紋個雞兒天才小熊貓
A popular Python library used by those working with data is pandas, an easy and flexible data manipulation and analysis library. There are a myriad of awesome methods and functions in pandas, some of which are probably less well-known than others. With this in mind, I have 5 tips on how these less common (at least in my opinion) methods and functions may be useful in case you don’t already know them ?:
pandas是供數據處理人員使用的流行Python庫, pandas是一種簡單而靈活的數據處理和分析庫。 熊貓中有許多很棒的方法和功能,其中一些可能不那么知名。 考慮到這一點,我為您提供了5個技巧,以防萬一您不了解這些不常見的方法和功能(至少在我看來)be:
Does any of these look interesting or unfamiliar to you? 💭 I hope the answer is ‘yes’ or at least ‘maybe’. In this post, I will go through each one of them and explain what I mean and illustrate how they are useful.
這些對您來說看起來有趣還是陌生? 💭我希望答案是“是”或至少是“也許”。 在這篇文章中,我將逐一介紹它們,解釋我的意思并說明它們的用處。
0. Python設置🔧 (0. Python setup 🔧)
I assume the reader (👀 yes, you!) has: ???? access to and is familiar with Python including installing packages, defining functions and other basic tasks?? working knowledge using pandas including basic data manipulation.
我假設讀者(👀是的,您!)具有:????訪問并熟悉Python,包括安裝軟件包,定義函數和其他基本任務??使用熊貓的工作知識,包括基本數據操作。
If you are new to Python, this is a good place to get started. If you haven’t used pandas before, this is a good resource to check out.
如果您不熟悉Python,那么這是一個入門的好地方。 如果您以前沒有使用過熊貓,那么這是檢查的好資源。
I have used and tested the scripts in Python 3.7.1 in Jupyter Notebook. Let’s make sure you have the right tools before we dive in.
我在Jupyter Notebook中使用并測試了Python 3.7.1中的腳本。 在開始之前,請確保您擁有正確的工具。
????確保所需的軟件包已安裝熊貓和seaborn (?? ?Ensure required packages are installed pandas and seaborn)
We will use the following powerful third party packages:
我們將使用以下功能強大的第三方軟件包:
pandas: Data analysis library and
熊貓 :數據分析庫和
seaborn: Visualisation library (to import a toy dataset).
seaborn:可視化庫(用于導入玩具數據集)。
1.數據📦 (1. Data 📦)
We will use seaborn’s dataset on tips to exemplify my tips. (Did you get it? … my pun… 😆):
我們將在提示上使用seaborn的數據集以舉例說明我的提示。 (你明白了嗎?……我的雙關語……):
# Import packages
import pandas as pd
import seaborn as sns# Import data
df = sns.load_dataset('tips')
print(f"{df.shape[0]} rows and {df.shape[1]} columns")
df.head()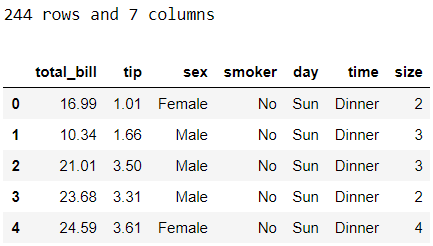
Details about this dataset including data dictionary can be found here (this source is actually for R, but it appears to be referring to the same underlying dataset). I have quoted their data description below for quick access:
可以在此處找到有關此數據集的詳細信息,包括數據字典(此來源實際上是R的來源,但似乎是指相同的基礎數據集)。 為了快速訪問,我在下面引用了它們的數據描述:
“One waiter recorded information about each tip he received over a period of a few months working in one restaurant.”
“一位服務員記錄了在一家餐館工作幾個月后收到的每條小費的信息。”
2.提示🌟 (2. Tips 🌟)
📍技巧1:使用query()進行過濾 (📍 Tip #1: Filter with query())
Let’s start with my favourite tip! Say we wanted to filter the data to those who tipped more than $6 with $30+ total bill. One common way to accomplish this is to use:
讓我們從我最喜歡的提示開始! 假設我們想過濾那些向總費用超過30美元的小費超過6美元的用戶提供數據。 實現此目的的一種常見方法是使用:
df.loc[(df['tip']>6) & (df['total_bill']>=30)]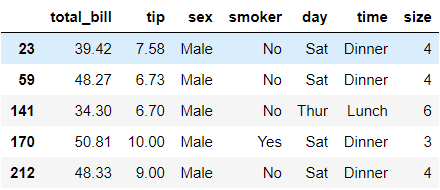
This does the job, but don’t you think it’s little too verbose: each condition requires reference to the dataframe and a parenthesis wrapping if there are multiple conditions. Now, let me show you how we could achieve the same outcome with more elegant code with query():
這可以完成工作,但是您不認為它太冗長了嗎:如果存在多個條件,則每個條件都需要引用數據框和括號括起來。 現在,讓我向您展示如何通過使用query()編寫更優雅的代碼來實現相同的結果:
df.query("tip>6 & total_bill>=30")You see how clean, simple and readable this looks? We are not repeatedly typing df or overloading with brackets and parentheses anymore. With less keystrokes, it’s also quicker to write code and code will be less prone to mistakes. A few more additional tips on query():
您看這看起來多么干凈,簡單和可讀? 我們不再重復輸入df或使用方括號和括號重載。 按鍵次數減少,編寫代碼的速度也會更快,并且代碼更不會出錯。 有關query()的其他一些提示:
