熊貓分發
Let’s uncover the practical details of Pandas’ Series, DataFrame, and Panel
讓我們揭露Pandas系列,DataFrame和Panel的實用細節
Note to the Readers: Paying attention to comments in examples would be more helpful than going through the theory itself.
讀者注意:注意示例中的注釋比通過理論本身更有用。
· Series (1D data structure: Column-vector of DataTable)· DataFrame (2D data structure: Table)· Panel (3D data structure)
· 系列(1D數據結構:DataTable的列向量) · DataFrame(2D數據結構:Table) · 面板(3D數據結構)
Pandas is a column-oriented data analysis API. It’s a great tool for handling and analyzing input data, and many ML framework support pandas data structures as inputs.
Pandas是面向列的數據分析API。 這是處理和分析輸入數據的好工具,許多ML框架都支持熊貓數據結構作為輸入。
熊貓數據結構 (Pandas Data Structures)
Refer Intro to Data Structures on Pandas docs.
請參閱 熊貓文檔上的 數據結構簡介 。
The primary data structures in pandas are implemented as two classes: DataFrame and Series.
大熊貓中的主要數據結構實現為兩類: DataFrame 和 Series 。
Import numpy and pandas into your namespace:
將 numpy 和 pandas 導入您的名稱空間:
import numpy as np
import pandas as pd
import matplotlib as mpl
np.__version__
pd.__version__
mpl.__version__系列(一維數據結構:DataTable的列向量) (Series (1D data structure: Column-vector of DataTable))
CREATING SERIES
創作系列
Series is one-dimensional array having elements with non-unique labels (index), and is capable of holding any data type. The axis labels are collectively referred to as index. The general way to create a Series is to call:
系列是 一維數組,具有帶有非唯一標簽(索引)的元素 ,并且能夠保存任何數據類型。 軸標簽 統稱為 指標 。 創建系列的一般方法是調用:
pd.Series(data, index=index)Here, data can be an NumPy’s ndarray, Python’s dict, or a scalar value (like 5). The passed index is a list of axis labels.
在這里, data 可以是NumPy的 ndarray ,Python的 dict 或標量值(如 5 )。 傳遞的 index 是軸標簽的列表。
Note: pandas supports non-unique index values. If an operation that does not support duplicate index values is attempted, an exception will be raised at that time.
注意: pandas支持 非唯一索引值 。 如果嘗試執行不支持重復索引值的操作,則此時將引發異常。
If data is list or ndarray (preferred way):
如果 data 是 list 或 ndarray (首選方式):
If data is an ndarray or list, then index must be of the same length as data. If no index is passed, one will be created having values [0, 1, 2, ... len(data) - 1].
如果 data 是 ndarray 或 list ,則 index 必須與 data 具有相同的長度 。 如果沒有傳遞索引,則將創建一個具有 [0, 1, 2, ... len(data) - 1] 值的索引 。
If data is a scalar value:
如果 data 是標量值:
If data is a scalar value, an index must be provided. The value will be repeated to match the length of index.
如果 data 是標量值,則 必須提供 index 。 該值將重復以匹配 index 的長度 。
If data is dict:
如果 data 是 dict :
If data is a dict, and - if index is passed the values in data corresponding to the labels in the index will be pulled out, otherwise - an index will be constructed from the sorted keys of the dict, if possible
如果 data 是一個 dict ,以及 - 如果 index 被傳遞的值在 data 對應于所述標簽的 index 將被拉出,否則 - 一個 index 將從的排序鍵來構建 dict ,如果可能的話
SERIES IS LIKE NDARRAY AND DICT COMBINED
SERIES 像 NDARRAY 和 DICT 結合
Series acts very similar to an ndarray, and is a valid argument to most NumPy functions. However, things like slicing also slice the index. Series can be passed to most NumPy methods expecting an 1D ndarray.
Series 行為與 ndarray 非常相似 ,并且是大多數NumPy函數的有效參數。 但是,諸如切片之類的事情也會對索引進行切片。 系列可以傳遞給大多數期望一維 ndarray NumPy方法 。
A key difference between Series and ndarray is automatically alignment of the data based on labels during Series operations. Thus, you can write computations without giving consideration to whether the Series object involved has some non-unique labels. For example,
Series 和 ndarray 之間的主要區別在于 在 Series 操作 期間,基于標簽的數據自動對齊 。 因此,您可以編寫計算而無需考慮所 涉及 的 Series 對象 是否 具有某些非唯一標簽。 例如,


