無監督學習 k-means
有關深層學習的FAU講義 (FAU LECTURE NOTES ON DEEP LEARNING)
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. Try it yourself! If you spot mistakes, please let us know!
這些是FAU YouTube講座“ 深度學習 ”的 講義 。 這是演講視頻和匹配幻燈片的完整記錄。 我們希望您喜歡這些視頻。 當然,此成績單是使用深度學習技術自動創建的,并且僅進行了較小的手動修改。 自己嘗試! 如果發現錯誤,請告訴我們!
導航 (Navigation)
Previous Lecture / Watch this Video / Top Level / Next Lecture
上一個講座 / 觀看此視頻 / 頂級 / 下一個講座

Welcome back to deep learning! Today we want to talk about a couple of the more advanced GAN concepts, in particular, the conditional GANs and Cycle GANs.
歡迎回到深度學習! 今天,我們要討論幾個更高級的GAN概念,尤其是條件GAN和Cycle GAN。

So, let’s have a look at what I have here on my slides. It’s part four of our unsupervised deep learning lecture. First, we start with the conditional GANs. So, one problem that we had so far is that the generators create a fake generic image. Unfortunately, it’s not specific for a certain condition or characteristic. So let’s say if you have text to image generation then, of course, the image should depend on the text. So, you need to be able to model the dependency somehow. If you want to generate zeros then you don’t want to generate ones. So, you need to put in some condition whether you want to generate the digit 0, 1, 2, 3, and so on. This can be done by encoding conditioning which is introduced in [15].
因此,讓我們看一下幻燈片上的內容。 這是我們無監督深度學習講座的第四部分。 首先,我們從條件GAN開始。 因此,到目前為止,我們遇到的一個問題是生成器創建了偽造的通用映像。 不幸的是,它并非特定于特定條件或特征。 因此,假設您有文本生成圖像,那么圖像當然應該取決于文本。 因此,您需要能夠以某種方式對依賴關系進行建模。 如果要生成零,則不要生成零。 因此,無論是否要生成數字0、1、2、3等,都需要設置一些條件。 這可以通過在[15]中介紹的編碼條件來完成。
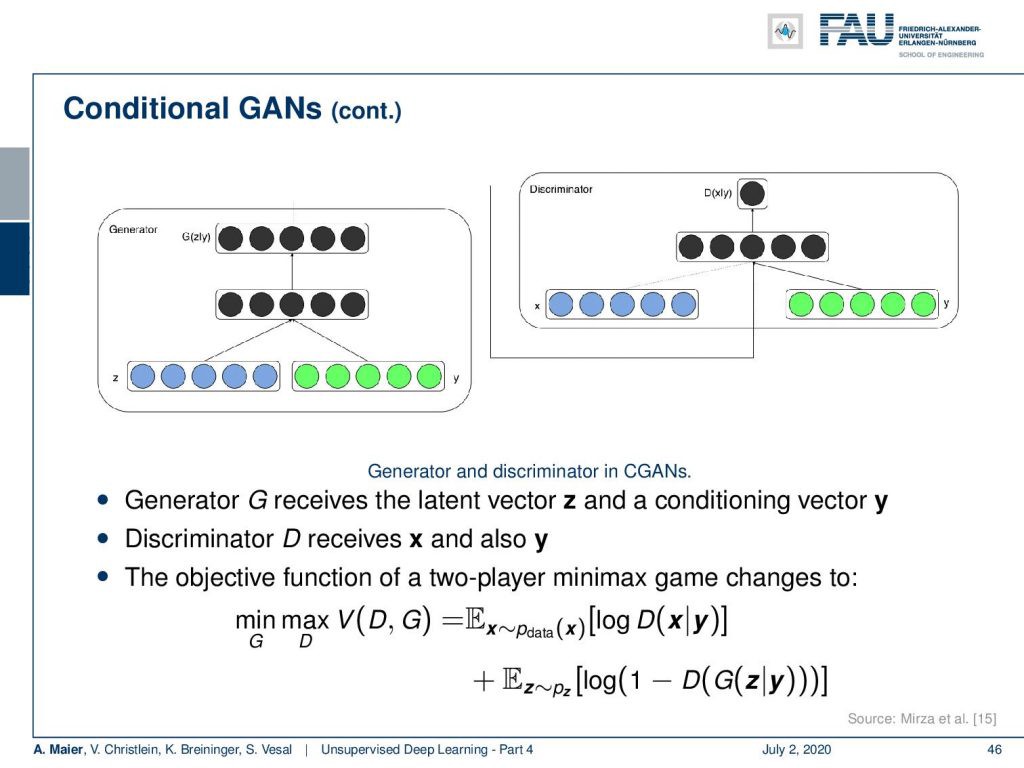
The idea here is now that you essentially split up your latent vector into the set that has essentially the observation. Then, you also have the condition which is encoded here in the conditioning vector y. You concatenate the two and use them in order to generate something. Also, the discriminator then gets the generated image, but it also gets access to the conditional vector y. So, it knows what it’s supposed to see and the specific generated output of the generator. So, both of them receive the conditioning and this then essentially again results in a two-player minimax game that can be described again as a loss that is dependent on the discriminator. The extension here is that you additionally have the conditioning with y in the loss.
現在的想法是,您實際上將潛伏向量分成了本質上具有觀測值的集合。 然后,您還具有在條件向量y中編碼的條件。 您將兩者串聯起來并使用它們來生成某些東西。 同樣,鑒別器然后獲得生成的圖像,但它也可以訪問條件向量y 。 因此,它知道應該看到什么以及生成器的特定生成的輸出。 因此,他們兩個都接受了條件調整,然后這基本上又導致了兩人minimax游戲,該游戲可以再次描述為取決于判別器的損失。 這里的擴展是,您另外具有損耗為y的條件。