# reference global variable name with @
median_tip = df['tip'].median()
display(df.query("tip>@median_tip").head())
# wrap column name containing . with backtick: `
df.rename(columns={'total_bill':'total.bill'}, inplace=True)
display(df.query("`total.bill`<20").head())
df.rename(columns={'total.bill':'total_bill'}, inplace=True)
# wrap string condition with single quotes (this is what I like)
display(df.query("day=='Sat'").head())
# could also do it the other way around (i.e. 'day=="Sat"')
📍技巧2:使用display()顯示多個數據框 (📍 Tip #2: Show multiple dataframes with display())
I have already given this away in the previous code, so you could probably guess what this one is about. Assume we wanted to inspect both head and tail of the df in one cell of Jupyter Notebook. If we run the following code, it will only show the tail:
我已經在之前的代碼中給出了這一點,所以您可能會猜到這是關于什么的。 假設我們要在Jupyter Notebook的一個單元中檢查df的頭和尾。 如果我們運行以下代碼,它將僅顯示尾部:
df.head()
df.tail()
We can get around this with display():
我們可以通過display()解決這個問題:
display(df.head())
display(df.tail())
In the last line, display() is redundant but it is there for consistency. It works the same way if we take out display() from the last line:
在最后一行, display()是多余的,但為了保持一致性而存在。 如果我們從最后一行中取出display() ,則其工作方式相同:
display(df.head())
df.tail()📍技巧3a:按多列排序時使用布爾列表 (📍 Tip #3a: Use a list of booleans when sorting by multiple columns)
I have two tips on sorting. The first one is for sorting multiple columns.
我有兩個分類提示。 第一個是對多列進行排序。
Have you ever had to sort your data with multiple columns in different directions? Here is an example of what I mean: Sort the data by total bill in ascending order and break ties with amount of tip in descending order.
您是否曾經不得不以不同方向對多列數據進行排序? 這是我的意思的一個示例:按總帳單按升序對數據進行排序,按小費金額按降序按平局聯系。
Before I knew tip #3a, I would create an interim column to flip the scale of either total bill or tip to make all the relevant columns to have the same direction and sort afterwards (I have flipped tip in this example):
在我知道小費#3a之前,我將創建一個臨時列以翻轉總帳單或小費的比例,以使所有相關列具有相同的方向并隨后進行排序(在此示例中,我已翻轉小費):
df['rev_tip'] = -df['tip']
df.sort_values(by=['total_bill', 'rev_tip'], ascending=True).head()
This is a workaround but not very elegant way to tackle the task. Let’s delete rev_tip with del df['rev_tip']. Instead, we could pass a list of booleans to indicate the order for each variable for sorting:
這是一種解決方法,但不是很好的解決方法。 讓我們用del df['rev_tip']刪除rev_tip。 相反,我們可以傳遞一個布爾值列表來指示每個變量的排序順序:
df.sort_values(by=[‘total_bill’, ‘tip’], ascending=[True, False]).head()
Not only do we not need to create an extra column, the last code also looks cleaner and more readable.
我們不僅不需要創建額外的列,而且最后的代碼看起來也更清晰易讀。
It’s also possible to use the numerical representation of booleans. That is, if we change to ascending =[1,0], it will also give us the same output.
也可以使用布爾值的數字表示形式。 也就是說,如果我們更改為ascending =[1,0] ,它也會給我們相同的輸出。
📍技巧3b:使用nsmallest()或nlargest() (📍 Tip #3b: Use nsmallest() or nlargest())
This second tip will come in handy if you ever had to quickly check out data extract for records that have the smallest or largest values in a particular column. Using nsmallest(), we could check out 5 records with the smallest total bill like this:
如果您不得不快速檢出數據提取以獲取特定列中具有最小或最大值的記錄,那么第二條技巧將非常有用。 使用nsmallest(),我們可以檢查出5條總賬單最小的記錄,如下所示:
df.nsmallest(5, 'total_bill')
This is a short form for:
這是以下內容的縮寫:
df.sort_values(by='total_bill').head()Similarly, the outputs of these two lines are identical:
同樣,這兩行的輸出是相同的:
display(df.nlargest(5, 'total_bill'))
display(df.sort_values(by='total_bill', ascending=False).head())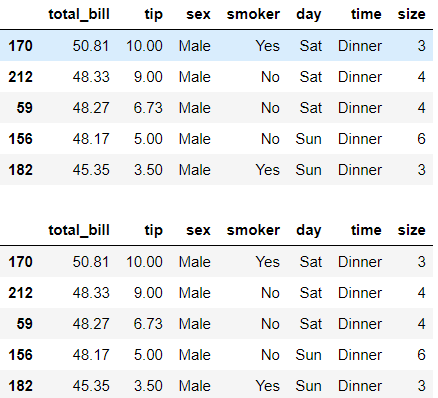
📍技巧4。 自定義describe() (📍 Tip #4. Customise describe())
Any pandas user is probably familiar with df.describe(). This shows summary stats for numerical columns. But we can get more than that by specifying its arguments.
任何熊貓用戶都可能熟悉df.describe() 。 這顯示了數字列的摘要統計信息。 但是,通過指定其參數,我們可以獲得更多的收益。
