python 數據框缺失值
介紹 (Introduction)
In the last article we went through on how to find the missing values. This link has the details on the how to find missing values in the data frame. https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
在上一篇文章中,我們探討了如何找到缺失的值。 該鏈接包含有關如何在數據框中查找缺失值的詳細信息。 https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
Now that you have identified all the missing values, what to do with these missing values? In this article we will go over on how to handle missing data in a data frame.
現在,您已經確定了所有缺失值,如何處理這些缺失值? 在本文中,我們將探討如何處理數據幀中的丟失數據。
There are multiple ways of handling missing data and this varies case by case. There is no universal best way in dealing with the missing data. Use your best judgement and explore different options to determine which method is best for your data set.
有多種處理丟失數據的方法,具體情況視情況而定。 沒有通用的最佳方法來處理丟失的數據。 根據您的最佳判斷,探索不同的選項,以確定哪種方法最適合您的數據集。
Deleting all rows/columns with missing data: This can be used when you have rows/columns where majority of the data is missing. When you are deleting rows/columns you might be losing some valuable information and lead to biased models. So analyze your data before deleting and check if there is any particular reason for missing data.
刪除所有缺少數據的行/列 :當您缺少大部分數據的行/列時,可以使用此方法。 當您刪除行/列時,您可能會丟失一些有價值的信息,并導致模型有偏差。 因此,請在刪除數據之前分析您的數據,并檢查是否有任何特殊原因導致數據丟失。
Imputing data: This is by far the most common way used to handle missing data. In this method you impute a value where data is missing. Imputing data can introduce bias into the datasets. Imputation can be done multiple ways.
估算數據 :這是迄今為止處理缺失數據的最常用方法。 在此方法中,您將在缺少數據的地方估算一個值。 估算數據可能會使數據集產生偏差。 插補可以通過多種方式完成。
a. You can impute mean, median or mode values of a column into the missing values in a column.
一個。 您可以將一列的均值,中位數或眾數值插入一列的缺失值中。
b. You use predictive algorithms to impute missing values.
b。 您可以使用預測算法來估算缺失值。
c. For categorical variables you can label missing data as a category.
C。 對于分類變量,可以將缺少的數據標記為類別。
For this exercise we will use the Seattle Airbnb data set which can be found in the below link. https://www.kaggle.com/airbnb/seattle?select=listings.csv
在本練習中,我們將使用Seattle Airbnb數據集,該數據集可在下面的鏈接中找到。 https://www.kaggle.com/airbnb/seattle?select=listings.csv
Load the data and find the missing values.
加載數據并找到缺少的值。
The details of this steps can be found in the previous post under the below link. https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
有關此步驟的詳細信息,請參見上一篇文章的以下鏈接。 https://medium.com/@kallepalliravi/python-finding-missing-values-in-a-data-frame-3030aaf0e4fd