So how does this thing work? You add a conditional feature like smiling, gender, age, or other properties of the image. Then, the generator and the discriminator learn to operate in those modes. This then leads to the property that you’re able to generate a face of a certain attribute. The discriminator learns that this is the face given that specific attribute. So, here, you see different examples of generated faces. In the first row are just random samples. The second row is conditioned into the property of old age. The third row is given the condition old age plus smiling and here you see that the conditioning vector is still able to produce similar images, but you can actually add those conditions on top.
那么這東西如何工作? 您添加條件功能,例如微笑,性別,年齡或圖像的其他屬性。 然后,生成器和鑒別器學習以那些模式進行操作。 然后,這導致該屬性,您可以生成特定屬性的外觀。 鑒別者得知給定特定屬性,這就是面Kong。 因此,在這里,您會看到生成面Kong的不同示例。 第一行只是隨機樣本。 第二行以老年屬性為條件。 第三行給出了老年條件和微笑條件,在這里您可以看到條件向量仍然能夠生成相似的圖像,但是您實際上可以將這些條件添加到頂部。

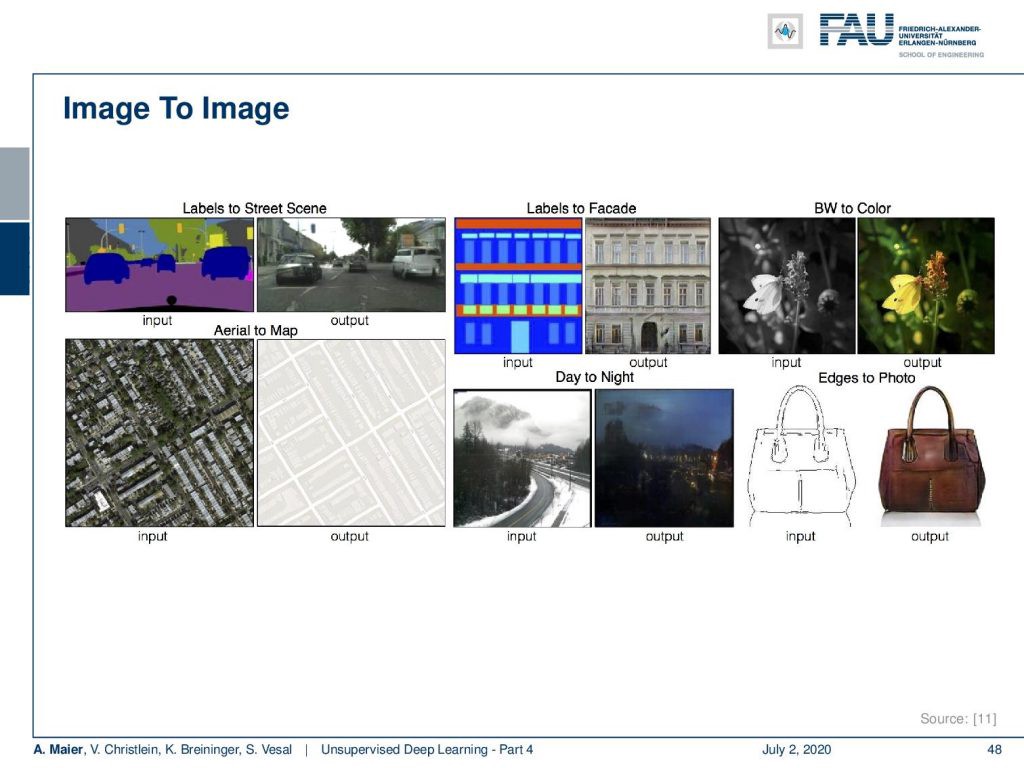
So, this allows then to create really very nice things like the image to image translation. Below, you have several examples of inputs and outputs. You can essentially then create labels to street scenes, you can generate aerial images to maps, you can generate labels to facades, or black & white to color, day to night, and edges to photo.
因此,這可以創建非常好看的東西,例如圖像到圖像的翻譯。 下面有幾個輸入和輸出示例。 然后,您基本上可以為街道場景創建標簽,可以為地圖生成航拍圖像,可以為立面生成標簽,或者為顏色生成黑白,白天到黑夜,以及照片邊緣。
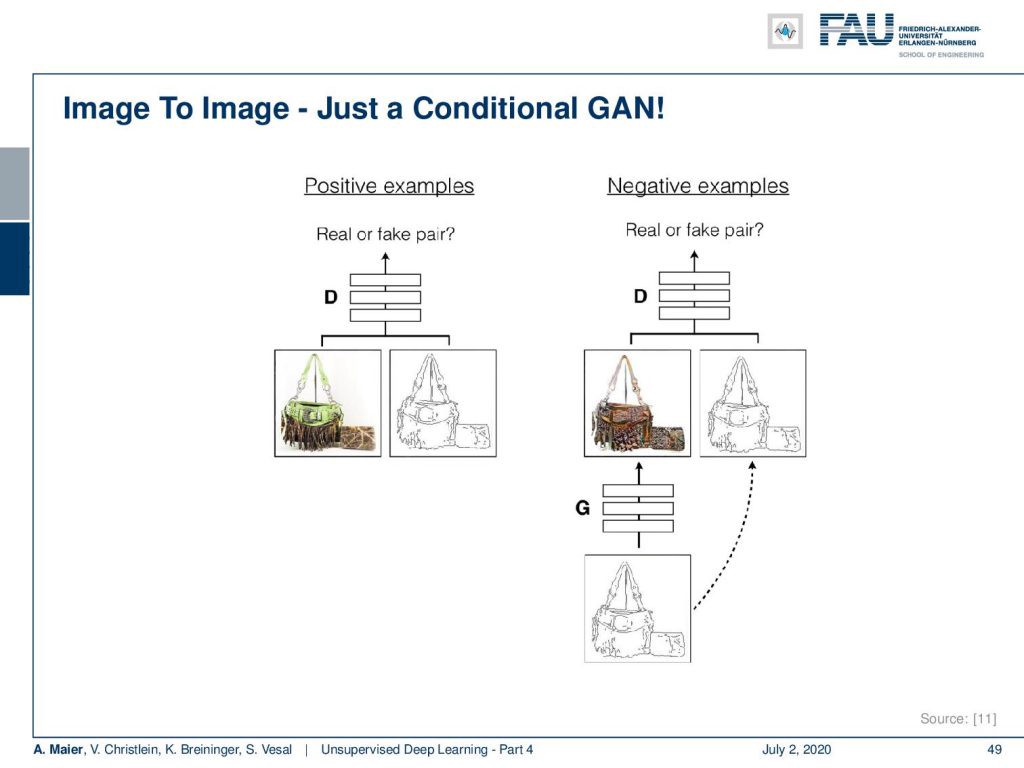
