大數據 vr csdn
Astronomy has become a big data discipline, and the ever growing databases in modern astronomy pose many new challenges for analysts. Scientists are more frequently turning to artificial intelligence and machine learning algorithms to analyze multidimensional data sets. However, it is not only a methodological and technical challenge: it is also a visual one! Data visualization is driving discovery in astronomy and is also helping with communicating new findings to the general public. The history of information graphics shows how the transformation of data into knowledge is vital for understanding the data at hand, a subject I have previously written about here.
天文學已經成為一門大數據學科,而現代天文學中不斷增長的數據庫對分析人員提出了許多新的挑戰。 科學家越來越多地轉向人工智能和機器學習算法來分析多維數據集。 但是,這不僅是方法和技術上的挑戰:這也是視覺上的挑戰! 數據可視化正在推動天文學的發現,并且還有助于將新發現傳達給公眾。 信息圖形的歷史表明,如何將數據轉換為知識對于理解手頭的數據至關重要,這是我先前在此撰寫的主題。
The problem of visualizing complex data and exploring it interactively is by no means new or limited to research. Examples from digital information design in bioinformatics and medicine (e.g. Genome Valence by Ben Fry or Meviatis by Ricarda Schuhmann) show how visualization can support the understanding of structures within data sets and facilitate exploration. The representation of the data’s dimensions (i.e. its parameter values) can result in dynamic and aesthetic data sculptures. Such visualizations are often quite beautiful in themselves but, crucially, their interactive features enable users to quickly make comparisons and interpret the data.
可視化復雜數據并以交互方式進行探索的問題絕不是新問題,也不是僅限于研究。 生物信息學和醫學中的數字信息設計的示例(例如Ben Fry的Genome Valence或Ricarda Schuhmann的Meviatis )顯示了可視化如何能夠支持對數據集內結構的理解并促進探索。 數據尺寸的表示(即參數值)可以產生動態和美觀的數據雕塑。 這樣的可視化效果通常很漂亮,但至關重要的是,它們的交互功能使用戶可以快速進行比較并解釋數據。
Today’s digital media allows us to go beyond designing interactive on-screen three-dimensional applications. Both augmented reality (AR) and virtual reality (VR) make it possible for users to take a fresh look at their data and explore parameter spaces in 3D. There is so much potential for using these technologies in the field of information design. For VR, the advantages are obvious:
當今的數字媒體使我們不僅可以設計交互式屏幕三維應用程序。 增強現實(AR)和虛擬現實(VR)都使用戶可以重新查看其數據并探索3D中的參數空間 。 在信息設計領域中使用這些技術的潛力很大。 對于VR,優勢顯而易見:
More space! VR offers a larger field of view than 2D images. This allows for multiple views to be arranged in space, making it easier to draw cross-references and connections.
更多的空間! VR提供比2D圖像更大的視野。 這樣就可以在空間中排列多個視圖,從而更容易繪制交叉引用和連接。
More dimensions! Compared to 2D graphics, VR visualizations offer additional parameters that can represent data (e.g. sound, haptics, lighting, interaction).
更多尺寸! 與2D圖形相比,VR可視化提供了可以表示數據的其他參數(例如,聲音, 觸覺 ,照明,交互)。
More structure! The perception of space and depth is more intuitive; enabling shapes and volumes to be recognized more quickly.
更結構! 對空間和深度的感知更加直觀; 使形狀和體積更快地被識別。
More fun! Immersing yourself in the data and the ability to go from overview to detail by scaling the space is a powerful immersive experience.
更多樂趣! 沉浸在數據中,并能夠通過縮放空間來從概覽到細節,這是一種強大的沉浸式體驗。
了解未知的本質 (Understanding the nature of the unknown)
