人工智能(AI)正越來越多地融入科學發現,以增強和加速研究,幫助科學家提出假設、設計實驗、收集和解釋大型數據集,并獲得僅靠傳統科學方法可能無法實現的洞察力。
過去十年間,AI取得了巨大的突破。其中就包括自監督學習和幾何深度學習(Geometric Deep Learning):前者允許在大量無標簽數據上訓練模型,后者則利用有關科學數據結構的知識來提高模型的準確性和效率;還有生成式人工智能方法:它可以通過分析包括圖像和序列在內的各種數據模式,創造出小分子藥物和蛋白質等設計。
這些方法在整個科學過程中為科學家提供了許多幫助;不過,盡管取得了這些進步,但仍然存在的核心問題。人工智能工具的開發者和用戶都需要更好地了解這些方法何時需要改進,數據質量差、管理不善帶來的挑戰依然存在。
這些問題橫跨各個科學學科,因此,現在需要開發能夠促進科學理解或自主獲取科學理解的基礎算法方法——這也是人工智能創新的關鍵重點領域。

如何收集、轉換、理解數據為形成科學見解和理論奠定了基礎;而2010 年代初興起的深度學習極大地擴展了這些科學發現過程的范圍和雄心。
現在,人工智能(AI)越來越多地應用于各個科學學科,以整合海量數據集、完善測量、指導實驗、探索與數據相匹配的理論空間,以及提供與科學工作流程相結合的可操作的可靠模型,從而實現自主發現。
數據收集和分析是科學理解和發現的基礎,也是科學的兩大核心目標 ;而定量方法和新興技術,從顯微鏡等物理儀器到引導等研究技術,長期以來一直被用于實現這些目標。20 世紀 50 年代引入的數字化技術為計算機在科學研究中的普遍應用鋪平了道路;自 2010 年代以來,數據科學的興起使人工智能能夠從大型數據集中識別出與科學相關的模式,從而提供有價值的指導。
盡管科學實踐和程序在科學研究的各個階段各不相同,但人工智能算法的發展卻跨越了傳統上相互孤立的學科:這些算法可以加強科學研究的設計和執行。它們通過優化參數和功能,自動收集、可視化和處理數據,探索候選假設的廣闊空間以形成理論,以及生成假設并估計其不確定性以建議相關實驗,正在逐漸成為研究人員不可或缺的工具。
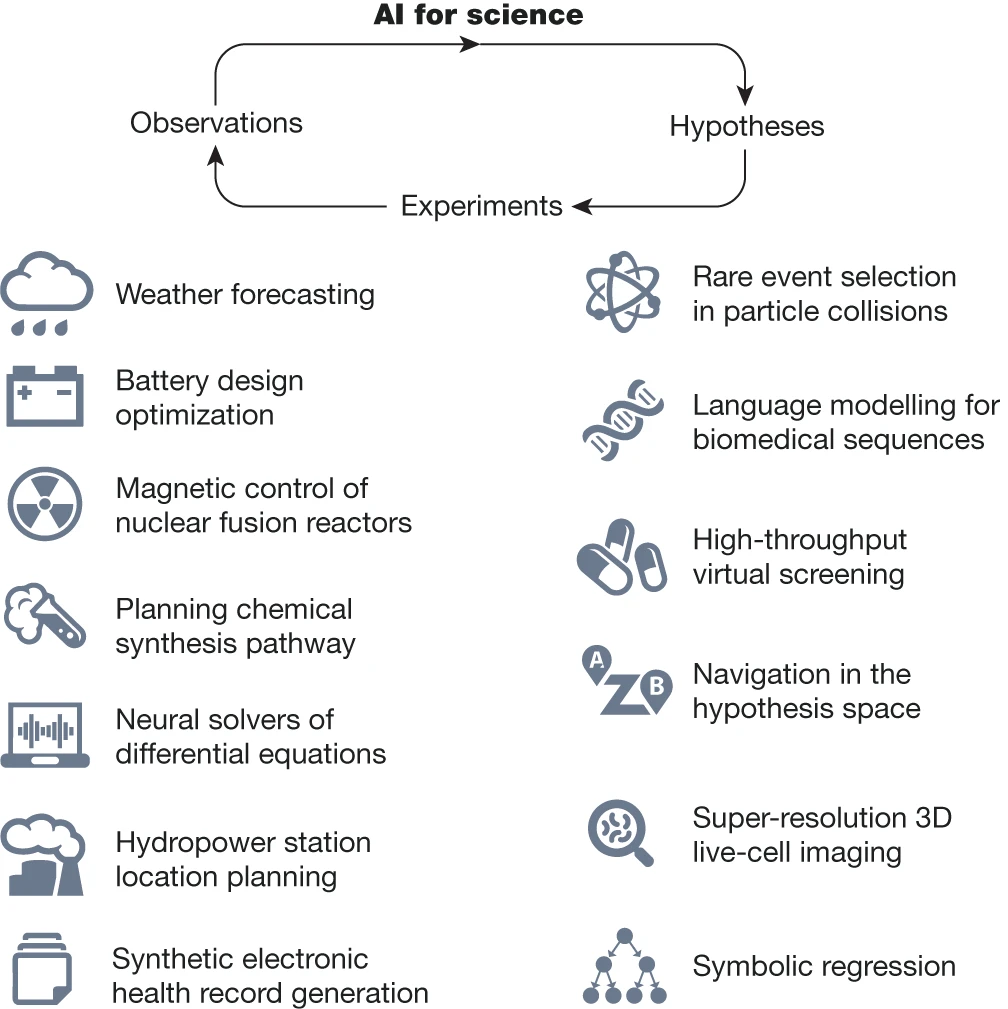
人工智能時代的科學。科學發現是一個多方面的過程,涉及幾個相互關聯的階段,包括假設形成、實驗設計、數據收集和分析。人工智能可以在這一過程的每個階段增強和加速研究,從而重塑科學發現。這里展示的原則和說明性研究突出了人工智能對提高科學認識和發現的貢獻。
自 2010 年代初以來,人工智能方法的威力已大大增強,這是因為有了快速、大規模并行計算和存儲硬件(圖形處理單元和超級計算機)的幫助,再加上新算法的支持,人們可以獲得大量數據集。
后者包括深度表征學習,特別是多層神經網絡,能夠識別基本、緊湊的特征,同時解決科學問題中的多項任務。
- 其中,幾何深度學習已被證明有助于整合科學知識,這些知識以物理關系、先驗分布、約束條件和其他復雜描述符(如分子中原子的幾何形狀)的緊湊數學陳述的形式呈現。
- 自我監督學習使在有標簽或無標簽數據上訓練的神經網絡能夠將所學表征遷移到標簽示例較少的不同領域,例如,通過預訓練大型基礎模型并使其適應于解決不同領域的各種任務。
- 此外,生成模型可以估計復雜系統的基礎數據分布,并支持新的設計。
- 與人工智能的其他用途不同,強化學習方法=通過探索許多可能的場景,并根據所考慮實驗的預期信息增益等指標為不同行動分配獎勵,從而找到環境的最佳策略。
在人工智能驅動的科學發現中,可以利用適當的歸納偏差將科學知識納入人工智能模型,歸納偏差是將結構、對稱性、約束條件和先驗知識作為緊湊數學語句的假設。然而,應用這些法則可能會導致方程式過于復雜,人類即使使用傳統的數值方法也無法求解。
一種新出現的方法是將科學知識納入人工智能模型,包括基本方程信息,如物理定律或蛋白質折疊中的分子結構和結合原理。這種歸納偏差可以減少達到相同準確度所需的訓練實例數量,并將分析擴展到廣闊的未探索科學假設空間,從而增強人工智能模型。
與人類利用人工智能的其他領域相比,利用人工智能進行科學創新和發現面臨著獨特的挑戰。最大的挑戰之一是科學問題中假設空間的廣闊性,使得系統性探索變得不可行。
例如,在生物化學領域,估計有 1060 種類似藥物的分子可供探索。人工智能系統有可能通過加速流程和提供接近實驗精確度的預測來徹底改變科學工作流程。然而,為人工智能模型獲取可靠注釋的數據集存在挑戰,這可能涉及耗時、耗資源的實驗和模擬。盡管存在這些挑戰,人工智能系統仍可實現高效、智能和高度自主的實驗設計和數據收集,人工智能系統可在人類監督下運行,對結果進行評估、評價和采取行動。這種能力促進了人工智能代理的發展,這些代理可在動態環境中持續互動,例如,可做出實時決策,為平流層氣球導航。
人工智能系統可以在解釋科學數據集和從科學文獻中概括性地提取關系和知識方面發揮重要作用。最近的研究結果表明,無監督語言人工智能模型有潛力捕捉復雜的科學概念,如元素周期表,并在功能材料被發現前幾年就預測其應用,這表明有關未來發現的潛在知識可能蘊藏在過去的出版物中。
