Redis專題-隊列
首先,想一想 Redis 適合做消息隊列嗎?
1、消息隊列的消息存取需求是什么?redis中的解決方案是什么?
無非就是下面這幾點:
0、數據可以順序讀取
1、支持阻塞等待拉取消息
2、支持發布/訂閱模式
3、重新消費
4、消息不丟失
5、消息可堆積
那我們來看看redis怎么滿足這些需求
1.1、基于 List 的消息隊列解決方案
1.1.1、數據保證順序
List 本身就是按先進先出的順序對數據進行存取的,底層的實現就是一個「鏈表」,在頭部和尾部操作元素,時間復雜度都是 O(1),這意味著它非常符合消息隊列的模型。
生產者使用 LPUSH 發布消息:
127.0.0.1:6379> LPUSH mq 5
(integer) 1
127.0.0.1:6379> LPUSH mq 3
(integer) 2
消費者使用 RPOP 拉取消息:
127.0.0.1:6379> RPOP mq
5
127.0.0.1:6379> RPOP mq
3
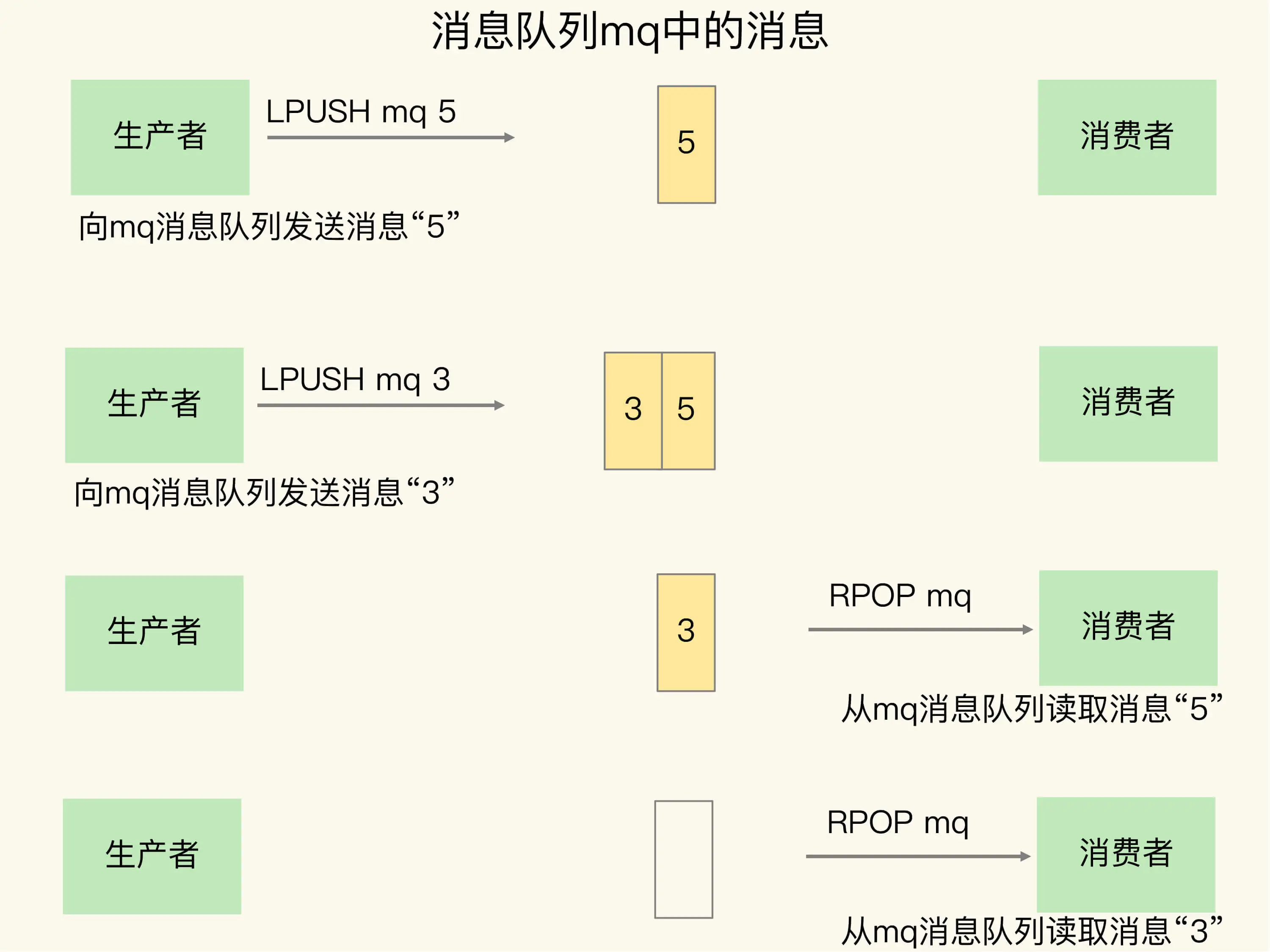
當隊列中已經沒有消息了,消費者在執行 RPOP 時,會返回 NULL。
127.0.0.1:6379> RPOP mq
(nil)
消費者讀取數據時,有一個潛在的性能風險點:
生產者寫入數據時,List 并不會主動通知消費者有新消息寫入。
如果消費者想要及時處理消息,需要在程序中不停地調用 RPOP 命令。
如果有新消息寫入,RPOP 命令就會返回結果,否則,RPOP 命令返回空值,再繼續循環。
// 偽代碼
while (true)
{var msg = redis.rpop("mq")if(msg == null)continue;handle(msg)
}
上述代碼中如果隊列為空,消費者依舊會頻繁拉取消息,這會造成「CPU 空轉」,不僅浪費 CPU 資源,還會對 Redis 造成壓力。
我們處理一下,當隊列為空時,我們可以「休眠」一會,再去嘗試拉取消息。
// 偽代碼
while (true)
{var msg = redis.rpop("mq")if(msg == null){Thread.Sleep(2000);continue;}handle(msg)
}
「CPU 空轉」解決了,但是有新的問題發生了:當消費者在休眠等待時有新消息,那么消費者處理新消息就會存在「延遲」。
那如何做,既能及時處理新消息,還能避免 CPU 空轉呢?
1.1.2、支持阻塞等待拉取消息