The result of an operation between unaligned Seriess will have the union of the indexes involved. If a label is not found in one series or the other, the result will be marked as missing NaN.
未對齊 Series 之間的運算結果 將具有所 涉及索引 的 并集 。 如果在一個序列或另一個序列中未找到標簽,則結果將標記為缺少 NaN 。
Also note that in the above example, the index 'b' was duplicated, so s['b'] returns pandas.core.series.Series.
還要注意,在上面的示例中,索引 'b' 是重復的,因此 s['b'] 返回 pandas.core.series.Series 。
Series is also like a fixed-sized dict on which you can get and set values by index label. If a label is not contained while reading a value, KeyError exception is raised. Using the get method, a missing label will return None or specified default.
Series 還類似于固定大小的 dict ,您可以在其上通過索引標簽獲取和設置值。 如果在讀取值時不包含標簽, 則會引發 KeyError 異常。 使用 get 方法,缺少的標簽將返回 None 或指定的默認值。
SERIES‘ NAME ATTRIBUTE
SERIES “ NAME ATTRIBUTE
Series can also have a name attribute (like DataFrame can have columns attribute). This is important as a DataFrame can be seen as dict of Series objects.
Series 還可以具有 name 屬性 (例如 DataFrame 可以具有 columns 屬性)。 這是很重要的 DataFrame 可以看作是 dict 的 Series 對象 。
The Series‘ name will be assigned automatically in many cases, in particular when taking 1D slices of DataFrame.
該 Series “ name 會自動在許多情況下采取的1D切片時進行分配,特別是 DataFrame 。
For example,
例如,
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
d = pd.DataFrame(d)
d
# one two
# 0 1.0 4.0
# 1 2.0 3.0
# 2 3.0 2.0
# 3 4.0 1.0
type(d) #=> pandas.core.frame.DataFrame
d.columns #=> Index(['one', 'two'], dtype='object')
d.index #=> RangeIndex(start=0, stop=4, step=1)s = d['one']
s
# 0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
# Name: one, dtype: float64
type(s) #=> pandas.core.series.Series
s.name #=> 'one'
s.index #=> RangeIndex(start=0, stop=4, step=1)You can rename a Series with pandas.Series.rename() method or by just assigning new name to name attribute.
您可以使用 pandas.Series.rename() 方法 重命名系列,也可以 僅將新名稱分配給 name 屬性。
s = pd.Series(np.random.randn(5), name='something')
id(s) #=> 4331187280
s.name #=> 'something's.name = 'new_name'
id(s) #=> 4331187280
s.name #=> 'new_name's.rename("yet_another_name")
id(s) #=> 4331187280
s.name #=> 'yet_another_name'COMPLEX TRANSFORMATIONS ON SERIES USING SERIES.APPLY
使用 SERIES.APPLY SERIES 復雜的轉換
NumPy is a popular toolkit for scientific computing. Pandas’ Series can be used as argument to most NumPy functions.
NumPy是用于科學計算的流行工具包。 熊貓Series可以用作大多數NumPy函數的參數。
For complex single-column transformation, you can use Series.apply. Like Python’s map function, Series.apply accepts as an argument a lambda function which is applied to each value.
對于復雜的單列轉換,可以使用 Series.apply 。 像Python的 map 函數一樣, Series.apply 接受一個lambda函數作為參數,該函數應用于每個值。
DataFrame (2D數據結構:表格) (DataFrame (2D data structure: Table))
Refer: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
請參閱: https : //pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
DataFrame is a 2D labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or a SQL table, or a dict of Series objects. Like Series, DataFrame accepts many different kinds of inputs.
DataFrame 是2D標簽的數據結構,具有可能不同類型的列。 你可以認為它像一個電子表格或SQL表或 dict 的 Series 對象 。 與 Series 一樣 , DataFrame 接受許多不同種類的輸入。
Along with the data, you can optionally pass index (row labels) and columns (column labels) arguments. Note that index can have non-unique elements (like that of Series). Similarly, columns names can also be non-unique.
與數據一起,您可以選擇傳遞 index (行標簽) 和 columns (列標簽) 參數。 請注意, index 可以具有 非唯一 元素(例如 Series 元素 )。 同樣, columns 名也可以 是非唯一的 。
If you pass an index and/or columns, you are guaranteeing the index and / or columns of the resulting DataFrame. Thus, a dict of Series plus a specific index will discard all data not matching up to the passed index (similar to passing a dict as data to Series).
如果傳遞 index 和/或 columns ,則可以 保證 所得 DataFrame 的 index 和/或 columns 。 因此, dict 的 Series 加上特定的索引將 丟棄 所有數據不匹配到所傳遞的索引(類似于傳遞一個 dict 作為 data 到 Series )。
If axis labels (index) are not passed, they will be constructed from the input data based on common sense rules.
如果 未傳遞 軸標簽( index ),則將基于常識規則根據輸入數據構造它們。
CREATING DATAFRAMEFrom a dict of ndarrays/lists
CREATING DATAFRAME 從 dict 的 ndarray S / list 小號
The ndarrays/lists must all be the same length. If an index is passed, it must clearly also be the same length as that of data ndarrays. If no index is passed, then implicit index will be range(n), where n is the array length.
該 ndarray S / list 小號都必須是相同的長度 。 如果 傳遞 了 index ,則它顯然也必須 與數據 ndarray s的 長度相同 。 如果沒有 傳遞 index ,則隱式 index 將是 range(n) ,其中 n 是數組長度。
For example,
例如,


From a dict of Series (preferred way):
從 dict 的 Series (首選方式):
The resultant index will be the union of the indexes of the various Series (each Series may be of a different length and may have different index). If there are nested dicts, these will be first converted to Series. If no columns are passed, the columns will be list of dict keys. For example,
將得到的 index 將是 各個的索引的 聯合 Series (各 Series 可以是不同的長度,并且可具有不同的 index )。 如果存在嵌套的 dict ,則將它們首先轉換為 Series 。 如果沒有 columns 都過去了, columns 將是 list 的 dict 鍵。 例如,


The row and column labels can be accessed respectively by accessing the index and columns attributes.
可以通過訪問 index 和 columns 屬性 分別訪問行和列標簽 。

From a list of dicts:
從 dict list 中 :
For example,
例如,
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]pd.DataFrame(data2)
# a b c
# 0 1 2 NaN
# 1 5 10 20.0pd.DataFrame(data2, index=['first', 'second'])
# a b c
# first 1 2 NaN
# second 5 10 20.0pd.DataFrame(data2, columns=['a', 'b'])
# a b
# 0 1 2
# 1 5 10From a Series:
從 Series :
The result will be a DataFrame with the same index as the input Series, and with one column whose name is the original name of the Series (only if no other column name provided).
結果將是一個 DataFrame ,其 index 與輸入 Series 相同 ,并且其中一列的名稱是 Series 的原始名稱 (僅當未提供其他列名稱時)。
For example,
例如,
s = pd.Series([1., 2., 3.], index=['a', 'b', 'c'])
type(s) #=> pandas.core.series.Seriesdf2 = pd.DataFrame(s)
df2
# 0
# a 1.0
# b 2.0
# c 3.0type(df2) #=> pandas.core.frame.DataFrame
df2.columns #=> RangeIndex(start=0, stop=1, step=1)
df2.index #=> Index(['a', 'b', 'c'], dtype='object')From a Flat File
從平面文件
The pandas.read_csv (preferred way):
所述 pandas.read_csv (優選的方式):
You can read CSV files into a DataFrame using pandas.read_csv() method. Refer to the official docs for its signature.
您可以 使用 pandas.read_csv() 方法將 CSV文件讀取到 DataFrame 。 請參閱官方文檔以獲取其簽名。
For example,
例如,

CONSOLE DISPLAY AND SUMMARY
控制臺顯示和摘要
Some helpful methods and attributes:
一些有用的方法和屬性:

