Hello,這里是Token_w的博客,歡迎您的到來
今天文章講解的是Python中的字符串與字符編碼,其中有基礎的理論知識講解,也有實戰中的應用講解,希望對你有所幫助
整理不易,如對你有所幫助,希望能得到你的點贊、收藏支持。感謝
目錄
- 一. 前言
- 二. 相關概念
- 2.1 字符與字節
- 2.2 編碼與解碼
- 三. Python中的默認編碼
- 3.1 Python源代碼文件的執行過程
- 3.2 默認編碼
- 3.3 最佳實踐
- 四. Python2與Python3中對字符串的支持
- (1) Python2
- (2) Python3
- 五. 字符編碼轉換
- 附六.字符編碼
- 1. ASCII碼
- 2. 擴展ASCII碼(Extended ASCII)
- 3. Unicode
- 4. GB2312
- 5. GBK
- 6. GB18030
- 7. UTF(UCS Transfer Format)
- 8. 簡單總結
一. 前言
Python中的字符編碼是個老生常談的話題,同行們都寫過很多這方面的文章。有的人云亦云,也有的寫得很深入。近日看到某知名培訓機構的教學視頻中再次談及此問題,講解的還是不盡人意,所以才想寫這篇文字。一方面,梳理一下相關知識,另一方面,希望給其他人些許幫助。
Python2的 默認編碼 是ASCII,不能識別中文字符,需要顯式指定字符編碼;Python3的 默認編碼 為Unicode,可以識別中文字符。
相信大家在很多文章中都看到過類似上面這樣“對Python中中文處理”的解釋,也相信大家在最初看到這樣的解釋的時候確實覺得明白了。可是時間久了之后,再重復遇到相關問題就會覺得貌似理解的又不是那么清楚了。如果我們了解上面說的默認編碼的作用是什么,我們就會更清晰的明白那句話的含義。
二. 相關概念
2.1 字符與字節
一個字符不等價于一個字節,字符是人類能夠識別的符號,而這些符號要保存到計算的存儲中就需要用計算機能夠識別的字節來表示。一個字符往往有多種表示方法,不同的表示方法會使用不同的字節數。這里所說的不同的表示方法就是指字符編碼,比如字母A-Z都可以用ASCII碼表示(占用一個字節),也可以用UNICODE表示(占兩個字節),還可以用UTF-8表示(占用一個字節)。字符編碼的作用就是將人類可識別的字符轉換為機器可識別的字節碼,以及反向過程。
UNICDOE才是真正的字符串,而用ASCII、UTF-8、GBK等字符編碼表示的是字節串。關于這點,我們可以在Python的官方文檔中經常可以看到這樣的描述"Unicode string" , " translating a Unicode string into a sequence of bytes"
我們寫代碼是寫在文件中的,而字符是以字節形式保存在文件中的,因此當我們在文件中定義個字符串時被當做字節串也是可以理解的。但是,我們需要的是字符串,而不是字節串。一個優秀的編程語言,應該嚴格區分兩者的關系并提供巧妙的完美的支持。JAVA語言就很好,以至于了解Python和PHP之前我從來沒有考慮過這些不應該由程序員來處理的問題。遺憾的是,很多編程語言試圖混淆“字符串”和“字節串”,他們把字節串當做字符串來使用,PHP和Python2都屬于這種編程語言。最能說明這個問題的操作就是取一個包含中文字符的字符串的長度:
- 對字符串取長度,結果應該是所有字符串的個數,無論中文還是英文
- 對字符串對應的字節串取長度,就跟編碼(encode)過程使用的字符編碼有關了(比如:UTF-8編碼,一個中文字符需要用3個字節來表示;GBK編碼,一個中文字符需要2個字節來表示)
注意:Windows的cmd終端字符編碼默認為GBK,因此在cmd輸入的中文字符需要用兩個字節表示
# Python2
a = 'Hello,中國' # 字節串,長度為字節個數 = len('Hello,')+len('中國') = 6+2*2 = 10
b = u'Hello,中國' # 字符串,長度為字符個數 = len('Hello,')+len('中國') = 6+2 = 8
c = unicode(a, 'gbk') # 其實b的定義方式是c定義方式的簡寫,都是將一個GBK編碼的字節串解碼(decode)為一個Uniocde字符串print(type(a), len(a))
# (<type 'str'>, 10)
print(type(b), len(b))
# (<type 'unicode'>, 8)
print(type(c), len(c))
# (<type 'unicode'>, 8)
Python3中對字符串的支持做了很大的改動,具體內容會在下面介紹。
2.2 編碼與解碼
先做下科普:UNICODE字符編碼,也是一張字符與數字的映射,但是這里的數字被稱為代碼點(code point), 實際上就是十六進制的數字。
Python官方文檔中對Unicode字符串、字節串與編碼之間的關系有這樣一段描述:
Unicode字符串是一個代碼點(code point)序列,代碼點取值范圍為0到0x10FFFF(對應的十進制為1114111)。這個代碼點序列在存儲(包括內存和物理磁盤)中需要被表示為一組字節(0到255之間的值),而將Unicode字符串轉換為字節序列的規則稱為編碼。
這里說的編碼不是指字符編碼,而是指編碼的過程以及這個過程中所使用到的Unicode字符的代碼點與字節的映射規則。這個映射不必是簡單的一對一映射,因此編碼過程也不必處理每個可能的Unicode字符,例如:
將Unicode字符串轉換為ASCII編碼的規則很簡單–對于每個代碼點:
-
如果代碼點數值<128,則每個字節與代碼點的值相同
-
如果代碼點數值>=128,則Unicode字符串無法在此編碼中進行表示(這種情況下,Python會引發一個UnicodeEncodeError異常)
將Unicode字符串轉換為UTF-8編碼使用以下規則: -
如果代碼點數值<128,則由相應的字節值表示(與Unicode轉ASCII字節一樣)
-
如果代碼點數值>=128,則將其轉換為一個2個字節,3個字節或4個字節的序列,該序列中的每個字節都在128到255之間。
簡單總結: -
編碼(encode):將Unicode字符串(中的代碼點)轉換特定字符編碼對應的字節串的過程和規則
-
解碼(decode):將特定字符編碼的字節串轉換為對應的Unicode字符串(中的代碼點)的過程和規則
