【騰訊云 TDSQL-C Serverless 產品體驗】基于TDSQL-C 存儲爬取的QQ音樂歌單數據

文章目錄
- 【騰訊云 TDSQL-C Serverless 產品體驗】基于TDSQL-C 存儲爬取的QQ音樂歌單數據
- 前言
- 出現的背景
- 一、TDSQL-C數據庫是什么?
- 二、TDSQL-C 的特點
- 三、TDSQL-C的應用場景
- 四、基于TDSQL-C 存儲爬取的QQ音樂歌單數據
- 1、創建TDSQL-C Serverless數據庫
- 2、創建所需數據庫并通過DMC進行數據庫管理
- 3、構建QQ音樂歌單爬蟲
- 3.1 初始化框架環境
- 3.2 在spiders下創建分類爬蟲
- 3.3 在spiders下創建歌單爬蟲
- 4、進行數據庫狀態觀察
- 總結
- 參考文獻
前言
最近有幸參與了騰訊云舉辦的 騰訊云 TDSQL-C 產品體驗活動。在這個過程中,通過了解 TDSQL-C 的產品和實踐,讓我受益非淺,原來數據庫還能這么玩! 也讓我真正體會到了降本增效這個詞的意義。
在看到活動的介紹和微信群的講解后,我馬不停蹄地開始了自己摸索。首先是跟著群里小助手發的實驗手冊,體驗了一下整個產品的業務流程。
隨后又查看官方的產品文檔,文檔非常的簡潔明了,然后根據這些資料開始了我的第一個 TDSQL-C 程序,基于 TDSQL-C 數據庫構建了一個基于 Vue 的問卷調查系統,親身體驗了 TDSQL-C 帶來的高性能、彈性可靠服務,整個過程十分絲滑。
下面就來整理,分享一下我的操作和感悟,希望能夠幫助到其他同學。
出現的背景
傳統數據庫為什么被云數據庫替代?
關于 TDSQL-C 的出現,我覺得需要先從云數據庫開始了解,傳統的本地數據庫部署需要企業自己購買、維護硬件設備和管理數據庫軟件,這對于資源有限的中小企業來說可能是一項昂貴和繁瑣的任務。同時,傳統數據庫在面對大規模的數據處理和高并發訪問時可能會遇到性能瓶頸和可用性問題。云數據庫的出現解決了這些問題。它將數據庫部署在云平臺上,并提供彈性的計算和存儲資源,使用戶能夠根據實際需求按需擴展數據庫的容量和性能。云數據庫還提供高可用性和可靠性,通過數據備份、冗余存儲和容災機制來保護數據的安全和可恢復性。此外,云數據庫還提供了便捷的管理和監控工具,簡化了數據庫的操作和維護過程。
serverless數據庫帶來了什么好處?
而云 Serverless 數據庫的出現則是為了進一步提供更高的靈活性和經濟效益。傳統的數據庫需要預先配置和維護一定數量的計算資源,而這些資源在閑置時仍然需要付費。而 Serverless 數據庫采用按需付費的模式,它根據實際的計算和存儲資源使用量來計費,無需預先配置資源。這使得用戶可以根據實際需求動態地擴展和縮減數據庫的資源,避免了資源浪費和額外的成本支出。Serverless 數據庫還可以自動管理和優化資源,用戶只需專注于應用開發,而無需關注底層基礎設施的管理。
而 TDSQL-C 是騰訊云自研的新一代云原生關系型數據庫。融合了傳統數據庫、云計算與新硬件技術的優勢,100%兼容 MySQL,為用戶提供極致彈性、高性能、高可用、高可靠、安全的數據庫服務。實現超百萬 QPS 的高吞吐、PB 級海量分布式智能存儲、Serverless 秒級伸縮,助力企業加速完成數字化轉型。
Serverless 服務是騰訊云自研的新一代云原生關系型數據庫 TDSQL-C MySQL 版的無服務器架構版,是全 Serverless 架構的云原生數據庫。Serverless 服務支持按實際計算和存儲資源使用量收取費用,不用不付費,將騰訊云云原生技術普惠用戶。
總的來說,云數據庫和云 Serverless 數據庫的產生是為了滿足不同規模和需求的用戶對于數據存儲和處理的需求,并提供更靈活、可擴展和經濟高效的解決方案。
一、TDSQL-C數據庫是什么?
TDSQL-C MySQL 版基于 Cloud Native 設計理念,既融合了商業數據庫穩定可靠、高性能、可擴展的特征,又具有開源云數據庫簡單開放、高效迭代的優勢。
我們來理解一下這段描述, Cloud Native 設計理念是什么?
Cloud Native 設計理念是一種在云計算環境下進行應用開發和部署的方法論和思維方式,目標是將應用程序和基礎設施解耦,使得應用程序能夠更好地適應云環境的動態性和彈性,并提供更好的可伸縮性、可靠性和可管理性。它能夠幫助開發者更快速、高效地構建和交付應用程序,并更好地應對日益復雜和變化的業務需求。
基于這個設計方式,所以 TDSQL-C MySQL 版可以為為用戶提供具備超高彈性、高性能、海量存儲、安全可靠的數據庫服務,以可幫助企業輕松應對諸如商品訂單等高頻交易、伴隨流量洪峰的快速增長業務、游戲業務、歷史訂單等大數據量低頻查詢、金融數據安全相關、開發測試、成本敏感等的業務場景。
二、TDSQL-C 的特點
我找到了一些關于我們在選擇底層組件時候需要關注的一些特點,憑什么 TDSQL-C 值得我們選擇呢?
