為什么80%的碼農都做不了架構師?>>> ??
cluster (集群):一個或多個擁有同一個集群名稱的節點組成了一個集群。每個集群都會自動選出一個主節點,如果該主節點故障,則集群會自動選出新的主節點來替換故障節點。
node (節點):一個節點是集群中的一個 Elasticsearch 運行實例。測試環境,多個節點可以同時啟動在同一個服務器上,生產環境一般是一個服務器上一個節點。節點啟動時將使用單播或者是組播來發現和自己配置的集群名稱相同的集群,并嘗試加入到該集群中。
shard (分片):一個分片就是一個Lucene實例,它是 Elasticsearch 管理的底層 「工作單元」。一個索引是邏輯上的一個命名空間,指向主分片和副本分片。索引的主分片和副本分片數量必須明確指定好,在應用代碼使用時只需要處理和索引的交互,不會涉及到和分片的交互。Elasticsearch 會在集群中的所有節點上設置好分片,但節點失效或加入新節點時會自動將移動節點分片。
primary shard (主分片):每個文檔都會被保存在一個主分片上。當我們索引一個文檔時,它將在一個主分片上進行索引,然后才放到該主分片的各副本分片上。默認情況下,一個索引有 5 個主分片。我們可以指定更少或更多的主分片來伸縮索引可處理的文檔數。需要注意的是,一旦索引創建,就不能修改主分片個數。
replica shard (副本分片):每個主分片可以擁有0個或多個副本分片,一個副本分片是主分片的一份拷貝。這樣做有兩個主要原因:
- 故障轉移:當主分片失效時,一個副本分片會被提升為主分片。
- 提高性能:獲取與搜索請求可以被主分片或副本分片處理。默認情況下,每個主分片都有一個副本分片,副本分片的數量可以動態調整。在同一個節點上,副本分片和其主分片不會同時運行。
單節點,三個主分片的原理圖
兩個節點,三個主分片,一個副本分片的原理圖
三個節點,三個主分片,兩個副本分片
索引中的主分片的數量在索引創建后就固定下來了,但是從分片的數量可以隨時改變。
在ES集群中可以監控統計很多信息,其中最重要的就是:集群健康(cluster health)。它的 status 有 green、yellow、red 三種;
status 意義 green所有主分片和從分片都可用 yellow所有主分片可用,但存在不可用的從分片 red存在不可用的主要分片

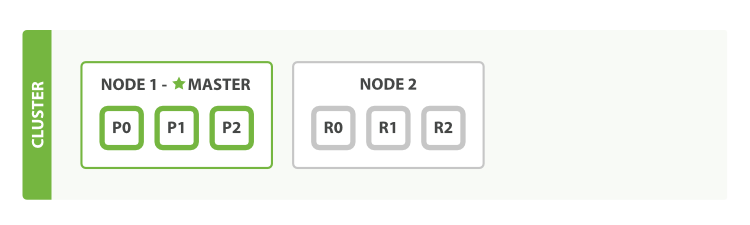
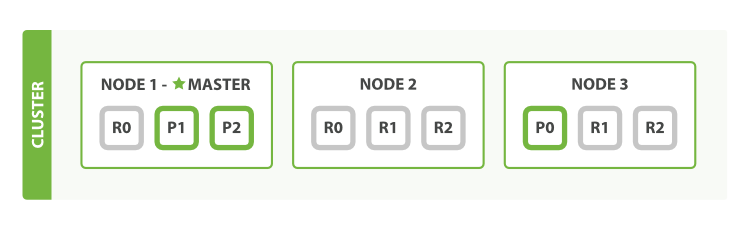
index (索引):一個索引類似關系型數據庫中的一個數據庫,它可以映射為多種type。一個索引就是邏輯上的一個命名空間,對應到1或多個主分片上,可以擁有0個或多個副本分片。
type (類型):表示一類相似的document。Type由名稱(如orderinfo,refundinfo)和mapping組成。類似于數據庫中的schema,描述了文檔可能具有的字段或屬性 、每個字段的數據類型—比如 string, integer 或 date — 以及Lucene是如何索引和存儲這些字段的。類型可以很好的抽象劃分相似但不相同的數據。每個document的類型名被存儲在一個叫 _type 的元數據字段上。
id:id 是用于標識文檔的。文檔 id 是自動生成的,如果顯式不指定。
document (文檔):一個文檔就是一個保存在 Elasticsearch 中的 JSON 文本,可以把它理解為關系型數據庫表中的一行。每個文檔都是保存在索引中的,擁有一種type和 id。一個文檔是一個 JSON Object?(一些語言中的 hash / hashmap / associative array) 包含了 0 或多個field?(鍵值對)。原始的 JSON 文本在索引后將被保存在 _source字段里,搜索完成后返回值中默認是包含該字段的。
document舉例:
{
? "_index": "test_index",
? "_type": "test_type",
? "_id": "1",
? "_version": 1,
? "_source": {
? ? "test_field1": "test field1",
? ? "test_field2": "test field2"
? }
}一個document不只包含了數據。它還包含了元數據(metadata) —— 關于文檔的信息。有三個元數據元素是必須存在的,它們是:
文檔通過 _index, _type以及_id來確定它的唯一性。
名字 說明 _index文檔存儲的地方 _type文檔代表的對象種類 _id文檔的唯一編號
其余可選的元數據類型:
名字 說明 _uid組合id,由_type和_id組成 _source文檔的原始json數據,可以從這里獲取每個字段的內容 _all整合所有字段內容到該字段,默認禁用
source field ( 源字段):默認情況下,在獲取和搜索請求返回值中的 _source字段保存了 源 JSON 文本。這使得我們可以直接在返回結果中訪問源數據,而不需要根據 id 再發一次檢索請求。索引的 JSON 字符串將完整返回,無論是否是一個合法的 JSON。該字段的內容也不會描述數據如何被索引。
field (字段):一個文檔包含了若干字段,或稱之為鍵值對。字段的值可以是簡單標量值,例如字符串、整型、日期,也可以是嵌套結構,例如數組或對象。一個字段類似于關系型數據庫表中的一列。每個字段的映射都有一個字段類型 ( 不要和文檔類型搞混了 ),它描述了這個字段可以保存的值類型,例如整型、字符串、對象。mapping還可以讓我們定義一個字段的值如何進行分析。
字段類型:
一級分類 二級分類 具體類型 核心類型 字符串類型 string,text,keyword 整數類型 integer,long,short,byte 浮點類型 double,float,half_float,scaled_float 邏輯類型 boolean 日期類型 date 范圍類型 range 二進制類型 binary 復合類型 數組類型 array 對象類型 object 嵌套類型 nested 地理類型 地理坐標類型 geo_point 地理地圖 geo_shape 特殊類型 IP類型 ip 范圍類型 completion 令牌計數類型 token_count 附件類型 attachment 抽取類型 percolator
