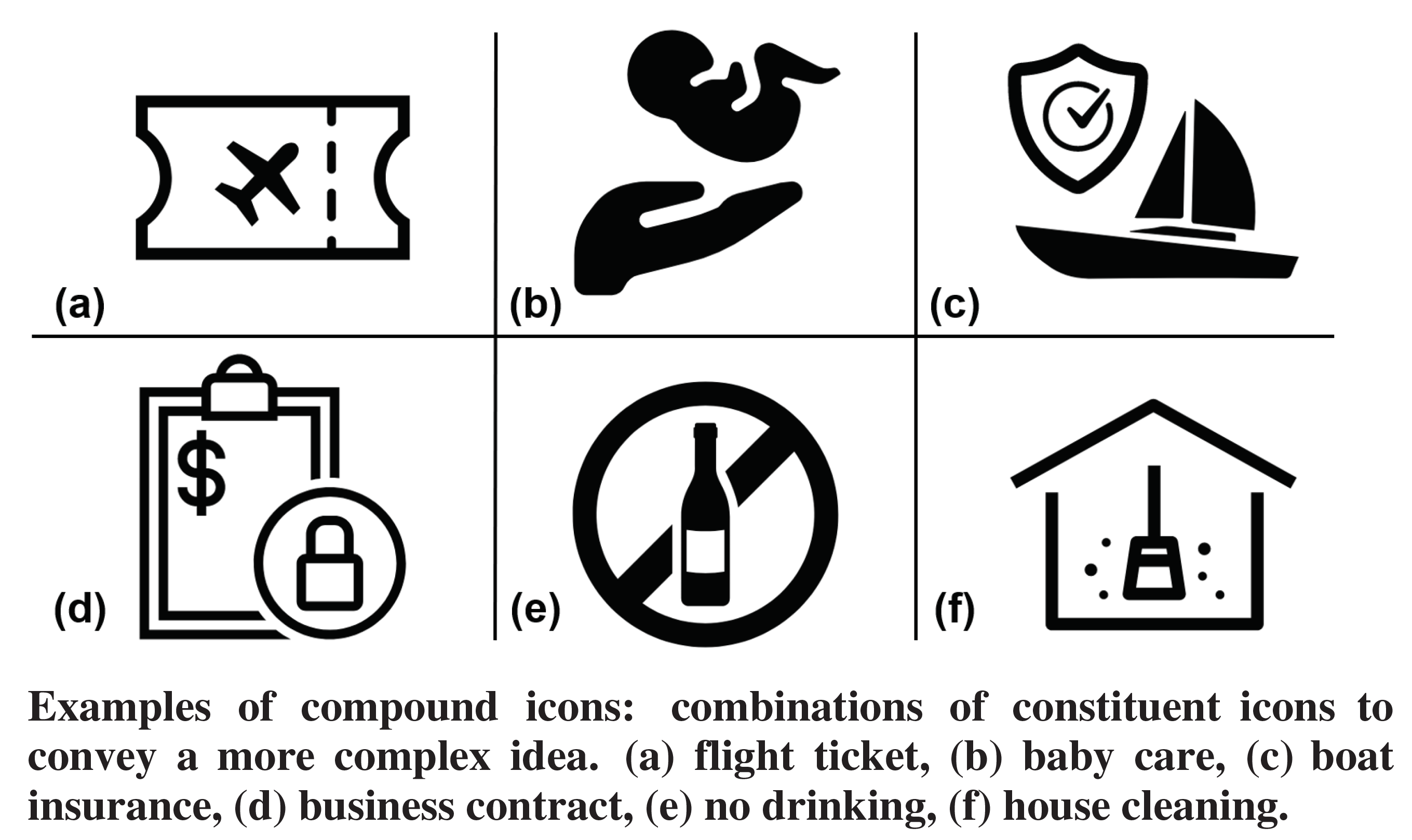
The next category we have on our list is about techniques to design complex icons. So given an input text, for example, House Cleaning, the task is to come up with a semantically meaningful icon. Now, the problem might look simple to search for icons by each word in the query, for example, an icon for “House” and another one for “Cleaning”. Now combine both of these icons and there we go, we have a compound icon. Even though this is correct for simple queries, however, the data for semantically labeled icons is scarce. So we need to figure out ways to extend the existing semantic knowledge of labeled icons to other sectors that are not so well explored. For this purpose, using the well-studied word embeddings from Natural Language Processing can be useful.
我們列表中的下一個類別是有關設計復雜圖標的技術。 因此,給定輸入文本(例如, House Cleaning) ,任務是拿出一個語義上有意義的圖標。 現在,按查詢中每個單詞搜索圖標看起來似乎很簡單,例如,一個圖標用于“房屋”,另一個圖標用于“清潔”。 現在將這兩個圖標結合起來,我們開始制作復合圖標。 即使對于簡單查詢來說這是正確的,但是,帶有語義標簽的圖標的數據卻很少。 因此,我們需要找出將標簽圖標的現有語義知識擴展到其他領域的方法,而這些領域并沒有得到很好的探索。 為此,使用自然語言處理中經過深入研究的詞嵌入可能會很有用。
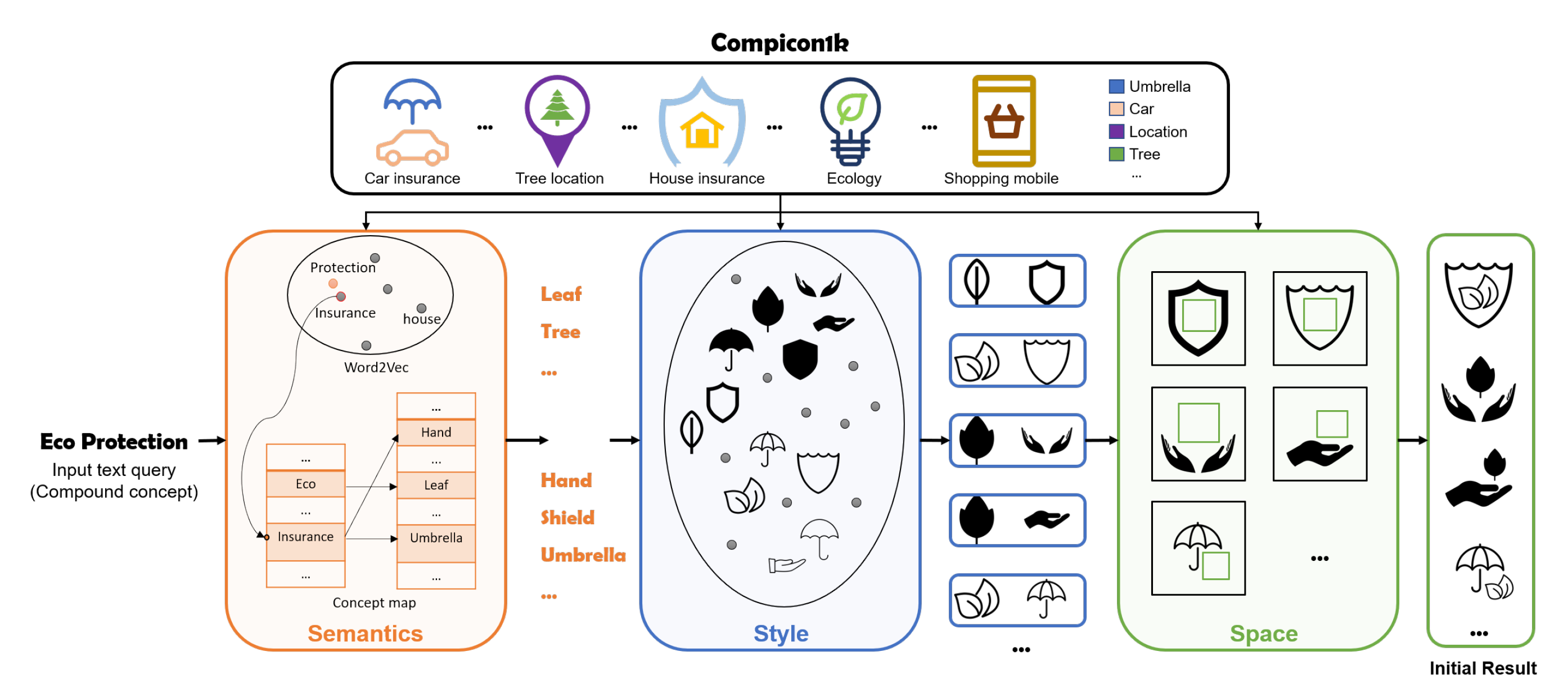