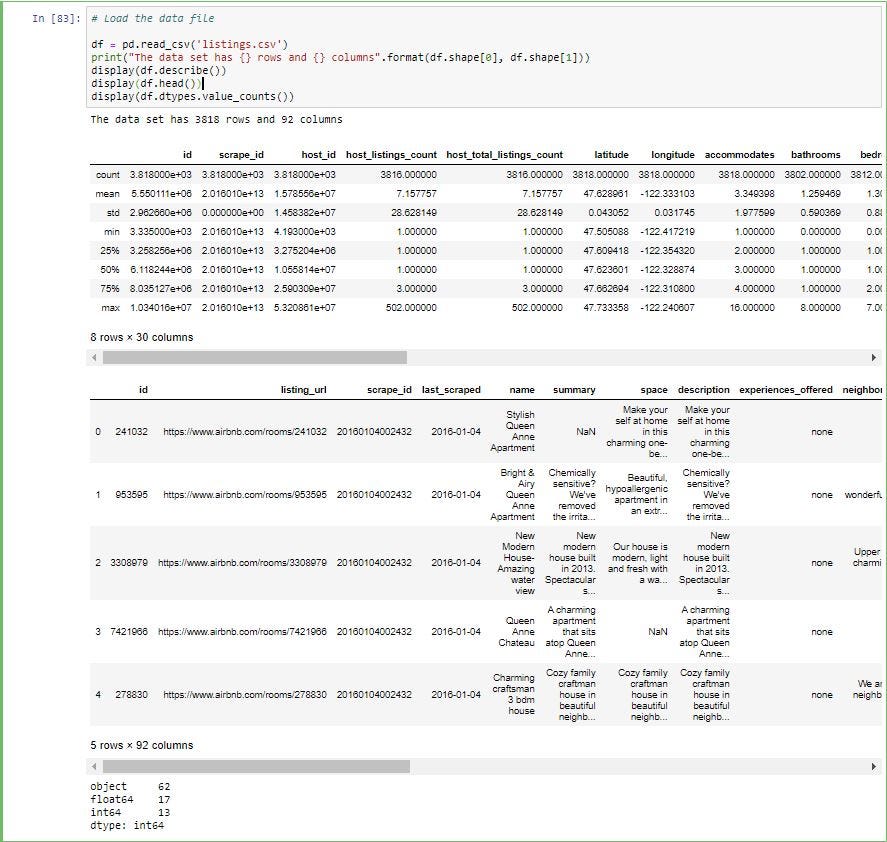
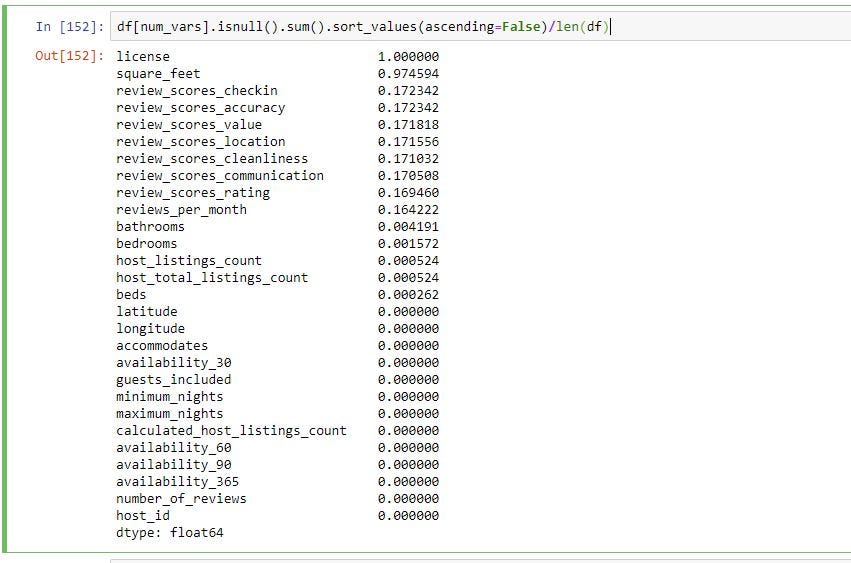
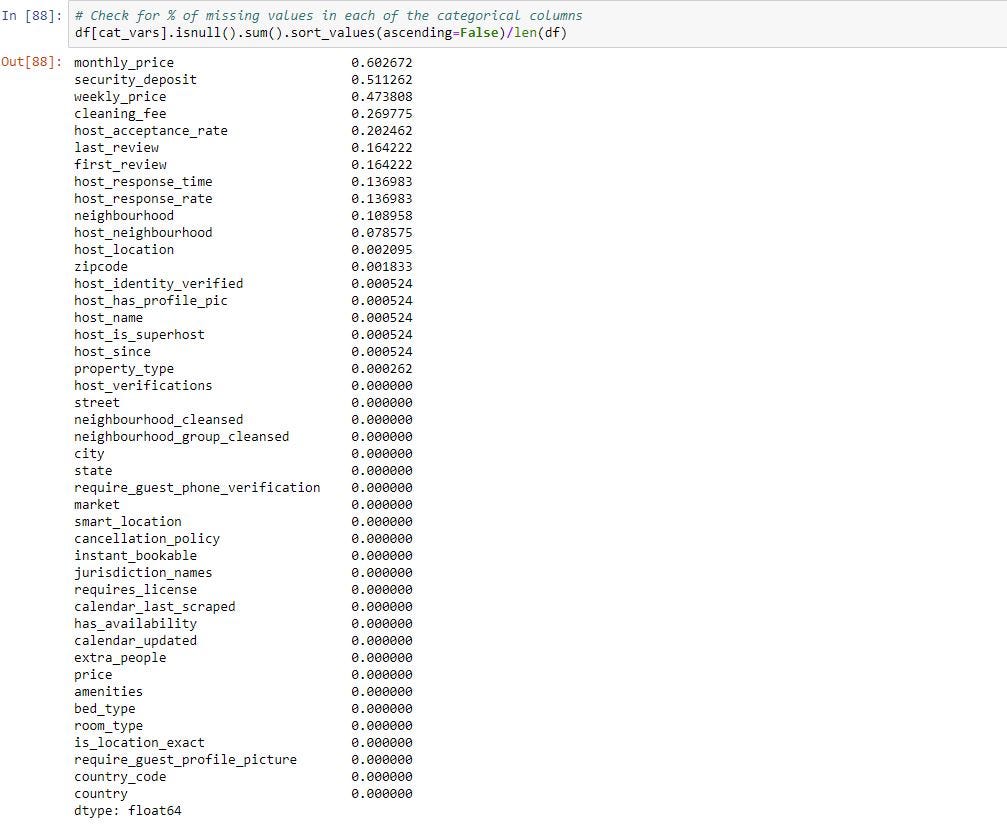
1.刪??除缺少數據的行/列: (1. Deleting rows/columns with missing data:)
Deleting Specific rows/columns
刪除特定的行/列
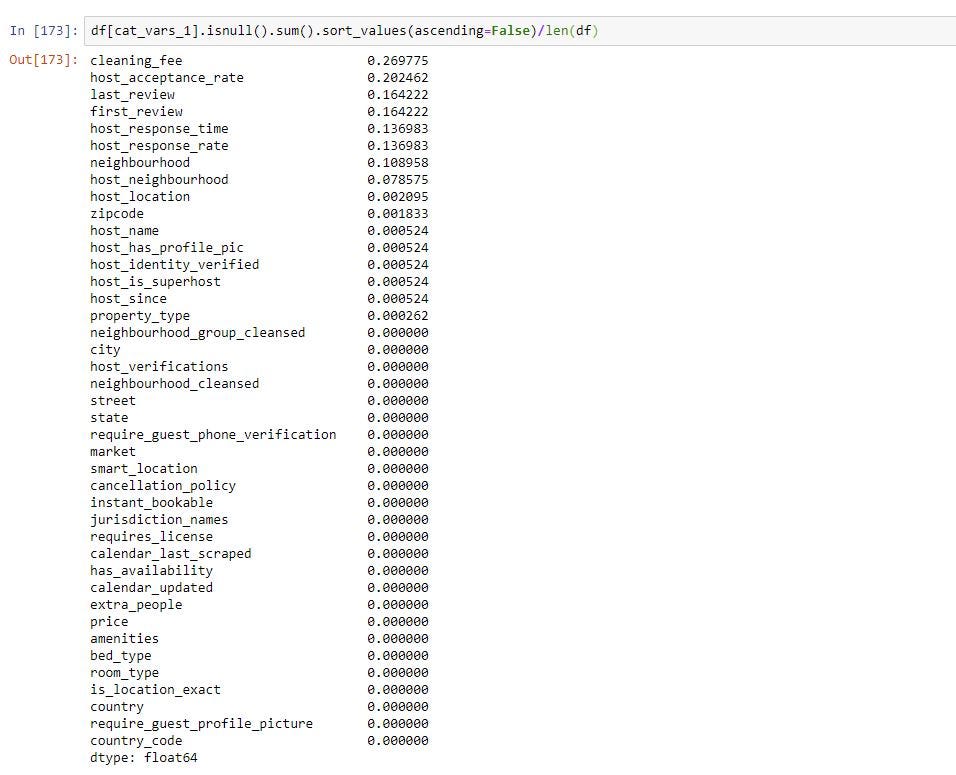
From the above you can see that 100% of the values in license column and 97% of the square_feet column are missing data in numerical columns.
從上面可以看到,許可證列中的100%的值和square_feet列中的97%的值在數字列中丟失。
60% of the values in monthly_price, 51% of values in security_deposit and 47% of values in weekly_price are missing data
缺少數據的month_price中的值的60%,security_deposit中的51%的值和weekly_price中的47%的值
Lets try deleting these 5 columns.
讓我們嘗試刪除這5列。
Pandas drop function can be used to delete rows and columns. Full details of this function can be found in the below https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.drop.html
熊貓拖放功能可用于刪除行和列。 可以在下面的https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.drop.html中找到此功能的完整詳細信息。
All columns which should be deleted should be included in columns parameter. axis =1 represents column, axis=0 represent rows. In the case we are telling to delete all columns specified in the columns parameter.
應該刪除的所有列都應包含在columns參數中。 軸= 1代表列,軸= 0代表行。 在這種情況下,我們告訴您刪除columns參數中指定的所有列。

