svm參數說明----------------------
如果你要輸出類的概率,一定要有-b參數
svm-train training_set_file model_file
svm-predict test_file model_fileoutput_file
自動腳本:Python?easy.py train_data test_data
自動選擇最優參數,自動進行歸一化。
對訓練集合和測試結合,使用同一個歸一化參數。
-c:參數
-g:?
-v:交叉驗證數
-s svm_type : set type of SVM (default?0)
?
?
?
?
?
-t kernel_type : set type of kernelfunction (default 2)
?
?
?
?
-d degree : set degree in kernel function(default 3)
?
-g gamma : set gamma in kernel function(default 1/num_features)
-r coef0 : set coef0 in kernel function(default 0)
-c cost : set the parameter C of C-SVC,epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC,one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in lossfunction of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB(default 100)
-e epsilon : set tolerance of terminationcriterion (default 0.001)
-h shrinking: whether to use the shrinkingheuristics, 0 or 1 (default 1)
-b probability_estimates: whether to traina SVC or SVR model for probability estimates, 0 or 1 (default 0)(如果需要估計分到每個類的概率,則需要設置這個)
-wi weight: set the parameter C of class ito weight*C, for C-SVC (default 1)
?
?
?
libsvm使用誤區----------------------
(1)?
(2)?
a)?
b)?
(3)?
a)?
(4)?
(5)?
?
libsvm在訓練model的時候,有如下參數要設置,當然有默認的參數,但是在具體應用方面效果會大大折扣。?
Options:可用的選項即表示的涵義如下
-s svm類型:SVM設置類型(默認0)
0 -- C-SVC
1 --v-SVC
2?
3 -- e -SVR
4 -- v-SVR?
?
-t?
0?
1?
2?
3?
?
?
-d degree:核函數中的degree設置(針對多項式核函數)(默認3)
-g r(gama):核函數中的gamma函數設置(針對多項式/rbf/sigmoid核函數)(默認1/ k)
-r coef0:核函數中的coef0設置(針對多項式/sigmoid核函數)((默認0)
-c cost:設置C-SVC,e -SVR和v-SVR的參數(損失函數)(默認1)
-n nu:設置v-SVC,一類SVM和v- SVR的參數(默認0.5)
-p p:設置e -SVR?
-m cachesize:設置cache內存大小,以MB為單位(默認40)
-e eps:設置允許的終止判據(默認0.001)
-h shrinking:是否使用啟發式,0或1(默認1)
-wi weight:設置第幾類的參數C為weight*C(C-SVC中的C)(默認1)
-v n: n-fold交互檢驗模式,n為fold的個數,必須大于等于2
其中-g選項中的k是指輸入數據中的屬性數。option -v?
?
當構建完成model后,還要為上述參數選擇合適的值,方法主要有Gridsearch,其他的感覺不常用,Gridsearch說白了就是窮舉。
?
網格參數尋優函數(分類問題):SVMcgForClass
[bestCVaccuracy,bestc,bestg]=
SVMcgForClass(train_label,train,
cmin,cmax,gmin,gmax,v,cstep,gstep,accstep)
輸入:
train_label:訓練集的標簽,格式要求與svmtrain相同。
train:訓練集,格式要求與svmtrain相同。
cmin,cmax:懲罰參數c的變化范圍,即在[2^cmin,2^cmax]范圍內尋找最佳的參數c,默認值為cmin=-8,cmax=8,即默認懲罰參數c的范圍是[2^(-8),2^8]。
gmin,gmax:RBF核參數g的變化范圍,即在[2^gmin,2^gmax]范圍內尋找最佳的RBF核參數g,默認值為gmin=-8,gmax=8,即默認RBF核參數g的范圍是[2^(-8),2^8]。
v:進行Cross Validation過程中的參數,即對訓練集進行v-fold Cross Validation,默認為3,即默認進行3折CV過程。
cstep,gstep:進行參數尋優是c和g的步進大小,即c的取值為2^cmin,2^(cmin+cstep),…,2^cmax,,g的取值為2^gmin,2^(gmin+gstep),…,2^gmax,默認取值為cstep=1,gstep=1。
accstep:最后參數選擇結果圖中準確率離散化顯示的步進間隔大小([0,100]之間的一個數),默認為4.5。
輸出:
bestCVaccuracy:最終CV意義下的最佳分類準確率。
bestc:最佳的參數c。
bestg:最佳的參數g。
?