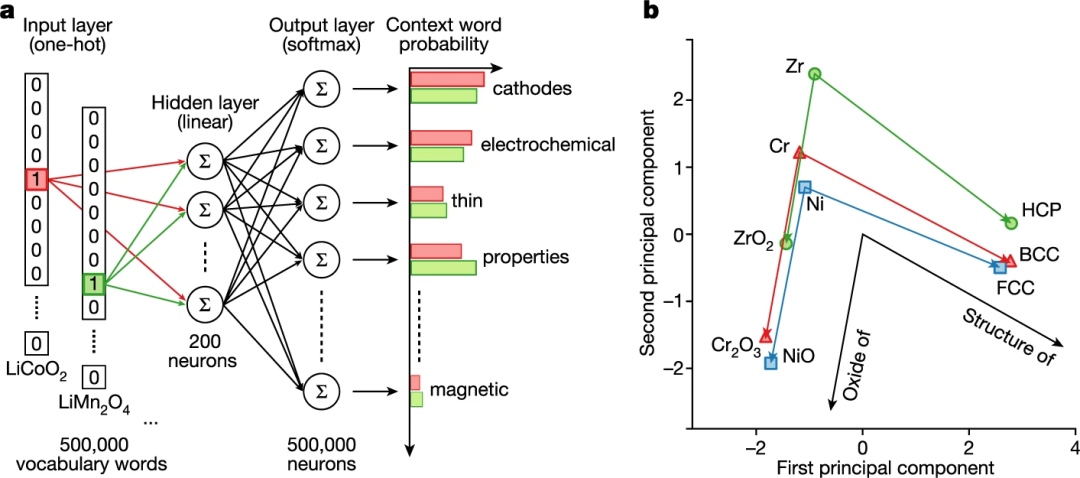
科學家將 Word2vec 的 Skip-gram 變體應用到文本語料庫中,該變體被訓練來預測出現在目標單詞附近的上下文單詞。結果證明,無監督方法可以在材料發現前幾年推薦用于功能應用的材料。
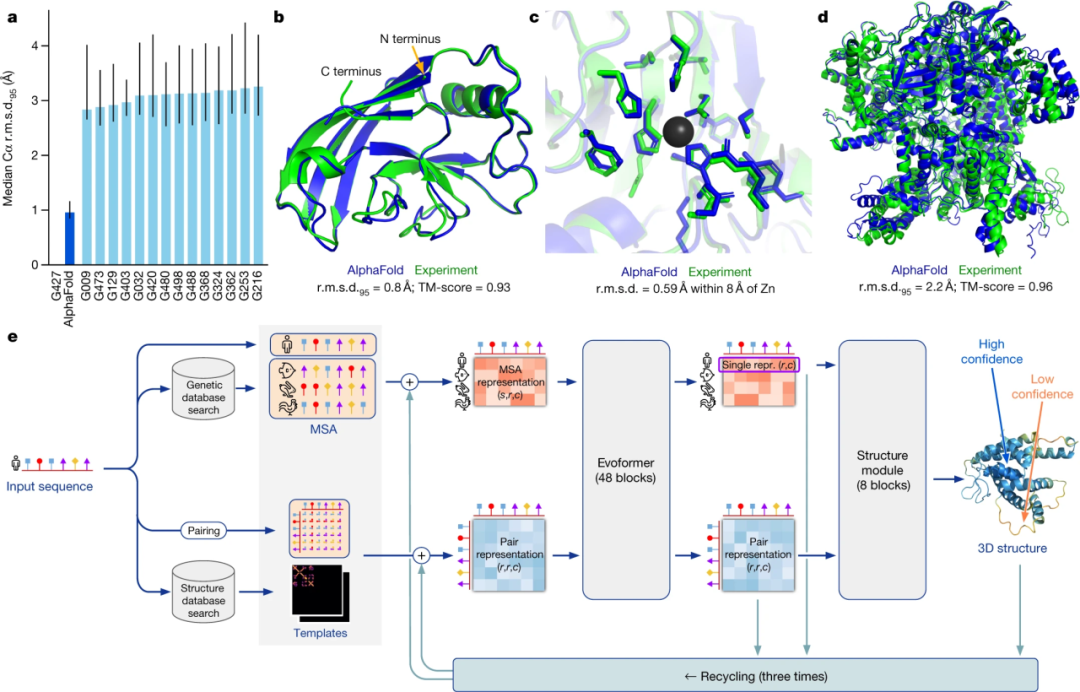
AlphaFold 可生成高度精確的蛋白質結構
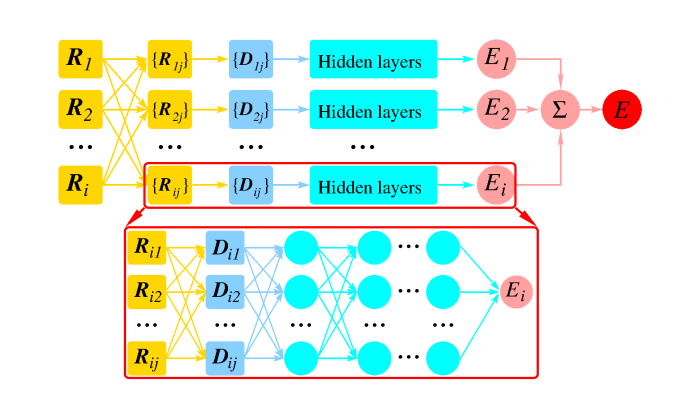
科學家引入了一種分子模擬方案——具有量子力學準確性的可擴展模型,基于由從頭數據訓練的精心設計的深度神經網絡生成的多體勢和原子間力。
最近取得的進展,包括成功揭示了已有 50 年歷史的蛋白質折疊問題和人工智能驅動的數百萬粒子分子系統模擬 ,都證明了人工智能在解決具有挑戰性的科學問題方面的潛力。然而,在取得重大發現的同時,“人工智能促進科學(AI4Science)”這一新興領域也面臨著巨大挑戰。與任何新技術一樣,AI4Science 的成功取決于我們是否有能力將其融入日常實踐并了解其潛力和局限性。
不過,我們也無需過度擔憂這些挑戰:在科學發現中廣泛采用人工智能的障礙包括發現過程每個階段特有的內部和外部因素,以及對方法、理論、軟件和硬件的實用性和潛在濫用的擔憂。

實驗平臺收集的數據集規模和復雜程度不斷增加,導致科學研究越來越依賴實時處理和高性能計算,以選擇性地存儲和分析高速生成的數據。
1)數據選擇
典型的粒子碰撞實驗每秒產生超過 100 TB 的數據。這類科學實驗正在挑戰現有數據傳輸和存儲技術的極限。在這些物理實驗中,99.99% 以上的儀器原始數據都是“背景事件(background event)”,必須實時檢測并丟棄,以控制數據傳輸速率。
為了識別罕見事件、便于未來的科學研究,深度學習方法用搜索離群信號的算法取代了預先編程的硬件事件觸發器,以檢測壓縮過程中可能遺漏的意外或罕見現象。背景過程可使用深度自動編碼器生成模型。自動編碼器會為以前未見過的、不屬于背景分布的信號(罕見事件)返回較高的損失值(異常得分)。
與有監督異常檢測不同,無監督異常檢測不需要注釋,已廣泛應用于物理學、神經科學、地球科學、海洋學和天文學。
2)數據標注
訓練有監督模型需要帶有注釋標簽的數據集,這些標簽可提供有監督信息,以指導模型訓練,并根據輸入估計目標變量的函數或條件分布。
偽標注和標簽傳播是替代費力的數據標注的誘人選擇,只需一小部分準確的標注,就能對海量無標注數據集進行自動標注。在生物學領域,為新表征的分子分配功能和結構標簽的技術對于監督模型的下游訓練至關重要,因為實驗生成標簽非常困難。
例如,盡管下一代測序技術不斷發展,但只有不到 1%的測序蛋白質標注了生物學功能。另一種數據標注策略是利用在人工標注數據上訓練的代理模型來標注未標注的樣本,并利用這些預測的偽標簽來監督下游預測模型。相比之下,標簽傳播(label propagation)則是通過基于特征嵌入構建的相似性圖將標簽擴散到未標記的樣本中。除自動標注外,主動學習還能確定需要人工標注的信息量最大的數據點或需要進行的信息量最大的實驗。通過這種方法,可以用較少的專家提供的標簽來訓練模型。
數據標注的另一種策略是利用領域知識制定標注規則。
3)數據生成
隨著訓練數據集的質量、多樣性和規模提高,深度學習的性能也在提高。創建更好模型的有效方法是通過自動數據增強和深度生成模型生成額外的合成數據點來增強訓練數據集。
除了人工設計此類數據擴增外,強化學習方法還能發現一種自動數據擴增策略:這種策略既靈活又與下游模型無關。深度生成模型,包括變分自編碼器、生成對抗網絡、
標準化流(normalizing flows)和擴散模型,可以學習底層數據分布,并從優化的分布中采樣訓練點。
生成對抗網絡已被證明可用于科學圖像,因為它們可以合成許多領域的逼真圖像,包括粒子碰撞事件、病理切片、胸部 X 射線、磁共振對比、三維(3D)材料微觀結構、蛋白質功能以及基因序列。概率編程是生成模型中的一種新興技術,它將數據生成模型表示為計算機程序。
4)數據細化
超高分辨率激光和無創顯微鏡系統等精密儀器可直接測量物理量或通過計算現實世界中的物體進行間接測量,從而得出高度精確的結果。
人工智能技術大大提高了測量分辨率、降低了噪音、消除了測量圓度的誤差,從而實現了各站點(site)一致的高精度。人工智能在科學實驗中的應用實例包括將黑洞等時空區域可視化、捕捉物理粒子碰撞、提高活細胞圖像的分辨率以及更好地檢測不同生物環境中的細胞類型。
深度卷積方法利用頻譜反褶積(spectral deconvolution)、靈活的稀疏性(sparsity)和生成能力等算法上的進步,可以將較差的時空分辨測量結果轉化為高質量、超分辨和結構化圖像。