As you can see below now you do not have columns which have been deleted.
如下所示,您現在沒有已刪除的列。
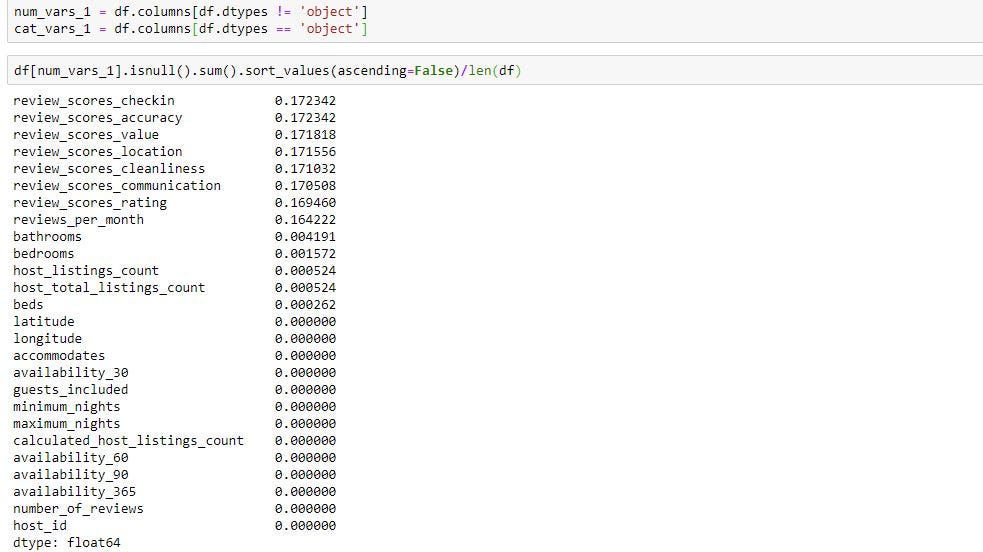
Deleting rows/columns with NA
用NA刪除行/列
If you want to delete rows/columns with NA we can use dropna function in pandas. Details of this function can be found in the below link. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
如果您想使用NA刪除行/列,我們可以在熊貓中使用dropna函數。 可以在下面的鏈接中找到此功能的詳細信息。 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
dropna function has multiple parameters, the 3 main ones are
dropna函數有多個參數,其中三個主要參數是
- how : this has 2 options “any” or “all”. If you set to “any” even if one value has NA in row or column it will delete those columns. If you set to “all” only if all the values in rows/columns have NA deletion will happen. 方式:這有2個選項“任何”或“全部”。 如果您設置為“ any”,即使一個值在行或列中具有NA,它將刪除這些列。 如果僅將行/列中的所有值都具有NA刪除,則設置為“所有”。
- axis : this can be set to 0 or 1. If 0 then drops rows with NA values, if 1 then drops columns with NA values. axis:可以將其設置為0或1。如果為0,則刪除具有NA值的行,如果為1,則刪除具有NA值的列。
- subset: if you want the operation to be performed only on certain columns then mention the column name int he subset. If subset is not define then the operation is performed on all the columns. 子集:如果您希望僅對某些列執行操作,請在子集中提及列名。 如果未定義子集,則對所有列執行該操作。