網格參數尋優函數(回歸問題):SVMcgForRegress
[bestCVmse,bestc,bestg]=
SVMcgForRegress(train_label,train,
cmin,cmax,gmin,gmax,v,cstep,gstep,msestep)
其輸入輸出與SVMcgForClass類似,這里不再贅述。
而當你訓練完了model,在用它做classification或regression之前,應該知道model中的內容,以及其含義。
?
用來訓練的是libsvm自帶的heart數據
?
model =
?
?
?
?
?
?
?
?
?
?
?
?
model.Parameters參數意義從上到下依次為:
-s svm類型:SVM設置類型(默認0)
-t?
-d degree:核函數中的degree設置(針對多項式核函數)(默認3)
-g r(gama):核函數中的gamma函數設置(針對多項式/rbf/sigmoid核函數) (默認類別數目的倒數)
-r coef0:核函數中的coef0設置(針對多項式/sigmoid核函數)((默認0)
?
SVM?
1.?
2.?
3.?
4.?
5.?
?
關于svm的C以及核函數參數設置----------------------
參考自:對支持向量機幾種常用核函數和參數選擇的比較研究
?
C一般可以選擇為:10^t , t=- 4..4就是0.0001?
?
?
在LIBSVM中-t用來指定核函數類型(默認值是2)。
0)線性核函數
(無其他參數)
1)多項式核函數
(重點是階數的選擇,即d,一般選擇1-11:1 3 5 7 9 11,也可以選擇2,4,6…)
2)RBF核函數
(徑向基RBF內核,exp{-|xi-xj|^2/均方差},其中均方差反映了數據波動的大小。
參數通常可選擇下面幾個數的倒數:0.1 0.2 0.4 0.6 0.8 1.6 3.2 6.4 12.8,默認的是類別數的倒數,即1/k,2分類的話就是0.5)
3)sigmoid核函數?
兩個參數g以及r:g一般可選1 2 3 4,r選0.2 0.4 0.60.8 1
4)自定義核函數
?
常用的四種核函數對應的公式如下:
?
與核函數相對應的libsvm參數:
1)對于線性核函數,沒有專門需要設置的參數
2)對于多項式核函數,有三個參數。-d用來設置多項式核函數的最高此項次數,也就是公式中的d,默認值是3。-g用來設置核函數中的gamma參數設置,也就是公式中的第一個r(gamma),默認值是1/k(k是類別數)。-r用來設置核函數中的coef0,也就是公式中的第二個r,默認值是0。
3)對于RBF核函數,有一個參數。-g用來設置核函數中的gamma參數設置,也就是公式中的第一個r(gamma),默認值是1/k(k是類別數)。
4)對于sigmoid核函數,有兩個參數。-g用來設置核函數中的gamma參數設置,也就是公式中的第一個r(gamma),默認值是1/k(k是類別數)。-r用來設置核函數中的coef0,也就是公式中的第二個r,默認值是0。
關于cost和gamma
SVM模型有兩個非常重要的參數C與gamma。其中 C是懲罰系數,即對誤差的寬容度。c越高,說明越不能容忍出現誤差,容易過擬合。C越小,容易欠擬合。C過大或過小,泛化能力變差
? ? ? ? ? ?gamma是選擇RBF函數作為kernel后,該函數自帶的一個參數。隱含地決定了數據映射到新的特征空間后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的個數影響訓練與預測的速度。
? ? ? ? ??此外大家注意RBF公式里面的sigma和gamma的關系如下:
? ??
