bigquery數據類型
I’ve used BigQuery every day with small and big datasets querying tables, views, and materialized views. During this time I’ve learned some things, I would have liked to know since the beginning. The goal of this article is to give you some tips and recommendations for optimizing your costs and performance.
我每天都使用BigQuery處理大小數據集,用于查詢表,視圖和實例化視圖。 在這段時間里,我學到了一些東西,從一開始我就想知道。 本文的目的是為您提供一些技巧和建議,以優化成本和性能。
基本概念 (Basic concepts)
BigQuery: Serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility [Google Cloud doc].
BigQuery :專為業務敏捷性而設計的無服務器,高度可擴展且經濟高效的多云數據倉庫[ Google Cloud doc ]。

GCP Project: Google Cloud projects form the basis for creating, enabling, and using all Google Cloud services including managing APIs, enabling billing, adding and removing collaborators, and managing permissions for Google Cloud resources [Google Cloud doc]. Each project could have more than one BigQuery Dataset.
GCP項目 :Google Cloud項目構成了創建,啟用和使用所有Google Cloud服務的基礎,包括管理API,啟用計費,添加和刪除協作者以及管理Google Cloud資源的權限[ Google Cloud文檔 ]。 每個項目可能有多個BigQuery數據集。
Dataset: It’s similar to the Databases or Schema concepts in other RDBMS. There are located tables, views, and materialized views.
數據集 :它類似于其他RDBMS中的數據庫或架構概念。 存在表,視圖和實例化視圖。
Slot: It’s a virtual CPU used by BigQuery to execute SQL queries. BigQuery automatically calculates how many slots are required by each query, depending on query size and complexity [Google Cloud doc]. This is the principal indicator if you are in flat-rate pricing because you make a slot commitment (minimum 500 slots).
插槽:這是BigQuery用于執行SQL查詢的虛擬CPU。 BigQuery會根據查詢的大小和復雜程度自動計算每個查詢需要多少個廣告位[ Google Cloud doc ]。 如果您采用固定費用定價,因為這是您承諾的廣告位承諾(最少500個廣告位),則這是主要指標。
Slot/ms: It’s the total amount of slots per millisecond used by a query. That’s the total number of slots consumed by the query over its entire execution time [Taking a practical approach to BigQuery slot usage analysis]. Notice that a query uses a different quantity of slots during all execution, for example, the number of slots when start making a join is higher than making a filter and also is the duration time.
插槽/毫秒:這是查詢使用的每毫秒的插槽總數。 這是查詢在整個執行時間內所消耗的插槽總數[ 采用實用的方法進行BigQuery插槽使用率分析 ]。 請注意,查詢在所有執行過程中使用不同數量的插槽,例如,開始建立連接時的插槽數量要比創建過濾器的數量高,并且持續時間也要多。
Numer of byte processed: It’s the total bytes read when you run a query. This is the principal cost if you are in on-demand pricing.
已處理字節數 :運行查詢時讀取的總字節數。 如果您按需定價,這是主要成本。

Partition: A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data [BigQuery partitioned table].
分區 :分區表是一種特殊的表,分為幾部分,稱為分區,這使管理和查詢數據更加容易[ BigQuery分區表 ]。
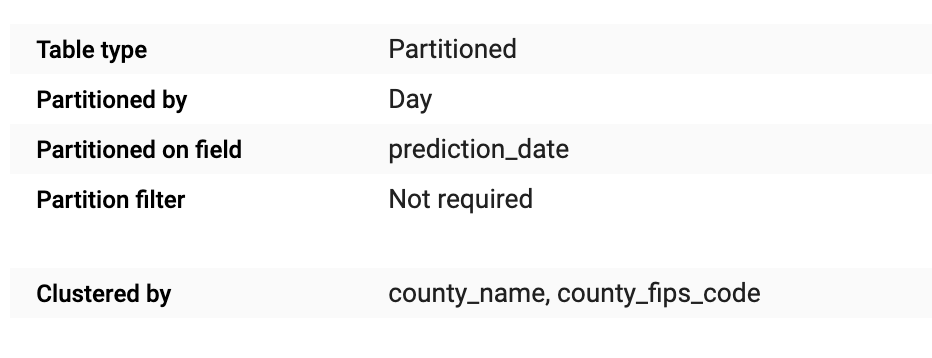
Clustering: A clustered table data is automatically organized based on the contents of one or more columns in the table’s schema [BigQuery clustered table].
集群 :集群表數據是根據表架構[ BigQuery集群表 ]中一個或多個列的內容自動組織的。
Resuming this two important concepts, I’ve made a simple image to understand visually how a table get organized.
總結這兩個重要概念,我制作了一個簡單的圖像以直觀地了解表的組織方式。