2.估算數據 (2. Imputing Data)
With imputing you are trying to assign a value through inference from the values to which it contributes. In this case you are assigning a value in the place of a missing value by using different methods on the feature which has missing value. Methods can as simple as assigning mean, median, mode of the column to the missing values or you can use machine learning techniques to predict the missing values. Imputation methods can be different for numerical and categorical variables.
使用插補時,您試圖通過推斷貢獻值來分配一個值。 在這種情況下,您可以通過對具有缺失值的要素使用不同的方法來為缺失值分配一個值。 方法可以簡單到為缺失值分配列的均值,中位數,眾數模式,也可以使用機器學習技術來預測缺失值。 數值和分類變量的插補方法可能不同。
Imputation for Numerical values:
數值的估算:
With numerical columns the most common approach to impute data is by imputing mean, median or mode of the column in place of the missing values.
對于數字列,最常用的估算數據方法是通過估算列的均值,中位數或眾數來代替缺失值。
To do that we will write a function to fill na with mean/median/mode and then apply that function to all the columns.
為此,我們將編寫一個用均值/中位數/眾數填充na的函數,然后將該函數應用于所有列。
In the below i am showing a example to fill the missing data with the mean of the column.
在下面的示例中,我展示了使用列的平均值填充缺失數據的示例。
fill_mean function iterates through each column in the data frame and fill’s na with the column mean.
fill_mean函數遍歷數據幀中的每一列,并用列均值填充na。
You can then use apply() function to apply fill_mean function on one column or multiple columns in a data frame.
然后,您可以使用apply()函數將fill_mean函數應用于數據框中的一列或多列。
This example shows using mean, you can use median() and mode() function in place of mean() if you want to impute median or mode of the column .
此示例顯示了使用均值,如果要對列的中值或眾數進行插值,則可以使用mean()和mode()函數代替mean()。