Wide DataFrames will be printed (print) across multiple rows by default. You can change how much to print on a single row by setting display.width option. You can adjust the max width of the individual columns by setting display.max_colwidth.
默認情況下,寬數據框將跨多行打印( print )。 您可以通過設置display.width選項更改在單行上打印的數量。 您可以通過設置display.max_colwidth來調整各個列的最大寬度。
pd.set_option('display.width', 40) # default is 80
pd.set_option('display.max_colwidth', 30)You can also display display.max_colwidth feature via the expand_frame_repr option. This will print the table in one block.
您還可以通過expand_frame_repr選項顯示display.max_colwidth功能。 這將把表格打印成一個塊。
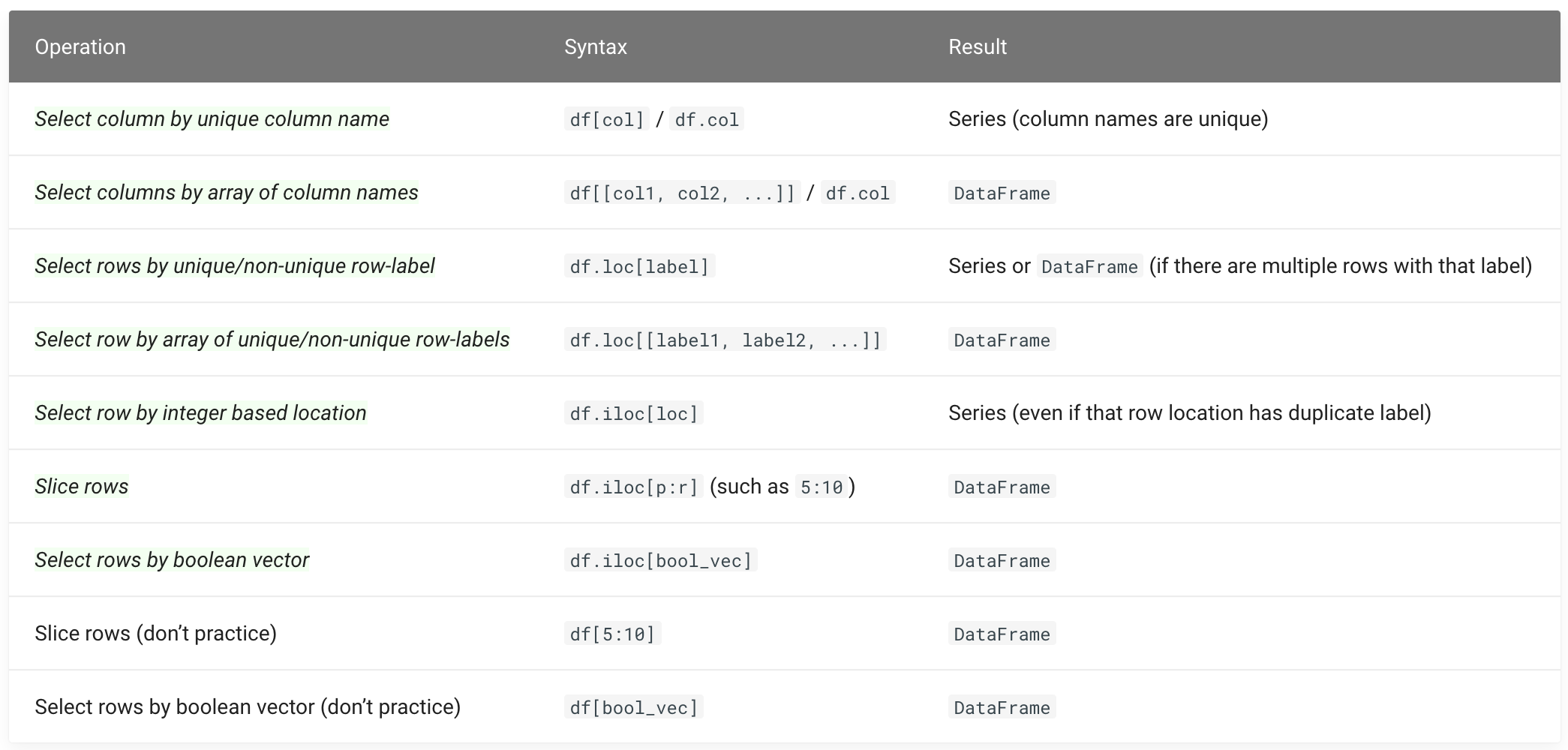
INDEXING ROWS AND SELECTING COLUMNS
索引行和選擇列
The basics of DataFrame indexing and selecting are as follows:
DataFrame 索引和選擇 的基礎 如下:
For example,
例如,
d = {
'one' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'a']),
'two' : pd.Series(['A', 'B', 'C', 'D'], index=['a', 'b', 'c', 'a'])
}df = pd.DataFrame(d)
df
# one two
# a 1.0 A
# b 2.0 B
# c 3.0 C
# a 4.0 Dtype(df['one']) #=> pandas.core.series.Series
df['one']
# a 1.0
# b 2.0
# c 3.0
# a 4.0
# Name: one, dtype: float64type(df[['one']]) #=> pandas.core.frame.DataFrame
df[['one']]
# one
# a 1.0
# b 2.0
# c 3.0
# a 4.0type(df[['one', 'two']]) #=> pandas.core.frame.DataFrame
df[['one', 'two']]
# one two
# a 1.0 A
# b 2.0 B
# c 3.0 C
# a 4.0 Dtype(df.loc['a']) #=> pandas.core.frame.DataFrame
df.loc['a']
# one two
# a 1.0 A
# a 4.0 Dtype(df.loc['b']) #=> pandas.core.series.Series
df.loc['b']
# one 2
# two B
# Name: b, dtype: objecttype(df.loc[['a', 'c']]) #=> pandas.core.frame.DataFrame
df.loc[['a', 'c']]
# one two
# a 1.0 A
# a 4.0 D
# c 3.0 Ctype(df.iloc[0]) #=> pandas.core.series.Series
df.iloc[0]
# one 1
# two A
# Name: a, dtype: objectdf.iloc[1:3]
# one two
# b 2.0 B
# c 3.0 Cdf.iloc[[1, 2]]
# one two
# b 2.0 B
# c 3.0 Cdf.iloc[[1, 0, 1, 0]]
# one two
# b 2.0 B
# a 1.0 A
# b 2.0 B
# a 1.0 Adf.iloc[[True, False, True, False]]
# one two
# a 1.0 A
# c 3.0 CCOLUMN ADDITION AND DELETION
列添加和刪除
You can treat a DataFrame semantically like a dict of like-indexed Series objects. Getting, setting, and deleting columns works with the same syntax as the analogous dict operations.
您可以將 DataFrame 語義上 像 索引相似的 Series 對象 的 dict 一樣 對待 。 獲取,設置和刪除列的語法與類似 dict 操作的 語法相同 。
When inserting a Series that doesn’t have the same index as the DataFrame, it will be conformed to the DataFrame‘s index (that is, only values with index matching DataFrame‘s existing index will be added, and missing index will get NaN (of the same dtype as dtype of that particular column) as value.
當插入一個 Series 不具有相同 index 的 DataFrame ,將符合該 DataFrame 的 index (即只與價值 index 匹配 DataFrame 現有 index 將被添加和缺失 index 會得到 NaN (相同 dtype 如 dtype 的特定列的)作為值。
When inserting a columns with scalar value, it will naturally be propagated to fill the column.
當插入具有標量值的列時,它自然會傳播以填充該列。
When you insert a same length (as that of DataFrame to which it is inserted) ndarray or list, it just uses existing index of the DataFrame. But, try not to use ndarrays or list directly with DataFrames, intead you can first convert them to Series as follows:
當您插入相同長度( DataFrame 插入 的 DataFrame 相同 )的 ndarray 或 list ,它僅使用 DataFrame 現有索引 。 不過,盡量不要用 ndarrays 或 list 直接與 DataFrame S,這一翻譯可以先它們轉換為 Series 如下:
df['yet_another_col'] = array_of_same_length_as_df# is same asdf['yet_another_col'] = pd.Series(array_of_same_length_as_df, index=df.index)For example,
例如,


