插入排序
算法分析
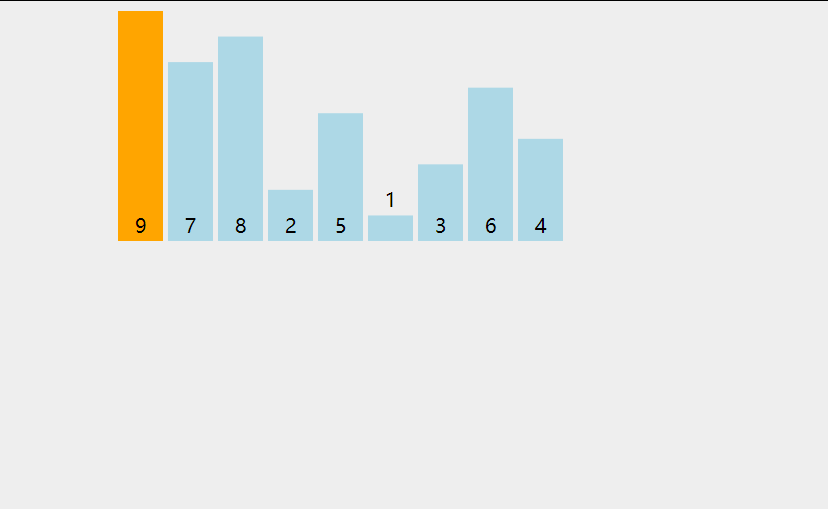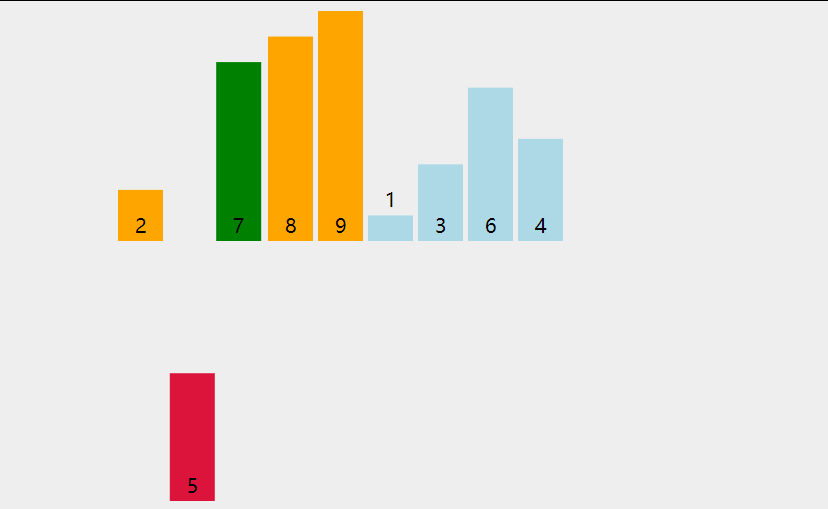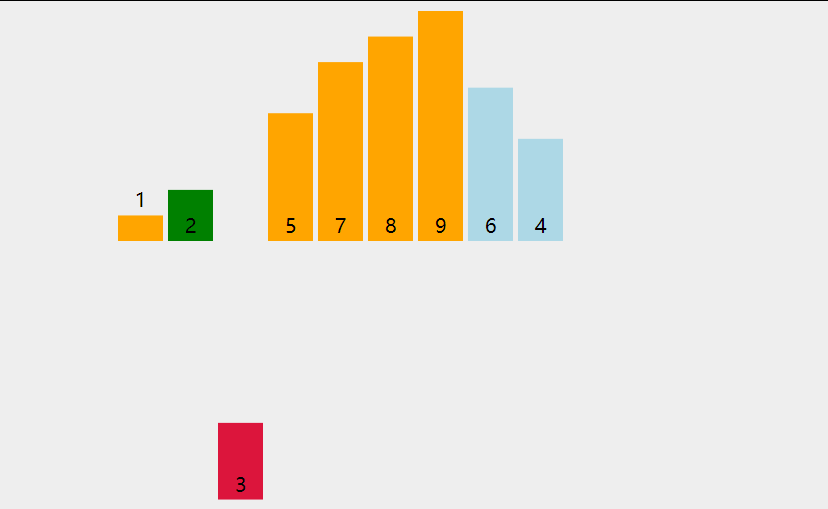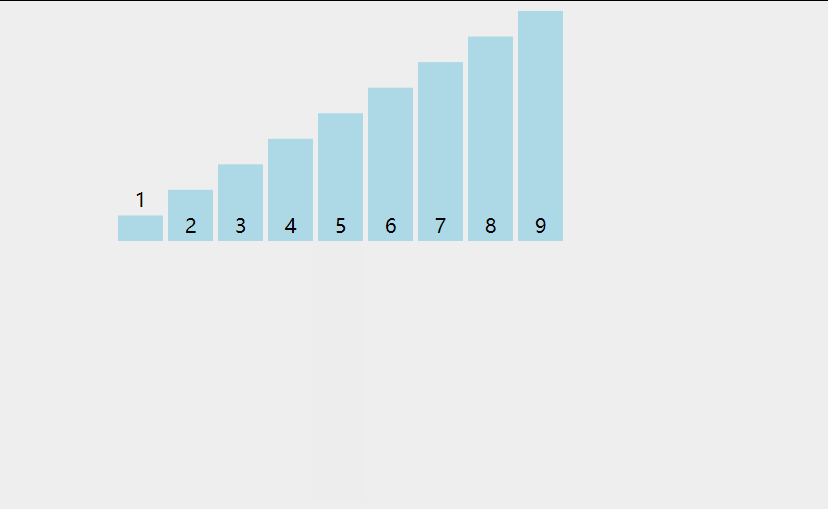
兩次循環, 大循環對隊列中的每一個元素拿出來作為小循環的裁定對象
小循環對堆當前循環對象在有序隊列中尋找插入的位置
性能參數
空間復雜度 O(1)
時間復雜度 O(n^2)
詳細代碼解讀
import randomdef func(l):# 外層循環: 對應遍歷所有的無序數據for i in range(1, len(l)):# 備份 取出數據temp = l[i]# 記錄取出來的下標值pos = i# 內層循環: 對應從后往前掃描所有有序數據"""i - 1 > 從最后一個有序數據開始, 即無序數據前一位-1 > 掃描到下標 0 為止, 要包括第一個, 因此設置 -1 往后推一位-1 > 從后往前掃描"""for j in range(i - 1, -1, -1):# 若有序數據 大于 取出數據if l[j] > temp:# 有序數據后移l[j + 1] = l[j]# 更新數據的插入位置pos = j # 對應所有有序數據比取出數據大的情況# 若有序數據 小于/等于 取出數據else:pos = j + 1break# 在指定位置插入數據l[pos] = tempif __name__ == '__main__':l = list(range(1, 13))random.shuffle(l)func(l)print(l)
簡單實例
import randomdef foo(l):for i in range(1, len(l)):temp = l[i]pos = ifor j in range(i - 1, -1, -1):if temp < l[j]:l[j + 1] = l[j]pos = jelse:pos = j + 1breakl[pos] = tempreturn lif __name__ == '__main__':l = list(range(13))random.shuffle(l)print(l) # [12, 0, 4, 5, 6, 2, 11, 10, 8, 7, 3, 1, 9]print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
冒泡排序
算法分析
兩兩比較, 每次比較出一個未排序隊列的最大值,讓只在隊列右側排列
兩次循環, 大循環每次輸出一個當前最大值.?
小循環進行具體的數值比對
性能參數
空間復雜度 O(1)
時間復雜度 O(n^2)
詳細代碼
""" 入學后, 第一次上體育課, 體育老師要求大家排隊, 按照身高從低到高排隊 獲取全班 10 名同學的身高 """""" 外層循環大循環控制總循環次數 內層循環小循環控制如歌得出這個最大值計算大小, 然后彼此交換 """import random""" 基礎版 """def func(l):# 外層循環: 走訪數據的次數for i in range(len(l) - 1):# 內層循環: 每次走訪數據時, 相鄰對比次數for j in range(len(l) - i - 1):# 要求從低到高# 如次序有誤就交換if l[j] > l[j + 1]:l[j], l[j + 1] = l[j + 1], l[j]# 遍歷次數print("走訪次數:", i + 1)""" 升級版 """def foo(l):# 外層循環: 走訪數據的次數for i in range(len(l) - 1):# 設置是否交換標志位flag = False# 內層循環: 每次走訪數據時, 相鄰對比次數for j in range(len(l) - i - 1):# 要求從低到高# 如次序有誤就交換if l[j] > l[j + 1]:l[j], l[j + 1] = l[j + 1], l[j]# 發生了數據交換flag = True# 如果未發生交換數據, 則說明后續數據均有序if flag == False:break # 跳出數據走訪# 遍歷次數print("走訪次數:", i + 1)if __name__ == '__main__':l = list(range(1, 11))random.shuffle(l)print("排序前:", l)# func(l) foo(l)print("排序后:", l)