Firstly, let’s check out the column types:
首先,讓我們檢查一下列類型:
df.info()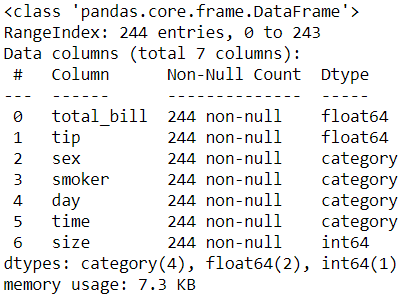
In our dataframe, we have numerical and categorical columns. Let’s see summary stats for all columns by adding include='all':
在我們的數據框中,我們有數值和類別列。 讓我們通過添加include='all'來查看所有列的摘要統計信息:
df.describe(include='all')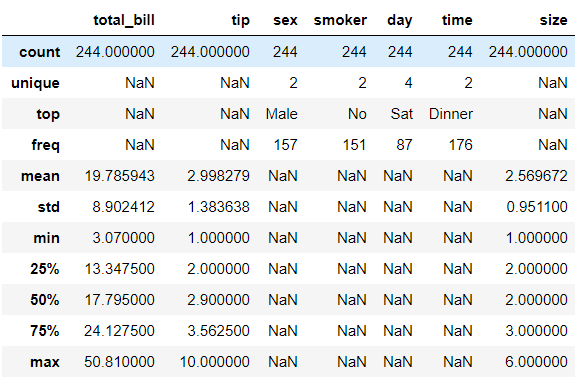
This is cool but a little messy. Let’s show the summary stats by column types separately with the following script:
這很酷,但有點混亂。 讓我們用以下腳本分別按列類型顯示摘要狀態:
display(df.describe(include=['category'])) # categorical types
display(df.describe(include=['number'])) # numerical types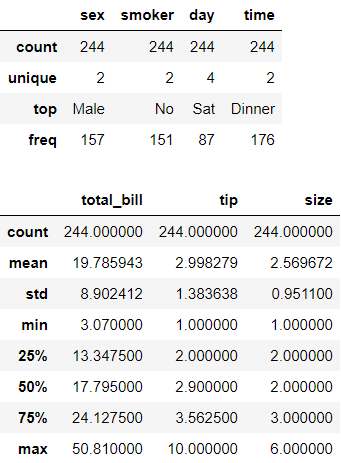
Do you like this better? If we had both strings and categorical columns and wished to display the summary stats for both in one table, we can use either: include=['category', 'object'] or exclude=['number']. If you are curious to learn more, check out the documentation.
你更喜歡這個嗎? 如果我們同時具有字符串和類別列,并希望在一個表中同時顯示兩者的摘要統計信息,則可以使用: include=['category', 'object']或exclude=['number']. 如果您想了解更多信息,請查閱文檔 。
📍技巧5:更新默認顯示設置 (📍 Tip #5: Update default display settings)
This last tip is probably more well-known than the rest. Let’s see some examples of useful display settings to change.
這最后一個技巧可能比其余的更廣為人知。 讓我們看一些有用的顯示設置更改示例。
Firstly, we can check out the current default limit for maximum number of columns and rows to be displayed with the code below:
首先,我們可以使用以下代碼查看當前默認限制,以顯示最大列數和行數:
print(f"{pd.options.display.max_columns} columns")
print(f"{pd.options.display.max_rows} rows")
This means if we try to display a dataframe with more than 20 columns, we only get to see the first 10 and final 10 (total of 20 columns shown) while the rest will be truncated as three dots. The same logic applies to rows. Often, we may want to see more than these maximums. If we want to change this behaviour, we can do so like this:
這意味著,如果我們嘗試顯示一個包含超過20列的數據框,我們只會看到前10個和最后10個(顯示的共20列),而其余部分將被截斷為三個點。 相同的邏輯適用于行。 通常,我們可能希望看到的不僅僅是這些最大值。 如果我們想改變這種行為,我們可以這樣做:
pd.options.display.max_columns = None
pd.options.display.max_rows = NoneHere, we are asking pandas to display every row and column without any limit. This may or may not be a good idea depending on how big your dataframe is. We can also set these options to a number of our choice:
在這里,我們要求熊貓無限制地顯示每一行和每一列。 根據數據框的大小,這可能不是一個好主意。 我們還可以將這些選項設置為多種選擇:
pd.options.display.max_columns = 50
pd.options.display.max_rows = 100Secondly, depending on the scale of the numerical variables you are working on, you may sometimes encounter scientific notations for very large or very small numbers when working with pandas. If you find it easier to read numbers as 1200 and 0.012 compared to 1.2e3 and 1.2e-2 respectively, you are likely to find this line of code handy:
其次,根據正在處理的數字變量的大小,在處理大熊貓時,有時可能會遇到非常大或非常小的數字的科學計數法。 如果您發現讀取數字1200和0.012比分別使用1.2e3和1.2e-2更容易,則可能會發現以下這行代碼很方便:
pd.options.display.float_format = ‘{:.4f}’.format # 4 decimal placesThis ensures that you will see real numbers instead of scientific notations.
這樣可以確保您看到的是實數而不是科學計數法。
If you are curious to learn more about other options to customise, check out the documentation.
如果您想了解更多有關其他定制選項的信息,請查閱文檔 。
Voila? These were my current top tips for a pandas user!
這些是我目前對熊貓用戶的最高提示!
Thank you for reading my post. Hope you find my tips useful ??. If you are interested to learn more about pandas, here is a link to my other post:??? How to transform variables in a pandas DataFrame
感謝您閱讀我的帖子。 希望您發現我的技巧有用useful?。 如果您有興趣了解有關熊貓的更多信息,請訪問我的另一篇文章鏈接:??? 如何在熊貓DataFrame中轉換變量
Bye for now 🏃💨
再見for
翻譯自: https://towardsdatascience.com/5-tips-for-pandas-users-e73681d16d17
紋個雞兒天才小熊貓
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388970.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388970.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388970.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

