說明:?
Allocation Rate, 翻譯為分配速率, 而不是分配率; 因為不是百分比,而是單位時間內分配的量;同理,?
Promotion Rate?翻譯為?提升速率;
您應該已經閱讀了前面的章節:
- 垃圾收集簡介 - GC參考手冊
- Java中的垃圾收集 - GC參考手冊
- GC 算法(基礎篇) - GC參考手冊
- GC 算法(實現篇) - GC參考手冊
- GC 調優(基礎篇) - GC參考手冊
- GC 調優(工具篇) - GC參考手冊
高分配速率(High Allocation Rate)
分配速率(Allocation rate)表示單位時間內分配的內存量。通常使用?MB/sec作為單位, 也可以使用?PB/year?等。
分配速率過高就會嚴重影響程序的性能。在JVM中會導致巨大的GC開銷。
如何測量分配速率?
指定JVM參數:?-XX:+PrintGCDetails -XX:+PrintGCTimeStamps?, 通過GC日志來計算分配速率. GC日志如下所示:
0.291: [GC (Allocation Failure) [PSYoungGen: 33280K->5088K(38400K)] 33280K->24360K(125952K), 0.0365286 secs] [Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure) [PSYoungGen: 38368K->5120K(71680K)] 57640K->46240K(159232K), 0.0456796 secs] [Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure) [PSYoungGen: 71680K->5120K(71680K)] 112800K->81912K(159232K), 0.0861795 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
計算?上一次垃圾收集之后,與下一次GC開始之前的年輕代使用量, 兩者的差值除以時間,就是分配速率。 通過上面的日志, 可以計算出以下信息:
- JVM啟動之后?
291ms, 共創建了?33,280 KB?的對象。 第一次 Minor GC(小型GC) 完成后, 年輕代中還有?5,088 KB?的對象存活。 - 在啟動之后?
446 ms, 年輕代的使用量增加到?38,368 KB, 觸發第二次GC, 完成后年輕代的使用量減少到?5,120 KB。 - 在啟動之后?
829 ms, 年輕代的使用量為?71,680 KB, GC后變為?5,120 KB。
可以通過年輕代的使用量來計算分配速率, 如下表所示:
| Event | Time | Young before | Young after | Allocated during | Allocation rate |
|---|---|---|---|---|---|
| 1st GC | 291ms | 33,280KB | 5,088KB | 33,280KB | 114MB/sec |
| 2nd GC | 446ms | 38,368KB | 5,120KB | 33,280KB | 215MB/sec |
| 3rd GC | 829ms | 71,680KB | 5,120KB | 66,560KB | 174MB/sec |
| Total | 829ms | N/A | N/A | 133,120KB | 161MB/sec |
通過這些信息可以知道, 在測量期間, 該程序的內存分配速率為?161 MB/sec。
分配速率的意義
分配速率的變化,會增加或降低GC暫停的頻率, 從而影響吞吐量。 但只有年輕代的?minor GC?受分配速率的影響, 老年代GC的頻率和持續時間不受?分配速率(allocation rate)的直接影響, 而是受到?提升速率(promotion rate)的影響, 請參見下文。
現在我們只關心?Minor GC?暫停, 查看年輕代的3個內存池。因為對象在?Eden區分配, 所以我們一起來看 Eden 區的大小和分配速率的關系. 看看增加 Eden 區的容量, 能不能減少 Minor GC 暫停次數, 從而使程序能夠維持更高的分配速率。
經過我們的實驗, 通過參數?-XX:NewSize、?-XX:MaxNewSize?以及?-XX:SurvivorRatio?設置不同的 Eden 空間, 運行同一程序時, 可以發現:
- Eden 空間為?