Given a query text, we calculate the nearest word for each unigram that is annotated and is associated with an icon in the existing dataset. Then the extracted icons from the query unigrams are ranked on the basis of style compatibility. To measure style compatibility, an embedding vector is generated for each icon describing it’s style. So closer the style vectors of two icons, similar they are in style. For this purpose, we can train a CNN to generate these style embeddings. This model is trained on an existing 1000 human-curated compound icons dataset where the individual icons inside a compound icon were considered more similar in styles as opposed to a different style of that icon occurring in another input compound icon.
給定一個查詢文本,我們將為每個有符號的,與現有數據集中的圖標相關聯的字母組合計算最接近的單詞。 然后,根據樣式兼容性對從查詢字母組合中提取的圖標進行排名。 為了衡量樣式的兼容性,將為每個描述樣式的圖標生成一個嵌入向量。 如此接近兩個圖標的樣式矢量,它們的樣式相似。 為此,我們可以訓練CNN來生成這些樣式嵌入。 該模型在現有的1000個人類管理的復合圖標數據集上進行了訓練,在該數據集中,復合圖標內的各個圖標在樣式上被認為與在另一個輸入復合圖標中出現的該圖標的不同樣式更加相似。
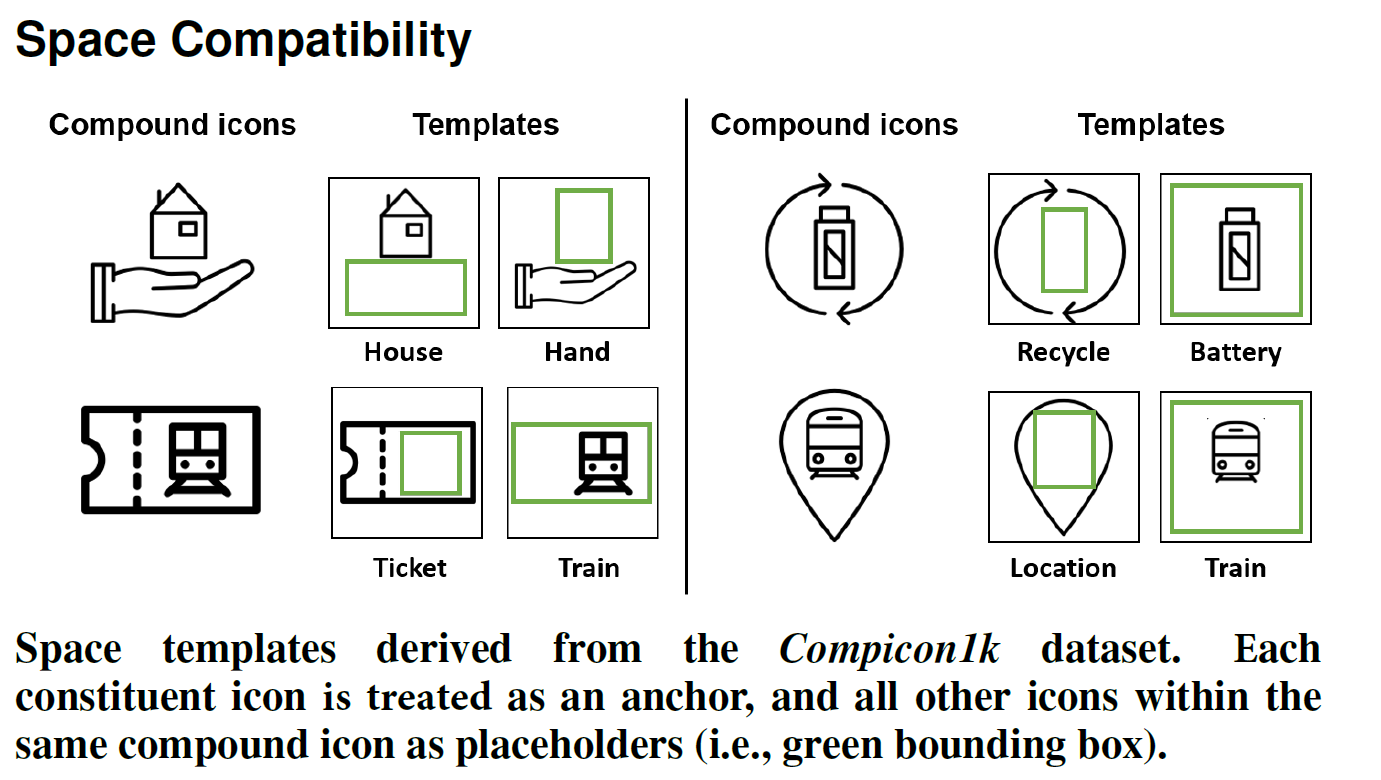