By default, columns get inserted at the end. The insert() method is available to insert at a particular location in the columns.
默認情況下,列會插入到末尾。 所述 insert() 方法可在列中的一個特定的位置插入。
Columns can be deleted using del, like keys of dict.
可以使用 del 刪除列 ,如dict鍵。
DATA ALIGNMENT AND ARITHMETICArithmetics between DataFrame objects
DataFrame 對象 之間的數據 DataFrame 和 DataFrame
Data between DataFrame objects automatically align on both the columns and the index (row labels). Again, the resulting object will have the union of the column and row labels. For example,
DataFrame 對象 之間的數據會 自動 在列和索引(行標簽) 上 對齊 。 同樣,得到的對象將有 列和行標簽的 結合 。 例如,

Important: You might like to try above example with duplicate columns names and index values in each individual data frame.
重要提示:您可能想嘗試上面的示例,在每個單獨的數據框中使用重復的列名和索引值。
Boolean operators (for example, df1 & df2) work as well.
布爾運算符(例如df1 & df2 )也可以工作。
Arithmetics between DataFrame and Series:
DataFrame 和 Series 之間的算法 :
When doing an operation between DataFrame and Series, the default behavior is to broadcast Series row-wise to match rows in DataFrame and then arithmetics is performed. For example,
在 DataFrame 和 Series 之間進行操作時 ,默認行為是按 行 廣播 Series 以匹配 DataFrame 中的行 ,然后執行算術運算。 例如,

In the special case of working with time series data, and the DataFrame index also contains dates, the broadcasting will be column-wise. For example,
在使用時間序列數據的特殊情況下,并且 DataFrame 索引還包含日期,廣播將按列進行。 例如,

