? ? ? ? 隨著預訓練模型的參數越來越大,尤其是175B參數大小的GPT3發布以來,讓很多中小公司和個人研究員對于大模型的全量微調望而卻步,近年來研究者們提出了各種各樣的參數高效遷移學習方法(Parameter-efficient Transfer Learning),即固定住Pretrain Language model(PLM)的大部分參數,僅調整模型的一小部分參數來達到與全部參數的微調接近的效果(調整的可以是模型自有的參數,也可以是額外加入的一些參數)。本文將介紹一些常見的參數高效微調技術,比如:BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2、Adapter Tuning及其變體、LoRA、AdaLoRA、QLoRA、MAM Adapter、UniPELT等。
推薦閱讀列表:
大模型PEFT技術原理(一):BitFit、Prefix Tuning、Prompt Tuning
4、P-Tuning
論文地址:https://arxiv.org/pdf/2103.10385.pdf
代碼地址:https://github.com/THUDM/P-tuning
? ? ? ?P-Tuning和Prompt-Tuning幾乎是同時出現,思路也很接近。之前很多Prompt設計都是人工的,不僅構造難度大,而且性能也不太穩定,很可能創建出導致性能大幅下降的對抗性提示。比如GPT3采用人工構造的模版來做上下文學習(in context learning),但人工設計的模版的變化特別敏感,加一個詞或者少一個詞,或者變動位置都會造成比較大的變化,如下圖所示:

? ? ? ?鑒于這些問題,最近的工作重點是自動搜索離散提示,也取得了一定的效果。然而,由于神經網絡本質上是連續的,離散的提示可能是次優的。在這項工作中,作者提出了一種新方法——P-tuning,在連續空間中自動搜索提示。P-tuning 利用很少的連續自由參數來作為預訓練語言模型輸入的提示,并使用梯度下降作為離散提示搜索的替代方法來優化連續提示。
作者認為直接通過虛擬token引入prompt存在兩個問題:
- 離散性:如果用預訓練詞表的embedding初始化,經過預訓練的詞在空間分布上較稀疏,微調的幅度有限,容易陷入局部最優。這里到底是局部最優還是有效信息prior其實很難分清
- 整體性:多個token的連續prompt應該相互依賴作為一個整體
? ? ? 針對這兩個問題,作者使用雙向LSTM+2層MLP來對prompt進行表征, 這樣LSTM的結構提高prompt的整體性,Relu激活函數的MLP提高離散型。這樣更新prompt就是對應更新整個lstm+MLP部分的Prompt Encoder。下面是p-tuning和離散prompt的對比
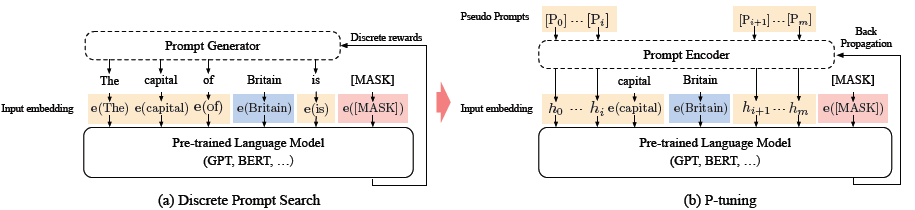
? ? ? ?相比Prefix Tuning,P-Tuning加入的可微virtual token,但僅限于輸入層,沒有在每一層都加;另外,virtual token的位置也不一定是前綴,插入的位置是可選的。這里的出發點實際是把傳統人工設計模版中的真實token替換成可微的virtual token。
? ? ? 在知識探測任務中,默認是固定LM只微調prompt。效果上P-tuning對GPT這類單項語言模型的效果提升顯著,顯著優于人工構建模板和直接微調,使得GPT在不擅長的知識抽取任務中可以BERT的效果持平。
局限性:
- 可解釋性差:這是所有連續型prompt的統一問題;
- 收斂更慢: 更少的參數想要挖掘更大模型的知識,需要更復雜的空間搜索;
- 可能存在過擬合:只微調prompt,理論上是作為探針,但實際模型是否真的使用prompt部分作為探針,而不是直接去擬合任務導致過擬合是個待確認的問題;
- 微調可能存在不穩定性:prompt-tuning和p-tuning的github里都有提到結果在SuperGLUE上無法復現的問題;
5、P-Tuning v2
論文地址:https://arxiv.org/pdf/2110.07602.pdf
代碼地址:https://github.com/THUDM/P-tuning-v2
? ? ? ? 之前提到的Prompt Tuning,是只凍結大語言模型的參數來優化連續Prompts,這樣可以大大減少每個任務的存儲和訓練時的內存使用,但是Prompt Tuning論文中表明當模型規模超過100億個參數時,提示優化可以與全量微調相媲美。但是對于那些較小的模型(從100M到1B),提示優化和全量微調的表現有很大差異,這大大限制了提示優化的適用性。雖然在GLUE和SuperGLUE 基準測試上表現出一定的優勢,然而在較難的硬序列標記任務(即序列標注)的有效性尚未得到驗證。
? ? ? ?基于此,作者提出了P-tuning v2,它利用深度提示優化(如:Prefix Tuning),對Prompt Tuning和P-Tuning進行改進,作為一個跨規模和NLU任務的通用解決方案。
? ? ? 與P-tuning相比,該方法在每一層都加入了Prompts tokens作為輸入,而不是僅僅加在輸入層,這帶來兩個方面的好處:
- 更多可學習的參數(從P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同時也足夠參數高效。
- 加入到更深層結構中的Prompt能給模型預測帶來更直接的影響。
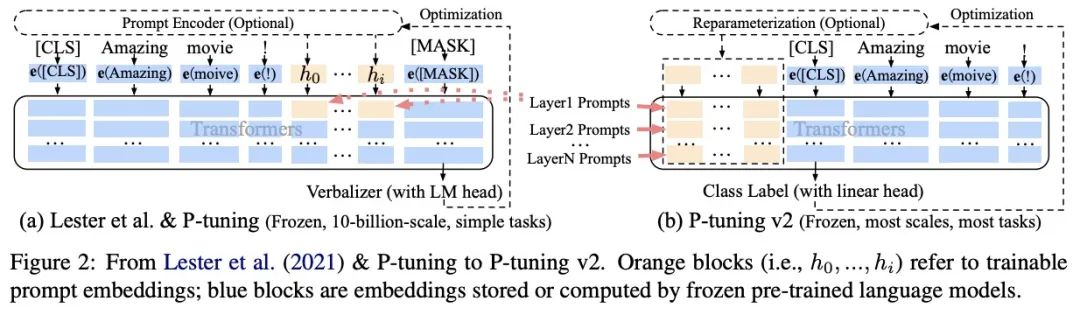
? ? ? 具體做法基本同Prefix Tuning,可以看作是將文本生成的Prefix Tuning技術適配到NLU任務中,然后做了一些改進:
- 移除重參數化的編碼器:以前的方法利用重參數化功能來提高訓練速度和魯棒性(如:Prefix Tuning中的MLP、P-Tuning中的LSTM))。在 P-tuning v2 中,作者發現重參數化的改進很小,尤其是對于較小的模型,同時還會影響模型的表現。
- 針對不同任務采用不同的提示長度:提示長度在提示優化方法的超參數搜索中起著核心作用。在實驗中,作者發現不同的理解任務通常用不同的提示長度來實現其最佳性能,這與Prefix-Tuning中的發現一致,不同的文本生成任務可能有不同的最佳提示長度。
- 引入多任務學習:先在多任務的Prompt上進行預訓練,然后再適配下游任務。多任務學習對我們的方法來說是可選的,但可能是相當有幫助的。一方面,連續提示的隨機慣性給優化帶來了困難,這可以通過更多的訓練數據或與任務相關的無監督預訓練來緩解;另一方面,連續提示是跨任務和數據集的特定任務知識的完美載體。實驗表明,在一些困難的序列任務中,多任務學習可以作為P-tuning v2的有益補充。
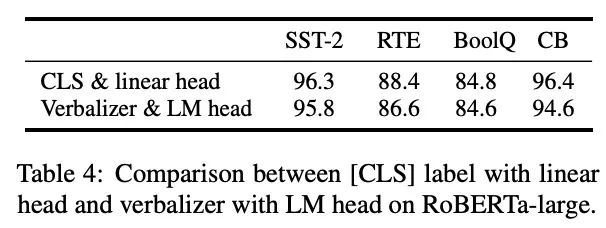
- 回歸傳統的分類標簽范式,而不是映射器:標簽詞映射器(Label Word Verbalizer)一直是提示優化的核心組成部分,它將one-hot類標簽變成有意義的詞,以利用預訓練語言模型頭。盡管它在few-shot設置中具有潛在的必要性,但在全數據監督設置中,Verbalizer并不是必須的,它阻礙了Prompt調優在需要無實際意義的標簽和句子嵌入的場景中的應用。因此,P-Tuning v2回歸傳統的CLS標簽分類范式,采用隨機初始化的分類頭(Classification Head)應用于tokens之上,以增強通用性,可以適配到序列標注任務,如下圖所示:






sd采樣方法詳解)
)

)






Unity開發Vision Pro——入門)