Inspired by the above research examples, the hypothesis I chose to explore for my bachelor thesis in Information Design was:
受到以上研究示例的啟發,我選擇為信息設計學士學位探索的假設是:
The presentation of scientific data with new digital media, especially VR, offers great potential for data analysis in science.
用新的數字媒體(尤其是VR)呈現科學數據,為科學數據分析提供了巨大潛力。
I wanted to test this hypothesis on a data set from my previous research which I had been struggling to get an overview of. During my PhD in Astrophysics, I was involved in the EXTraS project, which aimed to automatically classify unknown and newly discovered X-ray sources in the cosmos. The sources were observed by the X-ray satellite XMM-Newton from the European Space Agency (ESA). I set about designing the Virtual Data Cosmos as a way of grouping data with similar properties and visualizing these groups.
我想用以前的研究中的數據集來檢驗這個假設,而我一直在努力進行概述。 在獲得天體物理學博士學位期間,我參與了EXTraS項目,該項目旨在自動對宇宙中未知和新發現的X射線源進行分類。 來源是由歐洲航天局 (ESA)的X射線衛星XMM-Newton觀測到的。 我著手設計虛擬數據宇宙 ,以將具有相似屬性的數據分組并可視化這些組的方式。
As more and more data is collected by X-ray satellites, the data archives of these satellites are growing annually. The records detail millions of sources that emit X-rays, and from which any newly found source could yield new physical discoveries. The classification of unknown sources is therefore hugely important in modern astronomy and, due to the sheer amount of data, intelligent algorithms are increasingly being adopted by astronomers worldwide.
隨著越來越多的X射線衛星收集數據,這些衛星的數據檔案每年都在增長。 記錄詳細記錄了數百萬個發出X射線的放射源,任何新發現的放射源都可以從中產生新的物理發現。 因此,未知源的分類在現代天文學中非常重要,由于數據量巨大,全球各地的天文學家都越來越多地采用智能算法。
The image below shows an image of the entire sky in the optical wavelength as seen from Earth. This projection scan be seen as analogous to a world map in which the galactic plane lies on the equator and the galactic center is in the center of the map. Just as in a normal world map there are longitudes and latitudes, shown as white grid lines. This is typically referred to as a sky map. Laid over the optical image are white dots; each represents a region observed by the X-ray satellite XMM-Newton. Each white dot includes several unknown X-ray sources. The objective of the project was to classify each of these sources.
下圖顯示了從地球看到的整個光學波長的天空圖像。 該投影掃描被視為類似于世界地圖,其中銀河平面位于赤道上,而銀河中心位于地圖中心。 就像在正常的世界地圖中一樣,也有經度和緯度,以白色網格線顯示。 這通常稱為天空地圖 。 光學圖像上有白點。 每個代表一個由X射線衛星XMM-Newton觀測到的區域。 每個白點包括幾個未知的X射線源。 該項目的目的是對所有這些來源進行分類。
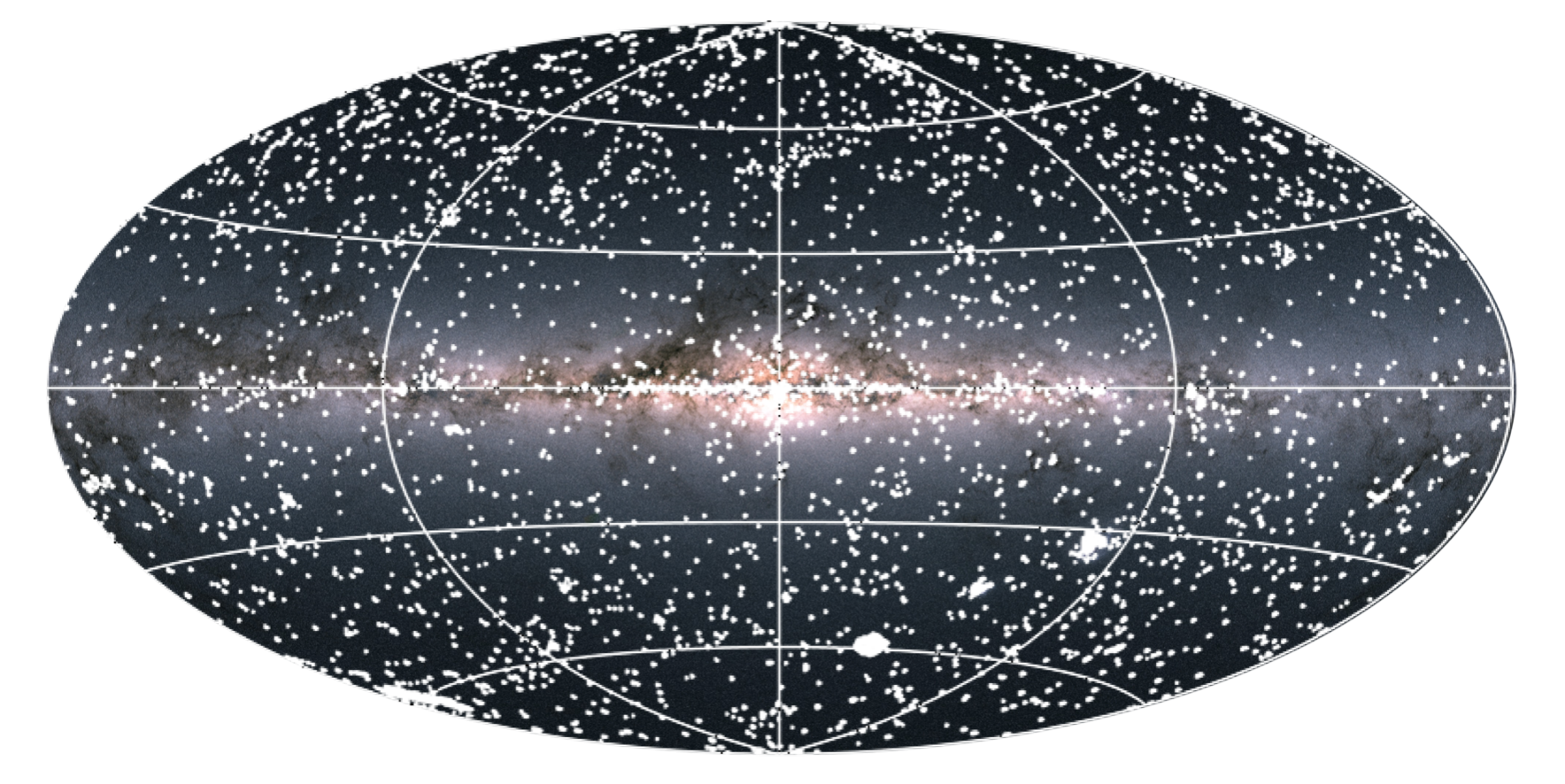
In order to understand the nature of each X-ray source, astronomers compare its features (specifically the energetic and temporal properties observed) to those of objects with known classification types such as binary star or Seyfert galaxy. Questions like these help:
為了了解每個X射線源的性質,天文學家將其特征(特別是觀察到的能量和時間性質)與具有已知分類類型的物體(如雙星或塞弗特星系)進行了比較 。 這些問題有幫助:
- What are the correlations between the properties of the X-ray source and those of known object classification type? X射線源的屬性與已知對象分類類型的屬性之間有什么關聯?
- Where are the differences? 區別在哪里?
Has the unknown object been discovered elsewhere in the electromagnetic spectrum which could yield further hints on its nature?