簡單代碼
import randomdef foo(l):for i in range(len(l) - 1):for j in range(len(l) - i - 1):if l[j] > l[j + 1] and j != len(l):l[j], l[j + 1] = l[j + 1], l[j]return lif __name__ == '__main__':l = list(range(13))random.shuffle(l)print(l) # [2, 3, 0, 7, 8, 11, 10, 6, 4, 5, 12, 1, 9]print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
升級版代碼
import randomdef foo(l):for i in range(len(l) - 1):flag = 1for j in range(len(l) - i - 1):if l[j] > l[j + 1] and j != len(l):l[j], l[j + 1] = l[j + 1], l[j]flag = 0if flag:breakreturn lif __name__ == '__main__':l = list(range(13))random.shuffle(l)print(l) # [0, 9, 1, 3, 8, 12, 6, 5, 2, 7, 10, 11, 4]print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
快速排序
算法分析


首先任意取一個元素作為關鍵數據 ( 通常取首元素
然后將所有比他小的數據源放在其前面,?所有比它大的放在他后面
通過一次排序將要排序的數據分為獨立的兩部分
然后按照該方法再遞歸對兩部分數據進行快速排序
性能參數
時間復雜度 O(nlogn)
空間復雜度 O(logn)
穩定性 不穩定
詳細代碼
# 快速排序 import randomdef quick(l):# 遞歸退出條件# 僅剩一個元素無需繼續分組if len(l) < 2:return l# 設置關鍵數據a = l[0]# 找出所有比 a 大的數據big = [x for x in l if x > a]# 找出所有比 a 小的數據small = [x for x in l if x < a]# 找出所有與 a 相等的數據same = [x for x in l if x == a]# 拼接數據排序的結果return quick(small) + same + quick(big)if __name__ == '__main__':l = list(range(1, 25))random.shuffle(l)l = quick(l)print(l)
二分查找
算法分析
只能對有序隊列進行查找, 利用和中間值進行對比, 然后基于判斷將隊列丟棄一半的方式
性能參數
時間復雜度 O(log2 n)
空間復雜度 O(1)
詳細代碼