The idea here is that we use the label image again as a conditioning vector. This leads us to the observations that this is domain translation. It is simply a conditional GAN. The positive examples are given to the discriminator. The example below shows a handbag and its edges. The negative examples are then constructed by giving the edges of the handbag to the generator to create a handbag that fools the discriminator.
這里的想法是我們再次將標簽圖像用作條件向量。 這導致我們發現這是領域翻譯。 它只是一個條件GAN。 判別器給出了肯定的例子。 下例顯示了手提包及其邊緣。 然后通過將手提包的邊緣提供給生成器以創建使識別符蒙昧的手提包來構造否定示例。
You can see that we are able to generate really complex images just by using conditional GANs. Now, a key problem here is, of course, that you need the two images to be aligned. So, your conditioning image like the edge image here has to exactly match the respective handbag image. If they don’t, you wouldn’t be able to train this. So, for domain translation using conditional GANs, you need exact matches. In many cases, you don’t have access to exact matches. So, let’s say you have a scene that shows zebras. You will probably not find a paired data set that shows exactly the same scene, but with horses. So, you cannot just use it with a conditional GAN.
您可以看到,僅通過使用條件GAN,我們就能生成真正復雜的圖像。 現在,這里的一個關鍵問題當然是您需要將兩個圖像對齊。 因此,您的調節圖像(如此處的邊緣圖像)必須與相應的手提包圖像完全匹配。 如果他們不這樣做,您將無法進行培訓。 因此,對于使用條件GAN的域名翻譯,您需要完全匹配。 在許多情況下,您無權訪問完全匹配項。 因此,假設您有一個顯示斑馬的場景。 您可能不會找到顯示完全相同的場景但有馬的成對數據集。 因此,您不能僅將其與條件GAN一起使用。