是否在電磁光譜的其他地方發現了未知物體,這可能進一步暗示其性質?
In order to describe the similarity between an unknown and a known X-ray source we astronomers use statistics as well as visualization. In this case, machine learning algorithms (supervised decision tree algorithms to be precise) automatically characterized every source in this large and complex data set by comparing their precise parameter values (e.g. observed X-ray intensity) with those of known objects. Ultimately, the algorithms calculate the probability of an X-ray source belonging to various classification types and allocate it to the class that is most likely.
為了描述未知和已知X射線源之間的相似性,我們的天文學家使用了統計數據和可視化數據。 在這種情況下,通過將機器學習算法(精確的監督決策樹算法 )的精確參數值(例如觀察到的X射線強度)與已知對象的精確參數值進行比較,可以自動表征該龐大而復雜的數據集中的每個源。 最終,算法計算出X射線源屬于各種分類類型的概率,并將其分配給最可能的類別。
For example: The X-ray source with ID 1 has a 45% probability of being a single star, a 30% probability of being a binary star and a 0.01% probability of being a galaxy. The algorithm therefore assigns the class with the highest probability as the final classification of the unknown source. In this case, source ID 1 would be classified as single star.
例如:ID為1的X射線源有45%的概率是單顆星,有30%的概率是雙星,有0.01%的概率是星系。 因此,該算法將概率最高的類別指定為未知源的最終分類。 在這種情況下,源ID 1將被分類為單顆星。
Once the algorithm has classified all unknown sources in this way, the task of the astronomer is to carefully screen and control the results. How did the algorithm perform? Did it make mistakes? Since more than one algorithm was tested one would need to compare the results of each to answer these questions. Did different algorithms classify the same unknown source into different classes? Also, as a scientist, one also wants to know why an algorithm classified an object as it did. The astronomer requires an understanding of the relationship between different parameters and source classification types, and does this with the help of visualization.
一旦算法以這種方式對所有未知源進行分類,天文學家的任務就是仔細篩選和控制結果。 該算法如何執行? 它犯錯了嗎? 由于測試了多種算法,因此需要比較每種算法的結果來回答這些問題。 是否有不同的算法將相同的未知源劃分為不同的類? 另外,作為科學家,人們也想知道 為什么 一種算法將對象分類。 天文學家需要了解不同參數與源分類類型之間的關系,并借助可視化來做到這一點。
傳統科學的局限性 (The limitations of traditional science viz)
A typical method is to create multiple scatterplots in which the X-ray properties of unknown cosmic sources are compared with each other while taking into account the results of a single algorithm. This is done by assigning a unique color and symbol to a specific source classification and depicting X-ray sources with specific class symbols in the plot. We astronomers can then analyze whether the positions of sources depicted with the same symbol form patterns that help to distinguish different classification types.
一種典型的方法是創建多個散點圖,其中將未知宇宙源的X射線屬性相互比較,同時考慮到單個算法的結果。 這是通過為特定的源分類分配唯一的顏色和符號并在繪圖中描繪具有特定類別符號的X射線源來完成的。 然后,我們的天文學家可以分析以相同符號表示的源位置是否形成有助于區分不同分類類型的模式。
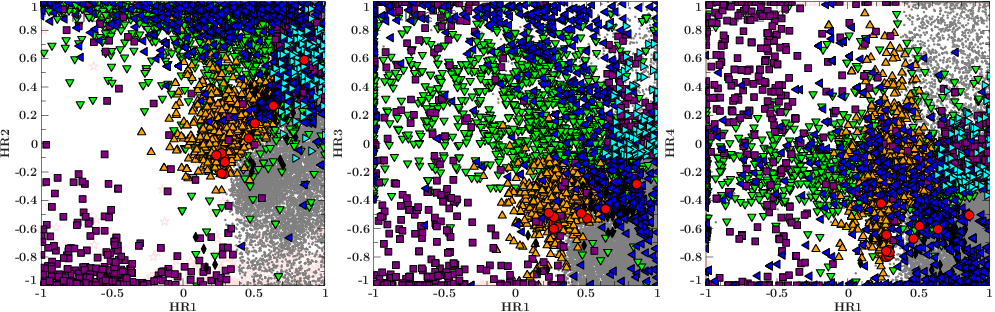
For example: these scatterplots were created to investigate the relationships between parameter HR1 and parameters HR2, HR3, and HR4. The parameters are abstract properties used to describe specific radiation energies of the cosmic sources and visualizing them in the abstract plane enables us to look for patterns that may characterize the properties of different objects. The data points represent all unknown cosmic sources observed by the satellite.