Here pd.date_range() is used to create fixed frequency DatetimeIndex, which is then used as index (rather than default index of 0, 1, 2, ...) for a DataFrame.
這里pd.date_range()是用于創建固定頻率DatetimeIndex,然后將其用作index (而非默認索引0, 1, 2, ... ),用于一個DataFrame 。
For explicit control over the matching and broadcasting behavior, see the section on flexible binary operations.
有關對匹配和廣播行為的顯式控制,請參見關于靈活的二進制操作的部分。
Arithmetics between DataFrame and Scalars
DataFrame 和標量 之間的算法
Operations with scalars are just as you would expect: broadcasted to each cell (that is, to all columns and rows).
標量運算與您期望的一樣:廣播到每個單元格(即,所有列和行)。
DATAFRAME METHODS AND FUNCTIONS
DATAFRAME 方法和功能
Evaluating string describing operations using eval() method
使用 eval() 方法 評估字符串描述操作
Note: Rather use assign() method.
注意:而是使用 assign() 方法。
The eval() evaluates a string describing operations on DataFrame columns. It operates on columns only, not specific rows or elements. This allows eval() to run arbitrary code, which can make you vulnerable to code injection if you pass user input into this function.
eval()評估一個字符串,該字符串描述對DataFrame列的操作。 它僅對列起作用,而不對特定的行或元素起作用。 這允許eval()運行任意代碼,如果將用戶輸入傳遞給此函數,可能會使您容易受到代碼注入的攻擊。
df = pd.DataFrame({'A': range(1, 6), 'B': range(10, 0, -2)})df
# A B
# 0 1 10
# 1 2 8
# 2 3 6
# 3 4 4
# 4 5 2df.eval('2*A + B')
# 0 12
# 1 12
# 2 12
# 3 12
# 4 12
# dtype: int64Assignment is allowed though by default the original DataFrame is not modified. Use inplace=True to modify the original DataFrame. For example,
允許分配,盡管默認情況下不修改原始DataFrame 。 使用inplace inplace=True修改原始DataFrame。 例如,
df.eval('C = A + 2*B', inplace=True)df
# A B C
# 0 1 10 21
# 1 2 8 18
# 2 3 6 15
# 3 4 4 12
# 4 5 2 9Assigning new columns to the copies in method chains — assign() method
在方法鏈中為副本分配新的列— assign() 方法
Inspired by dplyer‘s mutate verb, DataFrame has an assign() method that allows you to easily create new columns that are potentially derived from existing columns.
受 dplyer 的 mutate 動詞 啟發 , DataFrame 具有一個 assign() 方法,可讓您輕松創建可能從現有列派生的新列。
The assign() method always returns a copy of data, leaving the original DataFrame untouched.
的 assign() 方法 總是返回數據的副本 中,而原始 DataFrame 不變。
Note: Also check pipe() method.
注意:還要檢查 pipe() 方法。
df2 = df.assign(one_ratio = df['one']/df['out_of'])df2
# one two one_trunc out_of const one_ratio
# a 1.0 1.0 1.0 100 1 0.01
# b 2.0 2.0 2.0 100 1 0.02
# c 3.0 3.0 NaN 100 1 0.03
# d NaN 4.0 NaN 100 1 NaNid(df) #=> 4436438040
id(df2) #=> 4566906360Above was an example of inserting a precomputed value. We can also pass in a function of one argument to be evaluated on the DataFrame being assigned to.
上面是插入預計算值的示例。 我們還可以傳入一個參數的函數,以在 要分配給 其的 DataFrame 上求值。
df3 = df.assign(one_ratio = lambda x: (x['one']/x['out_of']))
df3
# one two one_trunc out_of const one_ratio
# a 1.0 1.0 1.0 100 1 0.01
# b 2.0 2.0 2.0 100 1 0.02
# c 3.0 3.0 NaN 100 1 0.03
# d NaN 4.0 NaN 100 1 NaNid(df) #=> 4436438040
id(df3) #=> 4514692848This way you can remove a dependency by not having to use name of the DataFrame.
這樣,您可以不必使用 DataFrame 名稱來刪除依賴 DataFrame 。
Appending rows with append() method
用 append() 方法 追加行
The append() method appends rows of other_data_frame DataFrame to the end of current DataFrame, returning a new object. The columns not in the current DataFrame are added as new columns.
的 append() 方法追加 的 行 other_data_frame DataFrame 到當前 DataFrame ,返回一個新對象。 當前 DataFrame 中 不在的列 將作為新列添加。
Its most useful syntax is:
它最有用的語法是:
<data_frame>.append(other_data_frame, ignore_index=False)Here,
這里,
other_data_frame: Data to be appended in the form ofDataFrameorSeries/dict-like object, or alistof these.other_data_frame:DataFrame或DataFrameSeries/dict的對象或它們的list形式附加的數據。ignore_index: By default it isFalse. If it isTrue, then index labels ofother_data_frameare ignoredignore_index:默認為False。 如果為True,則將忽略other_data_frame索引標簽
Note: Also check concat() function.
注意:還要檢查 concat() 函數。
For example,
例如,
df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
df
# A B
# 0 1 2
# 1 3 4
df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
df2
# A B
# 0 5 6
# 1 7 8
df.append(df2)
# A B
# 0 1 2
# 1 3 4
# 0 5 6
# 1 7 8
df.append(df2, ignore_index=True)
# A B
# 0 1 2
# 1 3 4
# 2 5 6
# 3 7 8The drop() method
的 drop() 方法
Note: Rather use del as stated in Column Addition and Deletion section, and indexing + re-assignment for keeping specific rows.
注意:最好使用“ 列添加和刪除”部分中所述的 del ,并使用索引+重新分配來保留特定行。
The drop() function removes rows or columns by specifying label names and corresponding axis, or by specifying directly index or column names. When using a multi-index, labels on different levels can be removed by specifying the level.
drop()函數通過指定標簽名稱和相應的軸,或通過直接指定索引或列名稱來刪除行或列。 使用多索引時,可以通過指定級別來刪除不同級別上的標簽。
The values attribute and copy() method
所述 values 屬性和 copy() 方法
The values attribute
該 values 屬性
The values attribute returns NumPy representation of a DataFrame‘s data. Only the values in the DataFrame will be returned, the axes labels will be removed. A DataFrame with mixed type columns (e.g. str/object, int64, float32) results in an ndarray of the broadest type that accommodates these mixed types.
所述 values 屬性一個的返回NumPy的表示 DataFrame 的數據。 僅 返回 DataFrame 的值, 將刪除軸標簽。 甲 DataFrame 與混合型柱(例如STR /對象,Int64類型,FLOAT32)導致的 ndarray 容納這些混合類型的最廣泛的類型。
Check Console Display section for an example.
有關示例,請參見控制臺顯示部分。
The copy() method
的 copy() 方法
The copy() method makes a copy of the DataFrame object’s indices and data, as by default deep is True. So, modifications to the data or indices of the copy will not be reflected in the original object.
該 copy() 方法使副本 DataFrame 對象的指標和數據,因為默認情況下 deep 為 True 。 因此,對副本的數據或索引的修改將不會反映在原始對象中。
If deep=False, a new object will be created without copying the calling object’s data or index (only references to the data and index are copied). Any changes to the data of the original will be reflected in the shallow copy (and vica versa).
如果 deep=False ,將在不復制調用對象的數據或索引的情況下創建新對象(僅復制對數據和索引的引用)。 原始數據的任何更改都將反映在淺表副本中(反之亦然)。
Its syntax is:
其語法為:
df.copy(deep=True)Transposing using T attribute or transpose() method
使用 T 屬性或 transpose() 方法進行 transpose()
Refer section Arithmetic, matrix multiplication, and comparison operations.
請參閱算術,矩陣乘法和比較運算部分。
To transpose, you can call the method transpose(), or you can the attribute T which is accessor to transpose() method.
要進行轉置,可以調用方法 transpose() ,也可以使用屬性 T ,它是 transpose() 方法的 訪問者 。
The result is a DataFrame as a reflection of original DataFrame over its main diagonal by writing rows as columns and vice-versa. Transposing a DataFrame with mixed dtypes will result in a homogeneous DataFrame with the object dtype. In such a case, a copy of the data is always made.
結果是 通過將行寫為列, 將 DataFrame 反映 在其主對角線上 的原始 DataFrame ,反之亦然。 移調一個 DataFrame 具有混合dtypes將導致同質 DataFrame 與對象D型。 在這種情況下,始終會復制數據。
For example,
例如,