可見,無論是編碼還是解碼,都需要一個重要因素,就是特定的字符編碼。因為一個字符用不同的字符編碼進行編碼后的字節值以及字節個數大部分情況下是不同的,反之亦然。
三. Python中的默認編碼
3.1 Python源代碼文件的執行過程
我們都知道,磁盤上的文件都是以二進制格式存放的,其中文本文件都是以某種特定編碼的字節形式存放的。對于程序源代碼文件的字符編碼是由編輯器指定的,比如我們使用Pycharm來編寫Python程序時會指定工程編碼和文件編碼為UTF-8,那么Python代碼被保存到磁盤時就會被轉換為UTF-8編碼對應的字節(encode過程)后寫入磁盤。當執行Python代碼文件中的代碼時,Python解釋器在讀取Python代碼文件中的字節串之后,需要將其轉換為UNICODE字符串(decode過程)之后才執行后續操作。
上面已經解釋過,這個轉換過程(decode,解碼)需要我們指定文件中保存的字節使用的字符編碼是什么,才能知道這些字節在UNICODE這張萬國碼和統一碼中找到其對應的代碼點是什么。這里指定字符編碼的方式大家都很熟悉,如下所示:
# -*- coding:utf-8 -*-
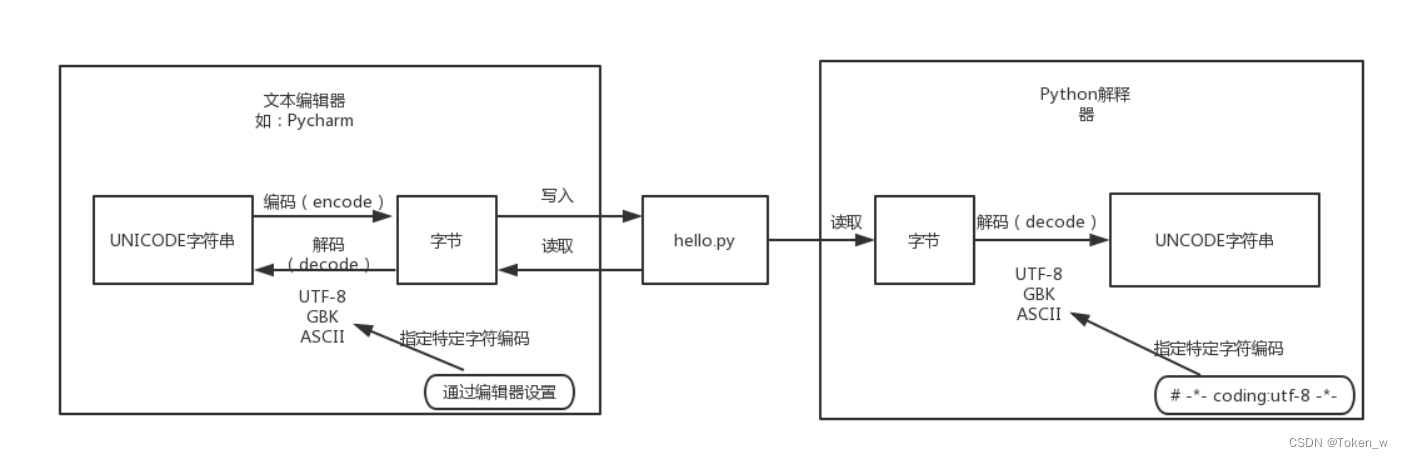
3.2 默認編碼
那么,如果我們沒有在代碼文件開始的部分指定字符編碼,Python解釋器就會使用哪種字符編碼把從代碼文件中讀取到的字節轉換為UNICODE代碼點呢?就像我們配置某些軟件時,有很多默認選項一樣,需要在Python解釋器內部設置默認的字符編碼來解決這個問題,這就是文章開頭所說的“默認編碼”。因此大家所說的Python中文字符問題就可以總結為一句話:當無法通過默認的字符編碼對字節進行轉換時,就會出現解碼錯誤(UnicodeEncodeError)。
Python2和Python3的解釋器使用的默認編碼是不一樣的,我們可以通過sys.getdefaultencoding()來獲取默認編碼:
# Python2
import sys
print(sys.getdefaultencoding() )
# 'ascii'# Python3
import sys
print(sys.getdefaultencoding() )
# 'utf-8'
因此,對于Python2來講,Python解釋器在讀取到中文字符的字節碼嘗試解碼操作時,會先查看當前代碼文件頭部是否有指明當前代碼文件中保存的字節碼對應的字符編碼是什么。如果沒有指定則使用默認字符編碼"ASCII"進行解碼導致解碼失敗,導致如下錯誤:
SyntaxError: Non-ASCII character '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
對于Python3來講,執行過程是一樣的,只是Python3的解釋器以"UTF-8"作為默認編碼,但是這并不表示可以完全兼容中文問題。比如我們在Windows上進行開發時,Python工程及代碼文件都使用的是默認的GBK編碼,也就是說Python代碼文件是被轉換成GBK格式的字節碼保存到磁盤中的。Python3的解釋器執行該代碼文件時,試圖用UTF-8進行解碼操作時,同樣會解碼失敗,導致如下錯誤:
SyntaxError: Non-UTF-8 code starting with '\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
3.3 最佳實踐
- 創建一個工程之后先確認該工程的字符編碼是否已經設置為UTF-8
- 為了兼容Python2和Python3,在代碼頭部聲明字符編碼:-- coding:utf-8 --
四. Python2與Python3中對字符串的支持
其實Python3中對字符串支持的改進,不僅僅是更改了默認編碼,而是重新進行了字符串的實現,而且它已經實現了對UNICODE的內置支持,從這方面來講Python已經和JAVA一樣優秀。下面我們來看下Python2與Python3中對字符串的支持有什么區別:
(1) Python2
Python2中對字符串的支持由以下三個類提供
class basestring(object)class str(basestring)class unicode(basestring)
執行help(str)和help(bytes)會發現結果都是str類的定義,這也說明Python2中str就是字節串,而后來的unicode對象對應才是真正的字符串。
#!/usr/bin/env python
# -*- coding:utf-8 -*-a = '你好'
b = u'你好'print(type(a), len(a))
print(type(b), len(b))
輸出結果:
(<type 'str'>, 6)
(<type 'unicode'>, 2)
(2) Python3
Python3中對字符串的支持進行了實現類層次的上簡化,去掉了unicode類,添加了一個bytes類。從表面上來看,可以認為Python3中的str和unicode合二為一了。
class bytes(object)
class str(object)
實際上,Python3中已經意識到之前的錯誤,開始明確的區分字符串與字節。因此Python3中的str已經是真正的字符串,而字節是用單獨的bytes類來表示。也就是說,Python3默認定義的就是字符串,實現了對UNICODE的內置支持,減輕了程序員對字符串處理的負擔。
#!/usr/bin/env python
# -*- coding:utf-8 -*-a = '你好'
b = u'你好'
c = '你好'.encode('gbk')print(type(a), len(a))
print(type(b), len(b))
print(type(c), len(c))
輸出結果:
<class 'str'> 2
<class 'str'> 2
<class 'bytes'> 4
五. 字符編碼轉換
上面提到,UNICODE字符串可以與任意字符編碼的字節進行相互轉換,如圖:
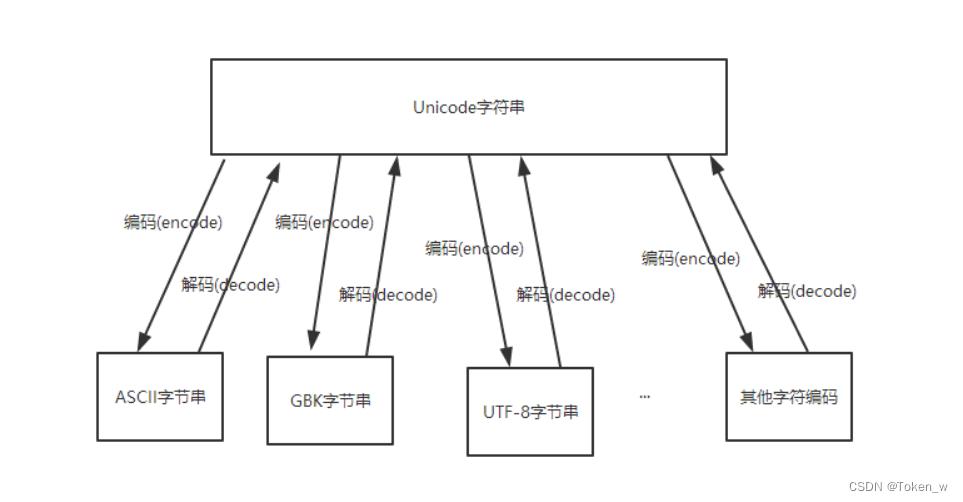
那么大家很容易想到一個問題,就是不同的字符編碼的字節可以通過Unicode相互轉換嗎?答案是肯定的。
