分布式訓練本質上是為了加快模型的訓練速度,面對較為復雜的深度學習模型以及大量的數據。單機單GPU很難在有限的時間內達成模型的收斂。這時候就需要用到分布式訓練。
分布式訓練又分為模型并行和數據并行兩大類。
1. 數據并行
數據并行在于將不同batch的數據分別交給不同的GPU來運算。如下圖所示,灰色部分表示數據,藍色表示模型。
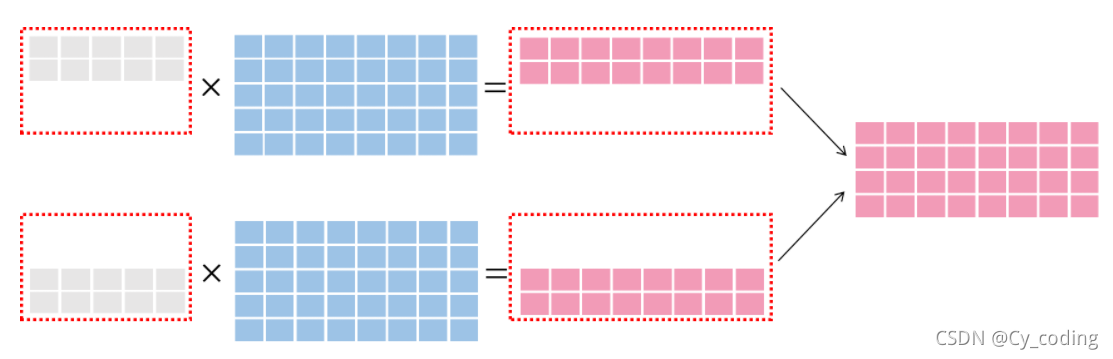
數據并行中的一類就是參數平均,比如將第一個Batch的256個數據交給第一個U
第二個batch的256個數據交給第二個U
參數平均就是在他們分別通過整個神經網絡計算出結果后取平均值,再修改模型中的參數。這樣實現實際上在不考慮多GPU與CPU的通信成本上,與單GPU以batchsize為512來進行訓練是一樣的,但因為同時進行了兩個batch的運算,運算速度在理想情況下是線性增加的。參數平均同時也是一個同步更新的過程,多個GPU的運算結果會統一結束并計算平均參數,這在我們使用同算力GPU的時候可以做到效率最大化。
除了同步更新,我們還有異步隨機梯度下降。這意味著不同的GPU不需要等待每一個epoch中所有GPU的運算完畢就可以直接更新參數。這很顯然進一步提升了多個U的效率,因為我們不再需要保證多個GPU的同步性,更大加快了模型的收斂。但不可避免地是,由于異步的特點,當某一個GPU完成運算并更新參數的時候,可能這時候模型中的全局參數已經經過了多次的改變,這可能會導致絕對誤差的放大,優化過程可能不穩定。
2. 模型并行
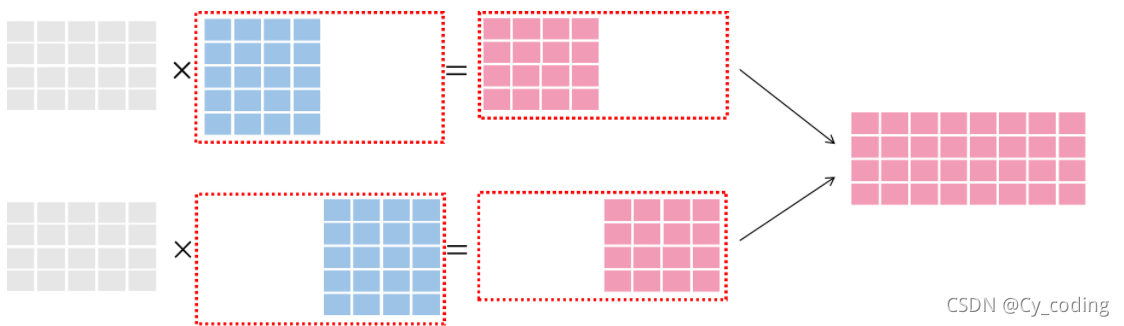
說完了數據并行,我們來看一下專門用于優化非常復雜的深度學習網絡的模型并行。與數據并行不同的是,這次我們通過將模型拆分為幾個小的部分,分別交給多個GPU來進行運算。每次仍然給每個模型一個batch的數據來進行計算,將多個GPU作為節點。最后將運算結果進行合并。實際上是一種將模型切割為幾個子模型按順序計算的過程。
參考文本 :
【深度學習】— 分布式訓練常用技術簡介
【分布式深度學習part1】:神經網絡的分布式訓練





)





 Bootstrap-select 從后臺獲取數據填充到select的 option中 用法詳解...)



-Linux從入門到精通第六天(非原創))



