提高機器學習質量的想法
The ultimate goal of every data scientist or Machine Learning evangelist is to create a better model with higher predictive accuracy. However, in the pursuit of fine-tuning hyperparameters or improving modeling algorithms, data might actually be the culprit. There is a famous Chinese saying “工欲善其事,必先利其器” which literally translates to — To do a good job, an artisan needs the best tools. So if the data are generally of poor quality, regardless of how good a Machine Learning model is, the results will always be subpar at best.
每個數據科學家或機器學習傳播者的最終目標是創建一個具有更高預測準確性的更好模型。 但是,在追求微調超參數或改進建模算法時,數據實際上可能是罪魁禍首。 中國有句名言“工欲善其事,必先利其器”,字面意思是:要做好工作,工匠需要最好的工具。 因此,如果數據質量通常很差,那么無論機器學習模型的質量如何,結果總是最好的。
Why is data preparation so important?
為什么數據準備如此重要?

It is no secret that data preparation in the process of data analytics is ‘an essential but unsexy’ task and more than half of data scientists regard cleaning and organizing data as the least enjoyable part of their work.
眾所周知 ,數據分析過程中的數據準備是“一項必不可少的但并不性感的任務”, 超過一半的數據科學家將清理和整理數據視為工作中最不愉快的部分。
Multiple surveys with data scientists and experts have indeed confirmed the common 80/20 trope — whereby 80% of the time is mired in the mundane janitorial work of prepping data, from collecting, cleaning to finding insights of the data (data wrangling or munching); leaving only 20% for the actual analytic work by modeling and building algorithm.
與數據科學家和專家進行的多次調查確實證實了常見的80/20斜率-80%的時間都沉浸在準備數據的平凡的清潔工作中,從收集,清理到發現數據見解(數據整理或壓縮) ; 通過建模和構建算法只剩下20%的實際分析工作。
Thus, the Achilles heel of a data analytic process is in fact the unjustifiable amount of time spent on just data preparation. For data scientists, this can be a big hurdle in productivity for building a meaningful model. For businesses, this can be a huge blow to the resources as the investment into data analytics only sees the remaining one-fifth of the allocation dedicated to the original intent.
因此,數據分析過程的致命弱點實際上是僅僅花費在數據準備上的無用時間。 對于數據科學家而言,這對于構建有意義的模型可能是生產力的一大障礙。 對于企業而言,這可能是對資源的巨大打擊,因為對數據分析的投資僅看到剩余的五分之一專用于原始意圖。