Python2中的字符串進行字符編碼轉換過程是:
字節串–>decode(‘原來的字符編碼’)–>Unicode字符串–>encode(‘新的字符編碼’)–>字節串
#!/usr/bin/env python
# -*- coding:utf-8 -*-utf_8_a = '我愛中國'
gbk_a = utf_8_a.decode('utf-8').encode('gbk')
print(gbk_a.decode('gbk'))
輸出結果:
我愛中國
Python3中定義的字符串默認就是unicode,因此不需要先解碼,可以直接編碼成新的字符編碼:
字符串–>encode(‘新的字符編碼’)–>字節串
#!/usr/bin/env python
# -*- coding:utf-8 -*-utf_8_a = '我愛中國'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
輸出結果:
我愛中國
最后需要說明的是,Unicode不是有道詞典,也不是google翻譯器,它并不能把一個中文翻譯成一個英文。正確的字符編碼的轉換過程只是把同一個字符的字節表現形式改變了,而字符本身的符號是不應該發生變化的,因此并不是所有的字符編碼之間的轉換都是有意義的。怎么理解這句話呢?比如GBK編碼的“中國”轉成UTF-8字符編碼后,僅僅是由4個字節變成了6個字節來表示,但其字符表現形式還應該是“中國”,而不應該變成“你好”或者“China”。
前面花了很大的篇幅介紹概念和理論,后面注重實踐,希望對您有所幫助。
附六.字符編碼
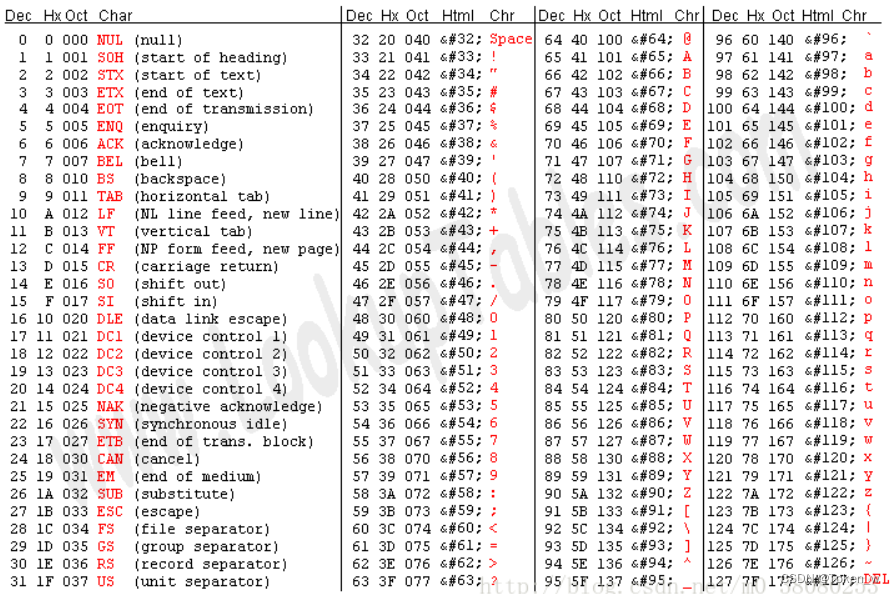
1. ASCII碼
ASCII碼是美國早期制定的編碼規范,只能表示128個字符,包括英文字符、阿拉伯數字、西文字符以及32個控制字符。簡單來說,就是下面這個表:
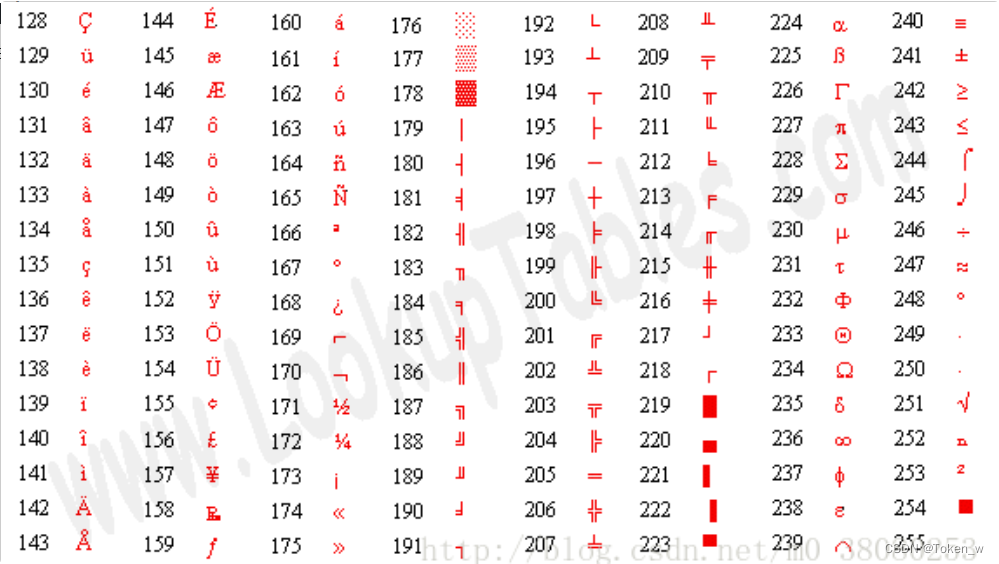
2. 擴展ASCII碼(Extended ASCII)
簡單而言,擴展ASCII碼的出現是因為ASCII不夠用,所以向ASCII表繼續擴充到256個符號。 但是因為對于擴展ASCII,不同的國家有不同的標準,于是促使了Unicode編碼的誕生。 擴展ASCII碼表如下:
3. Unicode
準確來說,Unicode不是編碼格式,而是字符集。這個字符集包含了世界上目前所有的符號。 另外,在原來有些字符可以用一個字節即8位來表示的,在Unicode將所有字符的長度全部統一為16位,因此字符是定長的。 Unicode是長這樣的:
\u4f60\u597d\u4e2d\u56fd\uff01\u0068\u0065\u006c\u006c\u006f\uff0c\u0031\u0032\u0033
上面這段Unicode的意思是“你好中國!hello,123”。
關于Unicode,可在這個網站查到所有字符: https://unicode-table.com/en/
4. GB2312