The key ingredient, here, is the so-called cycle consistency loss. So, you couple GANs with trainable inverse mappings. The key idea here is that you have one conditional GAN that inputs x as the conditioning image and generates then some new output. If you take this new output and use it in the conditioning variable of F, it should produce x again. So, you use the conditioning variables to form a loop and the key component here is that G and F should be essentially inverses of each other.
此處的關鍵因素是所謂的循環一致性損失。 因此,您將GAN與可訓練的逆映射結合在一起。 這里的關鍵思想是您有一個條件GAN,它輸入x作為條件圖像,然后生成一些新的輸出。 如果采用此新輸出并將其用于F的條件變量中,它將再次產生x 。 因此,您使用條件變量來形成循環,并且這里的關鍵部分是G和F本質上應該是彼此相反的。
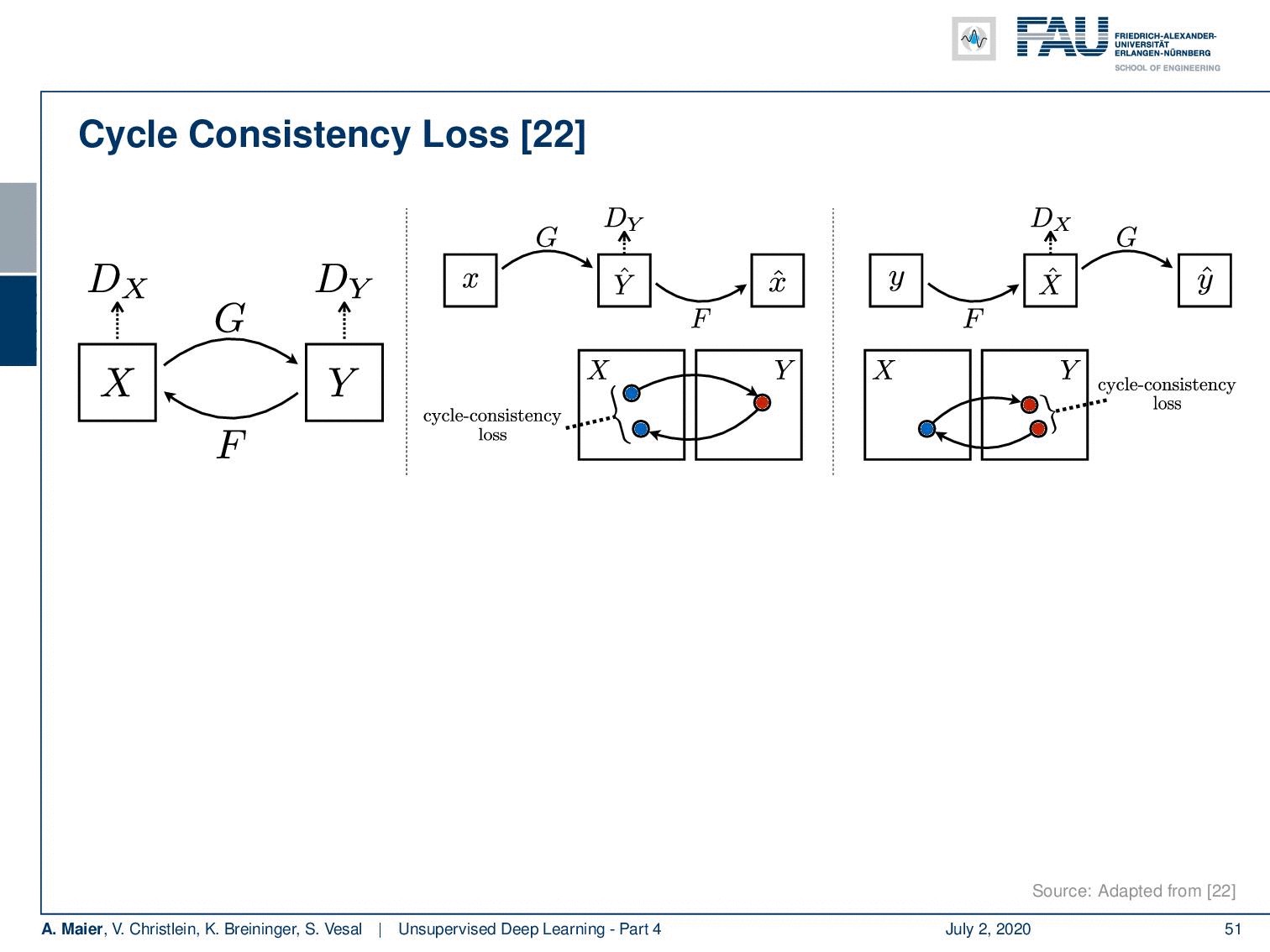
So, if you take F(G(x)), you should end up with x again. Of course, also if you take G(F(y)) then you should end up with y again. This then gives rise to the following concepts: So, you take two generators and two discriminators, one GAN G is generating y from x. One GAN F is generating x from y. You still need two discriminators D? and the discriminator D?. The Cycle GAN loss further has the consistency conditions as additions to the loss. Of course, you have the typical discriminator losses the original GAN losses for D? and D?. They are, of course, coupled