Heard of GIGO (garbage in, garbage out)? This is exactly what happens here. Data scientists arrive at a task with a given set of data, with the expectation to build the best model to fulfill the goal of the task. But halfway thru the assignment, he realizes that no matter how good the model is he can never achieve better results. After going back-and-forth he finds out that there are lapses in data quality and started scrubbing thru the data to make them “clean and usable”. By the time the data are finally fit again, the dateline is slowly creeping in and resources started draining up, and he is left with a limited amount of time to build and refine the actual model he was hired for.
聽說過GIGO(垃圾進,垃圾出)嗎? 這正是這里發生的情況。 數據科學家使用給定的數據集完成一項任務,并期望構建最佳模型來實現任務目標。 但是在完成任務的途中,他意識到無論模型多么出色,他都永遠無法取得更好的結果。 經過反復研究,他發現數據質量存在問題,并開始對數據進行清理以使其“干凈且可用”。 等到數據終于重新適合時,日期線就慢慢爬進去,資源開始消耗drain盡,他只剩下有限的時間來建立和完善他所雇用的實際模型。
This is akin to a product recall. When defects are discovered in products already on the market, it is often too late to remedy and products have to be recalled to ensure the public safety of consumers. In most cases, the defects are results of negligence in quality control of the components or ingredients used in the supply chain. For example, laptops being recalled due to battery issues or chocolates being recalled due to contamination in the dairy produce. Be it a physical or digital product, the staggering similarity we see here is that it is always the raw material taking the blame.
這類似于產品召回。 如果在市場上已有的產品中發現缺陷,通常為時已晚,無法補救,必須召回產品以確保消費者的公共安全。 在大多數情況下,缺陷是供應鏈中使用的組件或成分的質量控制疏忽的結果。 例如,由于電池問題而召回筆記本電腦 ,或者由于乳制品中的污染而召回巧克力 。 無論是物理產品還是數字產品,我們在這里看到的驚人相似之處都在于,總是責怪原材料。
But if data quality is a problem, why not just improve it?
但是,如果數據質量有問題,為什么不僅僅改善它呢?
To answer this question, we first have to understand what is data quality.
要回答這個問題,我們首先必須了解什么是數據質量。