100 MB?時, 分配速率低于?100 MB/秒。 - 將 Eden 區增大為?
1 GB, 分配速率也隨之增長,大約等于?200 MB/秒。
為什么會這樣? —— 因為減少GC暫停,就等價于減少了任務線程的停頓,就可以做更多工作, 也就創建了更多對象, 所以對同一應用來說, 分配速率越高越好。
在得出 “Eden區越大越好” 這個結論前, 我們注意到, 分配速率可能會,也可能不會影響程序的實際吞吐量。 吞吐量和分配速率有一定關系, 因為分配速率會影響 minor GC 暫停, 但對于總體吞吐量的影響, 還要考慮 Major GC(大型GC)暫停, 而且吞吐量的單位不是?MB/秒, 而是系統所處理的業務量。
示例
參考?Demo程序。假設系統連接了一個外部的數字傳感器。應用通過專有線程, 不斷地獲取傳感器的值,(此處使用隨機數模擬), 其他線程會調用?processSensorValue()?方法, 傳入傳感器的值來執行某些操作, :
public class BoxingFailure {private static volatile Double sensorValue;private static void readSensor() {while(true) sensorValue = Math.random();}private static void processSensorValue(Double value) {if(value != null) {//...}}
}
如同類名所示, 這個Demo是模擬 boxing 的。為了 null 值判斷, 使用的是包裝類型?Double。 程序基于傳感器的最新值進行計算, 但從傳感器取值是一個重量級操作, 所以采用了異步方式: 一個線程不斷獲取新值, 計算線程則直接使用暫存的最新值, 從而避免同步等待。
Demo 程序在運行的過程中, 由于分配速率太大而受到GC的影響。下一節將確認問題, 并給出解決辦法。
高分配速率對JVM的影響
首先,我們應該檢查程序的吞吐量是否降低。如果創建了過多的臨時對象, minor GC的次數就會增加。如果并發較大, 則GC可能會嚴重影響吞吐量。
遇到這種情況時, GC日志將會像下面這樣,當然這是上面的示例程序?產生的GC日志。 JVM啟動參數為?-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xmx32m:
2.808: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003076 secs]
2.819: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003079 secs]
2.830: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0002968 secs]
2.842: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003374 secs]
2.853: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0004672 secs]
2.864: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003371 secs]
2.875: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003214 secs]
2.886: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003374 secs]
2.896: [GC (Allocation Failure) [PSYoungGen: 9760K->32K(10240K)], 0.0003588 secs]
很顯然 minor GC 的頻率太高了。這說明創建了大量的對象。另外, 年輕代在 GC 之后的使用量又很低, 也沒有 full GC 發生。 種種跡象表明, GC對吞吐量造成了嚴重的影響。
解決方案
在某些情況下,只要增加年輕代的大小, 即可降低分配速率過高所造成的影響。增加年輕代空間并不會降低分配速率, 但是會減少GC的頻率。如果每次GC后只有少量對象存活, minor GC 的暫停時間就不會明顯增加。
運行?示例程序?時, 增加堆內存大小,(同時也就增大了年輕代的大小), 使用的JVM參數為?-Xmx64m:
2.808: [GC (Allocation Failure) [PSYoungGen: 20512K->32K(20992K)], 0.0003748 secs]
2.831: [GC (Allocation Failure) [PSYoungGen: 20512K->32K(20992K)], 0.0004538 secs]
2.855: [GC (Allocation Failure) [PSYoungGen: 20512K->32K(20992K)], 0.0003355 secs]
2.879: [GC (Allocation Failure) [PSYoungGen: 20512K->32K(20992K)], 0.0005592 secs]
