首先,為什么會有排序算法穩定性的說法?只要能排好不就可以了嗎?
看例子
第1行是數字2 記作 1 2
第2行是數字4 記作 2 4
第3行是數字2 記作 3 2
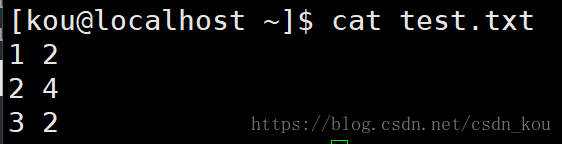
排序后的結果(如果看不懂命令的意思,參照這個博客)

那么引入我們的問題,有沒有可能排序結果是這樣子

排序的結果是正確的,可是它卻打亂了原本的文件順序。
那么在什么場景會出現這種情況呢?
我們在管理數據的時候,比如有ID和體重。那么胖的排前面,輕的排后面,沒問題!如果是體重相等呢?那就按服從ID排序了!
起始穩定排序的意義就是保證兩次排序結果相同,好好體會這句話的意義。
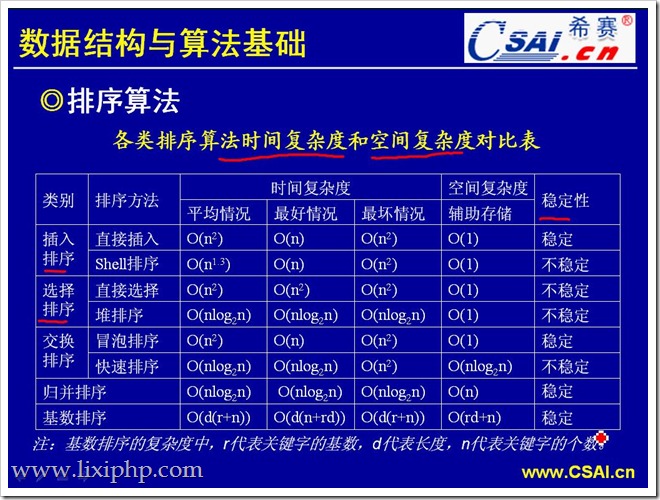
快速排序和歸并排序的平均時間復雜度都是一樣的,那為什么不全部都用歸并排序?
歸并排序需要開辟額外的空間,在數據較小時,可能不占優勢。
| 數組長度 | 快速排序(運行時間/毫秒) | 歸并排序(運行時間/毫秒) |
|---|---|---|
| 100 | 0 | 0 |
| 1000 | 1 | 1 |
| 10000 | 1 | 3 |
| 100000 | 14 | 14 |
| 1000000 | 79 | 120 |
| 10000000 | 982 | 1186 |
| 100000000 | 55733 | 12328 |
| 算法 | 最壞時間復雜性 | 平均時間復雜性 |
|---|---|---|
| 快速排序 | n^2 | n*log(n) |
| 歸并排序 | n*log(n) | n*log(n) |
例子
例如要排序的內容是一組原本按照價格高低排序的對象,如今需要按照銷量高低排序,使用穩定性算法,可以使得想同銷量的對象依舊保持著價格高低的排序展現,只有銷量不同的才會重新排序。(當然,如果需求不需要保持初始的排序意義,那么使用穩定性算法依舊將毫無意義)
換句話說,以某種關鍵字的方式排序后,能不影響到其他關鍵字原來排序結果的方法就是穩定的,比如一開始按照價格高低排序結果為 a(10元,賣了5個) b(8元,賣了20個) c(6元,賣了20個) d(4元,賣了30個),則按照銷量重拍后如果保持 d(30個,價格為4元) b(20個,價格為8元) c(20個,價格為6元) a(5個,價格為10元),則說明該方法為穩定的,而如果出現c在b前,破壞了排序前b在c前的順序,則說明這個方法是不穩定的



請問下面的程序一共輸出多少個“A”?多少個-?)