Tindependent quality as the measure of the agreement between data views presented and the same data in real-world based on inherent characteristics and features; secondly, the quality of dependent application — a measure of conformance of the data to user needs for intended purposes.
T 獨立質量是衡量基于固有特征和特征的數據視圖與現實世界中相同數據之間一致性的度量; 其次, 從屬應用程序的質量-衡量數據是否符合預期目的用戶需求的量度。
Let’s say you are a university recruiter trying to recruit fresh grads for entry-level jobs. You have a pretty accurate contact list but as you go thru the list you realize that most of the contacts are people over 50 years old, deeming it unsuitable for you to approach them. By applying the definition, this scenario fulfills only the first half of the complete definition — the list has the accuracy and consists of good data. But it does not meet the second criteria — the data, no matter how accurate are not suitable for the application.
假設您是一位大學招聘人員,正在嘗試為入門級工作招募應屆畢業生。 您有一個非常準確的聯系人列表,但是當您瀏覽列表時,您會意識到大多數聯系人都是50歲以上的人,認為不適合與他們聯系。 通過應用定義,此方案僅滿足完整定義的前半部分-列表具有準確性,并包含良好的數據。 但是它不符合第二個標準-數據,無論多么精確,都不適合該應用程序。
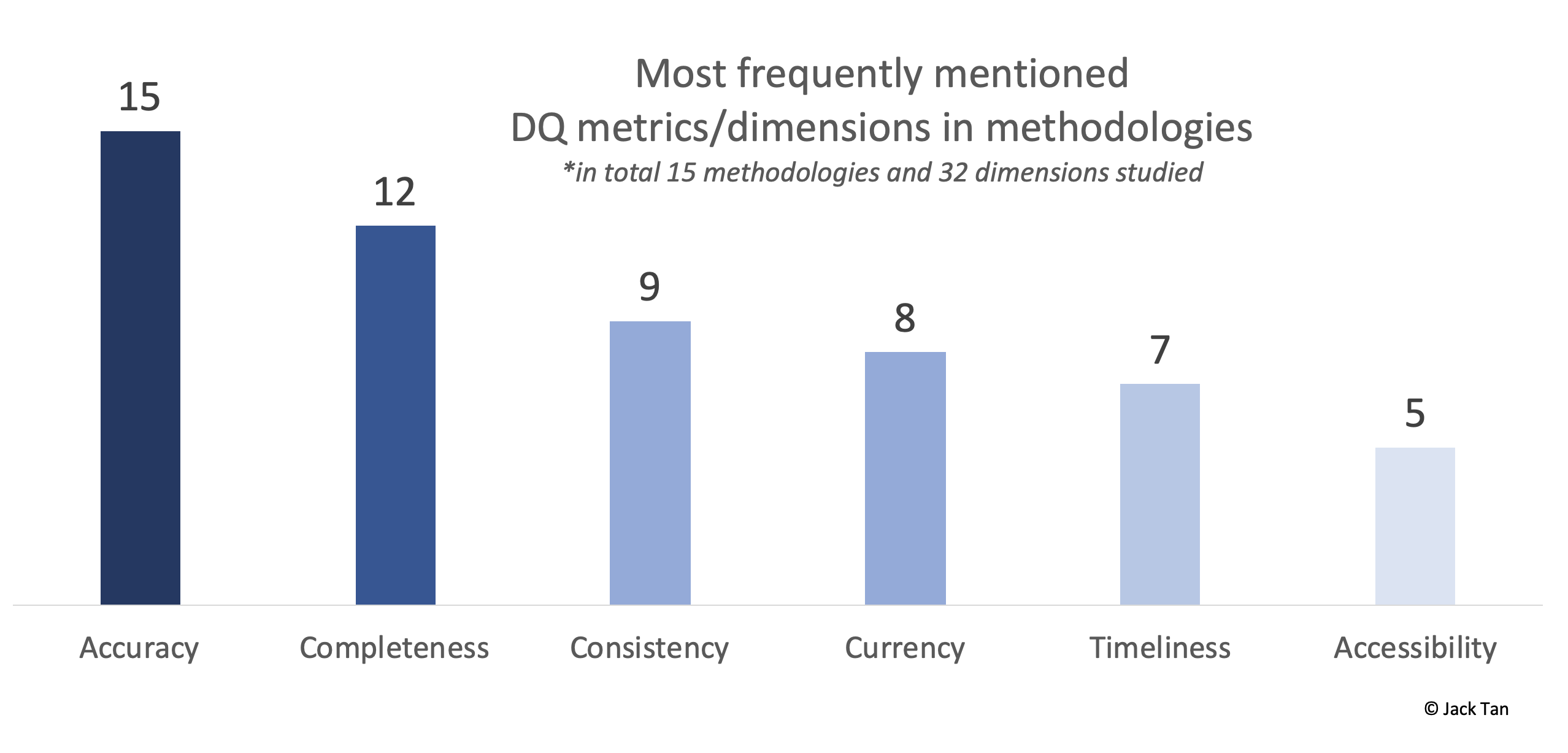
In this example, accuracy is the dimension we are looking at to assess the inherent quality of the data. There are a lot more different dimensions out there. To give you an idea of which dimensions are commonly studied and researched in peer-reviewed literature, here is a histogram showing the top 6 dimensions after studying 15 different data quality assessment methodologies involving 32 dimensions.
在此示例中,準確性是我們要評估的數據固有質量的維度。 那里還有更多不同的尺寸。 為了讓您了解在同行評審的文獻中通常研究和研究哪些維度,下面的直方圖顯示了研究15種不同的數據質量評估方法(涉及32個維度)后的前6個維度。
A systemic approach to Data Quality Assessment
數據質量評估的系統方法
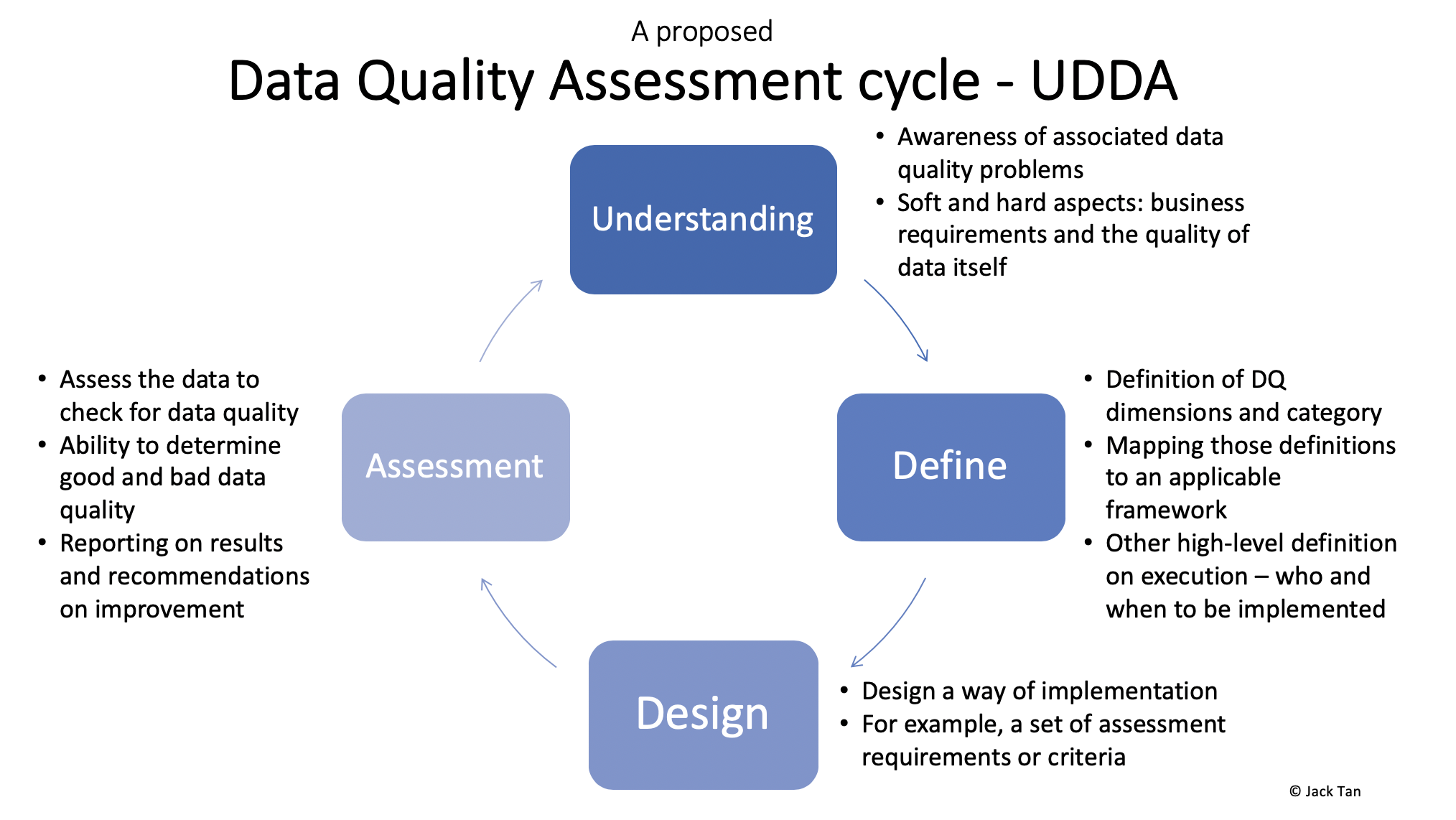