For the final part of the jigsaw, when the icons are filtered based on semantics and style compatibility, they are placed based on space compatibility. To calculate the space compatibility, the icons from the 1k human-curated compound icons are studied to generate templates based on each of the icons (shown in the image above). This is done to generate an idea of where the other icon can be placed relative to the current icon. Using this information, the icons are placed in the template to generate compound icons.
對于拼圖的最后一部分,當根據語義和樣式兼容性對圖標進行過濾時,將根據空間兼容性來放置圖標。 為了計算空間兼容性,研究了來自1k種人類固化復合圖標的圖標,以基于每個圖標生成模板(如上圖所示)。 這樣做是為了產生一個想法,即相對于當前圖標可以放置另一個圖標。 使用此信息,將圖標放置在模板中以生成復合圖標。
基于信息流的自動化[4] (Information Flow Based Automation [4])
Moving on to the text category, this work focuses on extracting information flow in infographics.
轉到文本類別,此工作著重于提取信息圖表中的信息流。
Given an infographic image, the information flow is basically a way to display the direction of visual group placements inside that image. Visual Groups are the information containing segments inside an infographic which are repeated to present a full picture. The flow of these visual groups is called Narrative Flow.
給定一個信息圖圖像,信息流基本上是一種顯示圖像內部視覺組放置方向的方法。 可視組是信息,這些信息包含信息圖表內的片段,這些片段會重復顯示完整的圖片。 這些視覺組的流動稱為敘事流 。