例如:創建這些散點圖以研究參數HR1與參數HR2,HR3和HR4之間的關系。 這些參數是抽象屬性,用于描述宇宙源的特定輻射能,并在抽象平面中對其進行可視化處理使我們能夠尋找可表征不同物體屬性的模式。 數據點代表衛星觀測到的所有未知宇宙源。
In this case, green triangles represent the class Seyfert galaxies, while purple squares depict the class of single variable stars that exist within our Milky Way. We see that the sources overlap if we only look at the HR1 parameter, but they occupy very different regions in the HR1-HR2 plane in the first scatterplot. Hence from that plot we can conclude that sources with a low HR1 and HR2 value belong to the purple square (variable star) class.
在這種情況下,綠色三角形代表塞弗特星系類別,而紫色正方形代表我們銀河系中存在的單變星類別。 如果僅查看HR1參數,就會看到源重疊,但是在第一個散點圖中,它們在HR1-HR2平面中占據了非常不同的區域。 因此,從該圖可以得出結論,HR1和HR2值較低的源屬于紫色正方形( 變星 )類。
But what about sources with high HR1 and HR2 values? Comparing only these parameters would put them in the galaxy (green) class. But there are many other classes which also occupy this region, e.g. blue triangles, which represent a kind of binary star system and this confuses the picture. To get a clearer understanding we now need to compare the HR1-HR2 parameter plane with the other scatterplots. If we now look at the second image, which illustrates the HR1-HR3 plane, we see that the sources shown in green and blue symbols are slightly more separated. And by combining the information of the first and second plots, we can identify the specific combinations of HR1, H2 and HR3 parameters that differentiate variable stars (purple), galaxies (green) and binary star systems (blue) .
但是,具有高HR1和HR2值的源又如何呢? 僅比較這些參數會將它們置于銀河 (綠色)類中。 但是還有許多其他類別也占據了這個區域,例如藍色三角形代表了一種雙星系統 ,這使圖片變得混亂。 為了更清楚地了解,我們現在需要將HR1-HR2參數平面與其他散點圖進行比較。 現在,如果我們查看第二張圖片,該圖片說明了HR1-HR3平面,那么我們看到以綠色和藍色符號顯示的源稍微分開了。 并通過結合第一和??第二個圖的信息,我們可以確定HR1,H2和HR3參數的特定組合,以區分可變恒星 (紫色), 星系 (綠色)和雙星系統 (藍色)。
With each additional scatterplot we gradually form a mental model of a multidimensional parameter space in which each source class is located in a unique location. In principle this is what the algorithms do and is why our parameters are also known as the ‘dimensions’ of a data set. However, the larger the number of parameters and classes, the more difficult it is for humans to keep an overview of all relationships. It is simply not possible for us to imagine more than three dimensions at once.
通過每個其他散點圖,我們逐漸形成多維參數空間的思維模型,其中每個源類都位于唯一的位置。 原則上,這就是算法的工作,也是為什么我們的參數也被稱為數據集的“維度”的原因。 但是,參數和類的數量越多,人們越難掌握所有關系。 我們根本無法一次想象三個以上的維度。
In our sample, the size of the data set and the fact there were more than 50 parameters made it impossible to get an overview of all the relationships between parameter values and source classifications. The scatterplots required were simply too many and, due to the size of the data set, many regions were occupied by multiple source classes. The overlap of their symbols made it very difficult to see the data patterns.