費用建議 (Cost recommendations)
There is not a magic recipe, however, It’s important to understand the BigQuery’s cost structure and then what exactly I’m spending on it.
但是,這并不是一個神奇的秘訣,重要的是要了解BigQuery的成本結構,然后確切地講我要花多少錢。
Cost Structure
成本結構
Storage [pricing]
儲存 [ 定價 ]
Active: A monthly charge for data stored in tables or in partitions that have been modified in the last 90 days. $0.020 per GB
活躍:按月收費,用于存儲在過去90天內已修改的表或分區中的數據。 每GB $ 0.020
Long-term: A lower monthly charge for data stored in tables or in partitions that have not been modified in the last 90 days. $0.010 per GB
長期:對于過去90天內未修改的表或分區中存儲的數據,每月收取的費用較低。 每GB $ 0.010
👨🏻?💻 Cost TipPartition your tables whenever is possible. Image this scenario you have a 10 Terabytes DataWarehouse and only use your last month’s data. If all your tables are not partitioned this could mean $200 monthly or for a partitioned slightly more than $100 (without counting the compute cost savings!).
成本提示盡可能對表進行分區。 在這種情況下,您有一個10 TB的DataWarehouse,并且僅使用上個月的數據。 如果您的所有表都沒有分區,則意味著每月200美元,或者分區的價格略高于100美元(不計算節省的計算費用!)。
Since the BigQuery partition limit for each table is 4000 an interesting approach could be to set a ‘maximum history availability’ in this case could be 3 years and the older data migrate to a cheaper storage li GCS nearline ($0.004 per GB), so with this, your DataWarehouse will not grow exponentially.
由于每個表的BigQuery分區限制為4000,因此一種有趣的方法是在這種情況下將“最大歷史可用性”設置為3年,并且較舊的數據遷移到價格便宜的GCS近線存儲(每GB 0.004美元),因此這樣,您的DataWarehouse不會成倍增長。
2. Compute
2.計算
BigQuery has two pricing models and one hybrid model:
BigQuery有兩種定價模型和一種混合模型:
- on-demand: pay for the number of bytes processed $5 per TB. 按需:支付處理的字節數,每TB 5美元。