去噪是各種科學學科中一項重要的人工智能任務,包括從噪聲中區分出相關信號并學習如何去除噪聲。去噪自動編碼器(DAE)可以將高維輸入數據投射到更緊湊的基本特征表示中。這些自動編碼器可最大限度地減少未損壞輸入數據點與根據噪聲損壞版本的壓縮表示重建的輸入數據點之間的差異。其他形式的分布學習自動編碼器,如變分自編碼器(VAE)也經常被使用:變分自編碼器通過潛在自編碼學習隨機表示,保留基本數據特征的同時忽略非必要的變異源(variation),可能代表隨機噪聲。
例如,在單細胞基因組學中,自動編碼器優化了數百萬個細胞中基于計數的基因激活向量,通常用于改進蛋白質-RNA 表達分析。

深度學習可以提取不同抽象程度的科學數據的有意義表征,并對其進行優化,通常通過端到端學習來指導研究。高質量的表征應盡可能多地保留數據信息,同時保持簡單易懂。有科學意義的表征應結構緊湊、具有鑒別性、能區分潛在的“變異因素(variation)”,并能編碼可在多項任務中通用的潛在機制。
1)幾何先驗
由于幾何和結構在科學領域發揮著核心作用,在學習表征中整合幾何先驗已被證明是有效的。對稱是幾何學中一個被廣泛研究的概念。它可以用不變性和等差性來描述,以表示神經特征編碼器等數學函數在一組變換(如剛體動力學中的 SE(3) 組)下的行為。重要的結構特性,如分子體系的二級結構含量、溶劑可及性、殘基緊密度(residue compactness)和氫鍵模式,都與空間方向無關。
在科學圖像分析中,對象在圖像中平移時不會發生變化,這意味著圖像分割掩碼是平移等變的,因為當輸入像素平移時,它們會發生等效變化。通過增加訓練樣本,將對稱性納入模型可以使人工智能在使用有限的標記數據集(如三維核糖核酸和蛋白質結構)時受益匪淺,并且可以改善對輸入的外推預測:因為輸入與模型訓練期間遇到的輸入明顯不同。
2)幾何深度學習
圖神經網絡已成為在具有底層幾何和關系結構的數據集上進行深度學習的主要方法。從廣義上講,幾何深度學習涉及發現關系模式,并通過神經信息傳遞算法為神經網絡模型配備歸納偏差,明確利用以圖形和變換組的形式編碼的局部信息。
根據科學問題的不同,科學家們開發了各種圖表示法來捕捉復雜系統。方向性邊緣有助于玻璃系統的物理建模,帶有連接多個節點的邊緣的超圖被用于染色質結構的理解,在多模態圖上訓練的模型被用于創建基因組學中的預測模型,稀疏、不規則和高度關系圖被應用于許多大型強子對撞機物理任務,包括從探測器讀數中重建粒子以及區分物理信號與背景過程。
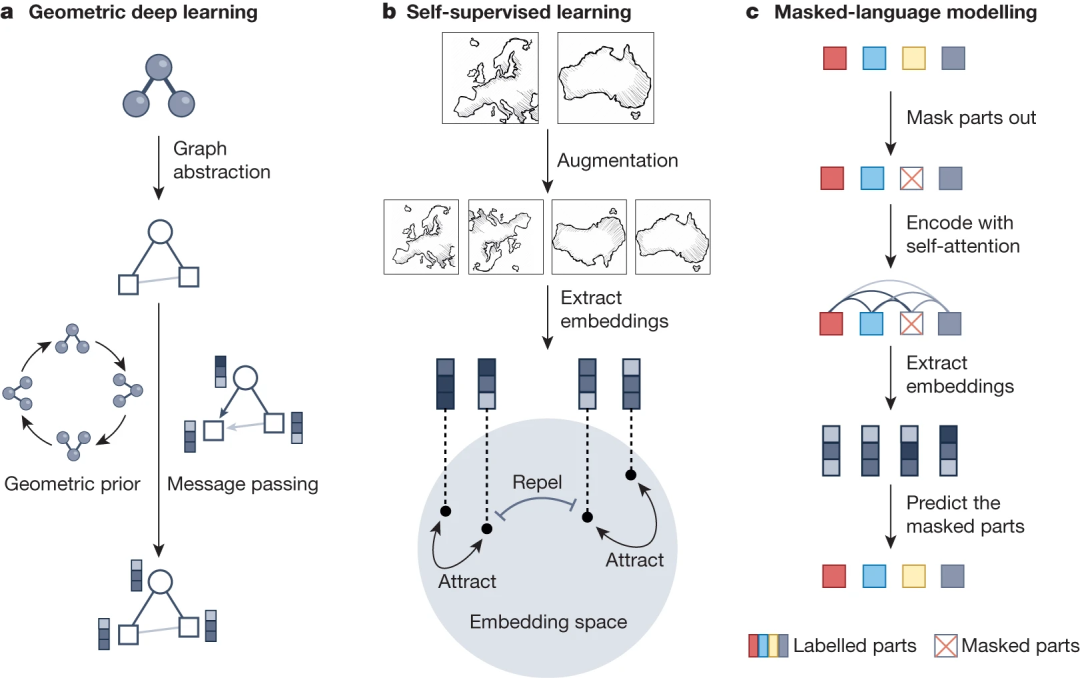
a)幾何深度學習通過利用圖和神經信息傳遞策略,整合了科學數據(如分子和材料)的幾何、結構和對稱性信息。這種方法通過沿圖中的邊交換神經信息來生成潛在表征(嵌入),同時考慮其他幾何先驗,如不變性和等差數列約束。因此,幾何深度學習可以將復雜的結構信息納入深度學習模型,從而更好地理解和處理底層幾何數據集。b)為了有效地表示衛星圖像等不同樣本,捕捉它們的相似性和差異性至關重要。自我監督學習策略(如對比學習)通過生成增強的對等物和對齊正對同時分離負對來實現這一目標。這種迭代過程增強了嵌入,從而產生了信息豐富的潛在表征,并在下游預測任務中取得了更好的表現。c)屏蔽語言建模能有效捕捉自然語言和生物序列等序列數據的語義。這種方法是將輸入的屏蔽元素輸入轉換器塊,其中包括預處理步驟,如位置編碼。自我注意機制由灰色線條表示,其顏色強度反映了注意權重的大小,它結合了非屏蔽輸入的表征,以準確預測屏蔽輸入。這種方法通過在輸入的許多元素中重復這一自動完成過程,產生高質量的序列表征。
3)自監督學習
當僅有少量標注樣本可用于模型訓練,或為特定任務標注數據的成本過高時,監督學習可能就不夠用了。在這種情況下,利用有標簽和無標簽數據可以提高模型性能和學習能力。
自監督學習是一種能讓模型學習數據集一般特征而無需依賴顯式標簽的技術。有效的自監督策略包括預測圖像的遮擋區域、預測視頻中過去或未來的幀,以及使用對比學習教模型區分相似和不相似的數據點。
自監督學習是一個關鍵的預處理步驟,它可以在大型無標簽數據集中學習可轉移的特征,然后在小型有標簽數據集中微調模型,以執行下游任務。這種預先訓練的模型對科學領域有廣泛的了解,是通用的預測器,可適用于各種任務;從而提高標簽效率,超越純監督方法。
4)語言建模
屏蔽語言建模是自然語言和生物序列自監督學習的常用方法。
將原子或氨基酸(標記)排列成結構以產生分子和生物功能,類似于字母組成單詞和句子以定義文檔的含義。隨著自然語言和生物序列處理的不斷發展,它們也在相互促進。在訓練過程中,目標是預測序列中的下一個標記,而在基于掩碼的訓練中,自監督任務是利用雙向序列上下文恢復序列中被掩碼的標記。
蛋白質語言模型可以對氨基酸序列進行編碼,以捕捉結構和功能特性并評估病毒變體的進化適應性。這些表征可用于各種任務,從序列設計到結構預測;在處理生化序列時,化學語言模型有助于有效探索廣闊的化學空間。如今,它們已被用于預測性質、規劃多步合成(multi-step syntheses)和探索化學反應空間。