當國人得到計算機后,那就要對漢字進行編碼。在ASCII碼表的基礎上,小于127的字符意義與原來相同;而將兩個大于127的字節連在一起,來表示漢字,前一個字節從0xA1(161)到0xF7(247)共87個字節,稱為高字節,后一個字節從0xA1(161)到0xFE(254)共94個字節,稱為低字節,兩者可組合出約8000種組合,用來表示6763個簡體漢字、數學符號、羅馬字母、日文字等。 在重新編碼的數字、標點、字母是兩字節長的編碼,這些稱為“全角”字符;而原來在ASCII碼表的127以下的稱為“半角”字符。 簡單而言,GB2312就是在ASCII基礎上的簡體漢字擴展。
gb2312碼表: http://www.fileformat.info/info/charset/GB2312/list.htm
5. GBK
簡單而言,GBK是對GB2312的進一步擴展(K是漢語拼音kuo zhan(擴展)中“擴”字的聲母), 收錄了21886個漢字和符號,完全兼容GB2312。
6. GB18030
GB18030收錄了70244個漢字和字符,更加全面,與 GB 2312-1980 和 GBK 兼容。 GB18030支持少數民族的漢字,也包含了繁體漢字和日韓漢字。 其編碼是單、雙、四字節變長編碼的。
7. UTF(UCS Transfer Format)
UTF是在互聯網上使用最廣的一種Unicode的實現方式。我們最常用的是UTF-8,表示每次8個位傳輸數據,除此之外還有UTF-16。
UTF-8長這樣,“你好中國!hello,123”:
你好中國!hello,123
8. 簡單總結
- 中國人民通過對 ASCII 編碼的中文擴充改造,產生了 GB2312 編碼,可以表示6000多個常用漢字。
- 漢字實在是太多了,包括繁體和各種字符,于是產生了 GBK 編碼,它包括了 GB2312 中的編碼,同時擴充了很多。
- 中國是個多民族國家,各個民族幾乎都有自己獨立的語言系統,為了表示那些字符,繼續把 GBK 編碼擴充為 GB18030 編碼。
- 每個國家都像中國一樣,把自己的語言編碼,于是出現了各種各樣的編碼,如果你不安裝相應的編碼,就無法解釋相應編碼想表達的內容。
- 終于,有個叫 ISO 的組織看不下去了。他們一起創造了一種編碼 UNICODE ,這種編碼非常大,大到可以容納世界上任何一個文字和標志。所以只要電腦上有 UNICODE 這種編碼系統,無論是全球哪種文字,只需要保存文件的時候,保存成 UNICODE 編碼就可以被其他電腦正常解釋。
- UNICODE 在網絡傳輸中,出現了兩個標準 UTF-8 和 UTF-16,分別每次傳輸 8個位和 16個位。于是就會有人產生疑問,UTF-8 既然能保存那么多文字、符號,為什么國內還有這么多使用 GBK 等編碼的人?因為 UTF-8 等編碼體積比較大,占電腦空間比較多,如果面向的使用人群絕大部分都是中國人,用 GBK 等編碼也可以。

的技術精要)
)














![[Android 11]使用Android Studio調試系統應用之Settings移植(七):演示用AS編譯錯誤問題](http://pic.xiahunao.cn/[Android 11]使用Android Studio調試系統應用之Settings移植(七):演示用AS編譯錯誤問題)

