為什么選擇做班級管理系統
Accuracy is a go-to metric because it’s highly interpretable and low-cost to evaluate. For this reason, accuracy — perhaps the most simple of machine learning metrics — is (rightfully) commonplace. However, it’s also true that many people are too comfortable with accuracy.
準確性是首選指標,因為它具有很高的解釋性和低成本。 因此,準確性(也許是機器學習指標中最簡單的一種)(理所應當)是司空見慣的。 然而,這也是事實,很多人都太舒服的準確性。
Being aware of the limitations of accuracy is essential.
意識到準確性的局限性是至關重要的。
Everyone knows that accuracy is misused on unbalanced datasets: for instance, in a medical condition dataset, where the majority of people do not have condition x (let’s say 95%) and the remainder do have condition x.
每個人都知道在不平衡的數據集上濫用了準確性:例如,在醫療狀況數據集中,大多數人沒有狀況x (比如說95%),其余人確實有狀況x 。
Since machine learning models are always looking for the easy way out, and especially if an L2 penalization is used (a proportionately less penalty on lower errors), the model can comfortably get away with 95% accuracy only guessing all inputs do not have condition x.
由于機器學習模型一直在尋找簡便的方法,特別是如果使用L2懲罰(對較低的錯誤按比例減少的懲罰),則僅憑猜測所有輸入都沒有條件x即可輕松獲得95%的精度的模型。
The reply to this common issue is to use some sort of metric that takes into account the unbalanced classes and somehow compensates lack of quantity with a boost of importance, like an F1 score or balanced accuracy.
解決此常見問題的方法是使用某種度量標準,該度量標準考慮了不平衡的類別,并以某種重要的方式補償了數量不足的情況,例如F1得分或平衡準確性。
Beyond this common critique, however — which doesn’t address other limitations of accuracy — there are some other problems with using accuracy that go beyond just dealing with balanced classes.
但是,除了這種常見的批評之外(沒有解決準確性的其他限制),使用準確性還有其他一些問題,這些問題不僅僅涉及平衡類。
Everyone agrees that training/testing and deployment of a model should be kept separate. More specifically, the former should be statistical, and the latter should be decision-based. However, there is nothing statistical about turning the outputs of machine learning models — which are (almost) always probabilistic — into decisions, and evaluating its statistical goodness based on this converted output.
每個人都同意,應分開進行模型的培訓/測試和部署。 更具體地說,前者應該是統計的,而后者應該是基于決策的。 但是,沒有關于將機器學習模型的輸出(幾乎總是概率)轉化為決策,并基于轉換后的輸出評估其統計優勢的統計信息。
Take a look at the outputs for two machine learning models: should they really be getting the same results? Moreover, even if one tries to remedy accuracy with other decision-based metrics like the commonly prescribed specificity/sensitivity or F1 score, the same problem exists.
看一下兩個機器學習模型的輸出:它們是否真的會得到相同的結果? 此外,即使人們試圖用其他基于決策的指標(如通常規定的特異性/敏感性或F1分數)來糾正準確性,也存在相同的問題。
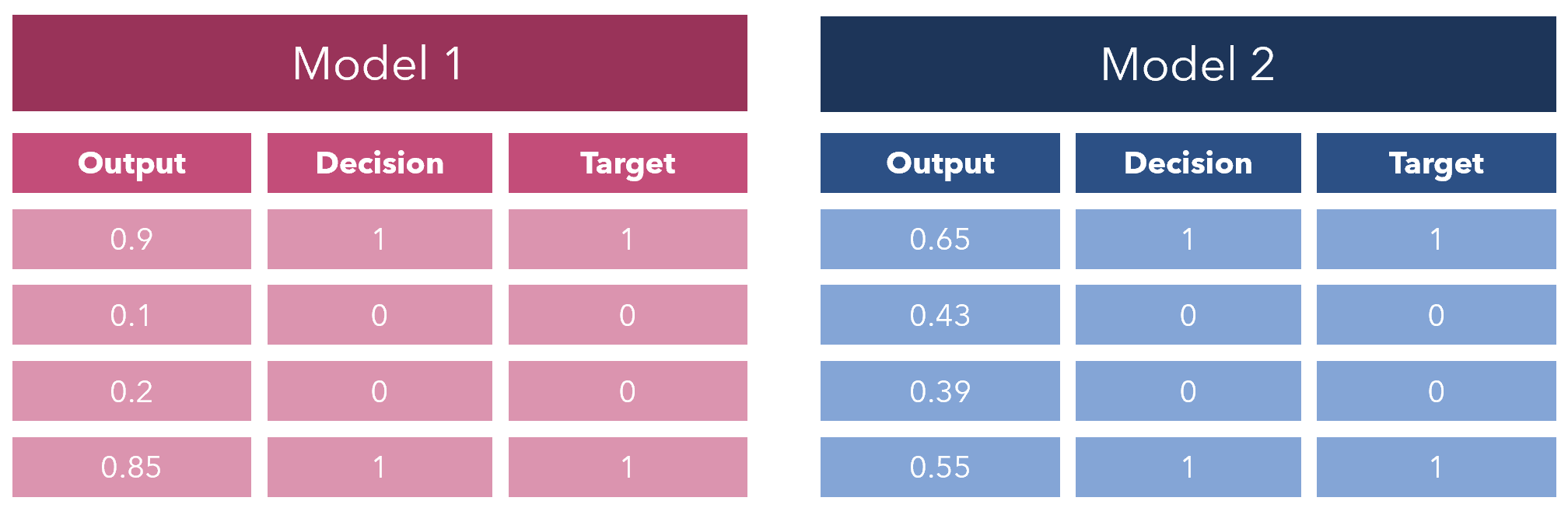
Model 2 is far less confident in its results than Model 1 is, but both receive the same accuracy. Accuracy is not a legitimate scoring rule, and hence it is deceiving in an inherently probabilistic environment.
模型2對結果的信心遠不如模型1可靠,但兩者的準確性相同。 準確性不是一個合理的評分規則,因此它在固有的概率環境中具有欺騙性。
While it can be used in the final presenting of a model, it leaves an empty void of information pertaining to the confidence of the model; whether it actually knew the class for most of the training samples or if it was only lucky in crossing on the right side of the 0.5 threshold.
雖然可以在模型的最終展示中使用它,但它留下了與模型的置信度有關的信息的空白; 無論是實際上對大多數訓練樣本都知道這門課,還是只是幸運地越過了0.5個閾值的右側。
This is also problematic. How can a reliable loss function — the guiding light that shows the model what is right and what is wrong — completely tilt its decision 180 degrees if the output probability shifts 0.01%? If a training sample with label ‘1’ received predictions 0.51 and 0.49 from model 1 and model 2, respectively, is it fair that model 2 is penalized at the full possible value? Thresholds, while necessary for decision-making in a physically deterministic world, are too sensitive and hence inappropriate for training and testing.