Sorting (sort_values(), sort_index()), Grouping (groupby()), and Filtering (filter())
排序( sort_values() , sort_index() ),分組( groupby() )和過濾( filter() )
The sort_values() method
所述 sort_values() 方法
Dataframe can be sorted by a column (or by multiple columns) using sort_values() method.
可以使用 sort_values() 方法 按一列(或按多列)對數據 sort_values() 進行排序 。
For example,
例如,


The sort_index() method
所述 sort_index() 方法
The sort_index() method can be used to sort by index.
所述 sort_index() 方法可用于通過排序 index 。
For example,
例如,

The groupby() method
所述 groupby() 方法
The groupby() method is used to group by a function, label, or a list of labels.
所述 groupby() 方法由功能,標簽或標簽的列表用于組。
For example,
例如,


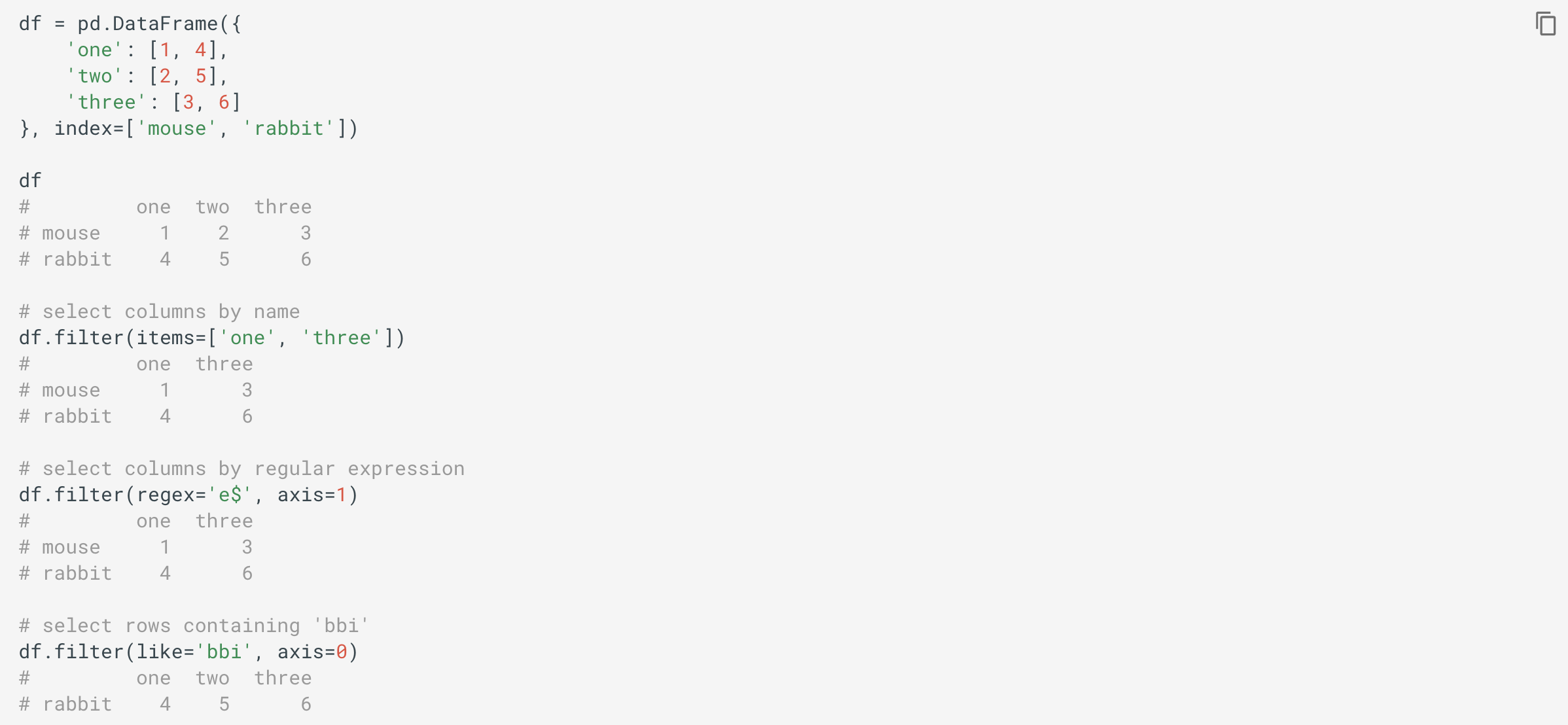
The filter() method
所述 filter() 方法
The filter() method returns subset of rows or columns of DataFrame according to labels in the specified index. Note that this method does not filter a DataFrame on its contents, the filter is applied to the labels of the index, or to the column names.
所述 filter() 方法返回的行或列的子集 DataFrame 根據在指定的索引標簽。 請注意,此方法不會 在其內容上 過濾 DataFrame 將過濾器應用于索引的標簽或列名。
You can use items, like and regex parameters, but note that they are enforced to be mutually exclusive. The parameter axis default to the info axis that is used when indexing with [].
您可以使用 items , like 和 regex 參數,但請注意,它們必須相互排斥。 參數 axis 默認為使用 [] 索引時使用的信息軸 。
For example,
例如,
Melting and Pivoting using melt() and pivot() methods
使用 melt() 和 pivot() 方法 進行 melt() 和 pivot()
The idea of melt() is to keep keep few given columns as id-columns and convert rest of the columns (called variable-columns) into variable and value, where the variable tells you the original columns name and value is corresponding value in original column.
melt() 的想法 是保留給定的列作為 id列 ,并將其余的列(稱為 variable-columns )轉換為 variable 和 value ,其中 變量 告訴您原始列的名稱和 value 是 原始列 中的對應值柱。
If there are n variable-columns which are melted, then information from each row from the original formation is not spread to n columns.
如果有n 可變柱被熔化,那么來自原始地層的每一行的信息都不會傳播到n列。
The idea of pivot() is to do just the reverse.
pivot() 的想法 只是相反。
For example,
例如,