- flat-rate: you purchase a monthly Slot commitment (minimum commitment is 500 slots, $10 000 monthly), this means you’ll have a maximum compute capacity (500 CPUs) for your GCP Project, the advantage here is you pay a fixed amount doesn’t matter the number of TB processed. 固定費用:您按月購買插槽承諾(最低承諾為500個插槽,每月支付10,000美元),這意味著您將為GCP項目擁有最大的計算容量(500個CPU),這是您需要支付固定金額的處理的TB數量無關緊要。
- flat-slot: is similar to flat-rate the main difference is that the commitment is as little as 60 seconds. The cost here is $20 per hour. flat-slot:類似于固定速率,主要區別在于承諾時間僅為60秒。 每小時費用為$ 20。
👨🏻?💻 Cost Tip
💻 費用提示
To decide which strategy is the best for your team you need to follow your expenses and slot utilization. Let’s check a real case and identify which pricing model is the best and why.
要確定哪種策略最適合您的團隊,您需要了解支出和插槽利用率。 讓我們檢查一個實際案例,并確定哪種定價模型是最佳的以及為什么。
Cloud Monitoring
云監控
Activate this important tool.
激活此重要工具。
Then select the BigQuery dashboard
然后選擇BigQuery儀表板
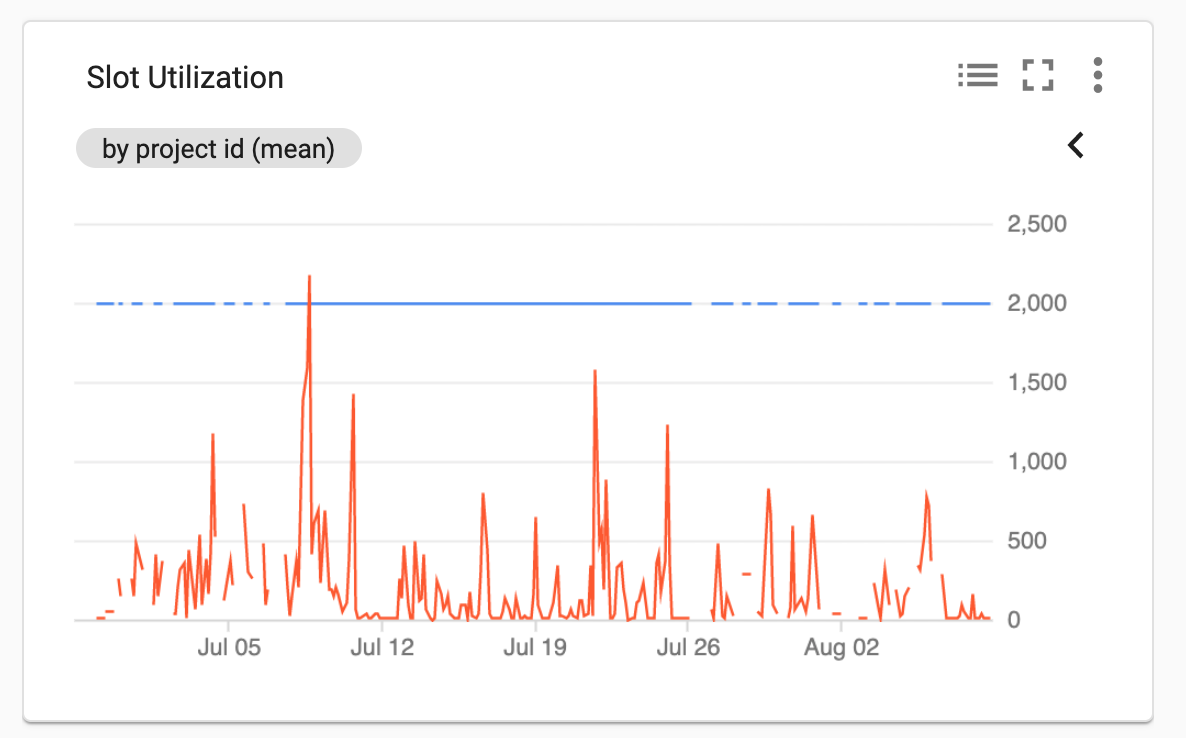
Now Let’s focus on the ‘Slot utilization’ chart. Here we observe a few peaks over 500 that could be caused by intense not optimized queries. This could tell me that an on-demand model or flat-rate could work, to define let’s check bytes processed.
現在,讓我們關注“插槽利用率”圖表。 在這里,我們觀察到500多個峰值可能是由強烈的未經優化的查詢引起的。 這可以告訴我按需模型或固定費率可以工作,以定義讓我們檢查已處理的字節。
Second check the bytes processed and the daily and monthly cost. This query results in the last 30 days we processed 115 Terabytes with a total cost of $572 this means that we are far from the $10,000 fix-rate and we keep with the on-demand price model. Another insight is that on July 16 was the highest peak in terabytes processed so only on this day a good idea would have been to use flex-slot.
其次檢查已處理的字節以及每日和每月成本。 該查詢的結果是,在過去30天內,我們處理了115 TB數據, 總成本為572美元,這意味著我們與10,000美元的固定費用相距甚遠,并且我們保持按需價格模型。 另一個見解是,7月16日是處理的TB的最高峰,因此只有在這一天,才可以使用flex-slot。