在我們的樣本中,數據集的大小以及超過50個參數的事實使得無法大致了解參數值與源分類之間的所有關系。 所需的散點圖太多了,并且由于數據集的大小,許多區域被多個源類別占用。 它們符號的重疊使得很難看到數據模式。
In addition, these plots correspond to the classification by a single algorithm. So as we increase the number of algorithms in use, the number of plots would quickly become unmanageable. I concluded that this traditional 2D visualization did not allow a proper overview of the data, and was frustrated that the decision-making mechanisms of the algorithm remained opaque.
此外,這些圖對應于單個算法的分類。 因此,隨著我們增加使用的算法數量,地塊數量將很快變得難以管理。 我得出的結論是,這種傳統的2D可視化無法正確查看數據,并且對算法的決策機制仍然不透明感到沮喪。
設計虛擬數據宇宙 (Designing the Virtual Data Cosmos)
直接可視化數據 (Visualizing the data directly)
To come up with a new way to visualize this big data set, I first did some research on the history and principles of data visualization. I was fascinated by the creativity with which designers and scientists mapped their data.
為了提出一種可視化此大數據集的新方法,我首先對數據可視化的歷史和原理進行了一些研究。 設計師和科學家繪制數據的創造力使我著迷。
Excellence in statistical graphics consists of complex ideas communicated with clarity, and efficiency.
統計圖形方面的卓越表現包括復雜,清晰,高效的想法。
Edward Tufte coined the term ‘graphic excellence’ in data visualization. He postulated various properties that statistical graphics require to be successful. His theory was that data should be displayed directly without the user being distracted by the design itself. Furthermore, statistical graphics should serve a clear purpose (either description, exploration, tabulation or decoration) and should show several levels of detail, from a rough overview to the fine structure of the data.
Edward Tufte創造了數據可視化中的“圖形卓越”一詞。 他提出了統計圖形必須具備的各種屬性才能成功。 他的理論是,數據應直接顯示,而用戶不會因設計本身而分心。 此外,統計圖形應具有明確的目的(描述,探索,制表或修飾),并應顯示從粗糙的概述到數據的精細結構的多個細節級別。
Similar claims were made by a 2015 study on the visualization of big data in VR and AR. The authors concluded that for a data visualization to serve as an analysis tool, it requires the data concerned to be represented exactly. The implication for my work was that the data mapping had to be done through coding. This meant that the data values themselves would define the visual aesthetic of the virtual environment.
2015年關于VR和AR中大數據可視化的研究也提出了類似的主張。 作者得出的結論是,要使數據可視化充當分析工具,就需要準確地表示有關數據。 這對我的工作意味著數據映射必須通過編碼來完成。 這意味著數據值本身將定義虛擬環境的視覺美感。
In addition, the interaction and scalability in a VR scene would allow the user to be fully immersed in the data and literally dive into it. One could easily move around and take different perspectives on the data set. Similarly, the user would be able to zoom out and get an overview, effectively holding the data in their hands. The data set could even be turned around and explored as though it were a physical object.
此外,VR場景中的交互性和可伸縮性將使用戶完全沉浸在數據中,并從字面上深入其中。 人們可以輕松地走動,并對數據集采取不同的觀點。 類似地,用戶將能夠縮小并獲得概覽,從而有效地將數據掌握在他們手中。 甚至可以將數據集轉為一個物理對象并進行探索。
This, for me, was the most important aspect of the VR approach: it combined the advantage of data physicalization with the possibility to shape and manipulate the data environment, which is not possible in the real world.
對我而言,這是VR方法最重要的方面:它將數據物理化的優勢與塑造和操縱數據環境的可能性相結合,這在現實世界中是不可能的。