- 完全兼容
TDSQL-C MySQL 版將開源數據庫的計算和存儲分離,存儲構建在騰訊云分布式云存儲服務之上,計算層全面兼容開源數據庫引擎 MySQL 5.7、8.0,業務無需改造即可平滑遷移。
- 超高性能
單節點百萬 QPS 的超高性能,可以滿足高并發高性能的場景,保證關鍵業務的連續性,并可進一步提供讀寫分離以及讀寫擴展性。
- 海量存儲
最高支持 PB 級的海量存儲,為用戶免去面對海量的數據時頻繁分庫分表的繁瑣操作,同時支持數據壓縮,在海量數據檢索和寫入性能上進行了大量優化。
- 秒級故障恢復
計算節點實現了無狀態,支持秒級的故障切換和恢復,即便計算節點所在的物理機宕機也可以在一分鐘之內恢復。
- 數據高可靠
集群支持安全組和 VPC 網絡隔離。自動維護數據和備份的多個副本,保障數據安全可靠,可靠性達99.9999999%。
- 彈性擴展
計算節點可根據業務需要快速升降配,秒級完成擴容,結合彈性存儲,實現計算資源的成本最優。
- 快速只讀擴展
計算節點可根據業務需要快速添加只讀節點,一個集群支持秒級添加或刪除1個 - 15個只讀節點,快速應對業務峰值和變化場景。
- 快照備份回檔
基于數據多版本的秒級快照備份對用戶的數據進行連續備份保護,免去主從架構備份回檔數據的同步和搬遷,最高以GB/秒的速度極速并行回檔,保證業務數據迅速恢復。
- Serverless 架構
Serverless 是騰訊自研云原生數據庫 TDSQL-C MySQL 版的無服務器架構版,自動擴縮容,僅按照實際使用量計費,不用不計費,輕松應對業務數據量動態變化和持續增長。
三、TDSQL-C的應用場景
TDSQL-C MySQL版廣泛適用于多個行業和應用場景,具備以下條件和優勢:
-
互聯網移動應用:
- 提供商用數據庫級別的高性能和高可靠性,保證業務的平穩高效運行。
- 解決了傳統主備架構在彈性能力、同步效率和主備切換時間等方面的問題,保證系統的高可用性和業務的連續性。
- 全面兼容開源數據庫
MySQL,無需更改現有業務應用即可接入TDSQL-C MySQL版,助力企業平滑上云。
-
游戲應用:
- 提供敏捷靈活的彈性擴展,根據業務需求快速升降級和擴容,應對業務峰值。
- 支持
PB級的海量存儲,按存儲量計費,自動擴容,減少了合區合服的繁瑣操作,實現資源和成本的最優配置。 - 提供秒級的快照備份和快速回檔能力,對用戶數據進行連續保護。
-
電商、直播、教育行業:
- 支持秒級的升配,最多可擴展至15個節點,快速增加
QPS的能力,解決了傳統數據庫升配時間隨存儲量和宿主機資源增加而上升的問題。 - 提供優化的
IOPS能力,保證在高并發狀態下的出色數據寫入能力,適應業務峰值需求。 - 通過物理復制方式連接讀寫節點和只讀節點,大大降低了只讀節點與讀寫節點之間的延遲,滿足電商場景中買家和賣家數據的一致性讀取需求。
- 支持秒級的升配,最多可擴展至15個節點,快速增加
-
金融、保險企業:
- 采用多可用區架構,在多個可用區備份數據,提供容災和備份功能。
- 提供全方位的安全保障措施,如白名單、VPC網絡等,保護數據庫數據的訪問、存儲和管理。
- 通過共享分布式存儲設計,徹底解決了主從異步復制帶來的備庫數據非強一致性問題。
這些條件和優勢使TDSQL-C MySQL版適用于各種業務場景,包括高頻交易、快速增長業務、大數據量低頻查詢、金融數據安全、開發測試和成本敏感場景。
