?????? 哈希表,也稱散列表,是一種通過key值來直接訪問在內存中的存儲的數據結構。它通過一個關鍵值的函數(被稱為散列函數)將所需的數據映射到表中的位置來訪問數據。
關于哈希表,主要為以下幾個方面:
一、哈希表的幾種方法
1、直接定址法:取關鍵字key的某個線性函數為散列地址,如Hash(key) = key? 或 Hash(key) = A*key+B;A,B為常數
2、除留取余法:關鍵值除以比散列表長度小的素數所得的余數作為散列地址。Hash(key) = key % p;
3、平均取中法:先計算構成關鍵碼的標識符的內碼的平方,然后按照散列表的大小取中間的若干位作為散列地址。
4、折疊法:把關鍵碼自左到右分為位數相等的幾部分,每一部分的位數應與散列表地址位數相同,只有最后一部分的位數可以短一些。把這些部分的數據疊加起來,就可以得到具有關鍵碼的記錄的散列地址。分為移位法和分界法。
5、隨機數法:選擇一個隨機函數,取關鍵字的隨機函數作為它的哈希地址。
6、數學分析法:設有N個d位數,每一位可能有r種不同的符號。這r種不同的符號在各位上出現的頻率不一定相同,可能在某些位上分布均勻些,每種符號出現的機會均等;在某些位上分布不均勻,只有某幾種符號經常出現。可根據散列表的大小,選取其中各種符號分布均勻的若干位作為散列地址。
在這里,我們建哈希表的方法用除留取余法為例。
盡管有這么多種方法,但是不同的key值可能會映射到同一散列地址上。這樣就會造成哈希沖突/哈希碰撞。
那么遇到哈希沖突我們該如何處理呢?
二、處理哈希沖突的閉散列方法
1、線性探測:當不同的key值通過哈希函數映射到同一散列地址上時,檢測當前地址的下一個地址是否可以插入,如果可以的話,就存在當前位置的下一個地址,否則,繼續向下一個地址尋找,地址++。
2、二次探測:是針對線性探測的一個改進,線性探測后插入的key值太集中,這樣造成key值通過散列函數后還是無法正確的映射到地址上,太集中也會造成查找、刪除時的效率低下。因此,通過二次探測的方法,取當前地址加上i^2,可以取到的新的地址就會稍微分散開。
如:此時的散列表長度為10:
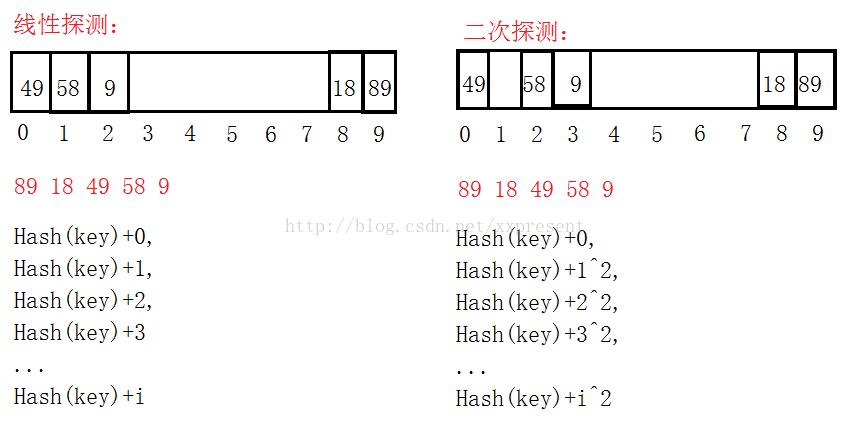
看到以上的例子之后,我們只是存入int型的數據時,計算余數尋找地址是比較容易的。如果我們存入的是字典值(string類型),那么我們就要通過string類型來轉化成數值來計算地址。這里用到了BKDR哈希算法(字符串哈希算法)。
同時,經研究表明,通過素數表作為哈希表的長度可以降低哈希沖突。
三、閉散列實現代碼
主要實現如下:
#pragma once
#include<vector>
#include<iostream>
using namespace std;
#include<assert.h>
#include<string>enum Status
{EXIST,DELETE,EMPTY
};template<class K,class V>
struct HashTableNode
{K _key;V _value;Status _status;HashTableNode(const K& key = K(), const V& value = V()):_key(key),_value(value),_status(EMPTY){}
};template<class K>
struct __HashFunc
{size_t operator()(const K& key){return key;}
};template<>
struct __HashFunc<string>
{size_t BKDRHash(const char* str){register size_t hash = 0;while(*str){hash = hash*131 + *str;++str;}return hash;}size_t operator()(const string& str){return BKDRHash(str.c_str());}
};
template<class K,class V,class _HashFunc = __HashFunc<K>>
class HashTable
{typedef HashTableNode<K,V> Node;
public:HashTable(size_t size):_size(0){assert(size > 0);// _tables.resize(size);_tables.resize(GetPrime());}~HashTable(){}size_t HashFunc(const K& key){_HashFunc hf;size_t va = hf(key);return va % _tables.size();}void Swap(HashTable<K,V,_HashFunc>& ht){_tables.swap(ht._tables);swap(_size,ht._size);}void _CheckCapacity(){if(_tables.size() == 0 || _size*10 / _tables.size() >= 7){size_t OldSize = _tables.size();// size_t NewSize = _tables.size()*2+3;size_t NewSize = GetPrime();HashTable<K,V,_HashFunc> ht(NewSize);for(size_t i = 0; i < OldSize; i++){if(_tables[i]._status == EXIST){ht.Insert(_tables[i]._key,_tables[i]._value);}}this->Swap(ht);}}pair<Node*,bool> Insert(const K& key,const V& value){_CheckCapacity();size_t index = HashFunc(key);//線性探測/*while(_tables[index]._status == EXIST ){if(_tables[index]._key == key)return make_pair((Node*)NULL,false);++index;if(index == _tables.size()){index = 0;}}*///二次探測size_t i = 0;size_t first = index;while(_tables[index]._status == EXIST ){if(_tables[index]._key == key)return make_pair((Node*)NULL,false);++i;index = first + i*i;index %= _tables.size();}++_size;_tables[index]._key = key;_tables[index]._value = value;_tables[index]._status = EXIST;return make_pair(&_tables[index],true);}Node* Find(const K& key,const V& value){size_t index = HashFunc(key);while(_tables[index]._status != EMPTY){if(_tables[index]._key == key && _tables[index]._status == EXIST){return &_tables[index];}else{++index;if(index == _tables.size()){index = 0;}}}return NULL;}bool Remove(const K& key,const V& value){Node* tmp = Find(key,value);if(tmp){tmp->_status = DELETE;return true;}return false;}size_t GetPrime(){// 使用素數表對齊做哈希表的容量,降低哈希沖突const int _PrimeSize = 28;static const unsigned long _PrimeList[_PrimeSize] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul,786433ul,1572869ul, 3145739ul,6291469ul, 12582917ul,25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,805306457ul,1610612741ul, 3221225473ul, 4294967291ul};for(size_t i = 0; i < _PrimeSize; i++){if(_tables.size() < _PrimeList[i])return _PrimeList[i];}return 0;}
private:vector<Node> _tables;size_t _size;
};void HashTest()
{HashTable<int,int> ht(10);ht.Insert(89,0);ht.Insert(18,0);ht.Insert(49,0);ht.Insert(58,0);ht.Insert(9,0);cout<<ht.Remove(58,0)<<endl;if(ht.Find(49,0))cout<<ht.Find(9,0)->_key<<endl;HashTable<string,string> ht1(10);ht1.Insert("sort","排序");ht1.Insert("left","左邊");ht1.Insert("right","右邊");ht1.Insert("up","上邊");if(ht1.Find("sort","排序"))cout<<ht1.Find("sort","排序")->_key<<endl;cout<<ht1.Remove("sort","排序")<<endl;
}
四、處理哈希沖突的開鏈法(哈希桶)
當用線性探測和二次探測時,總是在一個有限的哈希表中存儲數據,當數據特別多時,效率就比較低。因此采用拉鏈法的方式來降低哈希沖突。
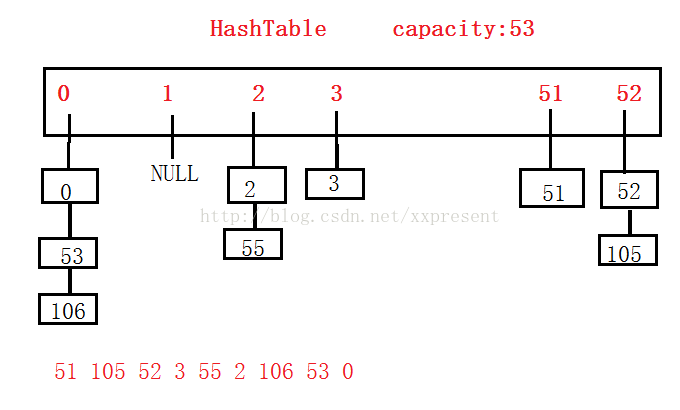
還有一種情況是,當一個鏈上鏈的數據過多時,我們可以采用紅黑樹的方式來降低高度,保持平衡且不至于過載。
五、哈希桶的實現方式(考慮到存儲整形和字符串型)
#pragma once
#include<iostream>
using namespace std;
#include<vector>
#include<string>namespace HashBucket
{template<class K>struct __HashFunc{size_t operator()(const K& key){return key;}};template<>struct __HashFunc<string>{size_t BKDRHash(const char* str){register size_t hash = 0;while(*str){hash = hash*131 + *str;++str;}return hash;}size_t operator()(const string& str){return BKDRHash(str.c_str());}};template<class K,class V,class _HashFunc>class HashTable;template<class K,class V>struct HashNode{pair<K,V> _kv;HashNode<K,V> *_next;HashNode(const pair<K,V>& kv):_kv(kv),_next(NULL){}};template<class K,class V,class Ref,class Ptr>struct HashIterator{typedef HashNode<K,V> Node;typedef HashIterator<K,V,Ref,Ptr> Self;Node* _node;HashTable<K,V,__HashFunc<K>>* _ht;HashIterator(Node* node,HashTable<K,V,__HashFunc<K>>* ht):_node(node),_ht(ht){}Ref operator*(){return _node->_kv;}Ptr operator->(){return &_node;}bool operator!=(const Self& s) const{return _node != s._node;}Self& operator++(){_node = Next(_node);return *this;}Node* Next(Node* node){Node* next = node->_next;if(next)return next;else{size_t index = _ht->HashFunc(node->_kv.first)+1;for(;index < _ht->_tables.size();++index){next = _ht->_tables[index];if(next){return next;}}return NULL;}}};template<class K,class V,class _HashFunc = __HashFunc<K>>class HashTable{typedef HashNode<K,V> Node;public:typedef HashIterator<K,V,pair<K,V>&,pair<K,V>*> Iterator;typedef HashIterator<K,V,const pair<K,V>&,const pair<K,V>*> ConstIterator;friend struct Iterator;friend struct ConstIterator;public:HashTable():_size(0){_tables.resize(GetNextPrime());}~HashTable(){Clear();}void Clear(){Node* cur = NULL;Node* del = NULL;for(size_t index = 0; index < _tables.size(); ++index){cur = _tables[index];if(cur == NULL){continue;}while(cur){del = cur;cur = cur->_next;delete del;del = NULL;}}}Iterator Begin(){Node* cur = _tables[0];for(size_t index = 0; index < _tables.size();++index){cur = _tables[index];if(cur){return Iterator(cur,this);}}return Iterator((Node*)NULL,this);}Iterator End(){return Iterator((Node*)NULL,this);/*Node* cur = _tables[_tables.size()-1];while(cur){if(cur == NULL){return Iterator(cur,this);}cur = cur->_next;}return Iterator((Node*)NULL,this);*/}size_t HashFunc(const K& key){_HashFunc hf;size_t va = hf(key);return va % _tables.size();}void Swap(HashTable<K,V,_HashFunc>& ht){_tables.swap(ht._tables);swap(_size,ht._size);}void _CheckCapacity(){//負載因子為1時,擴容if(_size == _tables.size()){size_t index = GetNextPrime();HashTable<K,V> tmp;tmp._tables.resize(index);Node* cur = NULL;for(;index < _tables.size();++index){cur = _tables[index];while(cur){tmp.Insert(cur->_kv);cur = cur->_next;}}this->Swap(tmp);}}size_t GetNextPrime(){// 使用素數表對齊做哈希表的容量,降低哈希沖突const int _PrimeSize = 28; static const unsigned long _PrimeList[_PrimeSize] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul,786433ul,1572869ul, 3145739ul,6291469ul, 12582917ul,25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,805306457ul,1610612741ul, 3221225473ul, 4294967291ul};for(size_t i = 0; i < _PrimeSize; i++){if(_tables.size() < _PrimeList[i])return _PrimeList[i];}return 0;}public:pair<Iterator,bool> Insert(pair<K,V> kv){_CheckCapacity();size_t index = HashFunc(kv.first);Node* cur = _tables[index];while(cur){if(cur->_kv.first == kv.first){return make_pair(Iterator(cur,this),false);}cur = cur->_next;}Node* tmp = new Node(kv);tmp->_next = _tables[index];_tables[index] = tmp;_size++;return make_pair(Iterator(tmp,this),true);}Node* Find(const K& key){size_t index = HashFunc(key);Node* cur = _tables[index];while(cur){if(cur->_kv.first == key){return cur;}cur = cur->_next;}return NULL;}bool Erase(const K& key){size_t index = HashFunc(key);Node* prev = NULL;Node* cur = _tables[index];Node* del = NULL;while (cur){if(cur->_kv.first == key){if(prev == NULL){_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;cur = NULL;_size--;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;size_t _size;};void HashTest(){HashTable<int,int> ht;ht.Insert(make_pair<int,int>(89,0));ht.Insert(make_pair<int,int>(18,0));ht.Insert(make_pair<int,int>(49,0));ht.Insert(make_pair<int,int>(58,0));ht.Insert(make_pair<int,int>(9,0));cout<<ht.Erase(58)<<endl;if(ht.Find(49))cout<<ht.Find(9)->_kv.first<<endl;HashTable<int,int>::Iterator it = ht.Begin();while(it != ht.End()){cout<<(*it).first<<":"<<(*it).second<<endl;++it;}HashTable<string,string> ht1;ht1.Insert(make_pair<string,string>("sort","排序"));ht1.Insert(make_pair<string,string>("left","左邊"));ht1.Insert(make_pair<string,string>("right","右邊"));ht1.Insert(make_pair<string,string>("up","上邊"));cout<<ht1.Erase("up")<<endl;cout<<ht1.Find("sort")->_kv.second<<endl;HashTable<string,string>::Iterator it1 = ht1.Begin();while(it1 != ht1.End()){cout<<(*it1).first<<":"<<(*it1).second<<endl;++it1;}}
};六、運行結果(編譯運行環境為:vs2013)



)





--【一】)

和waitpid()的參數解析)




的解釋與實踐)
)