5)Transformer架構
Transformer是一種神經架構模型,可通過靈活模擬任意標記對之間的相互作用來處理標記序列,超越了早期使用遞歸神經網絡進行序列建模的努力。
Transformer在自然語言處理中占據主導地位,并已成功應用于一系列問題:包括地震信號檢測、DNA 和蛋白質序列建模、序列變異對生物功能影響的建模、以及符號回歸。雖然Transformer統一了圖神經網絡和語言模型,但Transformer的運行時間和內存占用可能與序列長度成二次方關系,從而導致長程建模(long-range modelling)和線性化注意機制(linearized attention mechanisms)在效率方面面臨挑戰。
因此,無監督或自監督的生成式預訓練Transformer被廣泛使用,然后進行參數高效微調。
6)神經算子
標準的神經網絡模型可能無法滿足科學應用的需要,因為它們假定數據離散度是固定的。這種方法不適合以不同分辨率和網格收集的許多科學數據集。此外,數據通常是從連續域中的潛在物理現象(如地震活動或流體流動)中采樣的。
神經算子通過學習函數空間之間的映射來學習不受離散化影響的表征。神經算子保證離散化不變,這意味著它們可以處理任何離散化的輸入,并在網格細化時收斂到一個極限。神經算子經過訓練后,可以在任何分辨率下進行評估,無需重新訓練。相比之下,當部署過程中的數據分辨率與模型訓練時的數據分辨率發生變化時,標準神經網絡的性能就會下降。

可檢驗的假設是科學發現的核心。它們可以有多種形式:從數學中的符號表達到化學中的分子和生物學中的基因變異。例如,Johannes Kepler花了四年時間分析恒星和行星數據,最終提出了一個導致發現行星運動規律的假設。
人工智能方法可以在這一過程的多個階段發揮作用。它們可以從嘈雜的觀測數據中識別出候選的符號表達式,從而提出假設;它們可以幫助設計對象,如與治療目標結合的分子,或與數學猜想相矛盾的反例,建議在實驗室中進行實驗評估。
此外,人工智能系統還能學習假設的貝葉斯后驗分布,并利用它生成與科學數據和知識相匹配的假設。
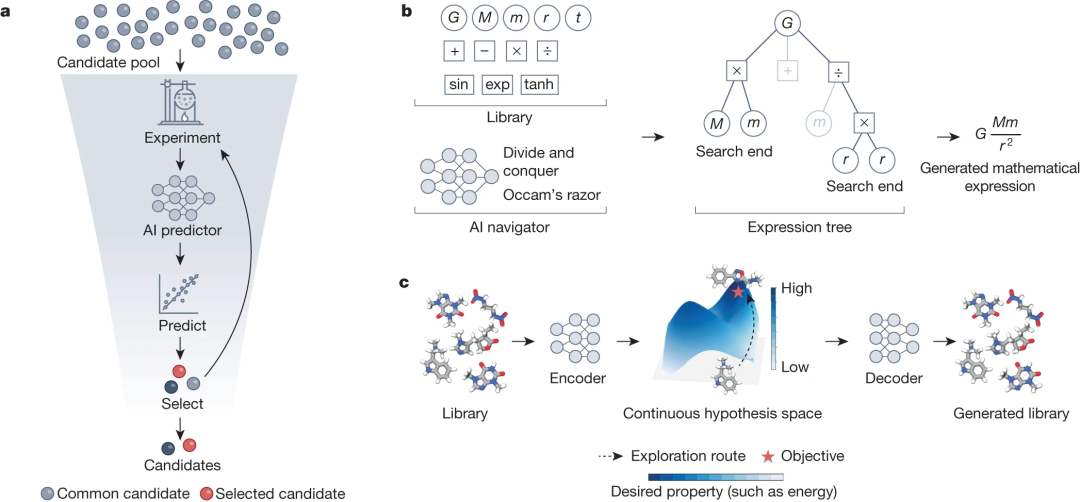
a)高通量篩選是指利用在實驗生成的數據集上訓練的人工智能預測器,篩選出少量具有理想特性的篩選對象,從而將候選對象庫的總規模減少幾個數量級。這種方法可以利用自監督學習,在大量未篩選對象上對預測器進行預訓練,然后在帶有標記讀數的篩選對象數據集上對預測器進行微調。實驗室評估和不確定性量化可以完善這種方法,從而簡化篩選過程,使其更具成本效益和時間效率,最終加快候選化合物、材料和生物分子的鑒定。b)人工智能導航儀利用強化學習代理和設計標準(如奧卡姆剃刀)預測的獎勵,在符號回歸過程中關注候選假設中最有希望的元素。圖中所示的示例說明了牛頓萬有引力定律數學表達式的推理過程。低分搜索路徑在符號表達式樹中顯示為灰色分支。c)人工智能微分器是一種自動編碼器模型,可將離散對象(如化合物)映射到可微分的連續潛空間中的點。這個空間允許對對象進行優化,例如從龐大的化學庫中選擇能最大限度地提高特定生化終點的化合物。理想化的景觀圖描述了學習到的潛在空間,較深的顏色表示富含預測分數較高的對象的區域。通過利用這一潛在空間,人工智能分化器可以高效地識別出能最大化紅星所示所需屬性的對象。
1)科學假說的黑箱預測器
要為科學探索確定有前途的假設,就需要有效地檢查許多候選假設,并選擇那些能最大限度提高下游模擬和實驗收益的假設。
在藥物發現中,高通量篩選可以評估數千到數百萬個分子,而算法可以優先選擇需要進行實驗研究的分子。可以對模型進行訓練,以預測實驗的效用,如相關的分子特性或符合觀察結果的符號公式。然而,許多分子可能無法獲得這些預測因子的實驗基礎數據。因此,可以采用弱監督學習方法來訓練這些模型,將有噪聲、有限或不精確的監督作為訓練信號。這些方法可以經濟有效地替代人類專家的注釋、昂貴的硅學計算或更高保真的實驗。
在高保真模擬基礎上訓練的人工智能方法已被用于高效篩選大型分子庫,如 160 萬個有機發光二極管候選材料 和 110 億個合成配體候選材料。在基因組學領域,經過訓練能從 DNA 序列預測基因表達值的變壓器架構有助于確定基因變體的優先次序。在粒子物理學中,識別質子中的固有粲夸克需要篩選所有可能的結構,并對每個候選結構擬合實驗數據。為進一步提高這些過程的效率,可將人工智能篩選出的候選結構送往中低通量實驗,利用實驗反饋不斷完善候選結構。實驗結果可通過主動學習和貝葉斯優化反饋到人工智能模型中,使算法能夠完善其預測,并將重點放在最有希望的候選結構上。
