前言
面試時間將近兩個小時(期間等待二面面試官來面我的時候等了半個多小時)面試官問的東西很多,還挖了好幾個坑,一個技術點套著一個技術點的問,一定要做好萬全的準備。問了一些基本層面上的技術點都答出來了,稍微問深一點我就有點懵了(實戰經驗還是不足)。
回來之后把這些題目做了一個分類并整理出答案(每次去面試的時候面試官問的問題面試結束后我都會做筆記)分為Spring+邏輯算法+MySQL+Java+Redis+并發編程+JVM+RabbitMQ等,接下來分享一下我的這次螞蟻二面面經+一些我的學習筆記。
1. 面試官:工作中使用過Zookeeper嘛?你知道它是什么,有什么用途呢?
小菜雞的我:
- 有使用過的,使用ZooKeeper作為dubbo的注冊中心,使用ZooKeeper實現分布式鎖。
- ZooKeeper,它是一個開放源碼的分布式協調服務,它是一個集群的管理者,它將簡單易用的接口提供給用戶。
- 可以基于Zookeeper 實現諸如數據發布/訂閱、負載均衡、命名服務、分布式協調/通知、集群管理、Master 選舉、分布式鎖和分布式隊列等功能。
- Zookeeper的用途:命名服務、配置管理、集群管理、分布式鎖、隊列管理
用途跟功能不是一個意思咩?
2. 面試官:說下什么是命名服務,什么是配置管理,又什么是集群管理吧
小菜雞的我(幸好我刷過面試題),無所畏懼
-
命名服務就是:
命名服務是指通過指定的名字來獲取資源或者服務地址。Zookeeper可以創建一個全局唯一的路徑,這個路徑就可以作為一個名字。被命名的實體可以是集群中的機器,服務的地址,或者是遠程的對象等。一些分布式服務框架(RPC、RMI)中的服務地址列表,通過使用命名服務,客戶端應用能夠根據特定的名字來獲取資源的實體、服務地址和提供者信息等。
-
配置管理: :
實際項目開發中,我們經常使用.properties或者xml需要配置很多信息,如數據庫連接信息、fps地址端口等等。因為你的程序一般是分布式部署在不同的機器上(如果你是單機應用當我沒說),如果把程序的這些配置信息保存在zk的znode節點下,當你要修改配置,即znode會發生變化時,可以通過改變zk中某個目錄節點的內容,利用watcher通知給各個客戶端,從而更改配置。
-
集群管理
集群管理包括集群監控和集群控制,其實就是監控集群機器狀態,剔除機器和加入機器。zookeeper可以方便集群機器的管理,它可以實時監控znode節點的變化,一旦發現有機器掛了,該機器就會與zk斷開連接,對用的臨時目錄節點會被刪除,其他所有機器都收到通知。新機器加入也是類似醬紫,所有機器收到通知:有新兄弟目錄加入啦。
3. 面試官:你提到了znode節點,那你知道znode有幾種類型呢?zookeeper的數據模型是怎樣的呢?
小菜雞的我(我先想想):
zookeeper的數據模型
ZooKeeper的視圖數據結構,很像Unix文件系統,也是樹狀的,這樣可以確定每個路徑都是唯一的。zookeeper的節點統一叫做znode,它是可以通過路徑來標識,結構圖如下:

znode的4種類型
根據節點的生命周期,znode可以分為4種類型,分別是持久節點(PERSISTENT)、持久順序節點(PERSISTENT_SEQUENTIAL)、臨時節點(EPHEMERAL)、臨時順序節點(EPHEMERAL_SEQUENTIAL)
-
持久節點(PERSISTENT)
這類節點被創建后,就會一直存在于Zk服務器上。直到手動刪除。
-
持久順序節點(PERSISTENT_SEQUENTIAL)
它的基本特性同持久節點,不同在于增加了順序性。父節點會維護一個自增整性數字,用于子節點的創建的先后順序。
-
臨時節點(EPHEMERAL)
臨時節點的生命周期與客戶端的會話綁定,一旦客戶端會話失效(非TCP連接斷開),那么這個節點就會被自動清理掉。zk規定臨時節點只能作為葉子節點。
-
臨時順序節點(EPHEMERAL_SEQUENTIAL)
基本特性同臨時節點,添加了順序的特性。
4、面試官:你知道znode節點里面存儲的是什么嗎?每個節點的數據最大不能超過多少呢?
小菜雞的我:

znode節點里面存儲的是什么?
Znode數據節點的代碼如下
public class DataNode implements Record {byte data[]; Long acl; public StatPersisted stat; private Set<String> children = null;
}哈哈,Znode包含了存儲數據、訪問權限、子節點引用、節點狀態信息,如圖:
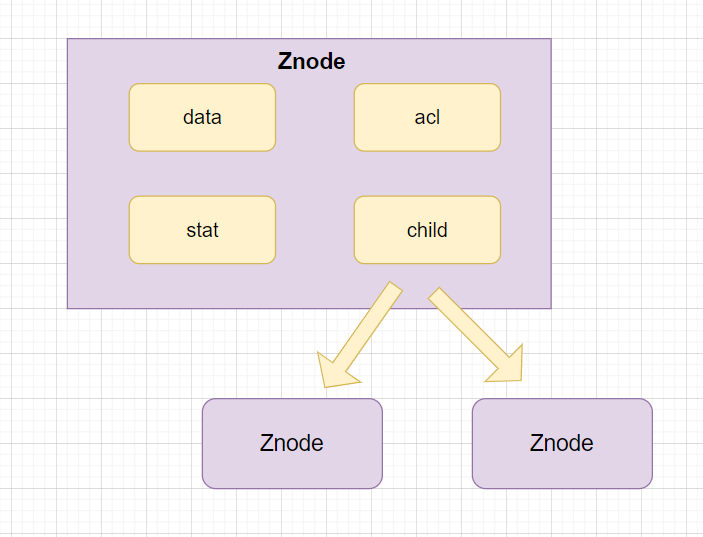
- data: znode存儲的業務數據信息
- ACL: 記錄客戶端對znode節點的訪問權限,如IP等。
- child: 當前節點的子節點引用
- stat: 包含Znode節點的狀態信息,比如事務id、版本號、時間戳等等。
每個節點的數據最大不能超過多少呢
為了保證高吞吐和低延遲,以及數據的一致性,znode只適合存儲非常小的數據,不能超過1M,最好都小于1K。
5、面試官:你知道znode節點上的監聽機制嘛?講下Zookeeper watch機制吧。
小菜雞的我:

- Watcher機制
- 監聽機制的工作原理
- Watcher特性總結
Watcher監聽機制
Zookeeper 允許客戶端向服務端的某個Znode注冊一個Watcher監聽,當服務端的一些指定事件觸發了這個Watcher,服務端會向指定客戶端發送一個事件通知來實現分布式的通知功能,然后客戶端根據 Watcher通知狀態和事件類型做出業務上的改變。
可以把Watcher理解成客戶端注冊在某個Znode上的觸發器,當這個Znode節點發生變化時(增刪改查),就會觸發Znode對應的注冊事件,注冊的客戶端就會收到異步通知,然后做出業務的改變。
Watcher監聽機制的工作原理
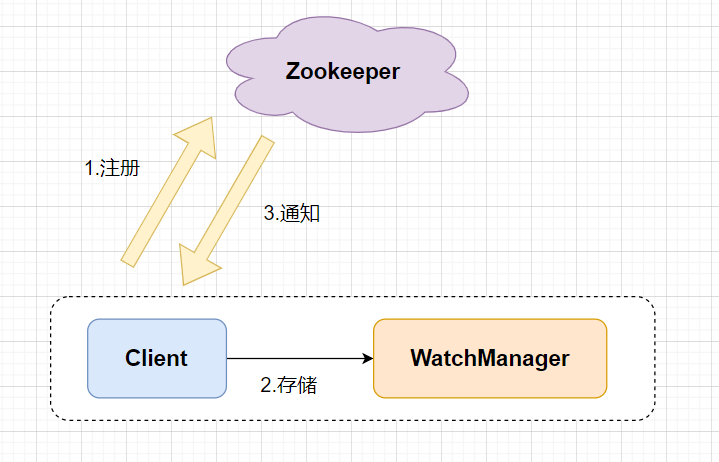
- ZooKeeper的Watcher機制主要包括客戶端線程、客戶端 WatcherManager、Zookeeper服務器三部分。
- 客戶端向ZooKeeper服務器注冊Watcher的同時,會將Watcher對象存儲在客戶端的WatchManager中。
- 當zookeeper服務器觸發watcher事件后,會向客戶端發送通知, 客戶端線程從 WatcherManager 中取出對應的 Watcher 對象來執行回調邏輯。
Watcher特性總結
- **一次性:**一個Watch事件是一個一次性的觸發器。一次性觸發,客戶端只會收到一次這樣的信息。
- 異步的: Zookeeper服務器發送watcher的通知事件到客戶端是異步的,不能期望能夠監控到節點每次的變化,Zookeeper只能保證最終的一致性,而無法保證強一致性。
- 輕量級: Watcher 通知非常簡單,它只是通知發生了事件,而不會傳遞事件對象內容。
- 客戶端串行: 執行客戶端 Watcher 回調的過程是一個串行同步的過程。
- 注冊 watcher用getData、exists、getChildren方法
- 觸發 watcher用create、delete、setData方法
6、面試官:你對Zookeeper的數據結構都有一定了解,那你講下Zookeeper的特性吧
小菜雞的我:(我背過書,啊哈哈)
Zookeeper 保證了如下分布式一致性特性:
- 順序一致性:從同一客戶端發起的事務請求,最終將會嚴格地按照順序被應用到 ZooKeeper 中去。
- 原子性:所有事務請求的處理結果在整個集群中所有機器上的應用情況是一致的,也就是說,要么整個集群中所有的機器都成功應用了某一個事務,要么都沒有應用。
- 單一視圖:無論客戶端連到哪一個 ZooKeeper 服務器上,其看到的服務端數據模型都是一致的。
- 可靠性: 一旦服務端成功地應用了一個事務,并完成對客戶端的響應,那么該事務所引起的服務端狀態變更將會被一直保留下來。
- 實時性(最終一致性): Zookeeper 僅僅能保證在一定的時間段內,客戶端最終一定能夠從服務端上讀取到最新的數據狀態。
7、面試官:你剛提到順序一致性,那zookeeper是如何保證事務的順序一致性的呢?
小菜雞的我:(完蛋了這題不會)
需要了解事務ID,即zxid。ZooKeeper的在選舉時通過比較各結點的zxid和機器ID選出新的主結點的。zxid由Leader節點生成,有新寫入事件時,Leader生成新zxid并隨提案一起廣播,每個結點本地都保存了當前最近一次事務的zxid,zxid是遞增的,所以誰的zxid越大,就表示誰的數據是最新的。
ZXID的生成規則如下:

ZXID有兩部分組成:
- 任期:完成本次選舉后,直到下次選舉前,由同一Leader負責協調寫入;
- 事務計數器:單調遞增,每生效一次寫入,計數器加一。
ZXID的低32位是計數器,所以同一任期內,ZXID是連續的,每個結點又都保存著自身最新生效的ZXID,通過對比新提案的ZXID與自身最新ZXID是否相差“1”,來保證事務嚴格按照順序生效的。
8、面試官:你提到了Leader,你知道Zookeeper的服務器有幾種角色嘛?Zookeeper下Server工作狀態又有幾種呢?
小菜雞的我:

Zookeeper 服務器角色
Zookeeper集群中,有Leader、Follower和Observer三種角色
Leader
Leader服務器是整個ZooKeeper集群工作機制中的核心,其主要工作:
- 事務請求的唯一調度和處理者,保證集群事務處理的順序性
- 集群內部各服務的調度者
Follower
Follower服務器是ZooKeeper集群狀態的跟隨者,其主要工作:
- 處理客戶端非事務請求,轉發事務請求給Leader服務器
- 參與事務請求Proposal的投票
- 參與Leader選舉投票
Observer
Observer是3.3.0 版本開始引入的一個服務器角色,它充當一個觀察者角色——觀察ZooKeeper集群的最新狀態變化并將這些狀態變更同步過來。其工作:
- 處理客戶端的非事務請求,轉發事務請求給 Leader 服務器
- 不參與任何形式的投票
Zookeeper下Server工作狀態
服務器具有四種狀態,分別是 LOOKING、FOLLOWING、LEADING、OBSERVING。
- 1.LOOKING:尋找Leader狀態。當服務器處于該狀態時,它會認為當前集群中沒有 Leader,因此需要進入 Leader 選舉狀態。
- 2.FOLLOWING:跟隨者狀態。表明當前服務器角色是Follower。
- 3.LEADING:領導者狀態。表明當前服務器角色是Leader。
- 4.OBSERVING:觀察者狀態。表明當前服務器角色是Observer。
9、面試官:你說到服務器角色是基于ZooKeeper集群的,那你畫一下ZooKeeper集群部署圖吧?ZooKeeper是如何保證主從節點數據一致性的呢?
小菜雞的我:

ZooKeeper集群部署圖
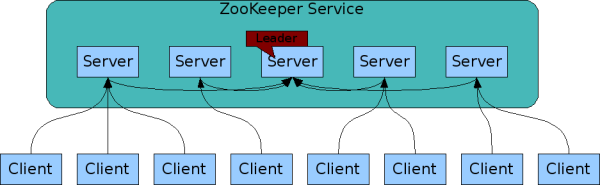
ZooKeeper集群是一主多從的結構:
- 如果是寫入數據,先寫入主服務器(主節點),再通知從服務器。
- 如果是讀取數據,既讀主服務器的,也可以讀從服務器的。
ZooKeeper如何保證主從節點數據一致性
我們知道集群是主從部署結構,要保證主從節點一致性問題,無非就是兩個主要問題:
- 主服務器掛了,或者重啟了
- 主從服務器之間同步數據~
Zookeeper是采用ZAB協議(Zookeeper Atomic Broadcast,Zookeeper原子廣播協議)來保證主從節點數據一致性的,ZAB協議支持崩潰恢復和消息廣播兩種模式,很好解決了這兩個問題:
- 崩潰恢復:Leader掛了,進入該模式,選一個新的leader出來
- 消息廣播: 把更新的數據,從Leader同步到所有Follower
Leader服務器掛了,所有集群中的服務器進入LOOKING狀態,首先,它們會選舉產生新的Leader服務器;接著,新的Leader服務器與集群中Follower服務進行數據同步,當集群中超過半數機器與該 Leader服務器完成數據同步之后,退出恢復模式進入消息廣播模式。Leader 服務器開始接收客戶端的事務請求生成事務Proposal進行事務請求處理。
結語
小編也是很有感觸,如果一直都是在中小公司,沒有接觸過大型的互聯網架構設計的話,只靠自己看書去提升可能一輩子都很難達到高級架構師的技術和認知高度。向厲害的人去學習是最有效減少時間摸索、精力浪費的方式。
我們選擇的這個行業就一直要持續的學習,又很吃青春飯。
雖然大家可能經常見到說程序員年薪幾十萬,但這樣的人畢竟不是大部份,要么是有名校光環,要么是在阿里華為這樣的大企業。年齡一大,更有可能被裁。
小編整理的學習資料分享一波!
送給每一位想學習Java小伙伴,用來提升自己。想要資料的可以點擊這里免費獲取
我們選擇的這個行業就一直要持續的學習,又很吃青春飯。
雖然大家可能經常見到說程序員年薪幾十萬,但這樣的人畢竟不是大部份,要么是有名校光環,要么是在阿里華為這樣的大企業。年齡一大,更有可能被裁。
小編整理的學習資料分享一波!
送給每一位想學習Java小伙伴,用來提升自己。想要資料的可以點擊這里免費獲取
[外鏈圖片轉存中…(img-SiWUTOWB-1624600978842)]
本文到這里就結束了,喜歡的朋友可以幫忙點贊和評論一下,感謝支持!













...)

)