但有時候增加堆內存的大小,并不能解決問題。通過前面學到的知識, 我們可以通過分配分析器找出大部分垃圾產生的位置。實際上在此示例中, 99%的對象屬于?Double?包裝類, 在readSensor?方法中創建。最簡單的優化, 將創建的?Double?對象替換為原生類型?double, 而針對 null 值的檢測, 可以使用?Double.NaN?來進行。由于原生類型不算是對象, 也就不會產生垃圾, 導致GC事件。優化之后, 不在堆中分配新對象, 而是直接覆蓋一個屬性域即可。
對示例程序進行簡單的改造(?查看diff?) 后, GC暫停基本上完全消除。有時候 JVM 也很智能, 會使用 逃逸分析技術(escape analysis technique) 來避免過度分配。簡單來說,JIT編譯器可以通過分析得知, 方法創建的某些對象永遠都不會“逃出”此方法的作用域。這時候就不需要在堆上分配這些對象, 也就不會產生垃圾, 所以JIT編譯器的一種優化手段就是: 消除內存分配。請參考?基準測試?。
過早提升(Premature Promotion)
提升速率(promotion rate), 用于衡量單位時間內從年輕代提升到老年代的數據量。一般使用?MB/sec?作為單位, 和分配速率類似。
JVM會將長時間存活的對象從年輕代提升到老年代。根據分代假設, 可能存在一種情況, 老年代中不僅有存活時間長的對象,也可能有存活時間短的對象。這就是過早提升:對象存活時間還不夠長的時候就被提升到了老年代。
major GC 不是為頻繁回收而設計的, 但 major GC 現在也要清理這些生命短暫的對象, 就會導致GC暫停時間過長。這會嚴重影響系統的吞吐量。
如何測量提升速率
可以指定JVM參數?-XX:+PrintGCDetails -XX:+PrintGCTimeStamps?, 通過GC日志來測量提升速率. JVM記錄的GC暫停信息如下所示:
0.291: [GC (Allocation Failure) [PSYoungGen: 33280K->5088K(38400K)] 33280K->24360K(125952K), 0.0365286 secs] [Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure) [PSYoungGen: 38368K->5120K(71680K)] 57640K->46240K(159232K), 0.0456796 secs] [Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure) [PSYoungGen: 71680K->5120K(71680K)] 112800K->81912K(159232K), 0.0861795 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
從上面的日志可以得知: GC之前和之后的 年輕代使用量以及堆內存使用量。這樣就可以通過差值算出老年代的使用量。GC日志中的信息可以表述為:
| Event | Time | Young decreased | Total decreased | Promoted | Promotion rate |
|---|---|---|---|---|---|
| (事件) | (耗時) | (年輕代減少) | (整個堆內存減少) | (提升量) | (提升速率) |
| 1st GC | 291ms | 28,192K | 8,920K | 19,272K | 66.2 MB/sec |
| 2nd GC | 446ms | 33,248K | 11,400K | 21,848K | 140.95 MB/sec |
| 3rd GC | 829ms | 66,560K | 30,888K | 35,672K | 93.14 MB/sec |
| Total | 829ms | ? | ? | 76,792K | 92.63 MB/sec |
根據這些信息, 就可以計算出觀測周期內的提升速率。平均提升速率為?92 MB/秒, 峰值為?140.95 MB/秒。
請注意,?只能根據 minor GC 計算提升速率。 Full GC 的日志不能用于計算提升速率, 因為 major GC 會清理掉老年代中的一部分對象。
提升速率的意義
和分配速率一樣, 提升速率也會影響GC暫停的頻率。但分配速率主要影響?minor GC, 而提升速率則影響?major GC?的頻率。有大量的對象提升,自然很快將老年代填滿。 老年代填充的越快, 則 major GC 事件的頻率就會越高。
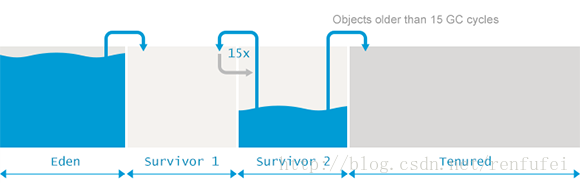
此前說過, full GC 通常需要更多的時間, 因為需要處理更多的對象, 還要執行碎片整理等額外的復雜過程。
示例
讓我們看一個過早提升的示例。 這個程序創建/獲取大量的對象/數據,并暫存到集合之中, 達到一定數量后進行批處理:
public class PrematurePromotion {private static final Collection<byte[]> accumulatedChunks = new ArrayList<>();private static void onNewChunk(byte[] bytes) {accumulatedChunks.add(bytes);if(accumulatedChunks.size() > MAX_CHUNKS) {processBatch(accumulatedChunks);accumulatedChunks.clear();}}
}