當假設涉及分子等復雜物體時,人工智能方法就變得非常有價值。例如,在蛋白質折疊方面,AlphaFold2可以根據氨基酸序列預測蛋白質的三維原子坐標,其精確度甚至可以達到原子級,甚至可以預測結構與訓練數據集中的任何蛋白質都不同的蛋白質。這一突破促進了各種人工智能驅動的蛋白質折疊方法的發展,如 RoseTTAFold。除了正向問題,人工智能方法也越來越多地用于逆向問題,旨在了解產生一組觀察結果的因果因素。逆向問題,如逆向折疊或固定骨架設計,可使用在數百萬個蛋白質結構上訓練過的黑盒預測器,根據蛋白質骨架三維原子坐標預測氨基酸序列。
不過,這種黑盒人工智能預測器需要大量訓練數據集,盡管減少了對現有科學知識的依賴,但可解釋性有限。
2)組合假設空間導航
盡管對所有與數據相匹配的假設進行采樣令人生畏,但一個可管理的目標是尋找一個好的假設,這可以表述為一個優化問題。與依賴人工設計規則的傳統方法相比,人工智能策略可用于估算每次搜索的回報,并優先選擇價值較高的搜索方向。通常采用強化學習算法訓練的代理來學習策略。該代理學會在搜索空間中采取能使獎勵信號最大化的行動,獎勵信號可定義為反映所生成假設的質量或其他相關標準。
為了解決優化問題,可以使用進化算法來解決符號回歸任務,進化算法會生成隨機符號法則作為初始解集。在每一代中,候選解都會有細微的變化。算法會檢查任何修改所產生的符號定律是否比之前的解決方案更適合觀測結果,并將最好的解決方案保留到下一代。
不過,強化學習方法正逐漸取代這一標準策略。強化學習利用神經網絡,通過添加預定義詞匯表中的數學符號,并利用所學策略決定下一步添加哪個符號,從而依次生成數學表達式。數學公式表示為一棵解析樹。學習策略將解析樹作為輸入,以決定擴展哪個葉節點和添加哪個符號(來自詞匯表)。使用神經網絡解決數學問題的另一種方法是將數學公式轉化為二進制符號序列。然后,神經網絡策略可以按概率順序每次增加一個二進制字符。通過設計一種衡量反駁猜想能力的獎勵,這種方法可以在事先不了解數學問題的情況下找到數學猜想的反駁方法。
組合優化也適用于發現具有理想藥物特性的分子等任務,其中分子設計的每一步都是一個離散的決策過程。在這個過程中,部分生成的分子圖將作為學習策略的輸入,對在分子中選定位置添加新原子和添加哪個原子做出離散選擇。通過迭代執行這一過程,策略可以生成一系列可能的分子結構,并根據其與目標特性的匹配度進行評估。搜索空間過于廣闊,無法探索所有可能的組合,但強化學習可以通過優先選擇值得研究的最有前景的分支來有效地引導搜索。強化學習方法可以使用訓練目標進行訓練,鼓勵產生的策略從所有合理的解決方案(具有高回報)中采樣,而不是像強化學習中的標準回報最大化那樣,只關注一個好的解決方案。
目前,這些強化學習方法已成功應用于各種優化問題,包括蛋白質表達最大化、規劃水力發電以減少對亞馬遜流域的不利影響,以及探索粒子加速器的參數空間。
人工智能代理學習到的政策預見了一些最初看似非常規的行動,但事實證明是有效的。例如,在數學領域,監督模型可以識別數學對象之間的模式和關系,幫助引導直覺和提出猜想。這些分析指出了以前未知的模式,甚至是世界的新模型。然而,在模型訓練過程中,強化學習方法可能無法很好地泛化到未見過的數據中,因為代理在找到一連串有效的行動后,可能會陷入局部最優狀態。為了提高泛化能力,需要采取一些探索策略來收集更廣泛的搜索軌跡,以幫助代理在新的和修改過的環境中表現得更好。
3)優化可變假設空間
科學假設通常以離散對象的形式出現,例如物理學中的符號公式或制藥和材料科學中的化合物。雖然組合優化技術已經成功地解決了其中的一些問題,但可微分空間也可用于優化,因為它適合基于梯度的方法,這種方法可以有效地找到局部最優點。
為了能夠使用基于梯度的優化方法,有兩種方法經常被使用:
- 第一種是使用 VAE 等模型,將離散的候選假設映射到潛在可變空間中的點。
- 第二種方法是將離散假設弛豫為可在可微分空間中優化的可微分對象。這種弛豫可以采取不同的形式,例如用連續變量替換離散變量,或使用原始約束條件的軟版本。
物理學中的符號回歸應用使用語法 VAE。這些模型使用無上下文語法將離散符號表達式表示為解析樹,并將解析樹映射到可變潛空間。然后采用貝葉斯優化法優化符號規律的潛在空間,同時確保表達式在語法上有效。
在天體物理學中,VAE 被用于根據預訓練的黑洞波形模型估算引力波探測器參數。這種方法比傳統方法快達六個數量級,因此捕捉瞬態引力波事件非常實用;在材料科學領域,熱力學規則與自動編碼器相結合,設計出一個可解釋的潛在空間,用于識別晶體結構的相圖;在化學領域,簡化分子輸入線輸入系統(SMILES)-VAE等模型可將 SMILES 字符串(即以計算機可輕松理解的離散系列符號形式表示化學結構的分子符號)轉化為可利用貝葉斯優化技術進行優化的可微分潛空間。通過將分子結構表示為潛在空間中的點,我們可以設計可微分目標,并利用自監督學習對其進行優化,從而根據分子的潛在表示預測分子特性。
這意味著,我們可以通過將人工智能預測器的梯度反向傳播到分子輸入的連續值表示來優化離散分子結構。解碼器可以將這些分子表征轉化為近似對應的離散輸入,這種方法可用于蛋白質和小分子的設計。
