本文分享了我在silent speech 項目過程中實現的基于嘴唇圖像數據集的autoencoder自編碼器。輸入輸出都是64?6464*6464?64的嘴唇灰度圖。自編碼器由編碼解碼兩個部分構成,同時實現了利用checkpoint在每個epoch運算時,自動保存測試集loss更小的模型。
數據集共包含84679張圖片,其中前68728張圖片作為訓練集,后15951張圖片作為測試集。

import tensorflow as tf
from tensorflow.keras import layers
from tensorflow import keras
import numpy as np
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras import optimizers
from matplotlib import pyplot as plt
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, concatenate, Flatten, Conv2DTranspose, UpSampling2D
from tensorflow.keras.models import Modeldef autoencoder_lips():input_img = Input(shape=(64, 64, 1))# encodingconv1 = Conv2D(filters=16, kernel_size=(5, 5), activation='relu', padding='same', name='lip_conv1')(input_img)conv2 = Conv2D(filters=16, kernel_size=(5, 5), activation='relu', padding='same', name='lip_conv2')(conv1)pooling1 = MaxPooling2D(pool_size=(2, 2), name='lip_pooling1')(conv2)conv3 = Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', name='lip_conv3')(pooling1)conv4 = Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', name='lip_conv4')(conv3)pooling2 = MaxPooling2D(pool_size=(2, 2), name='lip_pooling2')(conv4)# decodingconv5 = Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', name='lip_conv5')(pooling2)conv6 = Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same', name='lip_conv6')(conv5)upsample1 = UpSampling2D(size=(2, 2), name='lip_upsample1')(conv6)conv7 = Conv2D(filters=16, kernel_size=(5, 5), activation='relu', padding='same', name='lip_conv7')(upsample1)conv8 = Conv2D(filters=16, kernel_size=(5, 5), activation='relu', padding='same', name='lip_conv8')(conv7)upsample2 = UpSampling2D(size=(2, 2), name='lip_upsample2')(conv8)decoded = Conv2D(filters=1, kernel_size=(5, 5), activation='sigmoid', padding='same', name='lip_decoded')(upsample2)autoencoder_lip = Model(input_img, decoded, name='autoencoder_lips')autoencoder_lip.summary()return autoencoder_lipif __name__ == "__main__":X = np.load("lips_all_chapiters.npy")nb_images_chapiter7 = 15951# normalisationX = X/255.0# ch1-ch6X_train = X[:-15951, :]X_test = X[-15951:, :]model = autoencoder_lips()my_optimizer = keras.optimizers.Adam(learning_rate=0.0001, epsilon=1e-8)model.compile(optimizer=my_optimizer, loss='binary_crossentropy')filepath = "autoencoder_lips/autoencoder_lips-{epoch:02d}-{val_loss:.8f}.h5"checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1,save_best_only=True, mode='auto') # only save improved accuracy modelcallbacks_list = [checkpoint]history = model.fit(x=X_train, y=X_train, batch_size=256, epochs=100, callbacks=callbacks_list,validation_data=(X_test, X_test))
訓練好的自編碼器最終在測試集上的表現如下 :
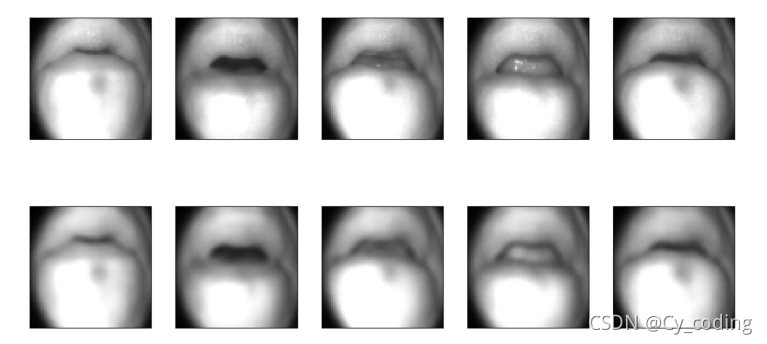
第一行是原始輸入的圖像,第二行是自編碼器輸出的對應圖像。我們可以發現雖然自編碼器生成的圖像與原圖像相比損失了清晰度,但是整體上還原了圖像原本的形態。我們因此可以利用自編碼器的中間層作為壓縮后的圖像信息,或稱features特征。自編碼器往往可以用于壓縮信息,或作為進一步進行學習的中間標簽。




 設置單獨接口的超時時間和FallBack)






)





 Bootstrap-select 從后臺獲取數據填充到select的 option中 用法詳解...)