If you fail to plan, you plan to fail. A good systemic approach cannot be successful without a good planning. To have a good plan, you need to have a thorough understanding of the business, especially on problems associating with data quality. In the previous example, one should be aware that the contact list, albeit correct has a data quality problem of not being applicable to achieve the goal of the assigned task.
如果您沒有計劃,您計劃失敗。 沒有良好的計劃,好的系統方法就不會成功。 要制定好的計劃,您需要對業務有透徹的了解 ,尤其是在與數據質量相關的問題上。 在前面的示例中,應該知道聯系人列表(盡管正確)存在數據質量問題,不適用于實現所分配任務的目標。
After the problems become clear, data quality dimensions to be investigated should be defined. This can be done using an empirical approach like surveys among stakeholders to find out which dimension matters the most in reference to the data quality problems.
在問題明確之后,應該定義要研究的數據質量維度。 可以使用經驗方法(例如,在利益相關者之間進行調查)來完成,以找出哪個維度相對于數據質量問題最為重要。
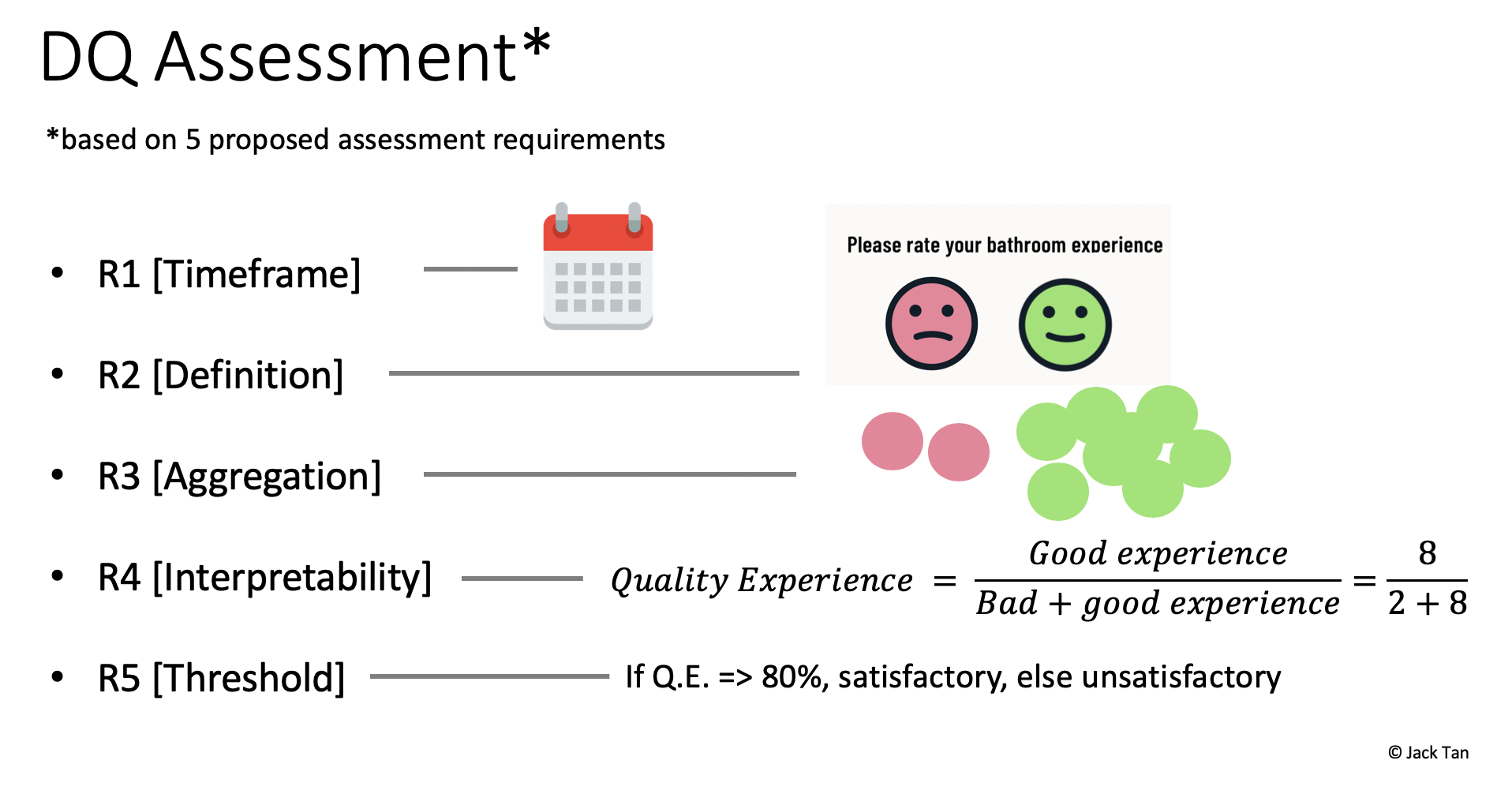
A set of assessment steps should follow suit. Design a way for the implementation so that these steps can map the assessment based on selected dimensions to the actual data. For instance, the following five requirements can be used as an example:
一套評估步驟也應隨之而來。 設計一種實現方式,以便這些步驟可以將基于選定維度的評估映射到實際數據。 例如,可以使用以下五個要求作為示例:
[1] Timeframe — Decide on an interval for when the investigative data are collected.
[1]時間范圍-決定收集調查數據的時間間隔。
[2] Definition — Define a standard on how to differentiate the good from the bad data.
[2]定義-定義有關如何區分好數據和壞數據的標準。
[3] Aggregation — How to quantify the data for the assessment.
[3]匯總-如何量化評估數據。
[4] Interpretability — A mathematical expression to assess the data.
[4]可解釋性-評估數據的數學表達式。
[5] Threshold —Select a cut-off point to evaluate the results.
[5]閾值—選擇一個截止點以評估結果。
Once the assessment methodologies are in place, it is time to get hands-on and carry out the actual assessment. After the assessment, a reporting mechanism can be set up to evaluate the results. If the data quality is satisfactory, then the data are fit for further analytic purposes. Else, the data have to be revised and potentially to be collected again. An example can be seen in the following illustration.