This paper classifies these Narrative Flow patterns into 12 classes based on the studied Visual Groups and their placements in the 13k infographic images dataset. Object Detection CNNs were used to initially detect Visual Groups containing Icons and Texts inside infographics and then the placements were studied to generate the information flow diagram.
根據研究的視覺組及其在13k信息圖圖像數據集中的位置,將這些敘事流模式分為12類。 使用對象檢測CNN最初檢測信息圖表中包含圖標和文本的視覺組,然后研究放置位置以生成信息流程圖。
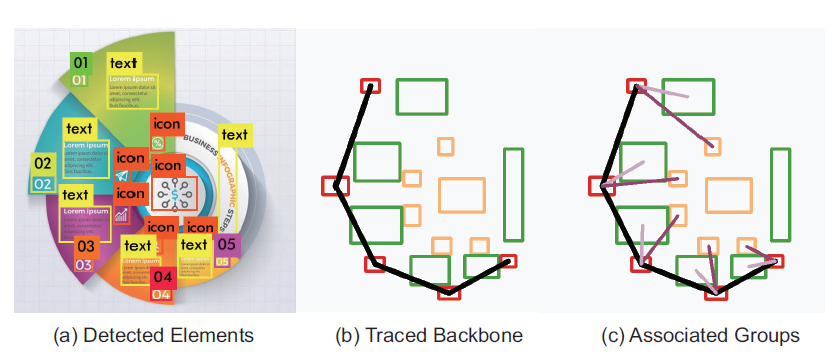
This paper discusses a Flow Extraction Algorithm to group the bounding boxes detected by the CNN (YOLO) into visual groups based on proximity and size and then detect the flow of these visual groups to predict the final visual information flow. Besides this, this system is also able to perform a reverse selection and classification where the users draw the direction of information flow and the system fetches the relevant infographics with a similar direction of flow. Also, as discussed above, the 12 classification categories of information flow are shown in the image below.
本文討論了一種流量提取算法 ,該算法將CNN( YOLO )所檢測到的邊界框根據接近度和大小分為可視組,然后檢測這些可視組的流量以預測最終的可視信息流。 除此之外,該系統還能夠執行反向選擇和分類,其中用戶繪制信息流的方向,并且系統以相似的流向獲取相關信息圖表。 另外,如上所述,下圖顯示了信息流的12個分類類別。