Piping (chaining) Functions using pipe() method
使用 pipe() 方法 進行管道(鏈接)函數
Suppose you want to apply a function to a DataFrame, Series or a groupby object, to its output then apply other, other, … functions. One way would be to perform this operation in a “sandwich” like fashion:
假設您要將一個函數應用于 DataFrame , Series 或 groupby 對象,然后將其應用于輸出,然后再應用其他其他函數。 一種方法是以類似“三明治”的方式執行此操作:
Note: Also check assign() method.
注意:還要檢查 assign() 方法。
df = foo3(foo2(foo1(df, arg1=1), arg2=2), arg3=3)In the long run, this notation becomes fairly messy. What you want to do here is to use pipe(). Pipe can be though of as a function chaining. This is how you would perform the same task as before with pipe():
從長遠來看,這種表示會變得很混亂。 您要在此處使用 pipe() 。 管道可以作為 函數鏈接 。 這就是您使用 pipe() 執行與以前相同的任務的方式 :
df.pipe(foo1, arg1=1).
pipe(foo2, arg2=2).
pipe(foo3, arg3=3)This way is a cleaner way that helps keep track the order in which the functions and its corresponding arguments are applied.
這種方式是一種更簡潔的方式,有助于跟蹤應用函數及其相應參數的順序。
Rolling Windows using rolling() method
使用 rolling() 方法 滾動Windows
Use DataFrame.rolling() for rolling window calculation.
使用 DataFrame.rolling() 進行滾動窗口計算。
Other DataFrame Methods
其他 DataFrame 方法
Refer Methods section in pd.DataFrame.
請參閱 pd.DataFrame 方法” 部分 。
Refer Computational Tools User Guide.
請參閱《 計算工具 用戶指南》。
Refer the categorical listing at Pandas API.
請參閱 Pandas API上 的分類清單 。
APPLYING FUNCTIONSThe apply() method: apply on columns/rows
應用函數 apply() 方法:應用于列/行
The apply() method applies the given function along an axis (by default on columns) of the DataFrame.
的 apply() 方法應用于沿軸線(默認上列)的給定的函數 DataFrame 。
Its most useful form is:
它最有用的形式是:
df.apply(func, axis=0, args, **kwds)Here:
這里:
func: The function to apply to each column or row. Note that it can be a element-wise function (in which caseaxis=0oraxis=1doesn’t make any difference) or an aggregate function.func:應用于每個列或行的函數。 請注意,它可以是按元素的函數(在這種情況下,axis=0或axis=1沒有任何區別)或聚合函數。axis: Its value can be0(default, column) or1.0means applying function to each column, and1means applying function to each row. Note that thisaxisis similar to how axis are defined in NumpPy, as for 2D ndarray,0means column.axis:其值可以是0(默認值,列)或1。0表示將功能應用于每一列,而1表示將功能應用于每一行。 請注意,此axis類似于在NumpPy中定義軸的方式,對于2D ndarray,0表示列。args: It is atupleand represents the positional arguments to pass tofuncin addition to the array/series.args:這是一個tuple,表示除了數組/系列之外還傳遞給func的位置參數。**kwds: It represents the additional keyword arguments to pass as keywords arguments tofunc.**kwds:它表示要作為func關鍵字參數傳遞的其他關鍵字參數。
It returns a Series or a DataFrame.
它返回 Series 或 DataFrame 。
For example,
例如,

The applymap() method: apply element-wise
所述 applymap() 方法:應用逐元素
The applymap() applies the given function element-wise. So, the given func must accept and return a scalar to every element of a DataFrame.
所述 applymap() 應用于給定的函數逐元素。 因此,給定的 func 必須接受并將標量返回給 DataFrame 每個元素 。
Its general syntax is:
其一般語法為:
df.applymap(func)For example,
例如,