此?Demo 程序?受到過早提升的影響。下文將進行驗證并給出解決辦法。
過早提升的影響
一般來說,過早提升的癥狀表現為以下形式:
- 短時間內頻繁地執行 full GC。
- 每次 full GC 后老年代的使用率都很低, 在10-20%或以下。
- 提升速率接近于分配速率。
要演示這種情況稍微有點麻煩, 所以我們使用特殊手段, 讓對象提升到老年代的年齡比默認情況小很多。指定GC參數?-Xmx24m -XX:NewSize=16m -XX:MaxTenuringThreshold=1, 運行程序之后,可以看到下面的GC日志:
2.176: [Full GC (Ergonomics) [PSYoungGen: 9216K->0K(10752K)] [ParOldGen: 10020K->9042K(12288K)] 19236K->9042K(23040K), 0.0036840 secs]
2.394: [Full GC (Ergonomics) [PSYoungGen: 9216K->0K(10752K)] [ParOldGen: 9042K->8064K(12288K)] 18258K->8064K(23040K), 0.0032855 secs]
2.611: [Full GC (Ergonomics) [PSYoungGen: 9216K->0K(10752K)] [ParOldGen: 8064K->7085K(12288K)] 17280K->7085K(23040K), 0.0031675 secs]
2.817: [Full GC (Ergonomics) [PSYoungGen: 9216K->0K(10752K)] [ParOldGen: 7085K->6107K(12288K)] 16301K->6107K(23040K), 0.0030652 secs]
乍一看似乎不是過早提升的問題。事實上,在每次GC之后老年代的使用率似乎在減少。但反過來想, 要是沒有對象提升或者提升率很小, 也就不會看到這么多的 Full GC 了。
簡單解釋一下這里的GC行為: 有很多對象提升到老年代, 同時老年代中也有很多對象被回收了, 這就造成了老年代使用量減少的假象. 但事實是大量的對象不斷地被提升到老年代, 并觸發 full GC。
解決方案
簡單來說, 要解決這類問題, 需要讓年輕代存放得下暫存的數據。有兩種簡單的方法:
一是增加年輕代的大小, 設置JVM啟動參數, 類似這樣:?-Xmx64m -XX:NewSize=32m, 程序在執行時, Full GC 的次數自然會減少很多, 只會對 minor GC的持續時間產生影響:
2.251: [GC (Allocation Failure) [PSYoungGen: 28672K->3872K(28672K)] 37126K->12358K(61440K), 0.0008543 secs]
2.776: [GC (Allocation Failure) [PSYoungGen: 28448K->4096K(28672K)] 36934K->16974K(61440K), 0.0033022 secs]
二是減少每次批處理的數量, 也能得到類似的結果. 至于選用哪個方案, 要根據業務需求決定。在某些情況下, 業務邏輯不允許減少批處理的數量, 那就只能增加堆內存,或者重新指定年輕代的大小。
如果都不可行, 就只能優化數據結構, 減少內存消耗。但總體目標依然是一致的: 讓臨時數據能夠在年輕代存放得下。
Weak, Soft 及 Phantom 引用
另一類影響GC的問題是程序中的?non-strong 引用。雖然這類引用在很多情況下可以避免出現?OutOfMemoryError, 但過量使用也會對GC造成嚴重的影響, 反而降低系統性能。
弱引用的缺點
首先,?弱引用(weak reference) 是可以被GC強制回收的。當垃圾收集器發現一個弱可達對象(weakly reachable,即指向該對象的引用只剩下弱引用) 時, 就會將其置入相應的ReferenceQueue?中, 變成可終結的對象. 之后可能會遍歷這個 reference queue, 并執行相應的清理。典型的示例是清除緩存中不再引用的KEY。
當然, 在這個時候, 我們還可以將該對象賦值給新的強引用, 在最后終結和回收前, GC會再次確認該對象是否可以安全回收。因此, 弱引用對象的回收過程是橫跨多個GC周期的。
實際上弱引用使用的很多。大部分緩存框架(caching solution)都是基于弱引用實現的, 所以雖然業務代碼中沒有直接使用弱引用, 但程序中依然會大量存在。
其次,?軟引用(soft reference) 比弱引用更難被垃圾收集器回收. 回收軟引用沒有確切的時間點, 由JVM自己決定. 一般只會在即將耗盡可用內存時, 才會回收軟引用,以作最后手段。這意味著, 可能會有更頻繁的 full GC, 暫停時間也比預期更長, 因為老年代中的存活對象會很多。
最后, 使用虛引用(phantom reference)時, 必須手動進行內存管理, 以標識這些對象是否可以安全地回收。表面上看起來很正常, 但實際上并不是這樣。 javadoc 中寫道:
In order to ensure that a reclaimable object remains so, the referent of a phantom reference may not be retrieved: The get method of a phantom reference always returns null.