四、基于TDSQL-C 存儲爬取的QQ音樂歌單數據
我這次準備使用 TDSQL-C Serverless MySQL 快速搭建一個爬蟲應用,這里我們打算使用 Python來實現,來體驗 云原生數據庫 TDSQL-C 給我們帶來的優勢。
如下為最項目代碼如下:
讓我們開始構建吧!!!
1、創建TDSQL-C Serverless數據庫

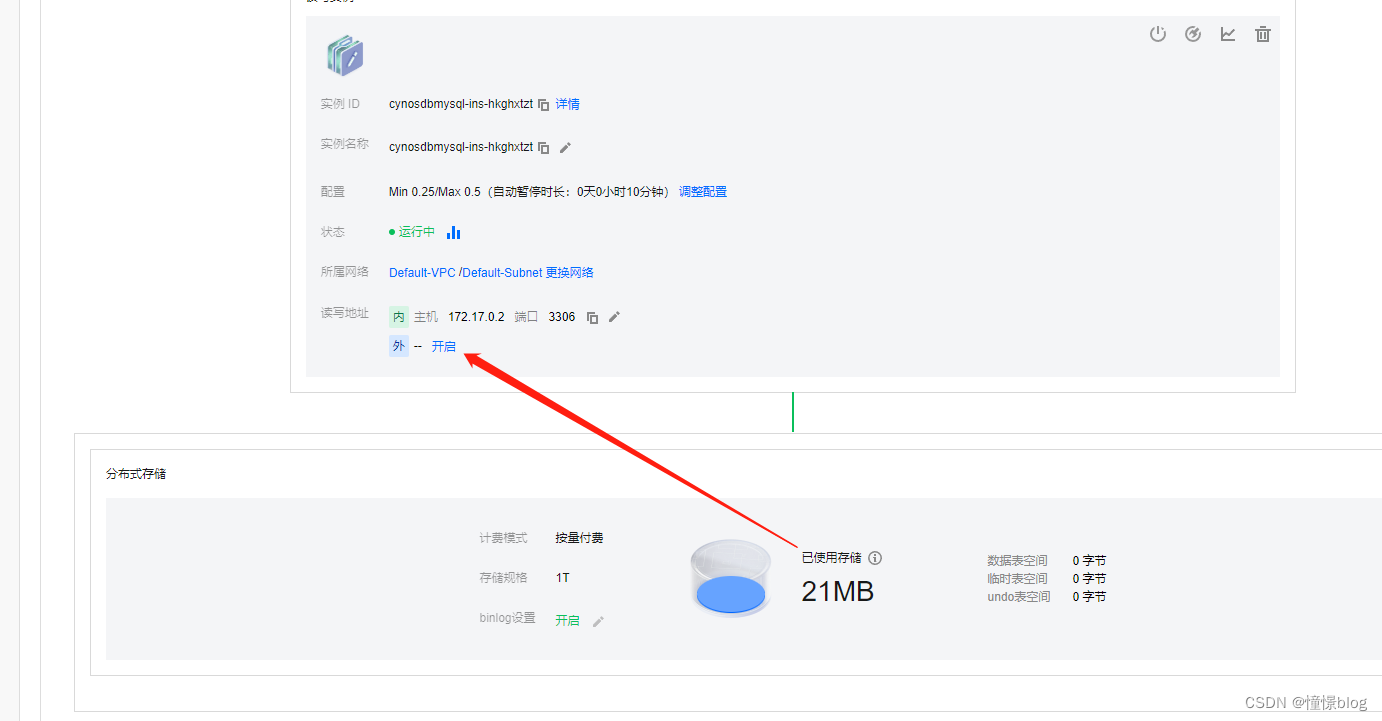
一直下一步購買后就能在TDSQL-C集群列表中看見

- 為了方便后續我們開發程序,我們需要先將數據庫的外網訪問打開
2、創建所需數據庫并通過DMC進行數據庫管理


- 通過 DMC 創建數據表
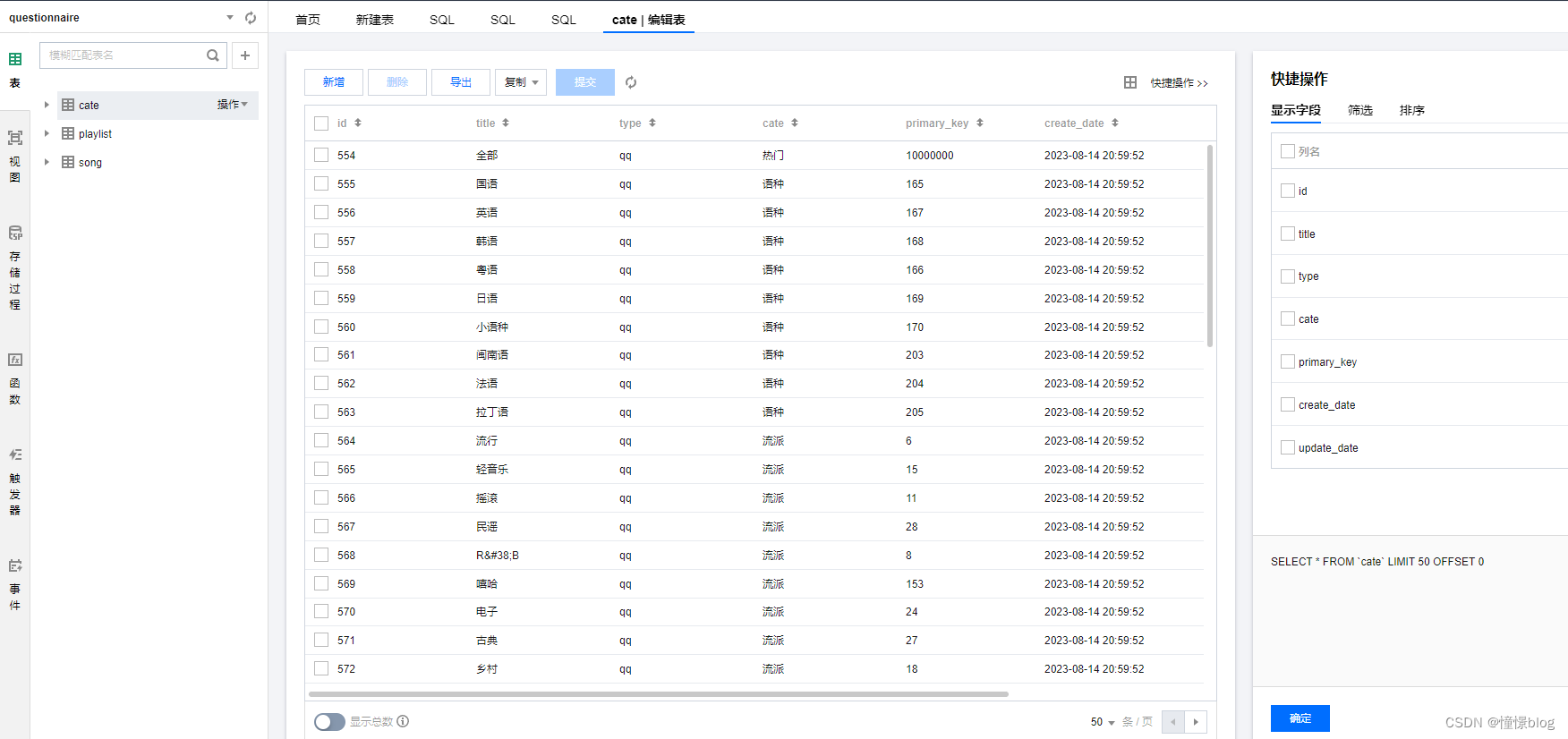
CREATE TABLE `cate` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`title` varchar(255) DEFAULT NULL,`type` varchar(255) DEFAULT NULL COMMENT 'kg | kw | wyy | qq',`cate` varchar(255) DEFAULT NULL COMMENT '分類',`primary_key` bigint(255) DEFAULT NULL COMMENT '平臺主鍵',`create_date` datetime DEFAULT NULL,`update_date` datetime DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,UNIQUE KEY `u` (`type`,`primary_key`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;CREATE TABLE `playlist` (`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,`title` varchar(255) DEFAULT NULL COMMENT '標題',`desc` longtext COMMENT '描述',`cate` varchar(255) DEFAULT NULL COMMENT '類型',`cate_id` varchar(255) DEFAULT NULL,`is_own` tinyint(255) DEFAULT '1' COMMENT '1 第三方創建的 2自己創建的',`primary_key` varchar(255) DEFAULT NULL COMMENT '第三方歌單主鍵',`key_type` char(10) DEFAULT NULL COMMENT 'qq | kg | wyy | kw ',`thumb_img` longtext COMMENT '封面',`tag` text COMMENT '標簽 ,',`tag_id` text COMMENT '標簽id ,拆分',`author` varchar(255) DEFAULT NULL COMMENT '作者',`author_id` bigint(255) DEFAULT NULL COMMENT '作者id',`collect_num` bigint(20) DEFAULT '0' COMMENT '收藏數量',`share_num` bigint(20) DEFAULT '0' COMMENT '分享數量',`comment_num` bigint(255) DEFAULT '0' COMMENT '評論數量',`play_num` bigint(20) DEFAULT '0' COMMENT '歌單播放次數',`song_num` bigint(20) DEFAULT '0' COMMENT '歌單歌曲數量',`platform_create_date` datetime DEFAULT NULL COMMENT '第三方歌單創建時間',`create_date` datetime DEFAULT NULL,`update_date` datetime DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
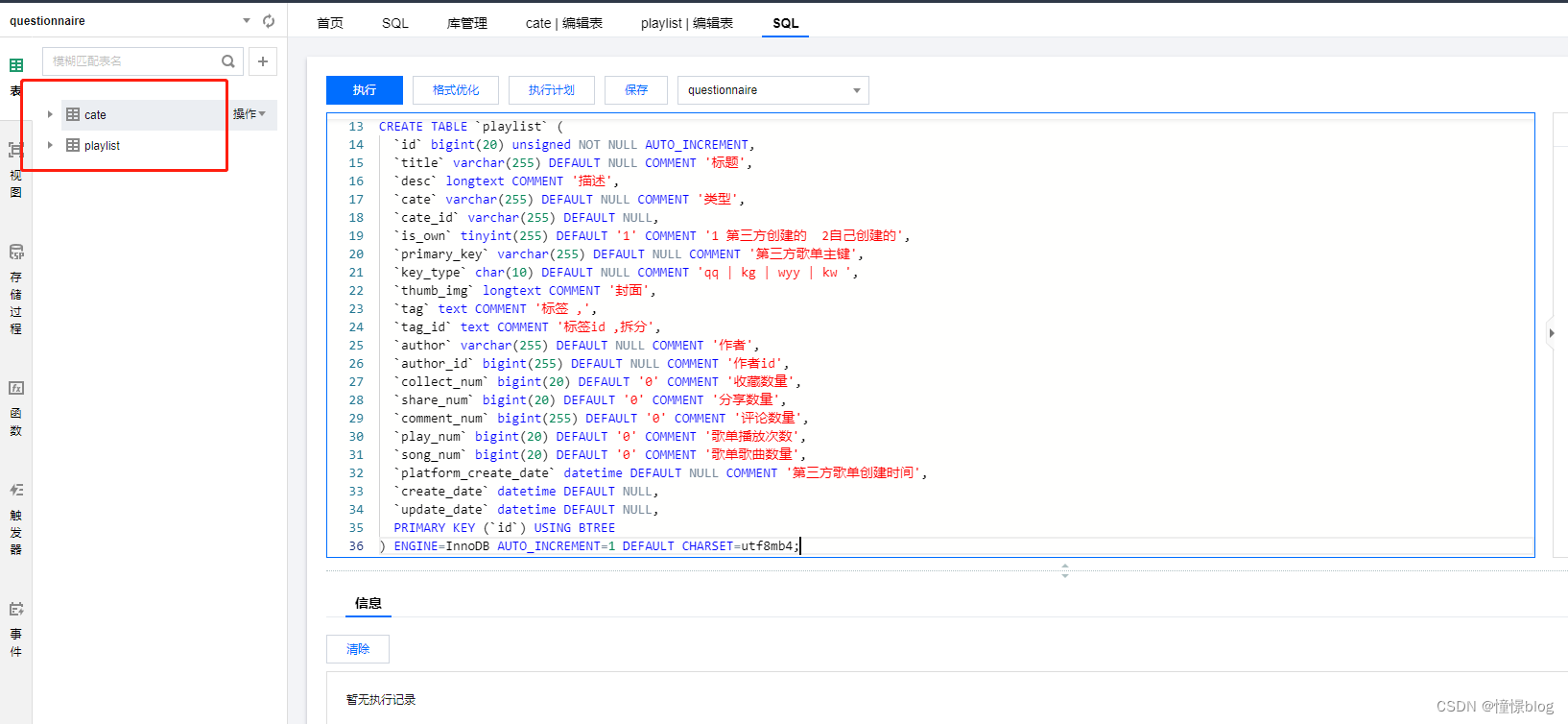
一個是分類表,用于存儲歌單的分類信息,然后通過分類去獲取歌單列表
另一個是歌單表,用于存儲爬取的歌單數據
3、構建QQ音樂歌單爬蟲
3.1 初始化框架環境
這里我采用了 feapder 這個輕量級框架
- 安裝
feapder爬蟲框架
pip3 install feapder[all]
- 創建爬蟲項目
feapder create -p QQSpider
- 在
setting.py中配置TDSQL-C數據庫以及redis信息
# # MYSQL
MYSQL_IP = "gz-xxxxxx"
MYSQL_PORT = 28671
MYSQL_DB = "questionnaire"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "123456"# # REDIS
# # ip:port 多個可寫為列表或者逗號隔開 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
REDISDB_IP_PORTS = "x"
REDISDB_USER_PASS = "x"
REDISDB_DB = 7
- 安裝依賴 requirements.txt
feapder~=1.7.7
pycryptodome
Flask~=2.2.2
pillow~=9.2.0
requests-toolbelt
requests~=2.27.1
apscheduler~=3.9.1
js2py~=0.71
urllib3~=1.26.11
pytz~=2022.1
gevent~=21.12.0
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
為了方便可以把這個 shell 寫在項目的根目錄
3.2 在spiders下創建分類爬蟲
- category.py
import feapder