為了解決這個問題,Redis 提供了 BRPOP 命令。BRPOP 命令也稱為阻塞式讀取,客戶端在沒有讀到隊列數據時,自動阻塞,直到有新的數據寫入隊列,再開始讀取新數據。和消費者程序自己不停地調用 RPOP 命令相比,這種方式能節省 CPU 開銷。(這里的 B 指的是阻塞(Block)。)
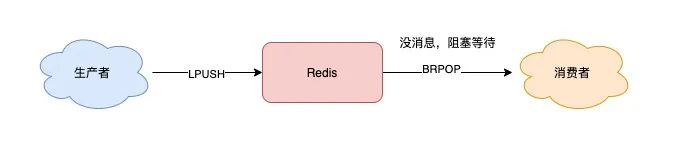
使用 BRPOP 這種阻塞式方式拉取消息時,還支持傳入一個「超時時間」,如果設置為 0,則表示不設置超時,直到有新消息才返回,否則會在指定的超時時間后返回 NULL
// 偽代碼
while (true)
{// 沒消息阻塞等待,0表示不設置超時時間var msg = redis.brpop("mq",0)if(msg == null)continue;handle(msg)
}
注意:如果設置的超時時間太長,這個連接太久沒有活躍過,可能會被 Redis Server 判定為無效連接,之后 Redis Server 會強制把這個客戶端踢下線。所以,采用這種方案,客戶端要有重連機制。
1.1.3、發布/訂閱模式
不支持。
1.1.4、重新消費
不支持。
但是在業務使用唯一ID等方式實現,消費ID后做判斷是否處理過,使對于同一條消息處理結果都是一致的,保證冪等性。
1.1.5、消息不丟失
僅消費端不丟失。
List 類型提供了 BRPOPLPUSH 命令,這個命令的作用是讓消費者程序從一個 List 中讀取消息,同時,Redis 會把這個消息再插入到另一個 List(可以叫作備份 List)留存。
如果消費者程序讀了消息但沒能正常處理,等它重啟后,就可以從備份 List 中重新讀取消息并進行處理了。
1.1.6、消息堆積
不可堆積。
如果消費較慢,List 中的消息越積越多,redis內存壓力會越來越大。
而且List本身也不支持消費組,不能使用多個消費端消費。
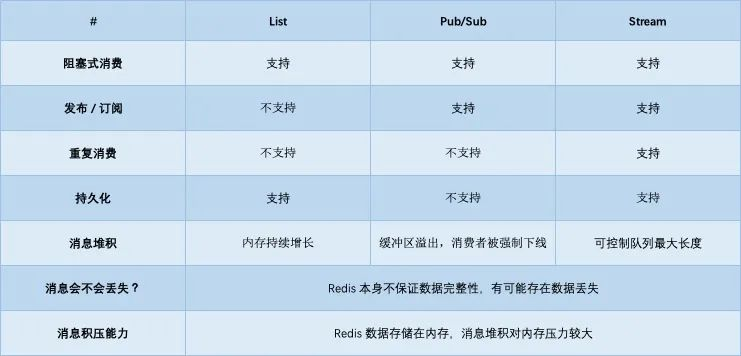
1.1.7、小結
| 需求 | LIST |
|---|---|
| 數據保證順序 | 支持。使用LPUSH/RPOP |
| 支持阻塞等待拉取消息 | 支持。使用BRPOP |
| 支持發布 / 訂閱模式 | 不支持 |
| 重復消費 | 不支持。但是可以自行實現全局唯一ID |
| 消息不丟失 | 不完全。消費端算是不丟失,BRPOPLPUSH |
| 消息堆積 | 不支持。內存持續增長 |
簡單的業務場景,可以使用list。
但如果想要有多個生產者和消費者,那么可以繼續往下看。
1.2、基于 Pub/Sub 的消息隊列解決方案
Redis 專門是針對「發布/訂閱」( PUBLISH / SUBSCRIBE) 這種隊列模型設計的。