為了防止可回收對象的殘留, 虛引用對象不應該被獲取:?
phantom reference?的?get?方法返回值永遠是?null。
令人驚訝的是, 很多開發者忽略了下一段內容(這才是重點):
Unlike soft and weak references, phantom references are not automatically cleared by the garbage collector as they are enqueued. An object that is reachable via phantom references will remain so until all such references are cleared or themselves become unreachable.
與軟引用和弱引用不同, 虛引用不會被 GC 自動清除, 因為他們被存放到隊列中. 通過虛引用可達的對象會繼續留在內存中, 直到調用此引用的 clear 方法, 或者引用自身變為不可達。
也就是說,我們必須手動調用?clear()?來清除虛引用, 否則可能會造成?OutOfMemoryError?而導致 JVM 掛掉. 使用虛引用的理由是, 對于用編程手段來跟蹤某個對象何時變為不可達對象, 這是唯一的常規手段。 和軟引用/弱引用不同的是, 我們不能復活虛可達(phantom-reachable)對象。
示例
讓我們看一個弱引用示例, 其中創建了大量的對象, 并在 minor GC 中完成回收。和前面一樣, 修改提升閥值。使用的JVM參數為:?-Xmx24m -XX:NewSize=16m -XX:MaxTenuringThreshold=1?, GC日志如下所示:
2.330: [GC (Allocation Failure) 20933K->8229K(22528K), 0.0033848 secs]
2.335: [GC (Allocation Failure) 20517K->7813K(22528K), 0.0022426 secs]
2.339: [GC (Allocation Failure) 20101K->7429K(22528K), 0.0010920 secs]
2.341: [GC (Allocation Failure) 19717K->9157K(22528K), 0.0056285 secs]
2.348: [GC (Allocation Failure) 21445K->8997K(22528K), 0.0041313 secs]
2.354: [GC (Allocation Failure) 21285K->8581K(22528K), 0.0033737 secs]
2.359: [GC (Allocation Failure) 20869K->8197K(22528K), 0.0023407 secs]
2.362: [GC (Allocation Failure) 20485K->7845K(22528K), 0.0011553 secs]
2.365: [GC (Allocation Failure) 20133K->9501K(22528K), 0.0060705 secs]
2.371: [Full GC (Ergonomics) 9501K->2987K(22528K), 0.0171452 secs]
可以看到, Full GC 的次數很少。但如果使用弱引用來指向創建的對象, 使用JVM參數?-Dweak.refs=true, 則情況會發生明顯變化. 使用弱引用的原因很多, 比如在 weak hash map 中將對象作為Key的情況。在任何情況下, 使用弱引用都可能會導致以下情形:
2.059: [Full GC (Ergonomics) 20365K->19611K(22528K), 0.0654090 secs]
2.125: [Full GC (Ergonomics) 20365K->19711K(22528K), 0.0707499 secs]
2.196: [Full GC (Ergonomics) 20365K->19798K(22528K), 0.0717052 secs]
2.268: [Full GC (Ergonomics) 20365K->19873K(22528K), 0.0686290 secs]
2.337: [Full GC (Ergonomics) 20365K->19939K(22528K), 0.0702009 secs]
2.407: [Full GC (Ergonomics) 20365K->19995K(22528K), 0.0694095 secs]
可以看到, 發生了多次 full GC, 比起前一節的示例, GC時間增加了一個數量級! 這是過早提升的另一個例子, 但這次情況更加棘手. 當然,問題的根源在于弱引用。這些臨死的對象, 在添加弱引用之后, 被提升到了老年代。 但是, 他們現在陷入另一次GC循環之中, 所以需要對其做一些適當的清理。像之前一樣, 最簡單的辦法是增加年輕代的大小, 例如指定JVM參數:?-Xmx64m -XX:NewSize=32m:
2.328: [GC (Allocation Failure) 38940K->13596K(61440K), 0.0012818 secs]
2.332: [GC (Allocation Failure) 38172K->14812K(61440K), 0.0060333 secs]
2.341: [GC (Allocation Failure) 39388K->13948K(61440K), 0.0029427 secs]
2.347: [GC (Allocation Failure) 38524K->15228K(61440K), 0.0101199 secs]
