數據透視表和數據交叉表
Consider the data of healthcare drugs as provided in the excel sheet. The concept of pivot tables in python allows you to extract the significance from a large detailed dataset. A pivot table helps in tracking only the required information from the data frames. It summarizes the data. The panda’s pivot table is a good alternative instead of using other tools for analysing the data. The following are the features for using panda’s pivot table.
考慮excel表中提供的保健藥物數據。 python中數據透視表的概念使您可以從大型詳細數據集中提取重要性。 數據透視表有助于僅跟蹤數據幀中所需的信息。 它匯總了數據。 熊貓的數據透視表是一個很好的選擇,而不是使用其他工具來分析數據。 以下是使用熊貓數據透視表的功能。
- It is quicker. 它更快。
- It is self-documenting 它是自我記錄
- It is easy to use for generating a report or email 易于生成報告或電子郵件
- It is more flexible in defining the aggregation functions. 定義聚合函數時更加靈活。
Consider this below dataset for execution. Download the dataset which is available here. In this article, you will learn python pivots with many examples.
在下面的數據集中考慮執行。 下載可在此處獲得的數據集。 在本文中,您將通過許多示例學習python數據透視。
The pivot table must have a data frame and an index. Run the below code which has used “Patient Name” as an index.
數據透視表必須具有數據框和索引。 運行以下使用“患者姓名”作為索引的代碼。
Example 1:
范例1:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Patient Name”])print(data)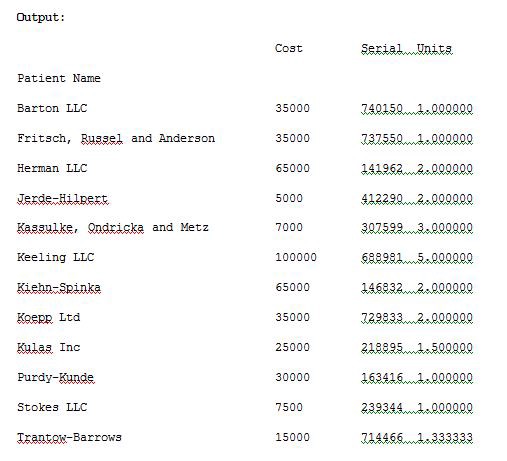
The pd.pivot_table(df,index=[“Patient Name”])will track the data with “Patient Name” as index. We can also track the data with multiple indexes by providing multiple arguments to the index variable. Run the below Example 2 to see the result.
pd.pivot_table(df,index = [“患者名稱”])將以“患者名稱”作為索引來跟蹤數據。 我們還可以通過為index變量提供多個參數來跟蹤具有多個索引的數據。 運行下面的示例2以查看結果。
Example 2:
范例2:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Patient Name”,”Jr Doctor”,”Sr Doctor”])pd.set_option(‘display.max_columns’,None)print(data)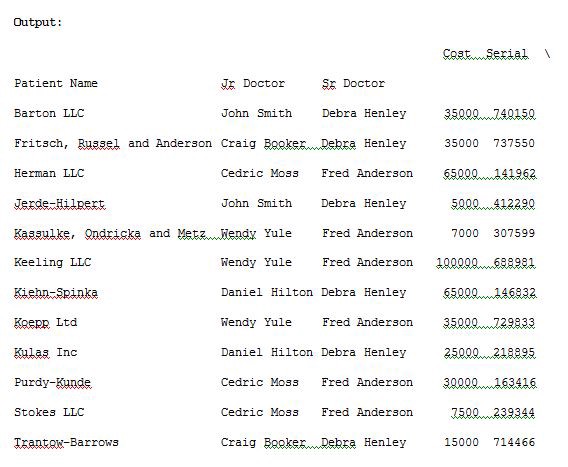