Regardless of how the X-ray source data was organized, my principle idea was to pull the cluster of X-ray parameters and probabilities apart and display them in three-dimensional space. The goal was an interactive data visualization in VR in which the data could be explored directly. By interacting with a concrete virtual environment anyone could explore this abstract data space.
不管X射線源數據是如何組織的,我的基本思想都是將X射線參數和概率簇分開,并在三維空間中顯示它們。 目標是在VR中進行交互式數據可視化,從而可以直接瀏覽數據。 通過與具體的虛擬環境進行交互,任何人都可以探索此抽象數據空間。
My solution for the problem resulted in the Virtual Data Cosmos. I’ll talk you through the design concept here. A detailed description of the design process will be explained in the next article in this series.
我針對該問題的解決方案產生了Virtual Data Cosmos 。 我將在這里與您討論整個設計概念。 設計過程的詳細描述將在本系列的下一篇文章中進行解釋。
應用設計理念 (Applying the design concept)
I wanted to ensure that the visualization would first give the user an overview of the data and only then allow them to go into the detail. By zooming in on their chosen classification type, one would finally reach the DNA of the X-ray source (i.e., they would find details of its spectral parameters) and therefore understand why the algorithm assigned the source to a certain class.
我想確保可視化效果將首先為用戶提供數據概覽,然后才允許他們進入細節。 通過放大他們選擇的分類類型,人們最終將到達X射線源的DNA(即,他們將找到其光譜參數的詳細信息),因此可以理解為什么算法將源分配給特定類別。
The VR experience consists of two spaces; users can choose to zoom in and out to seamlessly move from one space to the other:
VR體驗包含兩個空間: 用戶可以選擇放大和縮小以從一個空間無縫移動到另一個空間:
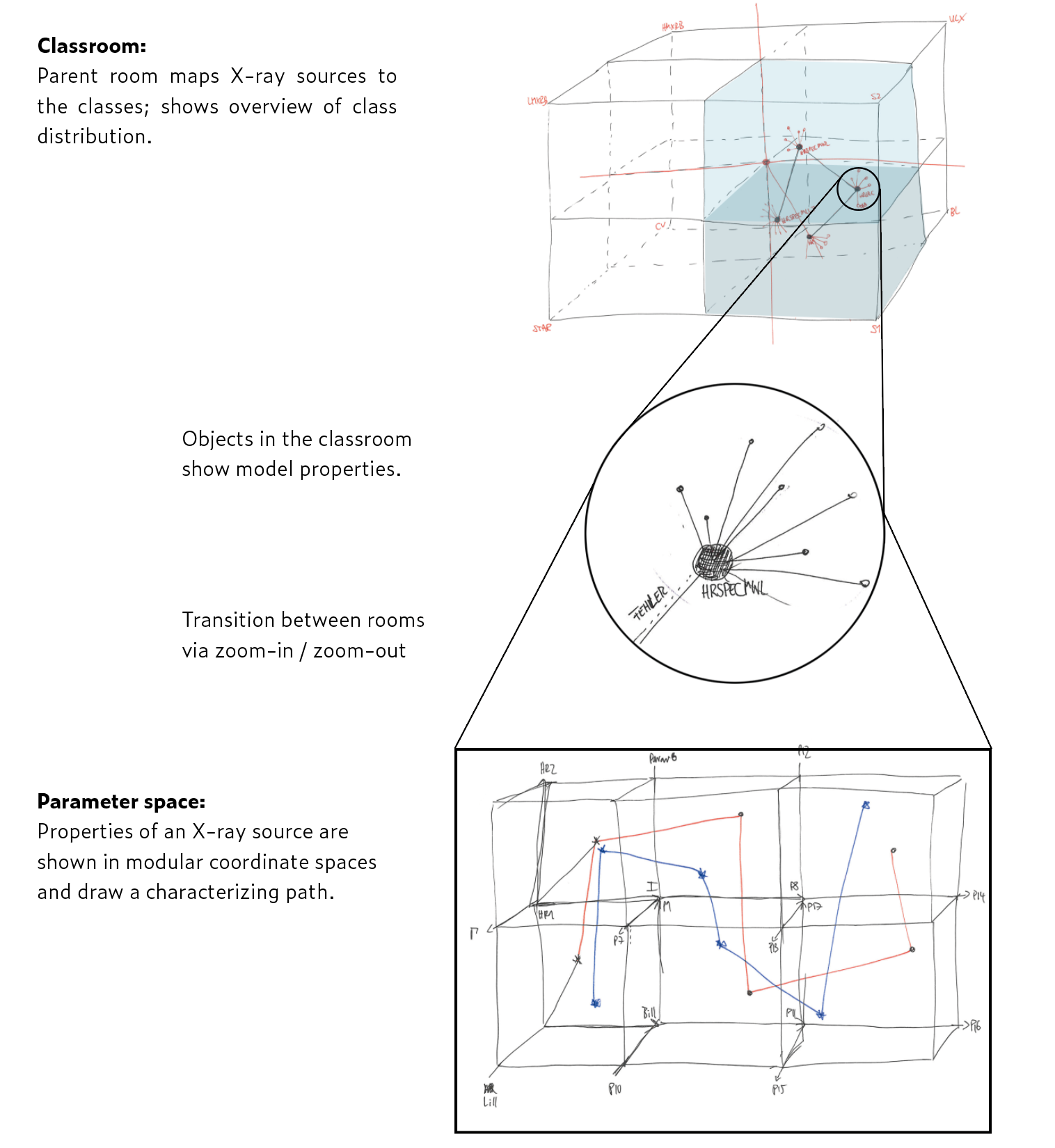
The class room represents the entire cosmos and includes all data points, grouped according to their classification by the algorithms.
教室代表整個宇宙,包括所有數據點,這些數據點根據算法的分類進行分組。
The parameter space represents the observed parameter values of a user-selected subsample of the X-ray sources, and their classification by a selected algorithm.
參數空間表示用戶選擇的X射線源子樣本的觀察參數值,以及通過選定算法進行的分類。
The starting point was to create the ‘class room’, within which each classification type has its own three-dimensional volume. The class room visualizes the classification results of the X-ray sources by the various algorithms and allows users to explore the probability distributions within the database. It prompts questions such as:
起點是創建“教室”,其中每個分類類型都有自己的三維空間。 教室通過各種算法可視化X射線源的分類結果,并允許用戶瀏覽數據庫中的概率分布。 它提示如下問題:
- How did an algorithm classify the unknown X-ray sources? 算法如何對未知的X射線源進行分類?
- What is the probability of a source of belonging to that source class? 一個源屬于該源類的概率是多少?
- What could be an alternative classification? 什么是替代分類?
Visualizing the complete data set in the class room was a very exciting moment! For the first time since the start of the EXTraS project, we were able to clearly visualize more than 500,000 data points without compromise, and compare the results of various algorithms all at once. I felt that I finally got a clear overview of the results and could easily see the distribution of all classified X-ray sources.
在教室中可視化完整的數據集是一個非常激動人心的時刻! 自EXTraS項目啟動以來,我們首次能夠毫不妥協地清晰地可視化超過500,000個數據點,并同時比較各種算法的結果。 我覺得我終于對結果有了一個清晰的概覽,并且可以輕松看到所有分類X射線源的分布。
Here are some screenshots from the VR class room:
這是VR教室的一些屏幕截圖:


The next step was to understand how an algorithm distinguished between different classes. By zooming in and comparing the features of various selected X-ray sources one enters the parameter space. There is a lot to view here, and again we faced the problem of how to visualize all parameter dimensions at once.
下一步是了解算法如何區分不同的類。 通過放大并比較各種選定的X射線源的特征,可以進入參數空間。 這里有很多視圖,而且我們再次面臨如何一次性可視化所有參數維的問題。
The desire to pull the data points apart eventually led to the final approach: to let each source perform a ‘walk’ through space, each source starting from the same point. Their parameter values were used to define the direction and length of each step. This mapping yields that each source produced a unique path (or trace) in space, and objects with similar properties ended up in similar locations in the virtual cosmos.
將數據點分開的愿望最終導致了最終的方法:讓每個源在空間中進行“漫游”,每個源都從同一點開始。 它們的參數值用于定義每個步驟的方向和長度。 通過這種映射,每個源都在空間中產生了唯一的路徑(或軌跡),并且具有相似屬性的對象最終位于虛擬宇宙中的相似位置。
For example, the following image shows the possible walks of three sources belonging to different classes. This one image allows us to draw the same conclusions that we received from comparing the three scatterplots from above.
例如,下圖顯示了屬于不同類別的三個源的可能遍歷。 這一幅圖像使我們能夠得出與從上方比較三個散點圖所得出的相同結論。
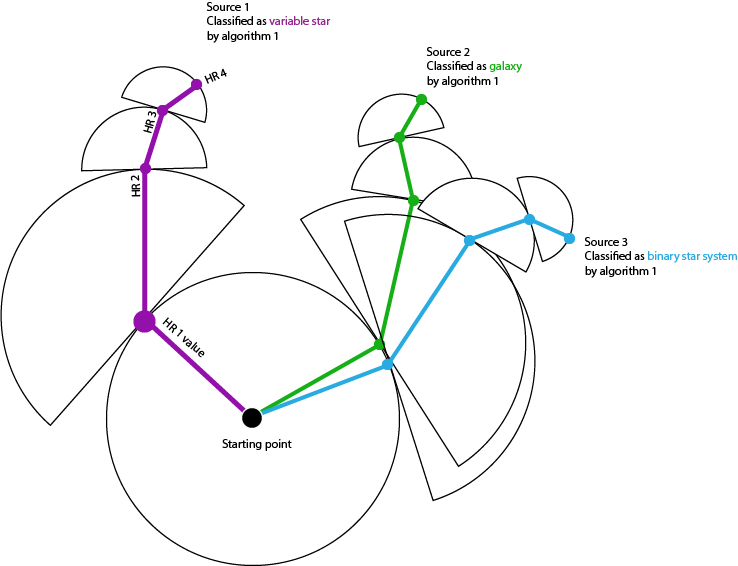
In this sketch, four steps are defined based on the values of the parameters HR1, HR2, HR3, and HR4. Their values mainly define the direction of the step, while the step length is defined by the selected algorithm.
在此草圖中,基于參數HR1,HR2,HR3和HR4的值定義了四個步驟。 它們的值主要定義步的方向,而步長由所選算法定義。
We see that the HR1and HR2 steps already help us to separate variable stars from galaxies or binary star systems. The additional parameters then help to differentiate between the latter two classes.
我們看到HR1和HR2步驟已經幫助我們將可變恒星與星系或雙星系統分開。 然后,附加參數有助于區分后兩個類。
We can see how an algorithm classified an object by the color of the objects path. More detailed information on the data mapping will be given in a subsequent article.
我們可以看到算法如何通過對象路徑的顏色對對象進行分類。 有關數據映射的更多詳細信息將在后續文章中給出。
This is a screenshot of the VR parameter space for a large number of sources that were classified to three different classes (named CV, BL and STAR):
這是VR參數空間的屏幕快照,該VR參數空間適用于被分類為三個不同類(名為CV,BL和STAR)的大量源:
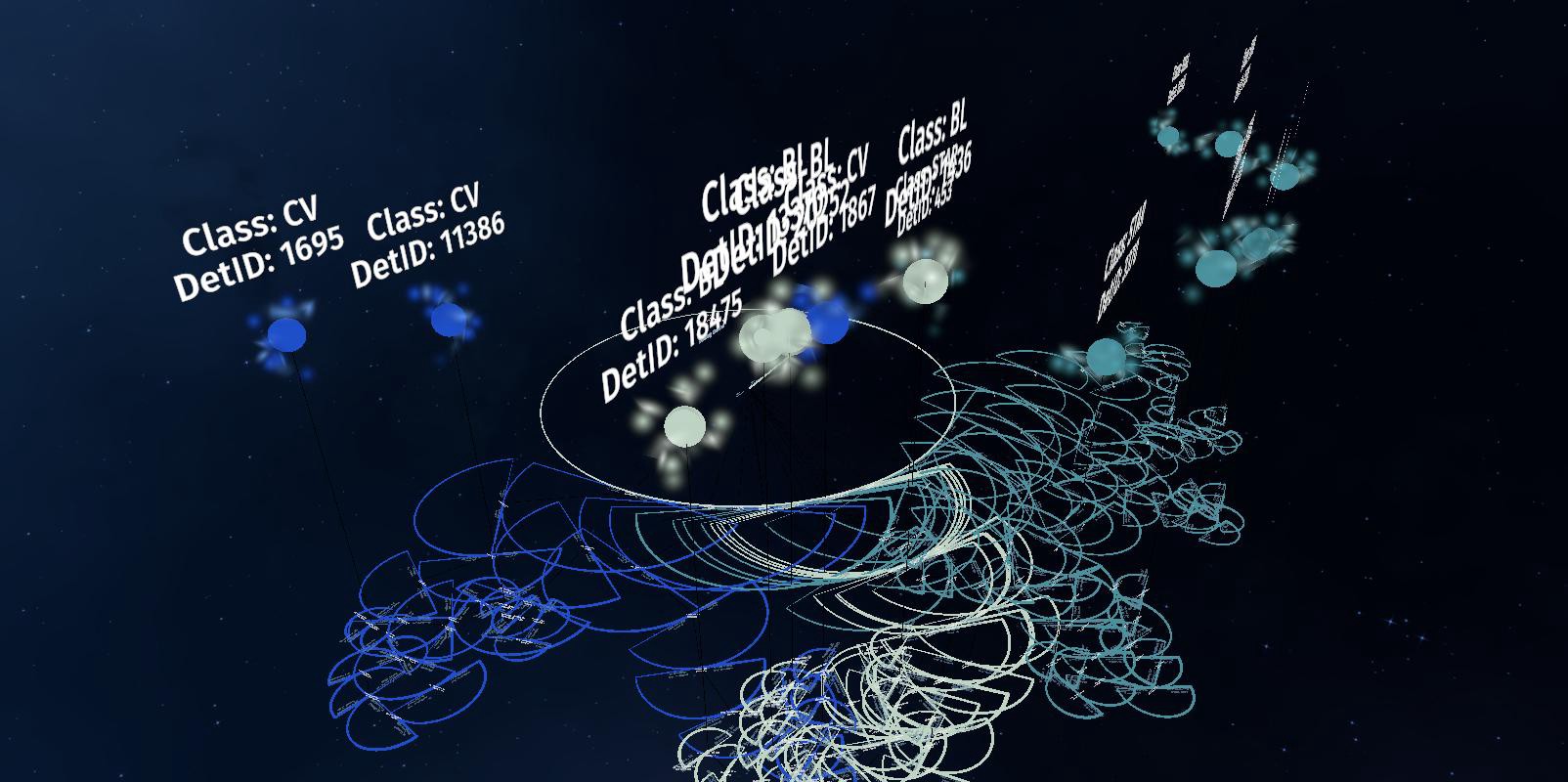
In the image above, there are three classes: variable stars (blue), a very active kind of elliptical galaxies (light green) and normal stars (dark green). We can see that sources whose parameters generated a similar path have been assigned to the same class. We can also see situations where the parameter values caused the path to take on a strange shape, causing confusion for the algorithm.
在上圖中,分為三類: 變星 (藍色),一種非常活躍的橢圓星系 (淺綠色)和普通星(深綠色)。 我們可以看到,其參數生成相似路徑的源已分配給同一類。 我們還可以看到參數值導致路徑采用奇怪形狀,導致算法混亂的情況。
This representation yielded a much better understanding of why a machine-learning algorithm classified a source in a certain way and made clear why it failed to characterize other sources when their paths overlapped.
通過這種表示,可以更好地理解為什么機器學習算法以某種方式對源進行分類,并闡明了為什么當路徑重疊時無法表征其他源的原因。
摘要 (Summary)
Creating the Virtual Data Cosmos convinced me not only of my hypothesis that VR offers great potential for scientific data analysis in science, but also that the pure presentation of big data can create interesting and aesthetic virtual spaces when determined by the specific parameters of the data. This generative approach implies that by exploring the virtual world, users can actually examine an abstract parameter space that is not necessarily visual in nature. By interacting with the virtual elements, the visualization becomes an extremely useful tool.