可以解決重復消費問題,可以多組生產者、消費者場景。
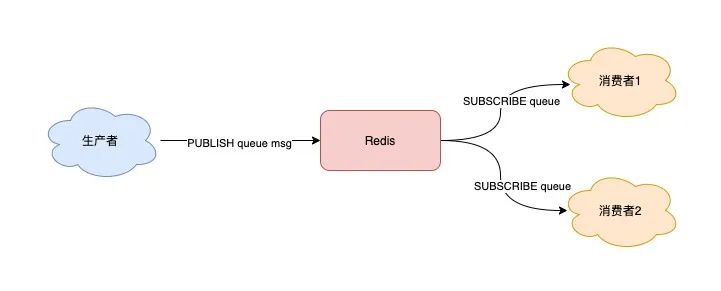
使用 Pub/Sub 這種方案,既支持阻塞式拉取消息,還很好地滿足了多組消費者,消費同一批數據的業務需求。
除此之外,Pub/Sub 還提供了「匹配訂閱」模式,允許消費者根據一定規則,訂閱「多個」自己希望的隊列。
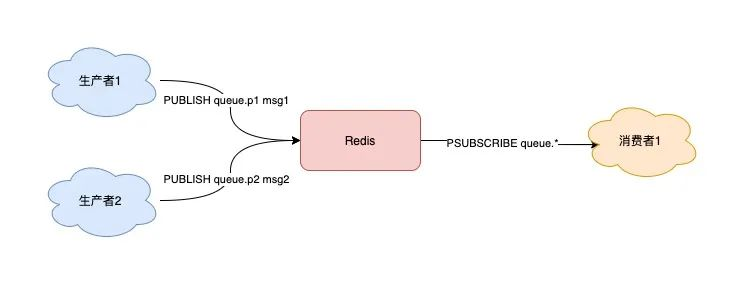
可以看到,Pub/Sub 最大的優勢就是,支持多組生產者、消費者處理消息。
缺點就是:丟數據。
Pub/Sub 沒有基于任何數據類型,也沒有做任何的數據存儲(不會寫入到 RDB 和 AOF 中),單純的建立轉發通道,把符合規則的數據轉發到另外一端,一切都是實時轉發的。
如果消費者異常,那么再次上線只能接受新的消息,在此期間生產者找不到消費者就會丟棄數據。
使用 Pub/Sub 時,注意:消費者必須先訂閱隊列,生產者才能發布消息,否則消息會丟失。
消息積壓時消息也可能會消息丟失或者消費失敗,Pub/Sub的實現上就是在server的內存上給訂閱的消費者分配了一個buffer。
生產者發布消息不斷寫入buffer中,當消息積壓時,buffer占用內存會持續增長,如果突破了buffer配置的上線,那么消費者就會被踢下線,導致消費失敗,數據丟失。
緩沖區的默認配置:client-output-buffer-limit pubsub 32mb 8mb 60。
32mb:緩沖區一旦超過 32MB,Redis 直接強制把消費者踢下線.
8mb + 60:緩沖區超過 8MB,并且持續 60 秒,Redis 也會把消費者踢下線
List 拉數據,Pub/Sub推數據。
Pub/Sub 的優缺點:
1、支持發布 / 訂閱,支持多組生產者、消費者處理消息
2、消費者下線,數據會丟失
3、不支持數據持久化,Redis 宕機,數據也會丟失
4、消息堆積,緩沖區溢出,消費者會被強制踢下線,數據也會丟失
哨兵集群和 Redis 實例通信時,采用了 Pub/Sub 的方案,因為哨兵正好符合即時通訊的業務場景。
很明顯Pub/Sub不是我們想要的消息隊列,繼續往下看
1.3、基于 Streams 的消息隊列解決方案
Streams 是 Redis 專門為消息隊列設計的數據類型,它提供了豐富的消息隊列操作命令。
XADD:插入消息,保證有序,可以自動生成全局唯一ID
XREAD:用于讀取消息,可以按ID讀取數據
XREADGROUP:按消費組形式讀取消息
XPENDING:可以用來查詢每個消費組內所有消費者已讀取但尚未確認的消息