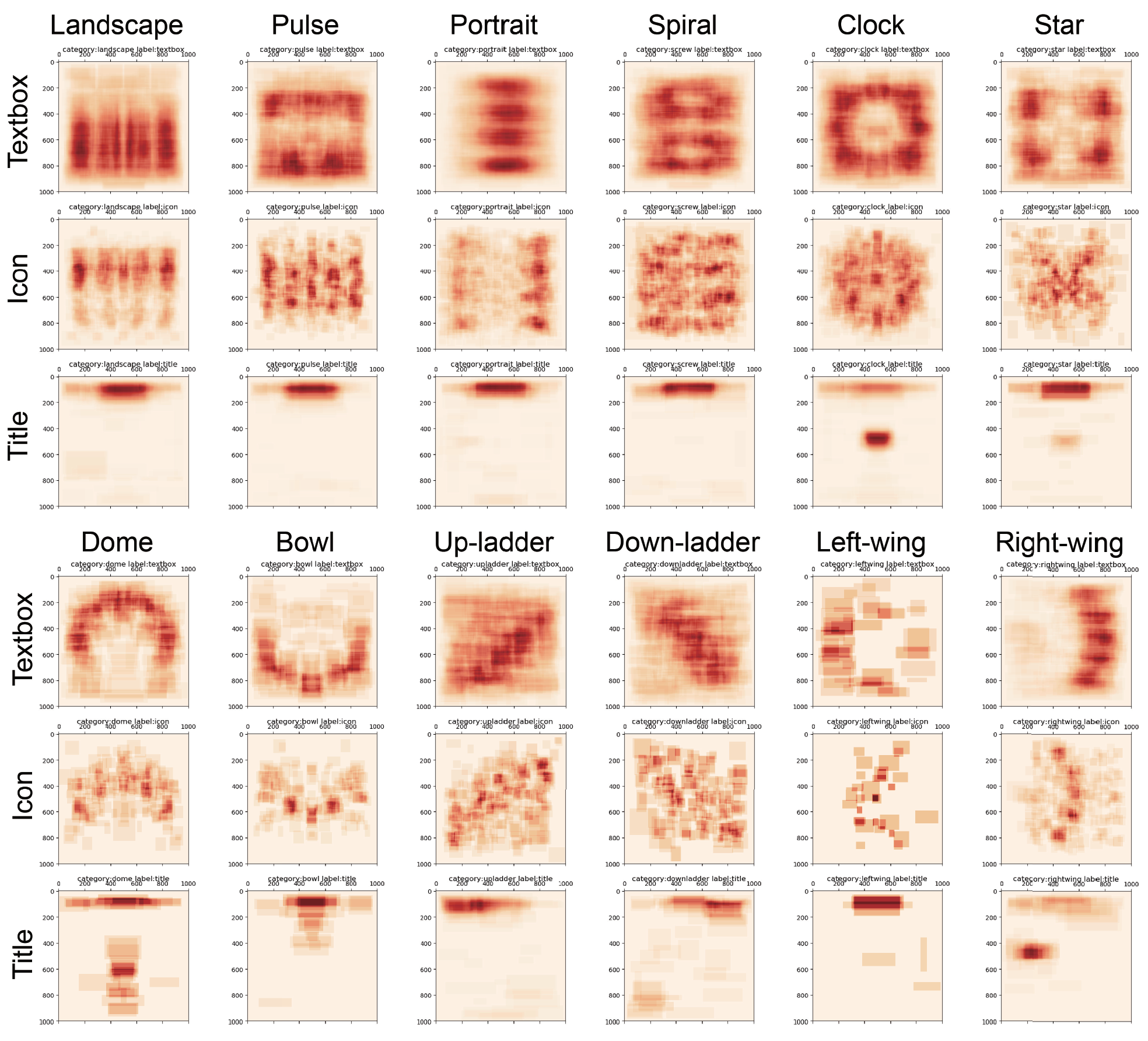
This paper also studies the spatial distribution of different elements inside the infographics based on these 12 classes, as shown below.
本文還基于這12個類別研究了信息圖表內部不同元素的空間分布,如下所示。
基于文本的自動化[5] (Text-Based Automation [5])