mapping (映射):就像數據庫中的schema,描述了文檔可能具有的字段或屬性,每個字段的數據類型以及Lucene是如何索引和存儲這些字段的。Elasticsearch的mapping一旦創建,只能增加字段,而不能修改已經mapping的字段。修改mapping只能通過重新建立一個index,然后創建一個新的mapping。
設置mapping
POST /library????????????????? #給索引為library創建映射關系
{
?????"settings":{//分片的設置
?????"number_of_shards" : 5,
?????"number_of_replicas" : 1
??????},
??????"mappings":{
??????? ????"books":{ ? #索引為library的type類型為books
??????? ??????? "properties":{??????? #這里往下就是映射關系
??????? ??????????? "title":{"type":"string"},
??????? ????????????"name":{"type":"string","index":"not_analyzed"},
??????? ??????????? "publish_date":{"type":"date","index":"not_analyzed"},
??????? ??????????? "price":{"type":"double"},
??????? ??????????? "number":{
??????? ??????????????? "type":"object",
??????? ??????????????? "dynamic":true
???????????????????? }
??????? ????????? }
??????? ???? ??}
??????? ?}
}
獲取mapping
GET library/_mapping
{
?? "library": {
????? "mappings": {
???????? "books": {
??????????? "properties": {
?????????????? "name": {
????????????????? "type": "string",
????????????????? "index": "not_analyzed"
?????????????? },
?????????????? "number": {
????????????????? "type": "object",
????????????????? "dynamic": "true"
?????????????? },
?????????????? "price": {
????????????????? "type": "double"
?????????????? },
?????????????? "publish_date": {
????????????????? "type": "date",
????????????????? "format": "dateOptionalTime"
?????????????? },
?????????????? "title": {
????????????????? "type": "string"
?????????????? }
??????????? }
???????? }
????? }
?? }
}
term (查詢詞):一個查詢詞是一個被 Elasticsearch 索引的確切值。查詢詞 foo,Foo,FOO 是不同的。查詢詞可以使用查詢詞查詢接口進行獲取。
"query": {
??? "term": {
????? "age": "39"
??? }
? }類似的terms
?"query" : {
??????? "constant_score" : {
??????????? "filter" : {
??????????????? "terms" : {
??????????????????? "price" : [20, 30]
??????????????? }
??????????? }
??????? }
??? }
analysis 分析:分析是將文本 ( text ) 轉化為查詢詞 ( term ) 的過程。比如這三種短語:FOO BAR,Foo-Bar,foo,bar 都有可能被分解成查詢詞 foo 與 bar。可以使用不同的分析器,這些查詢詞實際上將被存儲在索引中。一次對 FoO:bAR 的全文查詢 ( 不是查詢詞查詢 ) 可能會被分析為為查詢詞 foo,bar,可以匹配上保存在索引中的查詢詞。這就是分析處理過程(包含了索引與搜索),它使得 es 可以進行全文查詢。
routing (路由):當我們索引一個document時,它將被保存在一個主分片上,分片的選擇是通過路由值哈希得到的。默認情況下,路由值使用文檔的 id,如果該文檔指定了父文檔,則路由值使用父文檔 id。這是為了確保子文檔和父文檔被保存在相同的分片上。該值可以在索引時指定,也可以通過映射路由字段來指定。
當你索引一個文檔,它被存儲在單獨一個主分片上。Elasticsearch是如何知道文檔屬于哪個分片的呢?當你創建一個新文檔,它是如何知道是應該存儲在分片1還是分片2上的呢?
進程不能是隨機的,因為我們將來要索引文檔。事實上,它根據一個簡單的算法決定:
shard = hash(_routing) % number_of_primary_shards
_routing值是一個任意字符串,它默認是_id但也可以自定義。這個_routing字符串通過哈希函數生成一個數字,然后除以主分片的數量得到一個余數(remainder),余數的范圍永遠是0到number_of_primary_shards - 1,這個數字就是特定文檔所在的分片。
=============================================================================
與數據庫概念的映射關系:
| Elasticsearch | RDBMS |
| Elasticsearch | Relational DB |
| Indices(索引) | Databases |
| Types(類型) | Tables |
| Documents(文檔) | Rows |
| Fields(字段) | Columns |



