績效建議 (Performance recommendations)
The best partition field (Not is always day!)
最佳分區字段(并非總是一天!)
Each time I need to figure out which is the best partition strategy, I rely on the Google Cloud recommendation. At least each partition should be 1GB. This brings me that the majority of my tables are now partitioned by month.
每當我需要確定哪種是最佳分區策略時,我都會依靠Google Cloud的建議。 至少每個分區應為1GB。 這給我帶來了我的大多數表現在按月分區。
👨🏻?💻 Performance Tip
💻 性能提示
Evaluate to activate the ‘require_partition_filter’ so each time a person needs to query a table It will be required to add a Where clause filtering with the partition field.
評估以激活“ require_partition_filter”,以便每次有人需要查詢表時,都需要在分區字段中添加一個Where子句過濾。
ALTER TABLE mydataset.mypartitionedtable
SET OPTIONS (require_partition_filter=true)The best clustering strategy
最佳集群策略
Clustering is another great tool for optimizing your cost and performance. I always think clustering like a ‘box inside a box’ so to access an internal box I need to interact with the upper box.
群集是用于優化成本和性能的另一種出色工具。 我一直認為群集就像“ 盒子里的盒子 ”一樣,因此要訪問內部盒子,我需要與上面的盒子進行交互。
👨🏻?💻 Performance Tip
💻 性能提示
To understand this idea let’s compare the following three queries. The last one only retrieves the data within the partition, and giving the two levels of partitioning means that the query wouldn’t need to ‘open’ each box until finding the ‘city box’. All this will be reflected in a short execute time and fewer bytes consumed.
為了理解這個想法,讓我們比較以下三個查詢。 最后一個僅檢索分區內的數據,并且提供兩個分區級別意味著查詢無需先打開每個框,直到找到“城市框”為止。 所有這些都將在較短的執行時間和更少的字節消耗中得到反映。
Avoid windows functions
避免Windows功能
Operations that need to see all the data in the resulting table at once have to operate on a single node. Un-partitioned window functions like RANK() OVER() or ROW_NUMBER() OVER() will operate on a single node. [Looker question]. This means that it doesn’t matter that you have the best price model with thousands of slots, still, all the data will go to a single node if you use a window function.
需要立即查看結果表中所有數據的操作必須在單個節點上進行。 未分區的窗口函數(例如RANK() OVER()或ROW_NUMBER() OVER()將在單個節點上運行。 [ Looker問題 ]。 這意味著,具有數千個插槽的最佳價格模型并不重要,但是,如果您使用窗口功能,所有數據將轉到單個節點。
👨🏻?💻 “Resources exceeded during query execution” Tip
💻 “查詢執行期間超出了資源”提示
There are a few strategies you could use here. First for example if you need to use OVER()you need to PARTITION the window function by date and build a string as the primary key [Looker question].
您可以在此處使用一些策略。 首先,例如,如果需要使用OVER() ,則需要按日期對window函數進行分區,并構建一個字符串作為主鍵[ Looker問題 ]。
CONCAT(CAST(ROW_NUMBER() OVER(PARTITION BY event_date) AS STRING), ‘|’,(CAST(event_date AS STRING)) as idIf your query contains an ORDER BY clause It may cause the “Resources exceeded” message, for the same reason, all the data is passed to one node. In this situation, avoid ORDER BY if your result is just for creating a new table.
如果您的查詢包含ORDER BY子句,則可能由于相同的原因而導致“超出資源”消息,所有數據都傳遞到一個節點。 在這種情況下,如果結果只是用于創建新表,請避免使用ORDER BY 。
Exists some strategies to increase the resources during the execution time. Please refer to the Google Cloud documentation for more details
存在一些在執行期間增加資源的策略。 有關更多詳細信息,請參閱Google Cloud文檔 。
結論 (Conclusions)
BigQuery is a fantastic Data Warehouse with a challenging price model. To keep your cost-controlled without losing the performance, I recommend you to keep reading more articles and useful information I’m sure exists many excellent tips out there 👨🏻?💻 👩🏻?💻.
BigQuery是一個出色的數據倉庫,具有挑戰性的價格模型。 為了在不損失性能的情況下保持成本控制,我建議您繼續文章和有用的信息,我相信這里確實存在許多出色的技巧👨🏻?💻 👩🏻?💻。
PS This month Google Cloud introduced BigQuery Omni,
PS本月Google Cloud推出了BigQuery Omni ,
It’s a flexible, multi-cloud analytics solution that lets you cost-effectively access and securely analyze data across Google Cloud, Amazon Web Services (AWS), and Azure.
它是一種靈活的多云分析解決方案,可讓您經濟高效地訪問和安全地跨Google Cloud,Amazon Web Services(AWS)和Azure進行數據分析。