2.361: [GC (Allocation Failure) 39804K->14428K(61440K), 0.0040940 secs]
2.368: [GC (Allocation Failure) 39004K->13532K(61440K), 0.0012451 secs]
這時候, 對象在 minor GC 中就被回收了。
更壞的情況是使用軟引用,例如這個軟引用示例程序。如果程序不是即將發生?OutOfMemoryError?, 軟引用對象就不會被回收. 在示例程序中,用軟引用替代弱引用, 立即出現了更多的 Full GC 事件:
2.162: [Full GC (Ergonomics) 31561K->12865K(61440K), 0.0181392 secs]
2.184: [GC (Allocation Failure) 37441K->17585K(61440K), 0.0024479 secs]
2.189: [GC (Allocation Failure) 42161K->27033K(61440K), 0.0061485 secs]
2.195: [Full GC (Ergonomics) 27033K->14385K(61440K), 0.0228773 secs]
2.221: [GC (Allocation Failure) 38961K->20633K(61440K), 0.0030729 secs]
2.227: [GC (Allocation Failure) 45209K->31609K(61440K), 0.0069772 secs]
2.234: [Full GC (Ergonomics) 31609K->15905K(61440K), 0.0257689 secs]
最有趣的是虛引用示例中的虛引用, 使用同樣的JVM參數啟動, 其結果和弱引用示例非常相似。實際上, full GC 暫停的次數會小得多, 原因前面說過, 他們有不同的終結方式。
如果禁用虛引用清理, 增加JVM啟動參數 (-Dno.ref.clearing=true), 則可以看到:
4.180: [Full GC (Ergonomics) 57343K->57087K(61440K), 0.0879851 secs]
4.269: [Full GC (Ergonomics) 57089K->57088K(61440K), 0.0973912 secs]
4.366: [Full GC (Ergonomics) 57091K->57089K(61440K), 0.0948099 secs]
main 線程中拋出異常?java.lang.OutOfMemoryError: Java heap space.
使用虛引用時要小心謹慎, 并及時清理虛可達對象。如果不清理, 很可能會發生?OutOfMemoryError. 請相信我們的經驗教訓: 處理 reference queue 的線程中如果沒 catch 住 exception , 系統很快就會被整掛了。
使用非強引用的影響
建議使用JVM參數?-XX:+PrintReferenceGC?來看看各種引用對GC的影響. 如果將此參數用于啟動?弱引用示例?, 將會看到:
2.173: [Full GC (Ergonomics) 2.234: [SoftReference, 0 refs, 0.0000151 secs]2.234: [WeakReference, 2648 refs, 0.0001714 secs]2.234: [FinalReference, 1 refs, 0.0000037 secs]2.234: [PhantomReference, 0 refs, 0 refs, 0.0000039 secs]2.234: [JNI Weak Reference, 0.0000027 secs][PSYoungGen: 9216K->8676K(10752K)] [ParOldGen: 12115K->12115K(12288K)] 21331K->20792K(23040K), [Metaspace: 3725K->3725K(1056768K)], 0.0766685 secs] [Times: user=0.49 sys=0.01, real=0.08 secs]
2.250: [Full GC (Ergonomics) 2.307: [SoftReference, 0 refs, 0.0000173 secs]2.307: [WeakReference, 2298 refs, 0.0001535 secs]2.307: [FinalReference, 3 refs, 0.0000043 secs]2.307: [PhantomReference, 0 refs, 0 refs, 0.0000042 secs]2.307: [JNI Weak Reference, 0.0000029 secs][PSYoungGen: 9215K->8747K(10752K)] [ParOldGen: 12115K->12115K(12288K)] 21331K->20863K(23040K), [Metaspace: 3725K->3725K(1056768K)], 0.0734832 secs] [Times: user=0.52 sys=0.01, real=0.07 secs]