XACK:用于向消息隊列確認消息處理已完成
生產者推消息:
// *表示讓Redis自動生成消息ID
127.0.0.1:6379> XADD queue * name zhangsan
"1618469123380-0"
127.0.0.1:6379> XADD queue * name lisi
"1618469127777-0"
消費者拉消息:
XADD「*」表示讓 Redis 自動生成唯一的消息 ID
消息 ID 的格式是「時間戳-自增序號」(自增序號從0開始編號)
// 從開頭讀取5條消息,0-0表示從開頭讀取
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 0-0
1) 1) "queue"2) 1) 1) "1618469123380-0"2) 1) "name"2) "zhangsan"2) 1) "1618469127777-0"2) 1) "name"2) "lisi"
如果想繼續拉取消息,需要傳入上一條消息的 ID:
127.0.0.1:6379> XREAD COUNT 5 STREAMS queue 1618469127777-0
(nil)
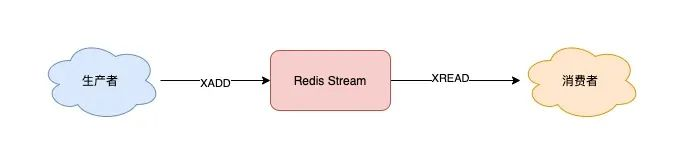
這就是Stream 最簡單的生產、消費。
1.3.1、數據保證順序
支持。
XADD插入消息,保證有序
1.3.2、支持阻塞等待拉取消息
支持。
在讀取消息時,只需要增加 BLOCK 參數即可。
// BLOCK 0 表示阻塞等待,不設置超時時間
127.0.0.1:6379> XREAD COUNT 5 BLOCK 0 STREAMS queue 1618469127777-0
這時,消費者就會阻塞等待,直到生產者發布新的消息才會返回。
1.3.3、發布/訂閱模式
支持。
Stream 通過以下命令完成發布訂閱:
XGROUP:創建消費者組
XREADGROUP:在指定消費組下,開啟消費者拉取消息
127.0.0.1:6379> XADD queue * name zhangsan
"1618470740565-0"
127.0.0.1:6379> XADD queue * name lisi
"1618470743793-0"
// 創建消費者組1,0-0表示從頭拉取消息
127.0.0.1:6379> XGROUP CREATE queue group1 0-0
OK
// 創建消費者組2,0-0表示從頭拉取消息
127.0.0.1:6379> XGROUP CREATE queue group2 0-0
OK
第一個消費組開始消費:
// group1的consumer開始消費,>表示拉取最新數據
127.0.0.1:6379> XREADGROUP GROUP group1 consumer COUNT 5 STREAMS queue >
1) 1) "queue"2) 1) 1) "1618470740565-0"2) 1) "name"2) "zhangsan"2) 1) "1618470743793-0"2) 1) "name"2) "lisi"
同樣地,第二個消費組開始消費:
// group2的consumer開始消費,>表示拉取最新數據
127.0.0.1:6379> XREADGROUP GROUP group2 consumer COUNT 5 STREAMS queue >
1) 1) "queue"2) 1) 1) "1618470740565-0"2) 1) "name"2) "zhangsan"2) 1) "1618470743793-0"2) 1) "name"2) "lisi"
我們可以看到,這 2 組消費者,都可以獲取同一批數據進行處理了。
通過創建消費組的形式達到訂閱的目的。
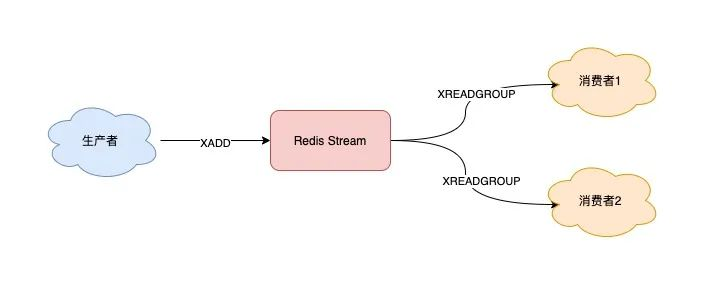
1.3.4、重新消費
支持。
上面拉取消息時用到了消息 ID,這里為了保證重新消費,也要用到這個消息 ID。
當一組消費者處理完消息后,需要執行 XACK 命令告知 Redis,這時 Redis 就會把這條消息標記為「處理完成」。
// group1下的 1618472043089-0 消息已處理完成
127.0.0.1:6379> XACK queue group1 1618472043089-0
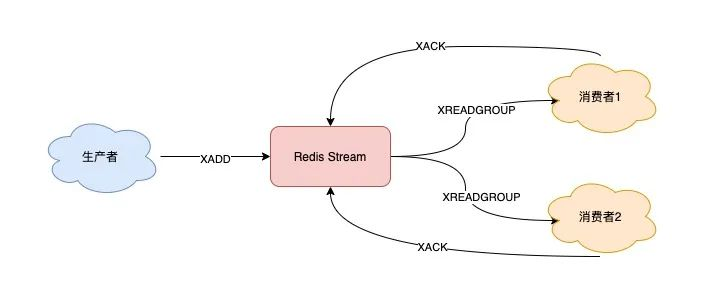
如果消費者異常宕機,肯定不會發送 XACK,那么 Redis 就會依舊保留這條消息。
待這組消費者重新上線后,Redis 就會把之前沒有處理成功的數據,重新發給這個消費者。這樣一來,即使消費者異常,也不會丟失數據了。
// 消費者重新上線,0-0表示重新拉取未ACK的消息
127.0.0.1:6379> XREADGROUP GROUP group1 consumer1 COUNT 5 STREAMS queue 0-0
// 之前沒消費成功的數據,依舊可以重新消費
1) 1) "queue"2) 1) 1) "1618472043089-0"2) 1) "name"2) "zhangsan"2) 1) "1618472045158-0"2) 1) "name"2) "lisi"
1.3.5、消息不丟失