I hope to be writing about my experience in the following weeks! Also, keep an eye on Materialized Views, now is in Beta that is why I didn’t add too much information here, however, I recommend you to give it a try.
我希望在接下來的幾周內寫下我的經歷! 另外,請注意Materialized Views (現在處于Beta版),這就是為什么我在此處未添加太多信息的原因,但是,我建議您嘗試一下。
PS 2 if you have any questions, or would like something clarified, ping me on Twitter or LinkedIn I like having a data conversation 😊 If you want to know about Apache Arrow and Apache Spark I had an article A gentle introduction to Apache Arrow with Apache Spark and Pandas with some examples.
PS 2如果您有任何疑問或想澄清一些問題,請在Twitter或LinkedIn上ping我,我想進行數據對話😊如果您想了解Apache Arrow和Apache Spark,我有一篇文章 通過Apache Spark和Pandas輕松介紹Apache Arrow 有一些例子。
有用的鏈接 (Useful links)
Thanks to all these persons behind each link.
感謝每個鏈接后面的所有這些人。
https://cloud.google.com/blog/products/data-analytics/monitoring-resource-usage-in-a-cloud-data-warehouse
https://cloud.google.com/blog/products/data-analytics/monitoring-resource-usage-in-a-cloud-data-warehouse
https://cloud.google.com/bigquery/docs/reservations-workload-management#choosing_between_on-demand_and_flat-rate_billing_models
https://cloud.google.com/bigquery/docs/reservations-workload-management#choosing_between_on-demand_and_flat-rate_billing_models
https://github.com/GoogleCloudPlatform/professional-services/tree/master/tools/bq-visualizer
https://github.com/GoogleCloudPlatform/professional-services/tree/master/tools/bq-visualizer
https://cloud.google.com/bigquery/pricing#on_demand_pricing
https://cloud.google.com/bigquery/pricing#on_demand_pricing
https://cloud.google.com/bigquery/docs/clustered-tables
https://cloud.google.com/bigquery/docs/clustered-tables
https://cloud.google.com/bigquery/docs/partitioned-tables
https://cloud.google.com/bigquery/docs/partitioned-tables
https://cloud.google.com/bigquery/pricing#active_storage
https://cloud.google.com/bigquery/pricing#active_storage
https://cloud.google.com/bigquery/pricing#flat_rate_pricing
https://cloud.google.com/bigquery/pricing#flat_rate_pricing
https://cloud.google.com/bigquery/docs/estimate-costs
https://cloud.google.com/bigquery/docs/estimate-costs
https://cloud.google.com/storage/pricing
https://cloud.google.com/storage/pricing
https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language
https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language
https://medium.com/enkel-digital/googles-big-query-resources-exceeded-during-query-execution-%EF%B8%8F-13c20b6693e2
https://medium.com/enkel-digital/googles-big-query-resources-exceeded-during-query-execution-%EF%B8%8F-13c20b6693e2
https://discourse.looker.com/t/resources-exceeded-during-query-execution-when-building-derived-table-in-bigquery/4414
https://discourse.looker.com/t/resources-exceeded-during-query-execution-when-building-derived-table-in-bigquery/4414
https://cloud.google.com/bigquery/docs/writing-results#large-results
https://cloud.google.com/bigquery/docs/writing-results#large-results
翻譯自: https://medium.com/dataseries/costs-and-performance-lessons-after-using-bigquery-with-terabytes-of-data-54a5809ac912
bigquery數據類型
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388360.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388360.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388360.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

中國計算機學科建設,計算機學科建設戰略研討會暨“十四五”規劃務虛會召開...

iphone開發如何隱藏各種bar
 閉包)
Swift5.1 語言指南(九) 閉包

服務器被攻擊怎么修改,服務器一直被攻擊怎么辦?

腳本 api_從腳本到預測API

Iphone代碼創建視圖

聊聊flink Table的OrderBy及Limit

binary masks_Python中的Masks概念

css+沿正方形旋轉,CSS3+SVG+JS 正方形沿著正方本中軸移動翻轉的動畫

Iphone在ScrollView下點擊TextField使文本筐不被鍵盤遮住

兩高發布司法解釋 依法嚴懲涉地下錢莊犯罪

python 儀表盤_如何使用Python刮除儀表板

VS2015 定時服務及控制端

css文件如何設置scss,Webpack - 如何將scss編譯成單獨的css文件?

Iphone表視圖的簡單操作

PhantomJS的使用

aws emr 大數據分析_DataOps —使用AWS Lambda和Amazon EMR的全自動,低成本數據管道


聯想r630服務器開啟虛擬化,整合虛擬化 聯想萬全R630服務器上市