2.323: [Full GC (Ergonomics) 2.383: [SoftReference, 0 refs, 0.0000161 secs]2.383: [WeakReference, 1981 refs, 0.0001292 secs]2.383: [FinalReference, 16 refs, 0.0000049 secs]2.383: [PhantomReference, 0 refs, 0 refs, 0.0000040 secs]2.383: [JNI Weak Reference, 0.0000027 secs][PSYoungGen: 9216K->8809K(10752K)] [ParOldGen: 12115K->12115K(12288K)] 21331K->20925K(23040K), [Metaspace: 3725K->3725K(1056768K)], 0.0738414 secs] [Times: user=0.52 sys=0.01, real=0.08 secs]
只有確定 GC 對應用的吞吐量和延遲造成影響之后, 才應該花心思來分析這些信息, 審查這部分日志。通常情況下, 每次GC清理的引用數量都是很少的, 大部分情況下為?0。如果GC 花了較多時間來清理這類引用, 或者清除了很多的此類引用, 就需要進一步觀察和分析了。
解決方案
如果程序確實碰到了?mis-,?ab-?問題或者濫用 weak, soft, phantom 引用, 一般都要修改程序的實現邏輯。每個系統不一樣, 因此很難提供通用的指導建議, 但有一些常用的辦法:
弱引用(Weak references) —— 如果某個內存池的使用量增大, 造成了性能問題, 那么增加這個內存池的大小(可能也要增加堆內存的最大容量)。如同示例中所看到的, 增加堆內存的大小, 以及年輕代的大小, 可以減輕癥狀。虛引用(Phantom references) —— 請確保在程序中調用了虛引用的?clear?方法。編程中很容易忽略某些虛引用, 或者清理的速度跟不上生產的速度, 又或者清除引用隊列的線程掛了, 就會對GC 造成很大壓力, 最終可能引起?OutOfMemoryError。軟引用(Soft references) —— 如果確定問題的根源是軟引用, 唯一的解決辦法是修改程序源碼, 改變內部實現邏輯。
其他示例
前面介紹了最常見的GC性能問題。但我們學到的很多原理都沒有具體的場景來展現。本節介紹一些不常發生, 但也可能會碰到的問題。
RMI 與 GC
如果系統提供或者消費?RMI?服務, 則JVM會定期執行 full GC 來確保本地未使用的對象在另一端也不占用空間. 記住, 即使你的代碼中沒有發布 RMI 服務, 但第三方或者工具庫也可能會打開 RMI 終端. 最常見的元兇是 JMX, 如果通過JMX連接到遠端, 底層則會使用 RMI 發布數據。
問題是有很多不必要的周期性 full GC。查看老年代的使用情況, 一般是沒有內存壓力, 其中還存在大量的空閑區域, 但 full GC 就是被觸發了, 也就會暫停所有的應用線程。
這種周期性調用?System.gc()?刪除遠程引用的行為, 是在?sun.rmi.transport.ObjectTable?類中, 通過?sun.misc.GC.requestLatency(long gcInterval)?調用的。
對許多應用來說, 根本沒必要, 甚至對性能有害。 禁止這種周期性的 GC 行為, 可以使用以下 JVM 參數:
java -Dsun.rmi.dgc.server.gcInterval=9223372036854775807L -Dsun.rmi.dgc.client.gcInterval=9223372036854775807L com.yourcompany.YourApplication
這讓?Long.MAX_VALUE?毫秒之后, 才調用?System.gc(), 實際運行的系統可能永遠都不會觸發。
ObjectTable.class
private static final long gcInterval =
((Long)AccessController.doPrivileged(new GetLongAction("sun.rmi.dgc.server.gcInterval", 3600000L))).longValue();
可以看到, 默認值為?3600000L,也就是1小時觸發一次 Full GC。
另一種方式是指定JVM參數?-XX:+DisableExplicitGC, 禁止顯式地調用?System.gc(). 但我們強烈反對?這種方式, 因為埋有地雷。
JVMTI tagging 與 GC
如果在程序啟動時指定了 Java Agent (-javaagent), agent 就可以使用?JVMTI tagging?標記堆中的對象。agent 使用tagging的種種原因本手冊不詳細講解, 但如果 tagging 標記了大量的對象, 很可能會引起 GC 性能問題, 導致延遲增加, 以及吞吐量降低。
問題發生在 native 代碼中,?JvmtiTagMap::do_weak_oops?在每次GC時, 都會遍歷所有標簽(tag),并執行一些比較耗時的操作。更坑的是, 這種操作是串行執行的。
如果存在大量的標簽, 就意味著 GC 時有很大一部分工作是單線程執行的, GC暫停時間可能會增加一個數量級。
檢查是否因為 agent 增加了GC暫停時間, 可以使用診斷參數?–XX:+TraceJVMTIObjectTagging. 啟用跟蹤之后, 可以估算出內存中 tag 映射了多少 native 內存, 以及遍歷所消耗的時間。
如果你不是 agent 的作者, 那一般是搞不定這類問題的。除了提BUG之外你什么都做不了. 如果發生了這種情況, 請建議廠商清理不必要的標簽。
巨無霸對象的分配(Humongous Allocations)
如果使用 G1 垃圾收集算法, 會產生一種巨無霸對象引起的 GC 性能問題。
說明: 在G1中, 巨無霸對象是指所占空間超過一個小堆區(region)?