When you need to apply a function element-wise, you might like to check first if there is a vectorized version available. Note that a vectorized version of func often exist, which will be much faster. You could square each number element-wise using df.applymap(lambda x: x**2), but the vectorized version df**2 is better.
當需要按 元素 應用函數時 ,您可能想先檢查是否有矢量化版本。 注意的 矢量版本 func 常同時存在,這會快很多。 您可以使用 df.applymap(lambda x: x**2) 對 每個數字逐個平方 ,但是矢量化版本 df**2 更好。
WORKING WITH MISSING DATA
處理丟失的數據
Refer SciKit-Learn’s Data Cleaning section.
請參閱SciKit-Learn的“數據清理”部分。
Refer Missing Data Guide and API Reference for Missing Data Handling: dropna, fillna, replace, interpolate.
有關丟失數據的處理 , 請參閱《 丟失數據指南》 和《 API參考》: dropna , fillna , replace , interpolate 。
Also check Data Cleaning section of The tf.feature_column API on other options.
還要 在其他選項上 查看 tf.feature_column API 的 “ 數據清理” 部分 。
Also go through https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
也可以通過https://www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/
NORMALIZING DATA
歸一化數據
One way is to perform df / df.iloc[0], which is particular useful while analyzing stock price over a period of time for multiple companies.
一種方法是執行 df / df.iloc[0] ,這在分析多個公司一段時間內的股價時特別有用。
THE CONCAT() FUNCTION
THE CONCAT() 函數
The concat() function performs concatenation operations along an axis while performing optional set logic (union or intersection) of the indexes (if any) on the other axis.
所述 concat() 沿軸線功能執行級聯操作,而執行索引的可選的一組邏輯(集或交集)(如果有的話)在另一軸上。
The default axis of concatenation is axis=0, but you can choose to concatenate data frames sideways by choosing axis=1.
默認的串聯 axis=0 為 axis=0 ,但是您可以通過選擇 axis=1 來選擇橫向串聯數據幀 。
Note: Also check append() method.
注意:還要檢查 append() 方法。
For example,
例如,
df1 = pd.DataFrame(
{
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
}, index=[0, 1, 2, 3]
)df2 = pd.DataFrame(
{
'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']
}, index=[4, 5, 6, 7]
)df3 = pd.DataFrame(
{
'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']
}, index=[1, 2, 3, 4]
)frames = [df1, df2, df3]df4 = pd.concat(frames)df4
# A B C D
# 0 A0 B0 C0 D0
# 1 A1 B1 C1 D1
# 2 A2 B2 C2 D2
# 3 A3 B3 C3 D3
# 4 A4 B4 C4 D4
# 5 A5 B5 C5 D5
# 6 A6 B6 C6 D6
# 7 A7 B7 C7 D7
# 1 A8 B8 C8 D8
# 2 A9 B9 C9 D9
# 3 A10 B10 C10 D10
# 4 A11 B11 C11 D11df5 = pd.concat(frames, ignore_index=True)df5
# A B C D
# 0 A0 B0 C0 D0
# 1 A1 B1 C1 D1
# 2 A2 B2 C2 D2
# 3 A3 B3 C3 D3
# 4 A4 B4 C4 D4
# 5 A5 B5 C5 D5
# 6 A6 B6 C6 D6
# 7 A7 B7 C7 D7
# 8 A8 B8 C8 D8
# 9 A9 B9 C9 D9
# 10 A10 B10 C10 D10
# 11 A11 B11 C11 D11df5 = pd.concat(frames, keys=['s1', 's2', 's3'])df5
# A B C D
# s1 0 A0 B0 C0 D0
# 1 A1 B1 C1 D1
# 2 A2 B2 C2 D2
# 3 A3 B3 C3 D3
# s2 4 A4 B4 C4 D4
# 5 A5 B5 C5 D5
# 6 A6 B6 C6 D6
# 7 A7 B7 C7 D7
# s3 1 A8 B8 C8 D8
# 2 A9 B9 C9 D9
# 3 A10 B10 C10 D10
# 4 A11 B11 C11 D11df5.index
# MultiIndex(levels=[['s1', 's2', 's3'], [0, 1, 2, 3, 4, 5, 6, 7]],
# labels=[[0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], [0, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4]])Like its sibling function on ndarrays, numpy.concatenate(), the pandas.concat() takes a list or dict of homogeneously-typed objects and concatenates them with some configurable handling of “what to do with other axes”.
像其在ndarrays上的同級函數numpy.concatenate()一樣, numpy.concatenate() pandas.concat()同類對象的列表或字典,并通過“可與其他軸做什么”的某種可配置處理將它們連接起來。
MERGING AND JOINING USING MERGE() AND JOIN() FUNCTIONS
使用 MERGE() 和 JOIN() 函數 合并和加入
Refer Mergem Join, and Concatenate official guide.
請參閱 Mergem Join和Concatenate 官方指南。
The function merge() merges DataFrame object by performing a database-style join operation by columns or indexes.
函數 merge() 通過按列或索引執行數據庫樣式的 DataFrame 操作來 合并 DataFrame 對象。
The function join() joins columns with other DataFrame either on index or on a key column.
函數 join() 在索引或鍵列 DataFrame 列與其他 DataFrame 連接起來 。
BINARY DUMMY VARIABLES FOR CATEGORICAL VARIABLES USING GET_DUMMIES() FUNCTION
使用 GET_DUMMIES() 函數的化學 變量的 GET_DUMMIES() 變量
To convert a categorical variable into a “dummy” DataFrame can be done using get_dummies():
可以使用 get_dummies() 將類別變量轉換為“虛擬” DataFrame :
df = pd.DataFrame({'char': list('bbacab'), 'data1': range(6)})df
# char data1
# 0 b 0
# 1 b 1
# 2 a 2
# 3 c 3
# 4 a 4
# 5 b 5dummies = pd.get_dummies(df['char'], prefix='key')
dummies
# key_a key_b key_c
# 0 0 1 0
# 1 0 1 0
# 2 1 0 0
# 3 0 0 1
# 4 1 0 0
# 5 0 1 0PLOTTING DATAFRAME USING PLOT() FUNCTION
使用PLOT()函數繪制數據DATAFRAME
The plot() function makes plots of DataFrame using matplotlib/pylab.
該 plot() 函數使得地塊 DataFrame 使用matplotlib / pylab。
面板(3D數據結構) (Panel (3D data structure))
Panel is a container for 3D data. The term panel data is derived from econometrics and is partially responsible for the name: pan(el)-da(ta)-s.
面板是3D數據的容器。 面板數據一詞源自計量經濟學,部分負責名稱: pan(el)-da(ta)-s 。
The 3D structure of a Panel is much less common for many types of data analysis, than the 1D of the Series or the 2D of the DataFrame. Oftentimes, one can simply use a Multi-index DataFrame for easily working with higher dimensional data. Refer Deprecate Panel.
與Series的1D或DataFrame的2D相比, Panel的3D結構在許多類型的數據分析中要少DataFrame 。 通常,人們可以簡單地使用Multi-index DataFrame來輕松處理高維數據。 請參閱“ 不贊成使用面板” 。
Here are some related interesting stories that you might find helpful:
以下是一些相關的有趣故事,您可能會覺得有幫助:
Fluent NumPy
流利的數字
Distributed Data Processing with Apache Spark
使用Apache Spark進行分布式數據處理
Apache Cassandra — Distributed Row-Partitioned Database for Structured and Semi-Structured Data
Apache Cassandra —用于結構化和半結構化數據的分布式行分區數據庫
The Why and How of MapReduce
MapReduce的原因和方式
翻譯自: https://medium.com/analytics-vidhya/fluent-pandas-22473fa3c30d
熊貓分發
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/387980.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/387980.shtml 英文地址,請注明出處:http://en.pswp.cn/news/387980.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

redis tomcat session

Fiddler抓包-只抓APP的請求

技術分享 | 基于EOS的Dapp開發

DOCKER windows 安裝Tomcat內容

python記錄日志_5分鐘內解釋日志記錄—使用Python演練

理解 Linux 中 `ls` 的輸出

鎖表的進程和語句,并殺掉

p值 t值 統計_非統計師的P值
)
獲取對象屬性(key)

github免費空間玩法

用php生成HTML文件的類

在Markdown中輸入數學公式

如何不部署Keras / TensorFlow模型
![[BZOJ3626] [LNOI2014] LCA 離線 樹鏈剖分](http://pic.xiahunao.cn/[BZOJ3626] [LNOI2014] LCA 離線 樹鏈剖分)
[BZOJ3626] [LNOI2014] LCA 離線 樹鏈剖分

Linux查看系統各類信息

biopython中文指南_Biopython新手指南-第1部分

整合后臺服務和驅動代碼注入

Java作業09-異常

為數據計算提供強力引擎,阿里云文件存儲HDFS v1.0公測發布
)