評估方法到位后,就可以動手進行實際評估了。 評估之后 ,可以建立報告機制來評估結果。 如果數據質量令人滿意,則將數據用于進一步的分析目的。 否則,必須修改數據并可能再次收集。 下圖顯示了一個示例。
Conclusion
結論
There is no one-size-fits-all solution for all data quality problems, as the definition outlined above, half of the data quality aspect is highly subjective. However, in the process of data quality assessment, we can always use a systemic approach to evaluate and assess data quality. While this approach is largely objective and relatively versatile, some domain knowledge is still required. For example in the selection of data quality dimension. Data Accuracy and Completeness might be critical aspects of the data for use case A but for use case B these dimensions might be less important.
對于所有數據質量問題,沒有一種千篇一律的解決方案,正如上面概述的定義,數據質量方面的一半是高度主觀的。 但是,在數據質量評估過程中,我們始終可以使用系統的方法來評估和評估數據質量。 盡管此方法主要是客觀的并且相對通用,但是仍需要一些領域知識。 例如在選擇數據質量維度時。 對于用例A,數據準確性和完整性可能是數據的關鍵方面,但對于用例B,這些維度可能不太重要。
翻譯自: https://towardsdatascience.com/how-to-improve-data-preparation-for-machine-learning-dde107b60091
提高機器學習質量的想法
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388794.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388794.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388794.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

mysql 集群實踐_MySQL Cluster集群探索與實踐
)
Python基礎:搭建開發環境(1)
)
python數據結構之隊列(一)

Android實現圖片放大縮小

matlab散點圖折線圖_什么是散點圖以及何時使用

java判斷題_【Java判斷題】請大神們進來看下、這些判斷題你都知道多少~

PoPo數據可視化第8期


java list用法_Java List 用法詳解及實例分析

python字符串和List:索引值以 0 為開始值,-1 為從末尾的開始位置;值和位置的區別哦...

邏輯回歸 python_深入研究Python的邏輯回歸
)
spring定時任務(@Scheduled注解)

net user 用戶名 密碼 /add 建立用戶

JavaScript是如何工作的:與WebAssembly比較及其使用場景

友元 java_C++ 友元關系詳解

Matplotlib中的“ plt”和“ ax”到底是什么?

【數據庫的備份與還原】 .


java 控制jsp_JSP學習之Java Web中的安全控制實例詳解