In the above program I have used pd.set_option(‘display.max_columns’,None)for displaying all the columns in a data frame so as to make it visible in a terminal output window during the program execution. The pd.pivot_table(df,index=[“Patient Name”,”Jr Doctor”,”Sr Doctor”])data will now track the data with the corresponding index names. For suppose if we don’t want Serial and Units columns as it is not useful than we can explicitly remove these columns by providing the values field. Run the below code of Example 3 to see the result.
在上面的程序中,我使用了pd.set_option('display.max_columns',None)來顯示數據框中的所有列,以便在程序執行期間使其在終端輸出窗口中可見。 現在,pd.pivot_table(df,index = [“患者姓名”,“小醫生”,“高級醫生”])數據將跟蹤具有相應索引名的數據。 假設如果我們不想使用Serial和Units列,因為它沒有用,那么我們可以通過提供values字段顯式刪除這些列。 運行下面的示例3的代碼以查看結果。
Example 3:
范例3:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Units”])pd.set_option(‘display.max_columns’,None)print(data)
We can use aggfunc and np.sum to get the count or a sum for the cost column automatically by using it as an argument in pivot_table()method.
我們可以使用aggfunc和np.sum來自動獲取成本列的計數或總和,方法是將其用作pivot_table()方法中的參數。
Example 4:
范例4:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Cost”],aggfunc=np.sum)pd.set_option(‘display.max_columns’,None)print(data)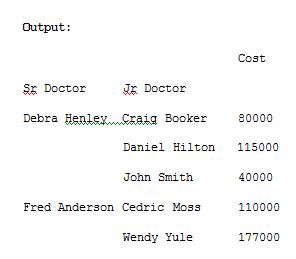
The aggfunc argument can take list of functions. We can compute the mean using numpy and len to get the count.
aggfunc參數可以接受功能列表。 我們可以使用numpy和len計算平均值以獲得計數。
Example 5:
范例5:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Cost”],aggfunc=[np.sum,len])pd.set_option(‘display.max_columns’,None)print(data)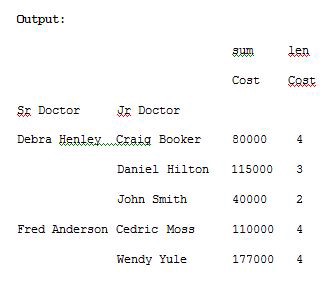