50%?的對象。
頻繁的創建巨無霸對象, 無疑會造成GC的性能問題, 看看G1的處理方式:
- 如果某個 region 中含有巨無霸對象, 則巨無霸對象后面的空間將不會被分配。如果所有巨無霸對象都超過某個比例, 則未使用的空間就會引發內存碎片問題。
- G1 沒有對巨無霸對象進行優化。這在 JDK 8 以前是個特別棘手的問題 —— 在?Java 1.8u40?之前的版本中, 巨無霸對象所在 region 的回收只能在 full GC 中進行。最新版本的 Hotspot JVM, 在 marking 階段之后的 cleanup 階段中釋放巨無霸區間, 所以這個問題在新版本JVM中的影響已大大降低。
要監控是否存在巨無霸對象, 可以打開GC日志, 使用的命令如下:
java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintReferenceGC -XX:+UseG1GC -XX:+PrintAdaptiveSizePolicy -Xmx128m MyClass
GC 日志中可能會發現這樣的部分:
0.106: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 60817408 bytes, allocation request: 1048592 bytes, threshold: 60397965 bytes (45.00 %), source: concurrent humongous allocation]0.106: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: requested by GC cause, GC cause: G1 Humongous Allocation]0.106: [G1Ergonomics (Concurrent Cycles) initiate concurrent cycle, reason: concurrent cycle initiation requested]0.106: [GC pause (G1 Humongous Allocation) (young) (initial-mark) 0.106: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 0, predicted base time: 10.00 ms, remaining time: 190.00 ms, target pause time: 200.00 ms]
這樣的日志就是證據, 表明程序中確實創建了巨無霸對象. 可以看到:?G1 Humongous Allocation?是 GC暫停的原因。 再看前面一點的?allocation request: 1048592 bytes?, 可以發現程序試圖分配一個?1,048,592?字節的對象, 這要比巨無霸區域(2MB)的?50%?多出 16 個字節。
第一種解決方式, 是修改 region size , 以使得大多數的對象不超過?50%, 也就不進行巨無霸對象區域的分配。 region 的默認大小在啟動時根據堆內存的大小算出。但也可以指定參數來覆蓋默認設置,?-XX:G1HeapRegionSize=XX。 指定的 region size 必須在?1~32MB?之間, 還必須是2的冪 【2^10 = 1024 = 1KB; 2^20=1MB; 所以 region size 只能是:?1m,2m,4m,8m,16m,32m】。
這種方式也有副作用, 增加 region 的大小也就變相地減少了 region 的數量, 所以需要謹慎使用, 最好進行一些測試, 看看是否改善了吞吐量和延遲。
更好的方式需要一些工作量, 如果可以的話, 在程序中限制對象的大小。最好是使用分析器, 展示出巨無霸對象的信息, 以及分配時所在的堆棧跟蹤信息。
總結
JVM上運行的程序多種多樣, 啟動參數也有上百個, 其中有很多會影響到 GC, 所以調優GC性能的方法也有很多種。
還是那句話, 沒有真正的銀彈, 能滿足所有的性能調優指標。 我們能做的只是介紹一些常見的/和不常見的示例, 讓你在碰到類似問題時知道是怎么回事。深入理解GC的工作原理, 熟練應用各種工具, 就可以進行GC調優, 提高程序性能。
原文鏈接:?GC Tuning: In Practice
翻譯人員:?鐵錨?http://blog.csdn.net/renfufei
翻譯時間: 2016年02月06日









How to take a picture of a black hole)

)

)





)