Stream 是新增加的數據類型,它與其它數據類型一樣,每個寫操作,也都會寫入到 RDB 和 AOF 中。
我們只需要配置好持久化策略,這樣的話,就算 Redis 宕機重啟,Stream 中的數據也可以從 RDB 或 AOF 中恢復回來。
1.3.6、消息堆積
支持,但有長度限制。
當消息隊列發生消息堆積時,一般只有 2 個解決方案:
1、生產者限流:避免消費者處理不及時,導致持續積壓
2、丟棄消息:中間件丟棄舊消息,只保留固定長度的新消息
Redis 在實現 Stream 時,采用了第 2 個方案。
在發布消息時,你可以指定隊列的最大長度,防止隊列積壓導致內存爆炸。
// 隊列長度最大10000
127.0.0.1:6379> XADD queue MAXLEN 10000 * name zhangsan
"1618473015018-0"
當隊列長度超過上限后,舊消息會被刪除,只保留固定長度的新消息。
這么來看,Stream 在消息積壓時,如果指定了最大長度,還是有可能丟失消息的。
除了以上介紹到的命令,Stream 還支持查看消息長度(XLEN)、查看消費者狀態(XINFO)等命令
1.3.7、小結
| 需求 | Stream |
|---|---|
| 數據保證順序 | 支持 |
| 支持阻塞等待拉取消息 | 支持 |
| 支持發布 / 訂閱模式 | 支持 |
| 重復消費 | 支持 |
| 消息不丟失 | 支持 |
| 消息堆積 | 支持 |
既然它的功能這么強大,這是不是意味著,Redis 真的可以作為專業的消息隊列中間件來使用呢?
2、與專業的消息隊列對比
一個專業的消息隊列,必須要做到兩大塊:
1、消息不丟
2、消息可堆積
消息隊列,其實就分為三大塊:生產者、隊列中間件、消費者。
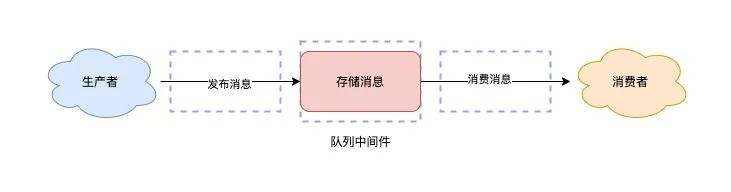
2.1、如何保證不丟消息?
2.1.1、生產者會不會丟失數據?
生產者丟失:
1、消息沒法出去,網絡原因或者其他原因,中間件返回失敗
2、不確定是否發送成功:網絡原因等導致發布超時,數據可能已經發送成功,但讀取響
應超時
第一種情況,重發即可。
第二種情況,因為不知道是否成功,為了避免丟失,就只能也重試發送到成功為止。
生產者一般設定重試次數,超過上限次數需記錄日志,發送警報。
是的,為了不丟失,可以接受重復發送,在消費端就需要做一些邏輯判斷了,業務可能需要保證冪等性。
所以,redis或者其他中間件隊列,都可以在生產者上保證不丟失數據。
2.1.2、消費者會不會丟失數據?
消費者拿到消息后,還沒處理完成,就異常宕機了,那消費者還能否重新消費失敗的消息?