與原始假設空間中的機理方法相比,在潛在空間中進行優化能更靈活地模擬潛在數據分布。然而,在假設空間中探索稀少的區域進行外推預測可能效果不佳。在許多科學學科中,假設空間可能遠遠大于實驗所能考察的范圍。例如,據估計大約有10^60個分子,而即使是最大的化學庫也只包含不到 10^10 個分子。
因此,我們迫切需要一種方法,在這些基本未開發的區域中高效搜索并識別高質量的候選解決方案。

通過實驗評估科學假設對科學發現至關重要。然而,實驗室實驗可能成本高昂且不切實際。計算機模擬已成為一種有前途的替代方法,為更高效、更靈活的實驗提供了可能。雖然模擬依賴于手工制作的參數和啟發式方法來模仿真實世界的場景,但與物理實驗相比,模擬需要在準確性和速度之間做出權衡,這就需要了解其背后的機制。
然而,隨著深度學習的出現,這些挑戰正在通過識別和優化假設以進行高效測試,以及賦予計算機模擬將觀察結果與假設聯系起來的能力而得到解決。
1)高效評估科學假設
人工智能系統提供了實驗設計和優化工具,可以增強傳統的科學方法,減少所需的實驗數量并節省資源。具體來說,人工智能系統可以協助完成實驗測試的兩個基本步驟:規劃和指導。在傳統方法中,這兩個步驟往往需要反復試驗,效率低下,成本高昂,有時甚至危及生命。人工智能規劃為設計實驗、優化實驗效率和探索未知領域提供了系統方法。同時,人工智能引導將實驗過程引向高產假設,讓系統從先前的觀察中學習并調整實驗進程。這些人工智能方法可以是基于模型的,使用模擬和先驗知識;也可以是無模型的,僅基于機器學習算法。
人工智能系統可以通過優化資源利用和減少不必要的調查來幫助規劃實驗。與假設搜索不同,實驗規劃涉及科學實驗設計中的程序和步驟。化學中的合成規劃就是一個例子。合成規劃涉及尋找一連串步驟,通過這些步驟可以從現有化學品中合成目標化合物。人工智能系統可以設計出所需化合物的合成路線,從而減少對人工干預的需求。
主動學習也被用于材料發現和合成。主動學習包括與實驗反饋反復互動并從中學習,以完善假設。材料合成是一個復雜的資源密集型過程,需要對高維參數空間進行有效探索。主動學習利用不確定性估計來探索參數空間,以盡可能少的步驟減少不確定性。
在正在進行的實驗中,決策通常必須實時調整。然而,如果僅憑人類的經驗和直覺,這一過程既困難又容易出錯。強化學習提供了另一種方法,可持續應對不斷變化的環境,最大限度地提高實驗的安全性和成功率。例如,強化學習方法已被證明對托卡馬克等離子體的磁控制有效,算法與托卡馬克模擬器互動,優化控制過程的策略。在另一項研究中,強化學習代理利用風速和太陽高度等實時反饋來控制平流層氣球,并為導航尋找有利的風流。
在量子物理學中,實驗設計需要動態調整,因為復雜實驗未來實體化的最佳選擇可能與直覺相反:強化學習方法可以通過迭代設計實驗和接收實驗反饋來克服這一問題。例如,強化學習算法已被用于優化量子系統的測量和控制,提高了實驗效率和精度。
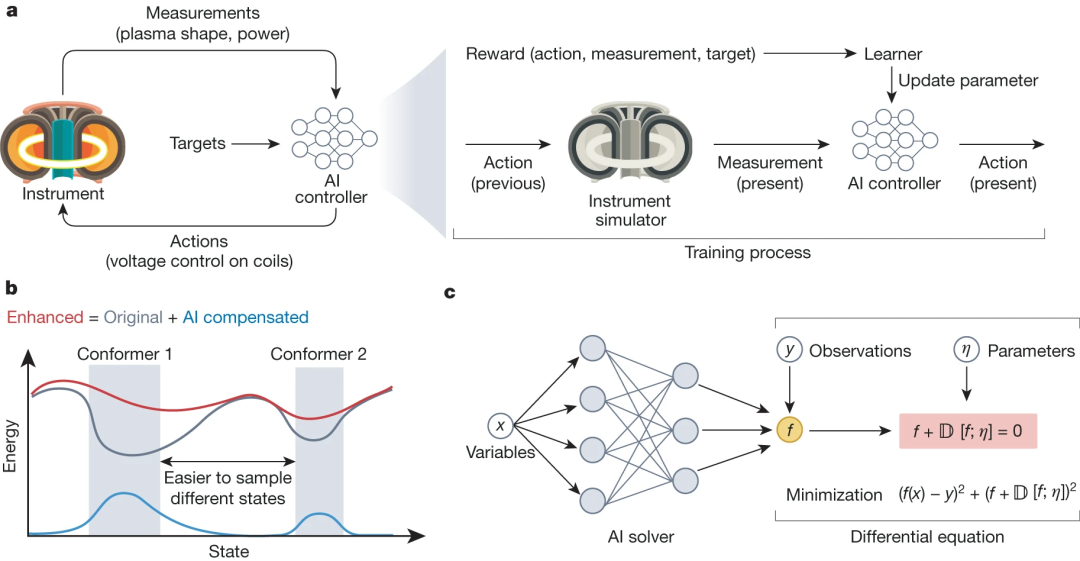
a)利用人工智能對復雜動態系統進行核聚變控制:Degrave 等人開發了一種人工智能控制器,通過托卡馬克反應堆中的磁場調節核聚變。人工智能代理接收對電氣電壓水平和等離子體配置的實時測量結果,并采取行動控制磁場和實現實驗目標,如維持正常的電力供應。b)在復雜系統的計算模擬中,人工智能系統可以加速罕見事件的檢測,如蛋白質不同構象結構之間的轉換。c)用于求解偏微分方程的神經框架,其中的人工智能求解器是一個經過訓練的物理信息神經網絡,用于估計目標函數 f。當微分方程的表達式是未知的(以 η 為參數)時,可以通過求解多目標損失來估算微分方程,從而優化方程的函數形式及其與觀測值 y 的擬合。
2)利用模擬從假設中推導出可觀測的數據
計算機模擬是一種強大的工具,可以從假設中推導出可觀測的數據,從而對無法直接驗證的假設進行評估。然而,現有的模擬技術嚴重依賴于人類對所研究系統內在機制的理解和知識,這可能是次優和低效的。人工智能系統可以通過更好地擬合復雜系統的關鍵參數、求解支配復雜系統的微分方程以及模擬復雜系統中的狀態,來提高計算機模擬的準確性和學習效率。
科學家在研究復雜系統時,通常會創建一個涉及參數化形式的模型,這就需要領域知識來確定參數的初始符號表達式。分子力場就是一個例子,這種力場可以解釋,但在表示各種函數方面能力有限,需要很強的歸納偏差或科學知識才能生成。為了提高分子模擬的準確性,人們開發了一種基于人工智能的神經勢能,它能擬合昂貴但準確的量子力學數據,以取代傳統的力場。
此外,不確定性量化已被用于定位高維自由能面上的能障,從而提高分子動力學的效率。對于粗粒度分子動力學,已利用人工智能模型確定系統需要從所學的隱藏復雜結構中粗化的程度,從而降低大型系統的計算成本。在量子物理學中,神經網絡因其靈活性和準確擬合數據的能力,在波函數或密度函數的參數化過程中取代了人工估計的符號形式。