這也是有問題的。 如果輸出概率偏移0.01%,可靠的損失函數(顯示模型正確與錯誤的指示燈)如何將其決策完全傾斜180度? 如果帶有標簽“ 1”的訓練樣本分別從模型1和模型2接收到預測0.51和0.49,那么將模型2懲罰為可能的全部值是否公平? 閾值雖然在物理確定性世界中進行決策是必需的,但過于敏感,因此不適用于培訓和測試。
Speaking of thresholds — consider this. You are creating a machine learning model to decide if a patient should receive a very invasive and painful surgery treatment. Where do you decide the threshold to give the recommendation? Instinctively, most likely not at a default 0.5, but at some higher probability: the patient is subjected to this treatment if, and only if, the model is absolutely sure. On the other hand, if the treatment is something less serious like an aspirin, it is less so.
說到閾值,請考慮一下。 您正在創建一個機器學習模型,以決定患者是否應該接受侵入性和痛苦性極高的手術治療。 您在哪里確定提出建議的門檻? 本能地,最有可能不是默認值0.5,而是更高的概率:當且僅當模型是絕對確定的,患者才接受這種治療。 另一方面,如果像阿斯匹林這樣的不那么嚴重的治療方法,那么情況就不那么嚴重了。
The results of the decision dictate the thresholds for forming it. This idea, hard-coding morality and human feeling into a machine learning model, is difficult to think about. One may be inclined to argue that over time and under the right balanced circumstances, the model will automatically shift its output probability distributions to a 0.5 threshold and manually adding a threshold is tampering with the model’s learning.
決策的結果決定了形成決策的閾值。 將道德和人類感覺硬編碼到機器學習模型中的想法很難考慮。 有人可能會爭辯說,隨著時間的流逝,在正確的平衡情況下,該模型將自動將其輸出概率分布更改為0.5閾值,而手動添加閾值會篡改該模型的學習。
The rebuttal would be to not use decision-based scoring functions in the first place, not hard-coding any number, including a 0.5 threshold, at all. This way, the model learns not to cheat and take the easy way out through artificially constructed continuous-to-discrete conversions but to maximize its probability of correct answers.
反對是首先不使用基于決策的評分功能,根本不硬編碼任何數字,包括0.5閾值。 這樣,該模型就不會通過人工構造的連續到離散轉換來欺騙并采取簡單的方法,而是最大限度地提高其正確答案的可能性。
Whenever a threshold is introduced in the naturally probabilistic and fluid nature of machine learning algorithms, it causes more problems than it fixes.
每當在機器學習算法的自然概率和流動性中引入閾值時,它都會引起更多的問題,而不是要解決的問題。
Loss functions that treat probability on the continuous scale it is instead of as discrete buckets are the way to go.
損失函數在連續尺度上處理概率,而不是像離散的桶那樣走。
What are some better, probability-based, and more informative metrics to use for honestly evaluating a model’s performance?
有什么更好的,基于概率的,更多信息的指標可用于誠實地評估模型的性能?
- Brier score 刺分數
- Log score 日志分數
- Cross-entropy 交叉熵
In the end, accuracy is an important and permanent part of the metrics family. But for those who decide to use it: understand that accuracy’s interpretability and simplicity comes at a heavy cost.
最后,準確性是指標系列的重要且永久的組成部分。 但是對于那些決定使用它的人:請理解準確性的可解釋性和簡單性要付出沉重的代價。
翻譯自: https://medium.com/analytics-vidhya/why-accuracy-is-troublesome-even-with-balanced-classes-590b405f5a06
為什么選擇做班級管理系統
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390028.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390028.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390028.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
使用Chrome開發者工具調試Android端內網頁(微信,QQ,UC,App內嵌頁等)

517. 超級洗衣機

netflix的準實驗面臨的主要挑戰

網站漏洞檢測針對區塊鏈網站安全分析


微觀計量經濟學_微觀經濟學與數據科學


1436. 旅行終點站

如何使用fio模擬線上環境

熊貓數據集_熊貓邁向數據科學的第二部分

Python基礎綜合練習

POJ 3608 旋轉卡殼

405. 數字轉換為十六進制數

為什么我要重新開始數據科學

藍牙協議 HFP,HSP,A2DP,A2DP_CT,A2DP_TG,AVRCP,OPP,PBAP,SPP,FTP,TP,DTMF,DUN,SDP

482. 密鑰格式化

安裝mariadb、安裝Apache

數據科學的發展_數據科學的發展與發展

Polling 、Long Polling 和 WebSocket