""" 1. 切分成兩部分,取中間值來判斷 2. 如何定義下一次的范圍:大于中間值, 在左側找小于中間值, 在右側找 3. 查找失敗情況: 中間值 小于左端 或者 中間值 大于 右端 """""" 撲克牌 只取 黑桃 13 張, 用 1-13 表示, 將牌從小到大排序, 反面向上排成一排, 找到黑桃 6 的位置 """""" l 原始數據 k 待查找數據 left 首元素下標值 right 尾元素下標值 """""" 遞歸方式實現 """def func(l, k, left, right):# 遞歸退出條件if left > right:# 查找結束return -1# 獲取中間元素對應下標值middle = (left + right) // 2# 對比中間元素 和 查找元素if l[middle] == k:return middleelif l[middle] > k:# 中間值 大于 查找值# 查找范圍是 中分后的 左邊部分# 左側下標值不變, 右側下標值變為 middle 前一位right = middle - 1return func(l, k, left, right)else:# 中間值 小于 查找值# 查找范圍是 中分后的 右邊部分# 左側下標值變為 middle 后一位, 右側下標值不變left = middle + 1return func(l, k, left, right)""" 循環方式實現 """def foo(l, k):left = 0right = len(l) - 1while left <= right:mid = (left + right) // 2if l[mid] > k:right = mid - 1elif l[mid] < k:left = mid + 1elif l[mid] == k:return midreturn -1if __name__ == '__main__':# l = list(range(1, 14))# k = 8# right = len(l) - 1# res = func(l, k, 0, right) l = list(range(1, 14))k = 10right = len(l) - 1res = foo(l, k)if res == -1:print("查找失敗")else:print("查找成功, 第 %d 張拿到" % res)
簡單代碼
def foo(l, k):left = 0right = len(l) - 1while left <= right:mid = (left + right) // 2if l[mid] > k:right = mid - 1elif l[mid] < k:left = mid + 1elif l[mid] == k:return midreturn -1if __name__ == '__main__':l = list(range(13))print(l) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]print(foo(l, 8)) # 8
總結
冒泡排序
重復走訪所有要排序的數據,
依次比較每兩個相鄰的元素,
如果兩者次序錯誤就交換
重復上面過程 直到沒有需要被調換的內容為止
插入排序
將數據插入到已經有序的數據中, 從而得到一個新的有序數據
默認首元素自然有序, 取出下一個元素, 對已經有序的數據從后向前掃描
若掃描的有序數據大于取出數據, 則該有序數據后移
若掃描的有序數據小于取出數據, 則在該有序數據后插入取出數據
若掃描的所有的有序數據大于取出數據, 則在有序數據的首位插入取出數據
特點
數據只移動不交換, 優于冒泡
快速排序
首先任意取一個元素作為關鍵數據 ( 通常取首元素 )
然后將所有比他小的數據源放在其前面
(從小到大)所有比它大的放在他后面
通過一次排序將要排序的數據分為獨立的兩部分
然后按照該方法再遞歸對兩部分數據進行快速排序
特點
每次若能均勻分組則排序速度最快, 但是不穩定
?
![[EmguCV|C#]使用CvInvoke自己繪製色彩直方圖-直方圖(Hitsogram)系列(4)](http://pic.xiahunao.cn/[EmguCV|C#]使用CvInvoke自己繪製色彩直方圖-直方圖(Hitsogram)系列(4))

)




)











| ProxySQL基本概念)