The columns are optional. They provide an additional way to segment the actual values you care about. The aggregation functions are applied to the values you list. Look at Example 6 for understanding.
列是可選的。 它們提供了另外一種細分實際值的方法。 聚合函數將應用于您列出的值。 請參閱示例6進行理解。
Example 6:
范例6:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Cost”],columns=[“Drug”],aggfunc=[np.sum])pd.set_option(‘display.max_columns’,None)print(data)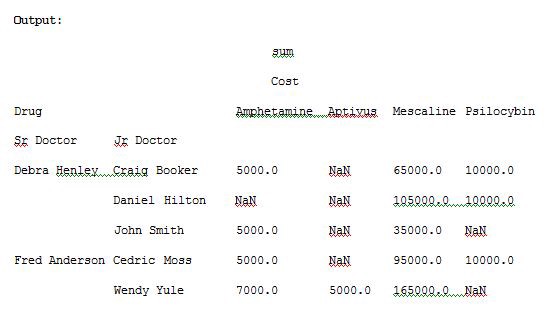
The NaN’s values can be replaced with 0 by passing fill_value argument for pivot_table() method. Run the Example 7 code and see the result.
NaN的值可以通過將ivot_table()方法的fill_value參數傳遞給0來替換。 運行示例7代碼,然后查看結果。
Example 7:
范例7:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Cost”],columns=[“Drug”],aggfunc=[np.sum],fill_value=0)pd.set_option(‘display.max_columns’,None)print(data)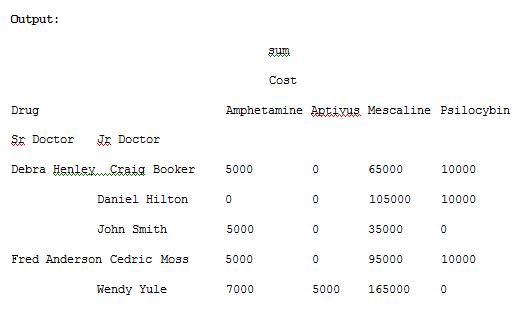
Now let us add units to the values list and execute the code, run the code in Example 8 and see the result.
現在,讓我們將單元添加到值列表中并執行代碼,運行示例8中的代碼并查看結果。
Example 8:
范例8:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”],values=[“Cost”,”Units”],columns=[“Drug”],aggfunc=[np.sum],fill_value=0)pd.set_option(‘display.max_columns’,None)print(data)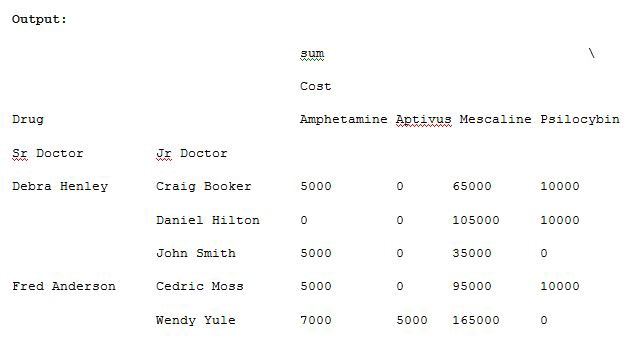
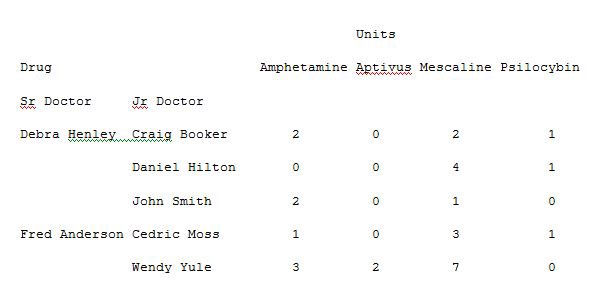
Now let us remove the drug from the columns and add this to the index. Run the below code in Example 9 to get a different visual representation.
現在,讓我們從列中刪除藥物并將其添加到索引中。 在示例9中運行以下代碼,以獲取不同的視覺表示。
Example 9:
范例9:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”,”Drug”],values=[“Cost”,”Units”],aggfunc=[np.sum],fill_value=0)pd.set_option(‘display.max_columns’,None)print(data)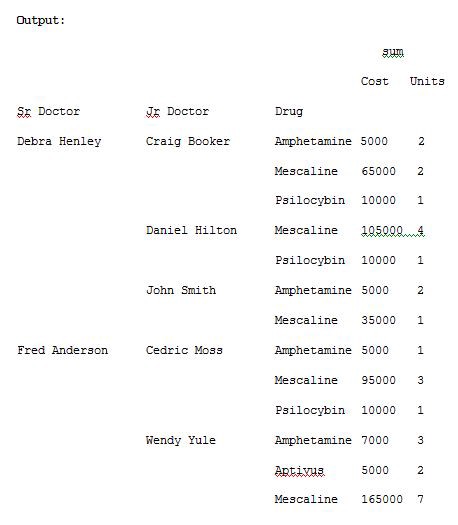