Another system in this series is known as the Text-to-Viz. Given a statistical statement, this system tries to directly come up with complete infographic design. Unlike other tools for infographic management, where the user needs to/can edit the final design of the infographic, Text-to-Viz generates these well defined, aesthetic infographics which need no editing. The best use case of this system if for the scenarios where the user doesn’t need to create a very design rich infographic but needs something simple and quick to present a piece of statistical information in a better way. According to this paper, there are 4 types of most common infographics:
該系列中的另一個系統稱為“ 文本到視頻”。 給定統計報表,此系統將嘗試直接提出完整的信息圖表設計。 與用戶需要/可以編輯信息圖的最終設計的其他信息圖管理工具不同,Text-to-Viz生成了這些定義清晰,美觀的信息圖,無需進行編輯。 該系統的最佳用例是針對以下情況:用戶不需要創建非常豐富的信息圖表,而是需要簡單快速地以更好的方式呈現統計信息的情況。 根據本文,最常見的信息圖表有4種類型:
- Statistical-based: Infographics containing charts, pictographs, etc. for presenting statistical information. 基于統計的:包含圖表,象形文字等的信息圖表,用于呈現統計信息。
- Timeline-based: Presenting timeline information. 基于時間軸:顯示時間軸信息。
- Process-based: Step by step action presentation. 基于過程:分步操作演示。
- Location-based: Showing information on a map. 基于位置:在地圖上顯示信息。
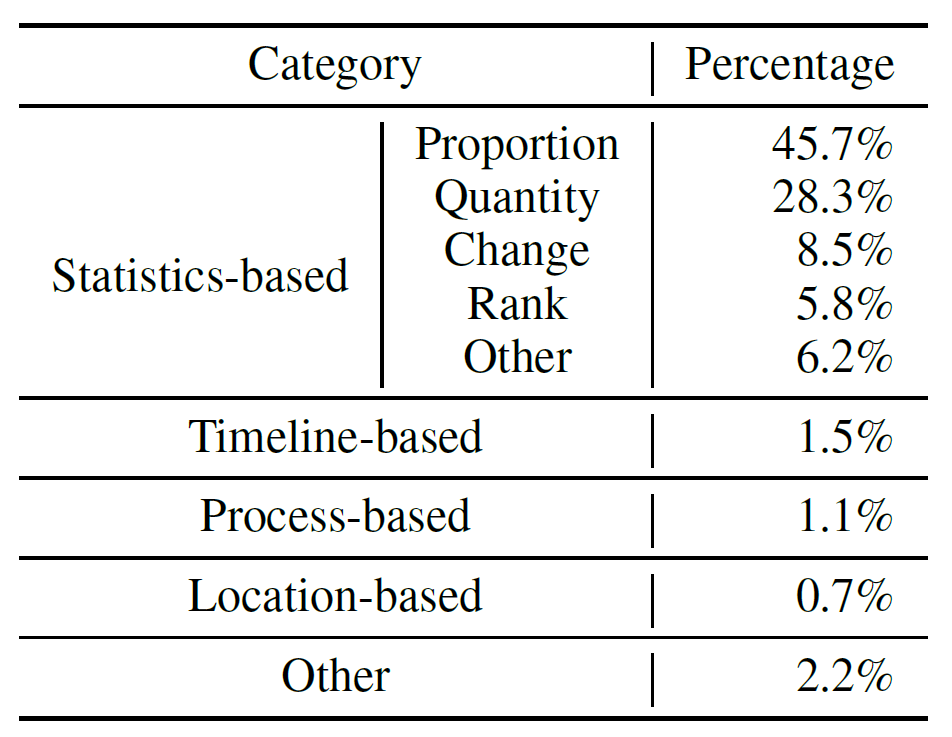
Since, according to this research, around 50% of the infographics are statistical-based, and in that, around 45% are proportion-based, they only tried to create an automatic infographic generation system for this set of infographics. After that, the next step was to study different parts of the proportion-based information text. An example is shown below where they are trying to classify and extract pieces of information to be designed separately.
由于根據這項研究,大約50%的信息圖表是基于統計的 ,而其中大約45%是基于比例的 ,因此他們僅嘗試為這組圖表創建自動的信息圖表生成系統。 之后,下一步是研究基于比例的信息文本的不同部分。 下面顯示了一個示例,他們試圖對這些信息進行分類和提取,以分別設計。