respectively with G and F. On top, you put this cycle consistency loss. The cycle consistency loss is a coupled loss that at the same time translates x to yand y to x again and makes sure that the zebra that is generated in y is still not recognized as fake by the discriminator. At the same time, you have the inverse cycle consistency which is then translating y into x using F and then x into y using G again while fooling the discriminator regarding x. So, you need the two discriminators. This then gives rise to the cyclic consistency loss that we have noted down for you here. You can, for example, use L1 norms and the expected values of those L1 norms to form specific identities. So, the total loss is then given as the GAN losses that we’ve already discussed earlier plus λ the cycle consistency loss.
因此,如果取F(G( x )),則應該再次以x結尾。 當然,如果您采用G(F( y )),那么您應該再次以y結尾。 這樣就產生了以下概念:因此,您有兩個生成器和兩個鑒別器,一個GAN G從x生成y 。 一個GAN F正在從y生成x 。 您仍然需要兩個鑒別符D?和鑒別符D?。 Cycle GAN損耗還具有一致性條件作為損耗的補充。 當然,對于D?和D?,典型的鑒別器損耗是原始GAN損耗。 當然,它們分別與G和F耦合。最重要的是,您將此循環一致性損失。 循環一致性損失是一個耦合損失,它同時將x轉換為y ,又將y轉換為x ,并確保鑒別器仍不會將y中生成的斑馬識別為偽造的。 同時,您具有逆循環一致性,然后使用F將y轉換為x ,然后使用G再次將x轉換為y ,同時愚弄關于x的鑒別符。 因此,您需要兩個鑒別符。 這會導致周期性一致性損失,我們在這里已為您記錄下來。 例如,您可以使用L1規范和這些L1規范的期望值來形成特定的標識。 因此,總損耗就是前面已經討論過的GAN損耗加上λ周期一致性損耗。