本人服務器遭受黑客長期攻擊,特把這幾天做的一些有用的安全方面總結出來,以方便以后查閱


代碼 摳圖_3 行 Python 代碼 5 秒摳圖的 AI 神器,根本無需 PS,附教程

python函數使用易錯舉例

圖像離群值_什么是離群值?

混合模型和EM---混合高斯

永恒python地速_立竿見影地把你的 Python 代碼提速7倍

頂尖大學實驗室的科研方法_這是來自頂尖大學的5門免費自然語言處理課程

Python學習---django知識補充之CBV

「CH2101」可達性統計 解題報告
![藍圖解鎖怎么用_[UE4藍圖][Materials]虛幻4中可互動的雪地材質完整實現(一)](http://pic.xiahunao.cn/藍圖解鎖怎么用_[UE4藍圖][Materials]虛幻4中可互動的雪地材質完整實現(一))
藍圖解鎖怎么用_[UE4藍圖][Materials]虛幻4中可互動的雪地材質完整實現(一)

數據預處理工具_數據預處理


在網上收集了一部分關于使用Google API進行手機定位的資料和大家分享

background圖片疊加_css怎么讓兩張圖片疊加,不用background只用img疊加

“入鄉隨俗,服務為主” 發明者量化兼容麥語言啦!

自考數據結構和數據結構導論_我跳過大學自學數據科學

爬取LeetCode題目——如何發送GraphQL Query獲取數據