Next up, the design space needs to be separated based on where different elements are to be placed. The researchers came up with 20 template designs where different elements could be placed based on the rules mentioned in the paper.
接下來,需要根據放置不同元素的位置來分隔設計空間。 研究人員提出了20種模板設計,可以根據論文中提到的規則放置不同的元素。

圖像圖表融合自動化[6] (Image Chart Fusion Automation [6])

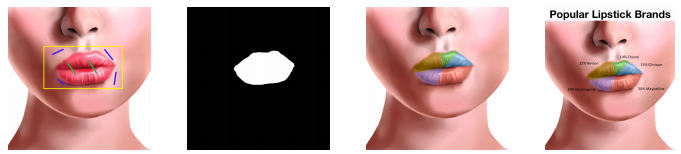
The last techniques in the list of automatic infographics generation are the techniques to design images containing chats, as shown in the above image. A survey on the photographic infographics showed the type of charts that are frequently used to present data embedded inside images [6]. These are Bar charts [41.2%], Pie charts [21.4%], Line charts [9.4%], and Scatterplots [2.2%]. Other than the charts, other ways of embedding this information are Single Divided Object: where the graphics are divided into smaller parts along a horizontal/vertical axis and the area of these divisions can be based on the ratio of different quantities we are trying to compare. This is followed by Multiple Resized Objects where the objects inside an image are sized according to the data they are trying to portray. Using the information about how and where the information is represented, researchers generally follow the pipeline shown below to generate final infographics.
自動信息圖表生成列表中的最后一種技術是設計包含聊天的圖像的技術,如上圖所示。 對攝影信息圖表的一項調查顯示了圖表的類型,這些圖表通常用于展示嵌入圖像內部的數據[6]。 這些是條形圖[41.2%],餅圖[21.4%],折線圖[9.4%]和散點圖[2.2%]。 除圖表外,其他嵌入此信息的方法是“ 單個對象劃分”:將圖形沿水平/垂直軸劃分為較小的部分,并且這些劃分的面積可以基于我們嘗試比較的不同數量的比率。 接下來是多個調整大小的對象 ,其中圖像內的對象根據它們要描繪的數據進行大小調整 。 使用有關如何以及在何處表示信息的信息,研究人員通常會按照以下所示的流程生成最終信息圖表。