So, this concept is fairly easy to grasp and I can tell you this has been widely applied. So, there are many many examples. You can translate from Monet to Photos, from zebras to horses, from summer to winter, and the respective inverse operations. If you couple this with more GANs and more cycle consistency losses, then you’re even able to take one photograph and translate it to Monet, Van Gogh, and other artists and have them represent a specific style.
因此,這個概念相當容易掌握,我可以告訴您這已被廣泛應用。 因此,有很多例子。 您可以從“莫奈”到“照片”,從斑馬到馬,從夏天到冬天,以及相應的逆運算。 如果您將其與更多的GAN和更多的循環一致性損失結合使用,那么您甚至可以拍攝一張照片并將其翻譯成Monet,Van Gogh和其他藝術家,并使它們代表特定的風格。

This is, of course, also interesting for autonomous driving where you then can for example input a scene and then generate different segmentation masks. So, you can also use it for image segmentation in this task. Here, we have an ablation study for the Cycle GAN where we show the Cycle alone, the GAN alone, the GAN plus forward loss, the GAN plus backward loss, and the complete Cycle GAN loss. You can see that with the Cycle GAN loss, you get much much better back and forth translations if you compare this to your respective ground truth.
當然,這對于自動駕駛也很有趣,在自動駕駛中您可以例如輸入一個場景然后生成不同的分割蒙版。 因此,您也可以在此任務中將其用于圖像分割。 在這里,我們對Cycle GAN進行了消融研究,其中顯示了單獨的Cycle,單獨的GAN,GAN加上正向損耗,GAN加上向后損耗以及完整的GAN損耗。 您會發現,如果將Cycle GAN損失與自己的事實相比較,來回翻譯會好得多。

Okay, there are a couple of more things to say about GANs and these are the advanced GAN concepts that we’ll talk about next time in deep learning. So, I hope you enjoyed this video and looking forward to seeing you in the next one. Good-bye!
好的,關于GAN還有很多要說的東西,這些是GAN的高級概念,我們下次將在深度學習中討論。 因此,我希望您喜歡這個視頻,并希望在下一個視頻中見到您。 再見!

If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced. If you are interested in generating transcripts from video lectures try AutoBlog.
如果你喜歡這篇文章,你可以找到這里更多的文章 ,更多的教育材料,機器學習在這里 ,或看看我們的深入 學習 講座 。 如果您希望將來了解更多文章,視頻和研究信息,也歡迎關注YouTube , Twitter , Facebook或LinkedIn 。 本文是根據知識共享4.0署名許可發布的 ,如果引用,可以重新打印和修改。 如果您對從視頻講座中生成成績單感興趣,請嘗試使用AutoBlog 。
鏈接 (Links)
Link — Variational Autoencoders: Link — NIPS 2016 GAN Tutorial of GoodfellowLink — How to train a GAN? Tips and tricks to make GANs work (careful, noteverything is true anymore!) Link - Ever wondered about how to name your GAN?
鏈接 —可變自動編碼器: 鏈接 — Goodfellow的NIPS 2016 GAN教程鏈接 —如何訓練GAN? 使GAN正常工作的提示和技巧(小心,什么都沒了!) 鏈接 -是否想知道如何命名GAN?
翻譯自: https://towardsdatascience.com/unsupervised-learning-part-4-eeb4d3ab601
無監督學習 k-means
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/387895.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/387895.shtml 英文地址,請注明出處:http://en.pswp.cn/news/387895.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

vCenter 升級錯誤 VCSServiceManager 1603

day28 socketserver


深度學習算法原理_用于對象檢測的深度學習算法的基本原理

【python】numpy庫linspace相同間隔采樣 詳解
)
Spring整合JMS——基于ActiveMQ實現(一)

軟件本地化 pdf_軟件本地化與標準翻譯

CentOS7+CDH5.14.0安裝全流程記錄,圖文詳解全程實測-8CDH5安裝和集群配置

node.js安裝部署測試

數據庫不停機導數據方案_如何計算數據停機成本
)
luogu4159 迷路 (矩陣加速)

社群系統ThinkSNS+ V2.2-V2.3升級教程
)
BZOJ4881 線段游戲(二分圖+樹狀數組/動態規劃+線段樹)

activemq部署安裝

python初學者_面向初學者的20種重要的Python技巧


什么是 DDoS 攻擊?

nginx 并發過十萬