import urllib.parsefrom feapder import Requestfrom items.cateItem import CateItemclass CategorySpider(feapder.Spider):commonParams = {'g_tk': 1124214810,'loginUin': '0','hostUin': 0,'inCharset': 'utf8','outCharset': 'utf-8','notice': 0,'platform': 'yqq.json','needNewCode': 0,}apiHeader = {'referer': 'https://c.y.qq.com/','host': 'c.y.qq.com'}domain = 'https://c.y.qq.com'def start_requests(self):url = "/splcloud/fcgi-bin/fcg_get_diss_tag_conf.fcg?" + self.getParams({'format': 'json','outCharset': 'utf-8',})yield self.request(url, method="GET")def request(self, path, **kwargs):req = Request(self.domain + path, **kwargs)return self.downloadMidware(req)def downloadMidware(self, request):if request.url.startswith('https://y.qq.com/n/ryqq/playlist'):return requestrequest.headers = self.apiHeaderreturn requestdef getParams(self, params):data = paramsdata.update(self.commonParams)return urllib.parse.urlencode(data)def validate(self, request, response):jsonData = response.jsonif jsonData['code'] != 0:raise Exception(jsonData['message'])return Truedef parse(self, request, response):jsonData = response.jsonfor cate in jsonData['data']['categories']:cateName = cate['categoryGroupName']for item in cate['items']:cateItem = CateItem()cateItem.primary_key = item['categoryId']cateItem.title = item['categoryName']cateItem.type = "qq"cateItem.cate = cateNameyield cateItemif __name__ == "__main__":CategorySpider(redis_key="qq_category:spider").start()這里我們還要配置一下 ORM,在itmes目錄下創建 cateItem,用于映射數據庫表,方便直接入庫,不用編寫原生SQL
- items/cateItem.py
from feapder import Item