To see the totals for cost and units of sum and mean, use margins=True. Run the below code and see the result.
要查看成本總計以及總和和均值的單位,請使用margins = True。 運行以下代碼,然后查看結果。
Example 10:
范例10:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Jr Doctor”,”Drug”],values=[“Cost”,”Units”],aggfunc=[np.sum,np.mean],fill_value=0,margins=True)pd.set_option(‘display.max_columns’,None)print(data)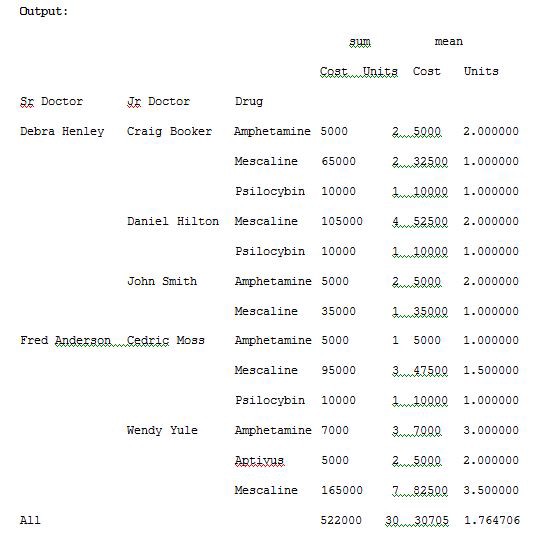
Let us now track the Sr Doctor level and track how the outcome is ordered. Run the below code of Example 11 for understanding.
現在讓我們跟蹤高級醫生的水平并跟蹤結果的排序方式。 運行以下示例11的代碼以進行理解。
Example 11:
示例11:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\Drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Outcome”],values=[“Cost”],aggfunc=[np.sum],fill_value=0,margins=True)pd.set_option(‘display.max_columns’,None)print(data)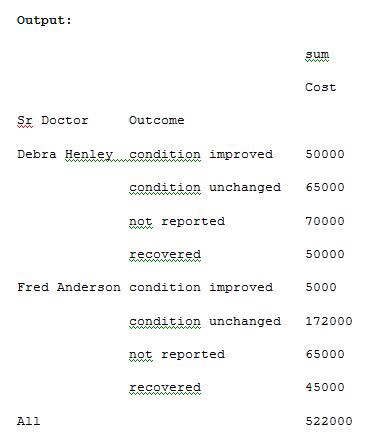
We can also pass a dictionary to the aggfunc argument to perform different functions on each of the values which you select. Run Example 12 code and see the result.
我們還可以將字典傳遞給aggfunc參數,以對您選擇的每個值執行不同的功能。 運行示例12代碼,然后查看結果。
Example 12:
范例12:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\Drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Outcome”],columns=[“Drug”],values=[“Units”,”Cost”],aggfunc={“Units”:len,”Cost”:np.sum},fill_value=0)pd.set_option(‘display.max_columns’,None)print(data)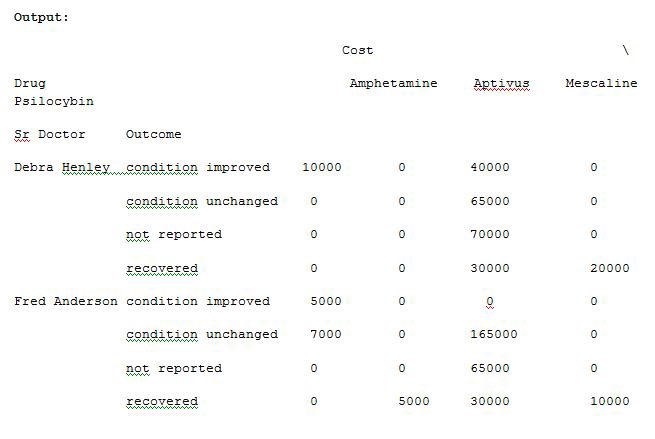
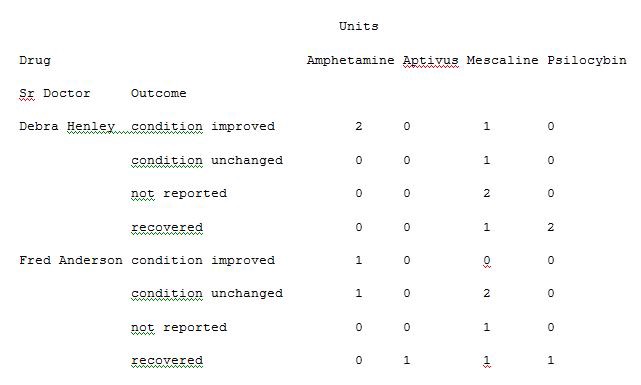
We can also provide the list for each value while passing a dictionary for aggfunc argument. Run the below code in Example 13 to see the result.
我們還可以為每個值提供列表,同時傳遞aggfunc參數的字典。 在示例13中運行以下代碼以查看結果。
Example 13:
示例13:
import pandas as pdimport numpy as npdf = pd.read_excel(“C:\\Users\\admin\\Desktop\\Drugs.xlsx”)data = pd.pivot_table(df,index=[“Sr Doctor”,”Outcome”],columns=[“Drug”],values=[“Units”,”Cost”],aggfunc={“Units”:len,”Cost”:[np.sum,np.mean]},fill_value=0)pd.set_option(‘display.max_columns’,None)print(data)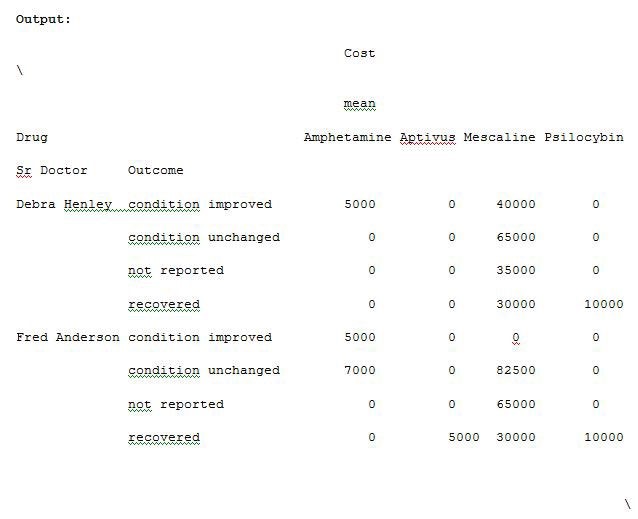
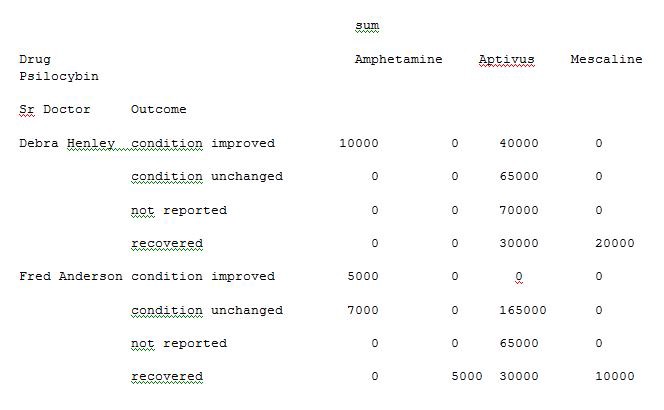
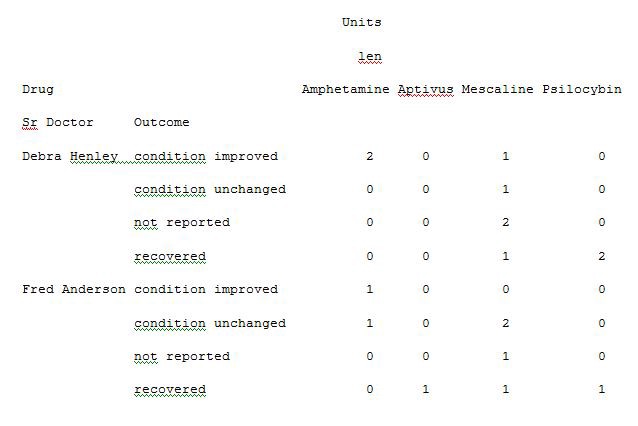
Thus you are able to extract and analyse the data from an excel sheet of a Microsoft product by applying the concept of a pivot table in python instead of using tools for analysis. The data analysis becomes very easy for understanding and is also very quick at processing the pivot table with python execution.
因此,您可以通過使用python中的數據透視表而不是使用分析工具來從Microsoft產品的Excel工作表中提取和分析數據。 數據分析變得非常容易理解,并且在使用python執行處理數據透視表時也非常快。
翻譯自: https://medium.com/analytics-vidhya/data-extraction-with-pivot-tables-a7d980c18dd0
數據透視表和數據交叉表
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388592.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388592.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388592.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
v5.0)
金融信息交換協議(FIX)v5.0


linux行命令測網速,Linux命令行測試網速的方法

Delphi XE2獲取漢字拼音首字母

圖像處理傅里葉變換圖像變化_傅里葉變換和圖像床單視圖。

HDUOJ 1062 TEXT REVERSE

VC++的windows服務

linux中gradle編譯慢,【Linux】解決linux下android studio用gradle構建從jcenter或maven下載依賴太慢...

MFC程序需要的函數庫及頭文件--《深入淺出MFC》
)
C#DNS域名解析工具(DnsLookup)

python.day05

滯后分析rstudio_使用RStudio進行A / B測試分析

Linux程序實現彈框,jQuery實現彈出框 效果絕對美觀

Interesting visualization tools for profiling.

MySQL的事務-原子性

codeforces CF438D The Child and Sequence 線段樹


linux的磁盤磁頭瓷片作用,Linux 磁盤管理