要解決這個問題,消費者在處理完消息后,必須「告知」隊列中間件,隊列中間件才會把標記已處理,否則仍舊把這些數據發給消費者。
這種方案需要消費者和中間件互相配合,才能保證消費者這一側的消息不丟。
無論是 Redis 的 Stream,還是專業的隊列中間件,例如 RabbitMQ、Kafka,其實都是這么做的。
所以,從這個角度來看,Redis 也是合格的。
2.1.3、隊列中間件會不會丟失數據?
上面的問題只要客戶端和服務端配合好,就能保證生產端、消費端都不丟消息。
但是,如果隊列中間件本身就不可靠呢?
在這個方面,Redis 其實沒有達到要求。
Redis 在以下 2 個場景下,都會導致數據丟失。
1、AOF 持久化配置為每秒寫盤,但這個寫盤過程是異步的,Redis 宕機時會存在數據丟失的可能
2、主從復制也是異步的,主從切換時,也存在丟失數據的可能(從庫還未同步完成主庫發來的數據,就被提成主庫)
基于以上原因我們可以看到,Redis 本身的無法保證嚴格的數據完整性。
RabbitMQ 或 Kafka 這類專業的隊列中間件,在使用時,一般是部署一個集群,生產者在發布消息時,隊列中間件通常會寫「多個節點」,以此保證消息的完整性。這樣一來,即便其中一個節點掛了,也能保證集群的數據不丟失。
Redis 的定位則不同,它的定位更多是當作緩存來用,它們兩者在這個方面肯定是存在差異的。
2.1.4、消息積壓怎么辦?
Redis 的數據都存儲在內存中,這就意味著一旦發生消息積壓,則會導致 Redis 的內存持續增長,如果超過機器內存上限,就會面臨被 OOM 的風險。
Redis 的 Stream 提供了可以指定隊列最大長度的功能,就是為了避免這種情況發生。
但 Kafka、RabbitMQ 這類消息隊列就不一樣了,它們的數據都會存儲在磁盤上,磁盤的成本要比內存小得多,當消息積壓時,無非就是多占用一些磁盤空間,相比于內存,在面對積壓時也會更加「坦然」。
把 Redis 當作隊列來使用時,始終面臨的 2 個問題:
1、Redis 本身可能會丟數據,
2、面對消息積壓 Redis 內存資源緊張.
如果你的業務場景足夠簡單,對于數據丟失不敏感,而且消息積壓概率比較小的情況下,把 Redis 當作隊列是完全可以的。
而且,Redis 相比于 Kafka、RabbitMQ,部署和運維也更加輕量。
如果你的業務場景對于數據丟失非常敏感,而且寫入量非常大,消息積壓時會占用很多的機器資源,那么我建議你使用專業的消息隊列中間件。
3、額外補充
3.1、延遲隊列
應用場景:
1、訂單超時未支付,關閉訂單退還庫存
2、訂單完成5天后沒有評論自動好評
3、用戶并發量大,延后發送郵件短信
4、…
3.1.1實現方式
-
ZSET + 定時輪詢
- zset支持高性能的 score 排序,且去重
- 內存上進行操作的,速度非常快
- 注意多進程爭搶,使用lua將zrangebyscore和zrem進行原子化
-
監聽key(不建議)
- WATCH 可以鑒定單個或者多個key的變化情況
- 數量較大時,監聽會滯后(過期事件是在Redis服務器刪除密鑰時產生的,而不是在理論上存活時間達到零時產生的)
參考、復制、學習、引用與:
redis官網
請勿過度依賴 Redis 的過期監聽
把Redis當作隊列來用,真的合適嗎?
消息隊列的考驗:Redis有哪些解決方案?
密碼加密網絡安全)






))詳細介紹】)











![應用程序運行報錯:First section must be [net] or [network]:No such file or directory](http://pic.xiahunao.cn/應用程序運行報錯:First section must be [net] or [network]:No such file or directory)