from feapder.utils import toolsclass CateItem(Item):"""This class was generated by feapder.command: feapder create -i spider_data."""__unique_key__ = ["title", "cate", "type", 'primary_key'] # 指定去重的key為 title、url,最后的指紋為title與url值聯合計算的md5def __init__(self, *args, **kwargs):# self.id = Nonesuper().__init__(**kwargs)self.table_name = "cate"self.title = Noneself.cate = Noneself.primary_key = Noneself.type = Noneself.create_date = Noneself.update_date = Nonedef pre_to_db(self):"""入庫前的處理"""self.create_date = tools.format_time("剛剛")self.update_date = tools.format_time("剛剛")- 運行測試爬取分類數據
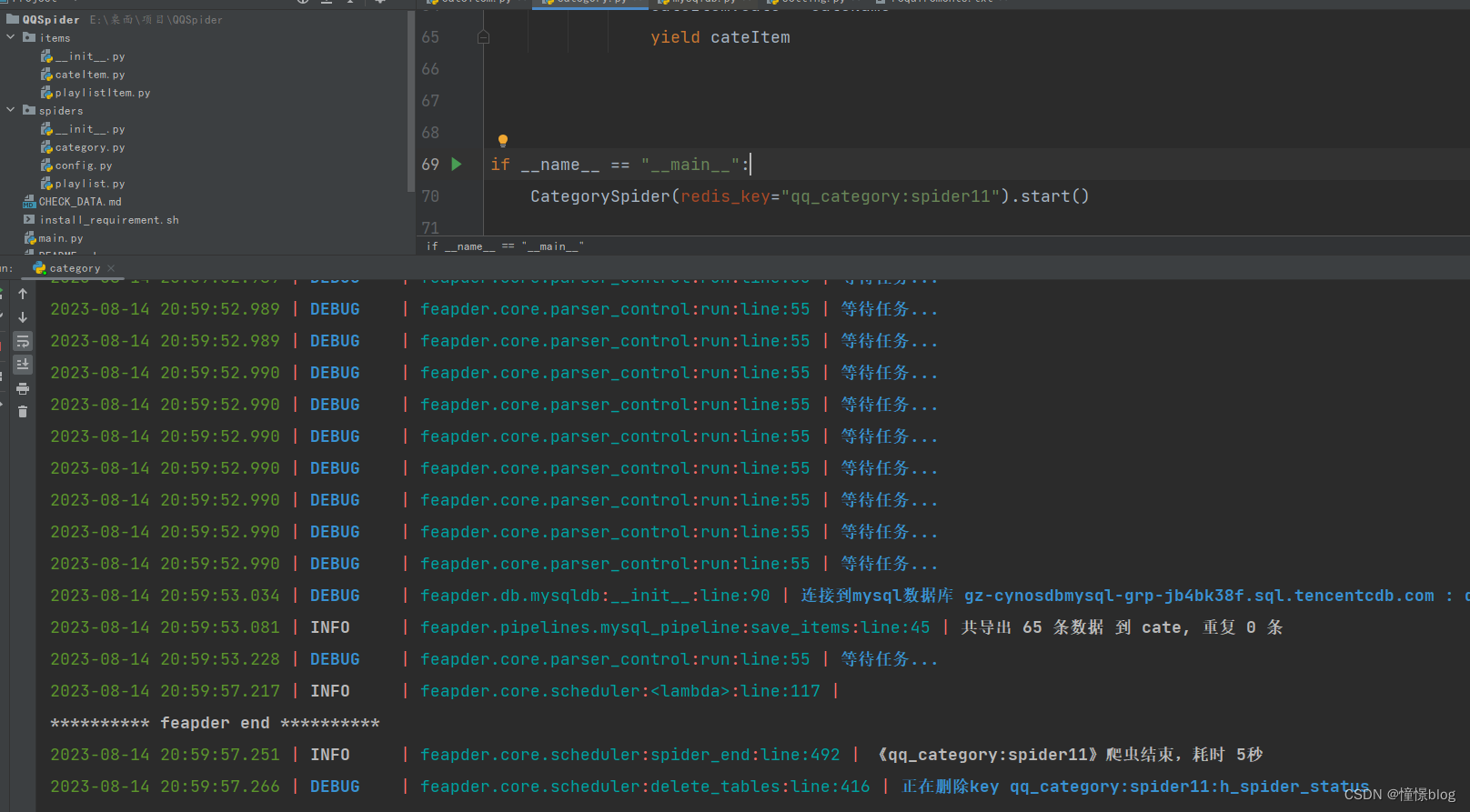
可以看到數據已經全部入庫了
3.3 在spiders下創建歌單爬蟲
同理,我們先建立一下歌單表的 ORM
- items/playlistItem.py
from feapder import Item
from feapder.utils import toolsclass PlaylistItem(Item):def __init__(self, *args, **kwargs):# self.id = Nonesuper().__init__(**kwargs)self.table_name = "playlist"self.title = Noneself.desc = Noneself.primary_key = Noneself.cate = Noneself.cate_id = Noneself.key_type = Noneself.thumb_img = Noneself.tag = Noneself.tag_id = Noneself.author = Noneself.author_id = Noneself.collect_num = Noneself.share_num = Noneself.comment_num = Noneself.play_num = Noneself.song_num = Noneself.platform_create_date = Noneself.create_date = Noneself.update_date = Nonedef pre_to_db(self):"""入庫前的處理"""self.create_date = tools.format_time("剛剛")self.update_date = tools.format_time("剛剛")然后創建爬蟲
- spiders/playlist.py
import urllib.parseimport feapder
from feapder import Request