So, from a given dataset, relevant variables are selected and the images corresponding to those variables are collected. When the user selects one of these images, then the charts are generated for the selected variables. These are to be embedded inside the selected images. At this stage, the user can either drag an area on the image to embed the chart on, or they can choose features from that image (for eg. Hough lines) to use as an anchor to overlay charts on these images.
因此,從給定的數據集中選擇相關變量,并收集與這些變量相對應的圖像。 當用戶選擇這些圖像之一時,將為所選變量生成圖表。 這些將嵌入到所選圖像中。 在此階段,用戶可以在圖像上拖動一個區域以將圖表嵌入其中,也可以從該圖像中選擇要素(例如,霍夫線)作為錨點以將圖表覆蓋在這些圖像上。

Overall, it is reasonable to represent “Trends/Timeline Data (Line Charts)” with Hugh Lines and “Pie Charts/Bar Charts, etc. ” with a masking technique. To fine-tune these embeddings, there are different types of distortions that can be calculated for each type of chart. For example, comparing the slope of the high lines and the line chart can give an estimated distortion of how well the line chart is embedded in the image. These values are used to optimize the fit of the charts on the images to generate aesthetic info-images. And finally, all of this is implemented in an interface where the users can use their domain knowledge or designing skills to fine-tune these automatically generated results.
總體而言,用屏蔽線表示“趨勢/時間線數據(折線圖)”和“休線”和“餅圖/條形圖等”是合理的。 為了微調這些嵌入,可以為每種圖表類型計算不同類型的失真。 例如,比較高線的斜率和折線圖可以給出折線圖在圖像中嵌入程度的估計失真。 這些值用于優化圖表在圖像上的擬合度,以生成美觀的信息圖像。 最后,所有這些都在一個界面中實現,用戶可以在其中使用他們的領域知識或設計技能來微調這些自動生成的結果。
結論 (Conclusion)
We discussed methods for generating infographics on different types of datasets: Timeline, Icons, Text, and Charts. All of these methods focus on a certain aspect of infographics focusing on the type of data they are trying to represent. These cues are generally an outcome of a survey of already existing infographics and then use that information to automate the process. This is still a new research area with a very promising future. The future direction of research can be to explore more variety of infographics and then combine the existing techniques with the new techniques to create a more holistic, generalized technique to automate/semi-automate this tedious process of infographics generation.
我們討論了在不同類型的數據集上生成圖表的方法:時間線,圖標,文本和圖表。 所有這些方法都集中在信息圖形的某個方面,集中在它們試圖表示的數據類型上。 這些提示通常是對已經存在的信息圖表進行調查的結果,然后使用該信息來自動化流程。 這仍然是一個新的研究領域,前景光明。 未來的研究方向可以是探索更多種類的信息圖表,然后將現有技術與新技術結合以創建更全面,通用的技術來自動化/半自動化這種繁瑣的信息圖表生成過程。
翻譯自: https://towardsdatascience.com/information-organization-with-infographics-using-machine-learning-a-survey-54b2169c1f21
27個機器學習圖表翻譯
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391131.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391131.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391131.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
在HTML中使用javascript (js高級程序設計)

大數據新手之路二:安裝Flume
)
leetcode 1723. 完成所有工作的最短時間(二分+剪枝+回溯)

異步解耦_如何使用異步生成器解耦業務邏輯

函數的定義,語法,二維數組,幾個練習題
)
leetcode 1482. 制作 m 束花所需的最少天數(二分查找)

算法訓練營 重編碼_編碼訓練營手冊:沉浸式工程程序介紹
)
面向Tableau開發人員的Python簡要介紹(第4部分)
![bzoj 4552: [Tjoi2016Heoi2016]排序](http://pic.xiahunao.cn/bzoj 4552: [Tjoi2016Heoi2016]排序)
bzoj 4552: [Tjoi2016Heoi2016]排序

oracle之 手動創建 emp 表 與 dept 表
—單表訪問)
深入理解InnoDB(8)—單表訪問

蝙蝠俠遙控器pcb_通過蝙蝠俠從Circle到ML:第二部分
)
camera驅動框架分析(上)

工程項目管理需要注意哪些問題
)
leetcode 872. 葉子相似的樹(dfs)

探索感染了COVID-19的動物的數據

Facebook哭暈在廁所,調查顯示用VR體驗社交的用戶僅為19%


解決Javascript疲勞的方法-以及其他所有疲勞