微分方程對復雜系統的時空動態建模至關重要。與數值代數求解器相比,基于人工智能的神經求解器能更完美地整合數據與物理。這些神經求解器將物理學與深度學習的靈活性相結合,將神經網絡建立在領域知識的基礎上。
人工智能方法已被應用于多個領域的微分方程求解,包括計算流體動力學、預測玻璃系統結構、求解剛性化學動力學問題,以及求解艾克納方程以描述地震波的傳播時間。在動力學建模中,連續時間可以用神經常微分方程建模。神經網絡可以利用物理信息損失對納維-斯托克斯方程在時空域中的解進行參數化。然而,標準卷積神經網絡對解法的精細結構特征建模能力有限;這個問題可以通過學習利用神經網絡建模函數間映射的算子來解決。此外,求解器必須能夠適應不同的領域和邊界條件。這可以通過將神經微分方程與圖神經網絡相結合來實現,從而通過圖分割實現任意離散。
統計建模是一種強大的工具,可通過對復雜系統中的狀態分布建模,對這些系統進行全面的定量描述。由于能夠捕捉高度復雜的分布,深度生成建模最近已成為復雜系統仿真中的一種重要方法。一個著名的例子是基于標準化流的波爾茲曼生成器。標準化流可以將任何復雜分布映射到先驗分布(例如簡單的高斯分布),然后使用一系列可逆神經網絡將其返回。標準化流雖然計算成本高昂(通常需要數百或數千個神經層),但卻能提供精確的密度函數,從而實現采樣和訓練。
與傳統模擬不同,標準化流可以直接從先驗分布中采樣,并應用計算成本固定的神經網絡來生成平衡狀態。這增強了晶格場和規范場論中的采樣,并改進了馬爾科夫鏈蒙特卡羅方法——否則這些方法可能會因模式混合而無法收斂。

要利用科學數據,就必須利用模擬和人類的專業知識來建立和使用模型。這種整合為科學發現帶來了機遇。然而,要進一步提高人工智能在各科學學科中的影響力,還需要在理論、方法、軟件和硬件基礎設施方面取得重大進展。
要實現通過人工智能推動科學發展的全面而實用的方法,跨學科合作至關重要。
1)實際考慮因素
科學數據集往往不能直接用于人工智能分析,因為測量技術的限制會產生不完整的數據集、有偏差或相互矛盾的讀數,而且由于隱私和安全問題,數據集的可訪問性有限。
此外,聯合學習和加密算法可用于防止向公共領域發布具有高商業價值的敏感數據。利用開放的科學文獻、自然語言處理和知識圖譜技術可以促進文獻挖掘,為材料發現、化學合成和治療科學提供了支持。
深度學習的使用對人工智能驅動的環內設計、發現和評估提出了復雜的挑戰。為了實現科學工作流程自動化、優化大規模仿真代碼和操作儀器,自主機器人控制可以利用預測,在高通量合成和測試線上進行實驗,創建自動駕駛實驗室。生成模型在材料探索領域的早期應用表明,可以識別出數百萬種可能的材料,這些材料具有所需的特性和功能,并可對其可合成性進行評估。在化學合成中,人工智能優化候選合成路線,然后由機器人按照預測的合成路線引導化學反應。
人工智能系統的實際實施涉及復雜的軟件和硬件工程,需要一系列相互依存的步驟:從數據整理和處理到算法實施以及用戶和應用界面設計。實施過程中的細微差別都可能導致性能的巨大變化,并影響到將人工智能模型融入科學實踐的成功與否。
因此,需要考慮數據和模型的標準化。由于模型訓練的隨機性、模型參數的變化以及訓練數據集的不斷變化,人工智能方法可能會受到可重復性的影響,而這些因素既依賴于數據,也依賴于任務。標準化基準和實驗設計可以緩解這些問題。提高可重復性的另一個方向是通過開源計劃,發布開放模型、數據集和教育計劃。
2)算法創新
為了促進科學理解或自主獲得科學理解,需要進行算法創新,以建立一個基礎生態系統,在整個科學過程中使用最合適的算法。
盡管許多科學定律并不具有普遍性,但它們的適用性一般都很廣泛。與最先進的人工智能相比,人類大腦能更好、更快地概括修改過的環境。一個很有吸引力的假設是,這是因為人類建立的不僅僅是一個觀察到的統計模型,而是一個因果模型,即由所有可能的干預(例如,不同的初始狀態、代理人的行動或不同的制度)所索引的統計模型系列。將因果關系納入人工智能仍是一個年輕的領域,仍有許多工作要做。自我監督學習等技術在科學問題上具有巨大潛力,因為它們可以利用大量無標簽數據,并將知識轉移到低數據環境中。然而,目前的遷移學習方案可能是臨時性的,缺乏理論指導,而且容易受到基礎分布變化的影響。盡管初步嘗試已經解決了這一難題,但仍需更多探索,以系統地衡量跨領域的可遷移性并防止負遷移。
此外,為了解決科學家們關心的難題,人工智能方法的開發和評估必須在真實世界的場景中進行,如藥物設計中可信的可實現合成路徑,并包括校準良好的不確定性估計器,以評估模型的可靠性,然后再將其過渡到真實世界的實施中。