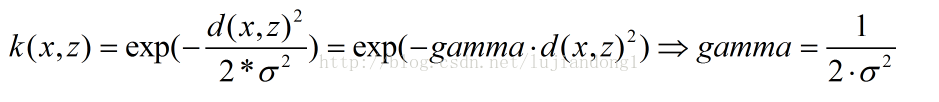
? ? ? ? 這里面大家需要注意的就是gamma的物理意義,大家提到很多的RBF的幅寬,它會影響每個支持向量對應的高斯的作用范圍,從而影響泛化性能。我的理解:如果gamma設的太大,
Grid Search
Grid Search是用在Libsvm中的參數搜索方法。很容易理解:就是在C,gamma組成的二維參數矩陣中,依次實驗每一對參數的效果。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
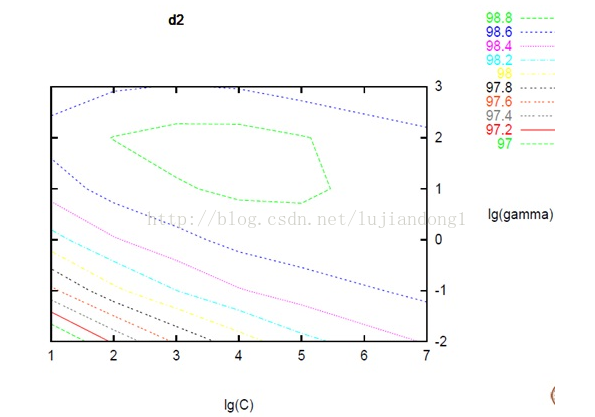
使用grid Search雖然比較簡單,而且看起來很na?ve。但是他確實有兩個優點:
- 可以得到全局最優
- (C,gamma)相互獨立,便于并行化進行
SVM有如下主要幾個特點:(1)非線性映射是SVM方法的理論基礎,SVM利用內積核函數代替向高維空間的非線性映射;
(2)對特征空間劃分的最優超平面是SVM的目標,最大化分類邊際的思想是SVM方法的核心;
(3)支持向量是SVM的訓練結果,在SVM分類決策中起決定作用的是支持向量;
(4)SVM 是一種有堅實理論基礎的新穎的小樣本學習方法。
它基本上不涉及概率測度及大數定律等,因此不同于現有的統計方法。
從本質上看,它避開了從歸納到演繹的傳統過程,實現了高效的從訓練樣本到預報樣本的“轉導推理”,
大大簡化了通常的分類和回歸等問題;(5)SVM 的最終決策函數只由少數的支持向量所確定,計算的復雜性取決于支持向量的數目,
而不是樣本空間的維數,這在某種意義上避免了“維數災難”。
(6)少數支持向量決定了最終結果,這不但可以幫助我們抓住關鍵樣本、“剔除”大量冗余樣本,
而且注定了該方法不但算法簡單,而且具有較好的“魯棒”性。
這種“魯棒”性主要體現在:
①增、刪非支持向量樣本對模型沒有影響;②支持向量樣本集具有一定的魯棒性;
③有些成功的應用中,SVM 方法對核的選取不敏感
兩個不足:
(1) SVM算法對大規模訓練樣本難以實施 由于SVM是借助二次規劃來求解支持向量,
而求解二次規劃將涉及m階矩陣的計算(m為樣本的個數),當m數目很大時該矩陣的存儲和計算
將耗費大量的機器內存和運算時間。
針對以上問題的主要改進有
J.Platt的SMO算法、
T.Joachims的SVM、
C.J.C.Burges等的PCGC、
張學工的CSVM
以及O.L.Mangasarian等的SOR算法
(2) 用SVM解決多分類問題存在困難
經典的支持向量機算法只給出了二類分類的算法,
而在數據挖掘的實際應用中,一般要解決多類的分類問題。
可以通過多個二類支持向量機的組合來解決。
主要有
一對多組合模式、一對一組合模式和SVM決策樹;
再就是通過構造多個分類器的組合來解決。
主要原理是克服SVM固有的缺點,結合其他算法的優勢,解決多類問題的分類精度。
如:
與粗集理論結合,形成一種優勢互補的多類問題的組合分類器。
)


)
![[EmguCV|C#]使用CvInvoke自己繪製色彩直方圖-直方圖(Hitsogram)系列(4)](http://pic.xiahunao.cn/[EmguCV|C#]使用CvInvoke自己繪製色彩直方圖-直方圖(Hitsogram)系列(4))

)




)