創建虛擬數據宇宙不僅使我相信虛擬現實為科學中的科學數據分析提供了巨大潛力的假設,而且使大數據的純粹呈現在由數據的特定參數確定的情況下可以創建有趣且美觀的虛擬空間,這使我相信了這一事實。 這種生成方法意味著,通過探索虛擬世界,用戶實際上可以檢查本質上不一定是視覺上的抽象參數空間。 通過與虛擬元素進行交互,可視化成為極其有用的工具。
The scalability in VR is just one advantage over traditional science viz methods. Additionally, the immersive data visualization is fun to work with. It encourages one to focus longer on the data and have a more complete sense of what information might otherwise be hidden.
虛擬現實中的可伸縮性只是相對于傳統科學方法的優勢之一。 此外,沉浸式數據可視化非常有趣。 它鼓勵人們將注意力集中在數據上,并對可能隱藏的信息有更全面的了解。
There is of course plenty more to be explored in this area. Once I was free from using conventional methods to represent the data, designing the parameter space using the radiation properties of the sources raised many new questions for me. How could the parameters be separated more precisely? Are there better representations that would allow the parameter correlations to be analyzed even more clearly? I’ll talk more about how I improved upon the first version by manipulating the parameters in the next article in this series.
當然,在這一領域還有很多值得探索的地方。 一旦我擺脫了使用傳統方法來表示數據的麻煩,利用光源的輻射特性設計參數空間就給我提出了許多新問題。 如何更精確地分離參數? 是否有更好的表示形式可以使參數相關性得到更清晰的分析? 在本系列的下一篇文章中,我將通過操縱參數來詳細討論如何對第一個版本進行改進。
The example of the Virtual Data Cosmos illustrates how applying principles of data visualization in VR can support the sciences by enabling the creation of mental models for multidimensional data. This project shows just how thinking outside the box and coming up with new ways to visualize big data opens many exciting possibilities for science.
虛擬數據宇宙的示例說明了在VR中應用數據可視化原理如何通過為多維數據創建心理模型來支持科學。 該項目展示了開箱即用的思維方式以及提出可視化大數據的新方法如何為科學帶來了許多令人興奮的可能性。
I hope I was able to inspire you to create your own VR data visualization experience. A walk-through of the VR experience I created is available on http://annok.de/vdc-2/
我希望能夠激發您創建自己的VR數據可視化體驗的靈感。 有關我創建的VR體驗的演練,請訪問http://annok.de/vdc-2/
During my years in astronomy, data visualization has been an elemental part of my research. Toward the end of my PhD, I encountered a challenge quite common in modern astronomy: understanding and visualizing information of a big dataset. Since I was also studying information design at the University of Applied Sciences, I started my exploration into data visualizations and how it could be a tool in processing multidimensional data in science or industry. In this series of articles I will describe my adventure, which eventually led to the development of the Virtual Data Cosmos.
在我從事天文學的幾年中,數據可視化一直是我研究的基本組成部分。 在攻讀博士學位時,我遇到了現代天文學中一個相當普遍的挑戰:理解和可視化大數據集的信息。 由于我還在應用科學大學學習信息設計,因此我開始探索數據可視化以及它如何成為處理科學或工業中多維數據的工具。 在本系列文章中,我將描述我的冒險,最終導致了Virtual Data Cosmos的發展。

翻譯自: https://medium.com/nightingale/how-data-visualization-in-vr-can-revolutionize-science-aece026a2207
大數據 vr csdn
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388388.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388388.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388388.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

object-c 日志

計算機真正管理的文件名是什么,計算機題,請大家多多幫忙,謝謝


Xcode做簡易計算器

計算機 編程 教程 pdf,計算機專業教程-第3章編程接口介紹.pdf

導入數據庫怎么導入_導入必要的庫

windows查看系統版本號

02:Kubernetes集群部署——平臺環境規劃

更便捷的畫決策分支圖的工具_做出更好決策的3個要素
-原創力文檔)
供來賓訪問計算機打開安全嗎,計算機安全設置操作手冊(22頁)-原創力文檔

Windows半透明窗口開發技巧



計算性能提升100倍,Uber推出機器學習可視化調試工具

計算機應用基礎成教作業,(計算機應用基礎成教08A卷1.doc

iPhone程序運行流程淺談

Trie樹kmpAC自動機后綴數組Manacher

矩陣線性相關則矩陣行列式_搜索線性時間中的排序矩陣

計算機英文版個人簡歷發文,計算機個人簡歷英文_英文簡歷.doc