科學數據是多模態的,包括圖像(如宇宙學中的黑洞圖像)、自然語言(如科學文獻)、時間序列(如材料的熱黃變)、序列(如生物序列)、圖(如復雜系統)和結構(如三維蛋白質配體構象)。例如,在高能物理中,射流是夸克和膠子在高能量下產生的粒子對準噴射;從輻射模式中識別它們的子結構有助于尋找新的物理學。噴流子結構可以用圖像、序列、二叉樹、通用圖和張量集來描述。雖然利用神經網絡處理圖像的研究已經非常廣泛,但僅僅處理粒子圖像是不夠的。同樣,單獨使用噴氣子結構的其他表示方法也無法提供復雜系統的整體綜合系統視圖。盡管整合多模態觀測結果仍是一項挑戰,但神經網絡的模塊化特性意味著不同的神經模塊可以將不同的數據模態轉化為通用的矢量表征。
科學知識,如分子中的旋轉等差性、數學中的相等約束、生物學中的疾病機理以及復雜系統中的多尺度結構,都可以納入人工智能模型。然而,哪些原則和知識最有幫助、最實用,目前還不清楚。由于人工智能模型需要大量數據才能擬合,因此在數據集較小或注釋稀少的情況下,將科學知識融入模型可以幫助學習。因此,研究必須建立將知識融入人工智能模型的原則性方法,并了解領域知識與從測量數據中學習之間的權衡。
人工智能方法通常以黑箱形式運行,這意味著用戶無法完全解釋輸出是如何產生的,以及哪些輸入對產生輸出至關重要。黑箱模型會降低用戶對預測的信任度,在一些領域的適用性有限,在這些領域中,模型輸出在實際應用之前必須被理解,例如人類太空探索,以及預測為政策提供依據的領域,例如氣候科學。盡管可解釋性技術層出不窮,透明的深度學習模型仍然難以實現。不過,人腦能綜合出高層次的解釋,即使不完美,也能說服其他人,這給我們帶來了希望:通過對現象進行類似的高層次抽象建模,未來的人工智能模型將能提供可解釋的解釋,其價值至少不亞于人腦提供的解釋。這也表明,研究更高層次的認知可能會激發未來的深度學習模型,使其同時具備當前的深度學習能力和處理可言語化抽象概念、因果推理以及從分布中歸納的能力。
3)科學行為和科學事業
展望未來,對人工智能專業技術的需求將受到兩股力量的影響。?
首先,存在即將從應用人工智能技術中獲益的問題。其次,智能工具有能力提升技術水平并創造新的機遇:例如自動駕駛實驗室。?
第二,智能工具有能力提升技術水平并創造新的機遇:例如檢查生物、化學或物理過程,這些過程發生在實驗無法達到的長度和時間尺度上。
在這兩種力量的基礎上,我們預計研究團隊的組成將發生變化,包括人工智能專家、軟件和硬件工程師,以及新的研究形式、 軟件和硬件工程師,以及涉及各級政府、教育機構和企業的新型合作形式。
然而,計算這些更新所需的計算量和數據量是巨大的。因此,大型科技公司對計算基礎設施和云服務進行了大量投資。盡管營利性組織和非學術性組織也能使用龐大的計算基礎設施,但它們的計算能力和計算成本并不高。盡管營利性組織和非學術性組織可以使用龐大的計算基礎設施,但高等教育機構可以更好地整合多個學科。此外,學術機構往往擁有獨特的歷史數據庫和測量技術,這些技術在其他地方可能不存在,但對AI4Science來說卻是必要的。這些互補性資產促進了產學合作的新模式,從而影響到研究問題的選擇。影響研究問題的選擇。
隨著人工智能系統的性能接近或超過人類,用它來替代常規實驗室工作正變得可行。這種方法使研究人員能夠根據實驗數據反復開發預測模型,并選擇實驗來改進模型,而無需手動執行費力的重復性工作。為了支持這種模式的轉變,培訓科學家設計、實施和改進實驗室工作的教育計劃正在興起。這些計劃幫助科學家了解 何時適合使用人工智能,并防止人工智能分析得出的結論被曲解。
人工智能工具的誤用和對其結果的曲解會產生重大負面影響。然而,人工智能的濫用并不僅僅是一個技術問題;它還取決于那些引領人工智能創新和投資人工智能實施的人的動機。建立道德審查流程和負責任的實施策略至關重要,包括 此外,還必須考慮與人工智能相關的安全風險,因為將算法重新用于人工智能已變得越來越容易。由于算法可適應廣泛的應用,它們可以為一種目的而開發,但又可用于另一種目的,這就造成了一種安全風險。
要利用科學數據,就必須利用人工智能。展望未來,人工智能有可能開啟以前遙不可及的科學發現。
來源:
[1]https://www.nature.com/articles/s41586-021-03819-2
[2]https://www.nature.com/articles/s41586-019-1335-8#Fig1
[3]https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.143001
[4]https://www.nature.com/articles/s41586-023-06221-2#Fig2



![應用程序運行報錯:First section must be [net] or [network]:No such file or directory](http://pic.xiahunao.cn/應用程序運行報錯:First section must be [net] or [network]:No such file or directory)
)




)
)

)





concurrent.futures高級別異步執行封裝)