Imputation for Categorical values:
分類值的插補:
For categorical variables clearly you cannot use mean or median for imputation. But we can use mode which is use the most frequently used value or the one other way is to missing data as category by itself.
顯然,對于分類變量,您不能使用均值或中位數進行插補。 但是我們可以使用使用最常用值的模式,或者另一種方法是單獨丟失數據作為類別。
Since i have already went through on how to impute most frequently value, in this step i will show how make a missing data as a category. This is very straight forward, you just replace NA with “missing data” category. Missing data will be one of the levels in each categorical variable.
由于我已經介紹了如何估算最頻繁的值,因此在這一步中,我將說明如何將缺失的數據作為類別。 這很簡單,您只需將NA替換為“缺少數據”類別。 丟失的數據將是每個分類變量中的級別之一。

Imputation using a model to predict missing values:
使用模型進行插補以預測缺失值:
One more option is to use model to predict missing values. To perform this task you can IterativeImputer from sklearn library. You can find details on this in the below link
另一種選擇是使用模型來預測缺失值。 要執行此任務,您可以從sklearn庫中獲取IterativeImputer。 您可以在以下鏈接中找到詳細信息
https://scikit-learn.org/stable/modules/generated/sklearn.impute.IterativeImputer.html
https://scikit-learn.org/stable/modules/generation/sklearn.impute.IterativeImputer.html
Iterative imputer considers features with missing values and develops a model as function of other features. It then estimates the missing value and imputes those values.
迭代沖刺者會考慮具有缺失值的要素,并根據其他要素開發模型。 然后,它估計缺失值并估算這些值。
It does it in a iterative manner, meaning it will take a 1st feature with missing values which it considers as response variable and considers all the other features as input variables. Using these input variables it will estimate the values for the missing values in the response variable. In the next step it will consider the 2nd feature with missing values as response variable and use all the other features as input variables and estimate missing values. This process will continue until all the features with missing values are addressed.
它以迭代方式進行,這意味著它將采用第一個具有缺失值的特征,將其視為響應變量,并將所有其他特征視為輸入變量。 使用這些輸入變量,它將估計響應變量中缺少的值的值。 在下一步中,它將把具有缺失值的第二個特征視為響應變量,并將所有其他特征用作輸入變量并估計缺失值。 此過程將繼續進行,直到解決所有缺少值的功能。
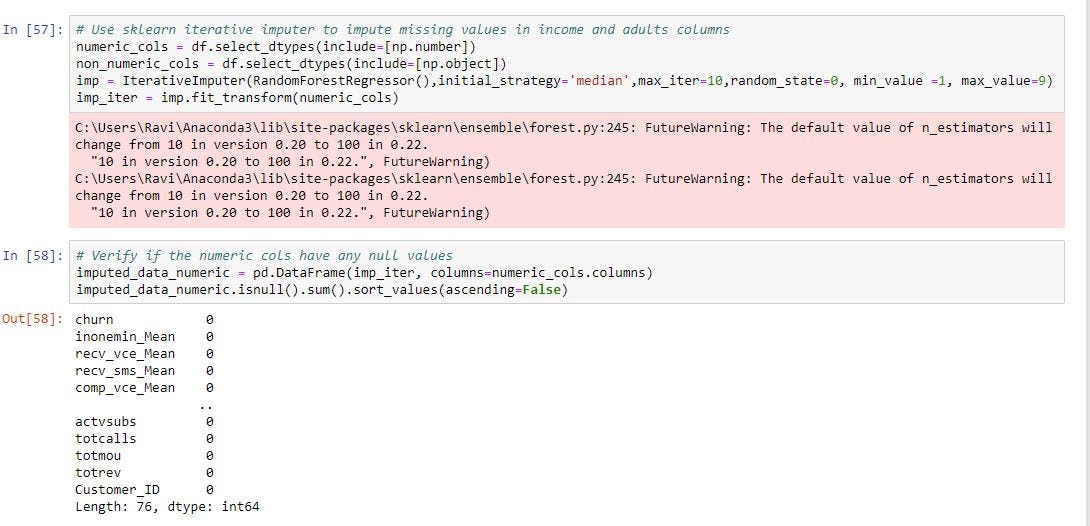
In the below example i am using Random forest in the imputer to estimate the missing values and fitting the imputer to a data frame.
在下面的示例中,我將在嵌入式計算機中使用隨機森林來估計缺失值,并將嵌入式計算機擬合到數據幀。
結論: (Conclusion:)
In this article we went through on how to handle the missing values in a data frame.
在本文中,我們探討了如何處理數據框中的缺失值。
- Delete the rows/columns with missing values 刪除缺少值的行/列
- Imputing the missing values with statistic like mean, mean or mode. 用均值,均值或眾數等統計數據來估算缺失值。
- For categorical variables making missing data as a category. 對于類別變量,將缺少的數據作為類別。
- Using Iterative Imputer develop a model to predict missing values in each of the features. 使用Iterative Imputer開發一個模型來預測每個功能部件中的缺失值。
翻譯自: https://medium.com/analytics-vidhya/python-handling-missing-values-in-a-data-frame-4156dac4399
python 數據框缺失值
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391078.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391078.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391078.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
 - 推薦)
Spring Cloud 5分鐘搭建教程(附上一個分布式日志系統項目作為參考) - 推薦
)
51nod1832(二叉樹/高精度模板+dfs)
TFO(Tcp Fast Open))
重學TCP協議(11)TFO(Tcp Fast Open)
![[網絡安全] 遠程登錄](http://pic.xiahunao.cn/[網絡安全] 遠程登錄)
[網絡安全] 遠程登錄

外星人圖像和外星人太空船_衛星圖像:來自太空的見解

chrome恐龍游戲_如何玩沒有互聯網的Google Chrome恐龍游戲-在線和離線

Hotpatch潛在的安全風險

spring中@Inject和@Autowired的區別?分別在什么條件下使用呢?

Objective-C語言的動態性

內存泄漏和內存溢出的區別

怎么注銷筆記本icloud_如何在筆記本電腦或臺式機的Web瀏覽器中在線查看Apple iCloud照片

棒棒糖 宏_棒棒糖圖表

ubuntu上如何安裝tomcat
)
leetcode 1734. 解碼異或后的排列(位運算)

ZooKeeper3.4.5-最基本API開發

字符串轉換整數python_將Python字符串轉換為Int:如何在Python中將字符串轉換為整數

理解Java里面的必檢異常和非必檢異常

使用vim打開文件的16進制形式,編輯和全文替換