from feapder.db.mysqldb import MysqlDBfrom items.playlistItem import PlaylistItemclass PlayListSpider(feapder.Spider):commonParams = {'g_tk': 1124214810,'loginUin': '0','hostUin': 0,'inCharset': 'utf8','outCharset': 'utf-8','notice': 0,'platform': 'yqq.json','needNewCode': 0,}apiHeader = {'referer': 'https://c.y.qq.com/','host': 'c.y.qq.com'}domain = 'https://c.y.qq.com'def start_requests(self):db = MysqlDB()cateList = db.find(sql="select * from cate where type = 'qq'", to_json=True)for cate in cateList:yield self.getPlaylistByCateId(cate['primary_key'], cate['title'])def getPlaylistByCateId(self, cateId, cateTitle, page=0, limit=50, sortId=5):sin = +page * +limitein = +limit * (+page + 1) - 1params = self.getParams({'format': 'json','outCharset': 'utf-8','picmid': 1,'categoryId': cateId,'sortId': sortId,'sin': sin,'ein': ein,})url = "/splcloud/fcgi-bin/fcg_get_diss_by_tag.fcg?" + paramsreturn self.request(url, method="GET", page=page, limit=limit, cateId=cateId, cateTitle=cateTitle)def getParams(self, params):data = paramsdata.update(self.commonParams)return urllib.parse.urlencode(data)# 構造請求def request(self, path, **kwargs):req = Request(self.domain + path, **kwargs)return self.downloadMidware(req)# 構造請求頭def downloadMidware(self, request):if request.url.startswith('https://y.qq.com/n/ryqq/playlist'):return requestrequest.headers = self.apiHeaderreturn requestdef validate(self, request, response):jsonData = response.jsonif jsonData['code'] != 0:raise Exception(jsonData['message'])return Truedef parse(self, request, response):jsonData = response.jsonplaylist = jsonData['data']['list']for item in playlist:playlist = PlaylistItem()playlist.title = item.get('dissname')playlist.thumb_img = item.get('imgurl')playlist.create_date = item.get('createtime')playlist.primary_key = item.get('dissid')playlist.desc = item.get('introduction')playlist.play_num = item.get('listennum')playlist.cate = request.cateTitleyield playlist# 分頁處理if len(playlist) != 0:yield self.getPlaylistByCateId(request.cateId, request.cateTitle, request.page + 1, request.limit)# 通過分類id獲取歌單列表if __name__ == "__main__":PlayListSpider(redis_key="qq_playlist:spider").start()運行爬蟲后可以看到數據庫的吞吐率很高,一會就有幾千條數據了
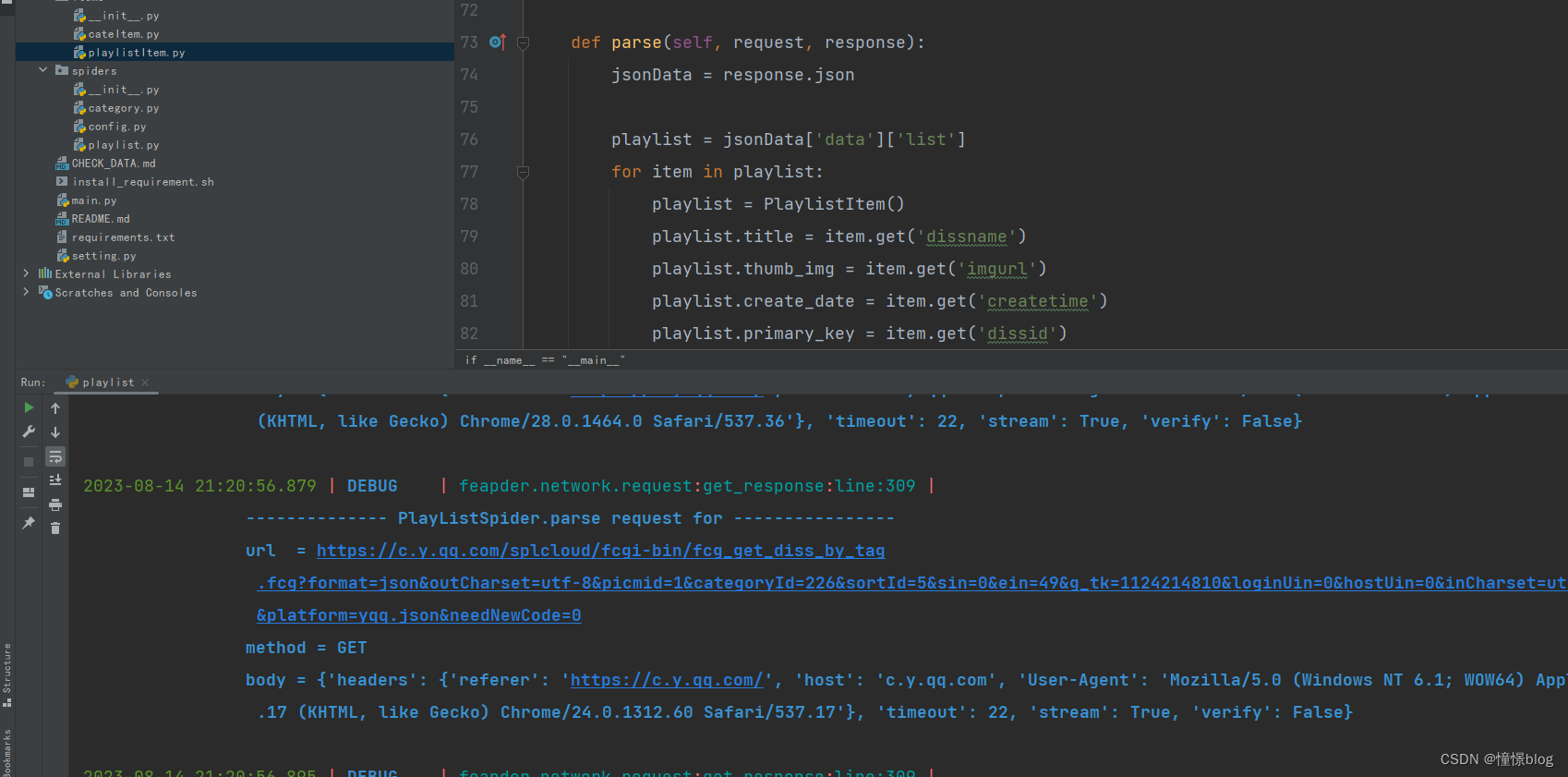
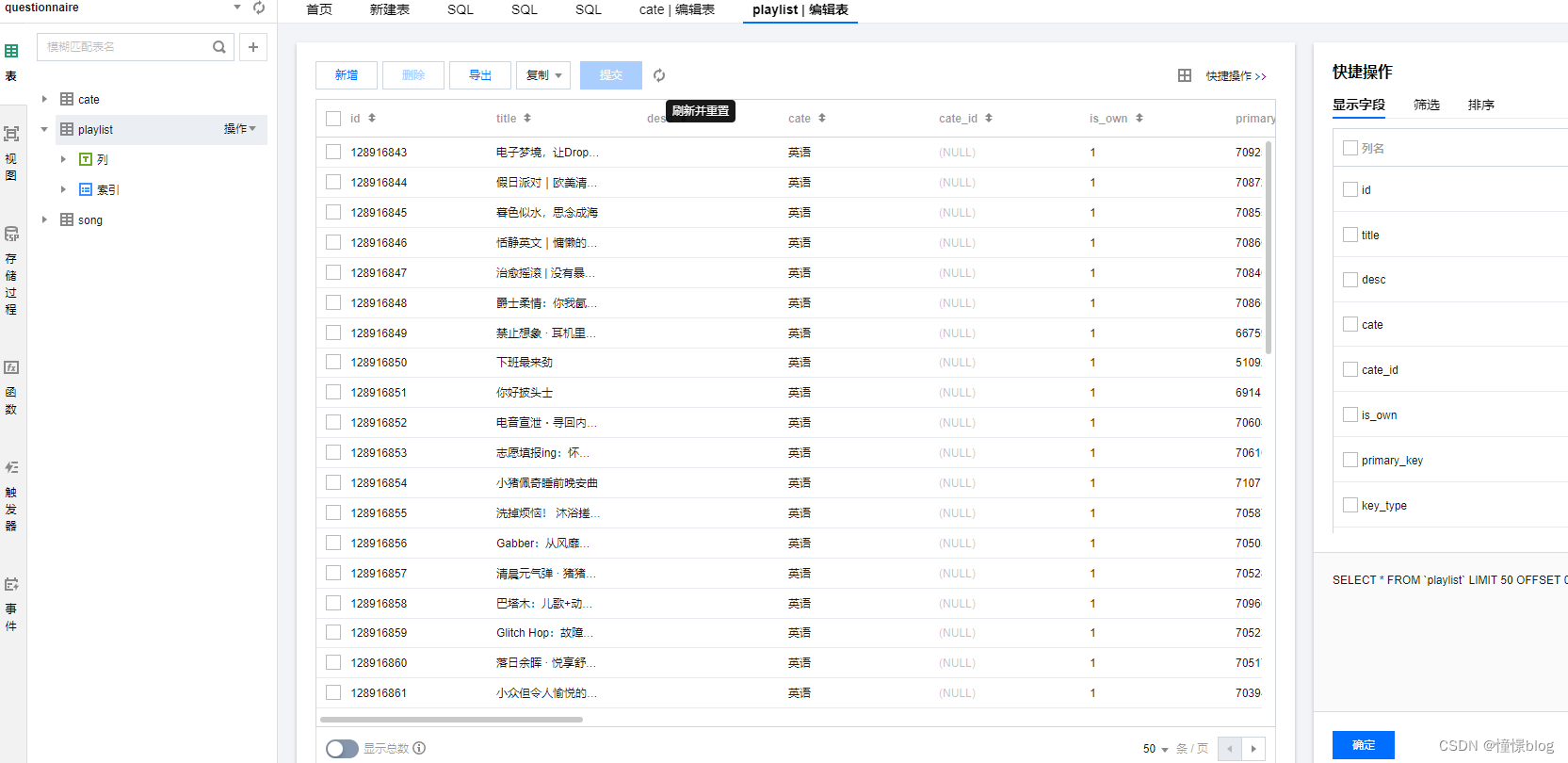
4、進行數據庫狀態觀察
在爬取的過程中,我一直擔心數據庫會成為應用的瓶頸,沒想到最低配的 TDSQL-C 性能也是異常的強悍,期間通過自帶的監控告警,也是很方便觀察到秒級性能波動
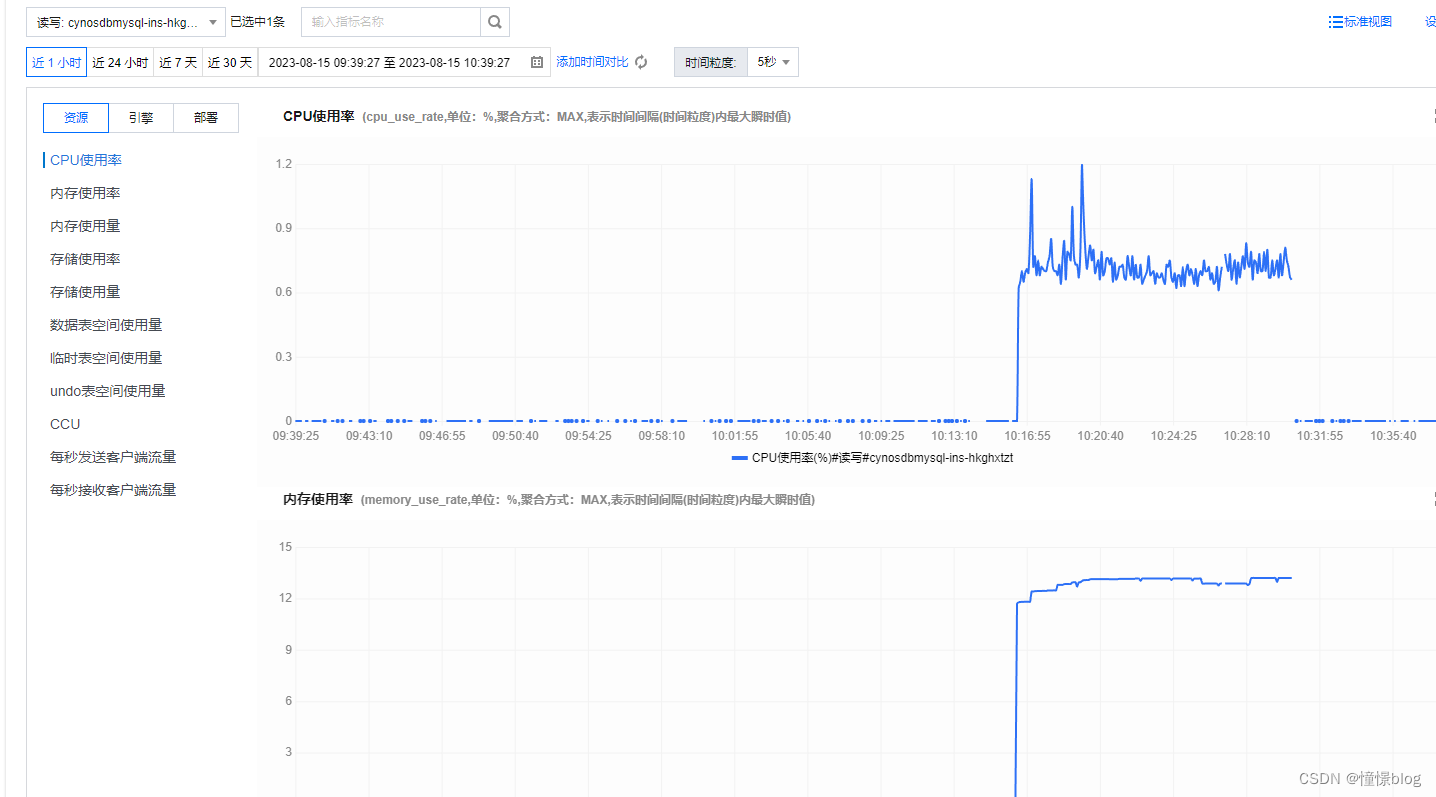
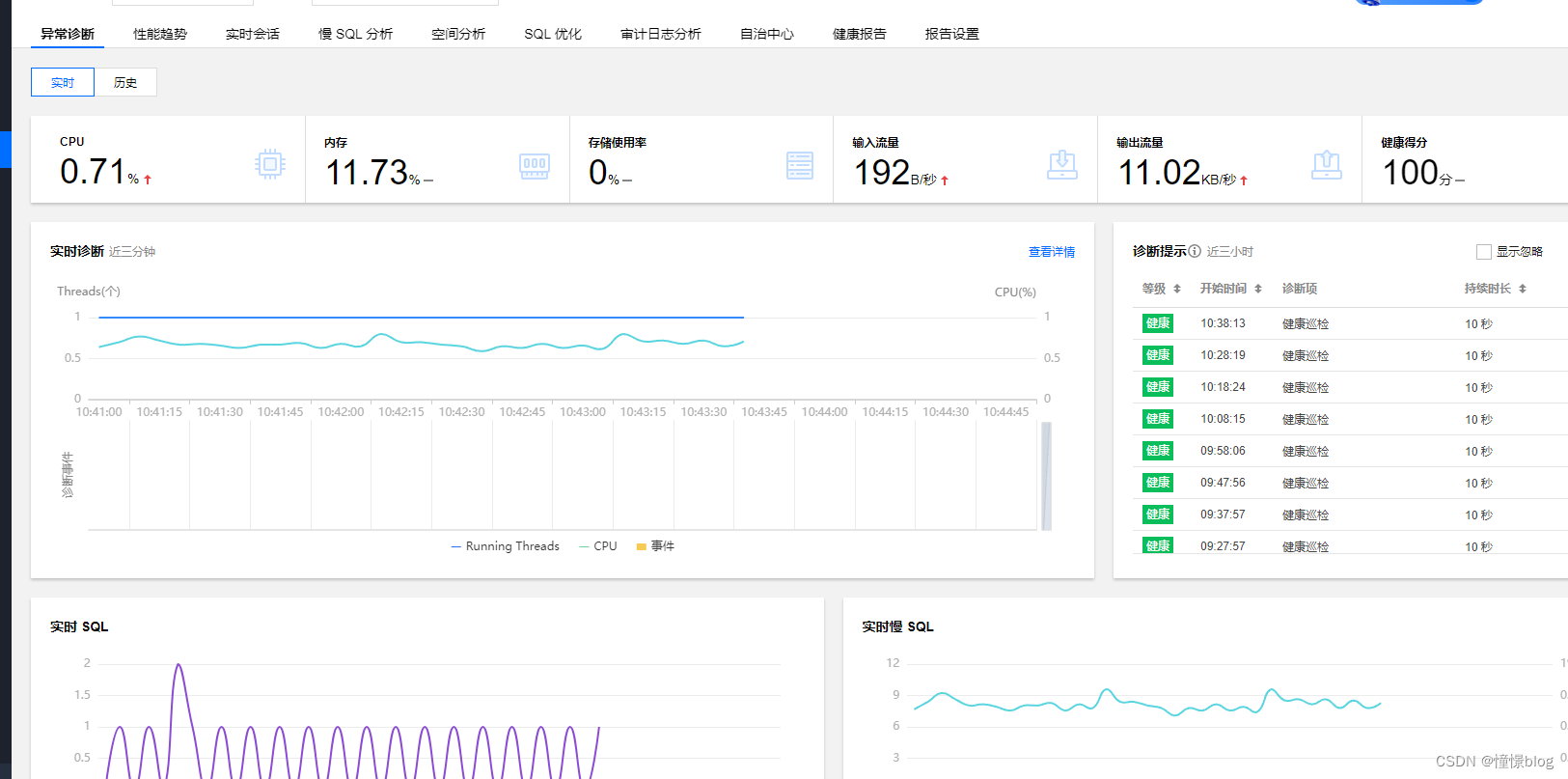
然后 TDSQL-C 旁邊還有個 數據庫智能管家,這是一個非常利于我們在線運維的工具,他可以看到當前實例的:異常、性能趨勢、實時會話、慢SQL分析、SQL優化、審計日志等等
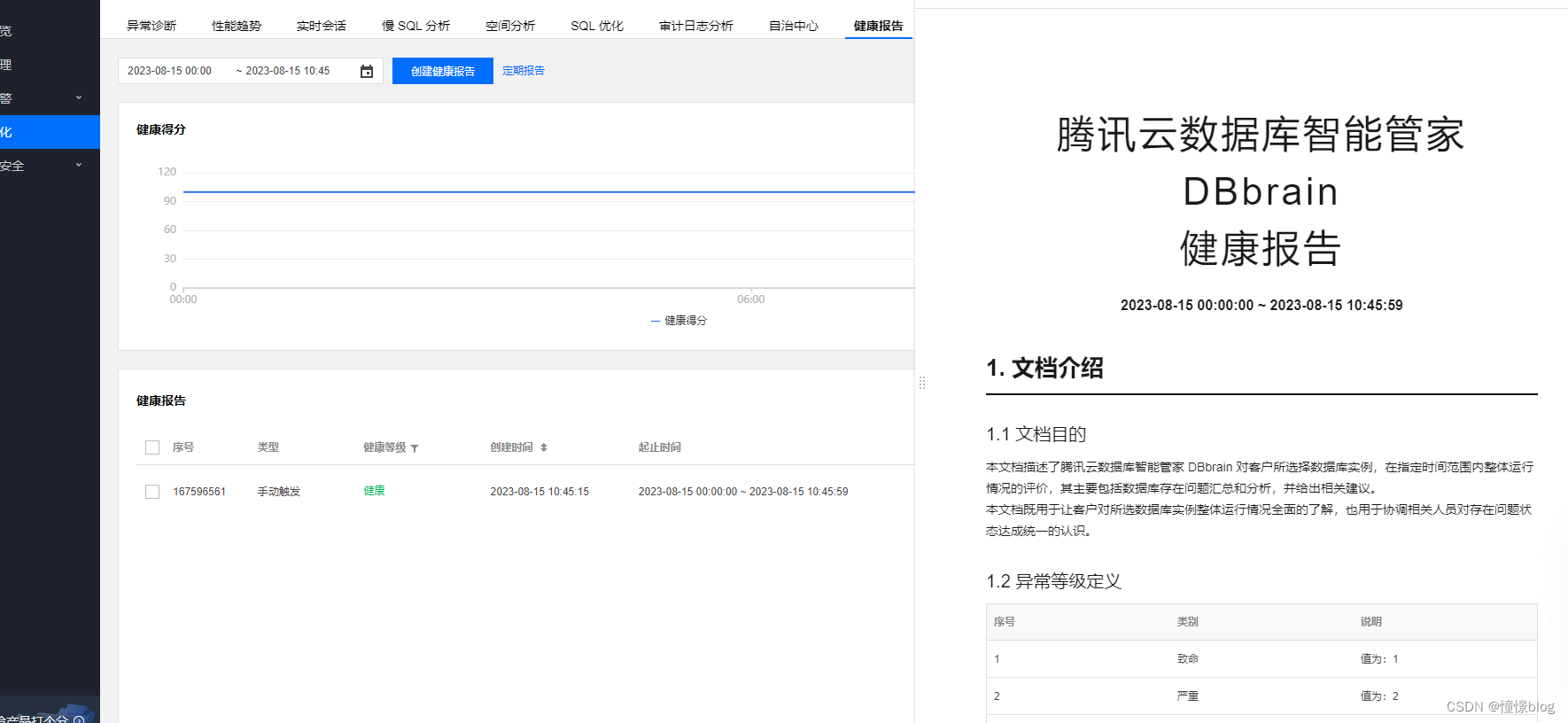
他還可以為我們根據時間區間創建健康報告,讓我們清晰地了解到數據庫實例的健康狀態,針對重要項目,我們可以設置定期報告,然后通過郵箱接收報告內容,從而減輕我們的運維負擔
總結
本次案例主要讓大家對云原生數據庫 TDSQL-C Serverless 有一個基本的認識,可以看到 TDSQL-C Serverless 與平時所使用的 Sql 語法差不多一致,基本上沒有什么學習成本,開箱即用,可以快速上手,真正的無縫接入, 異常的絲滑!!
針對本次體驗,我也總結了一些優點與遇到的一些問題,希望分享給大家,能給大家帶來一些技術選型建議:
- 其中優點有:
- 其中在
TDSQL-C的特點中:高性能、海量存儲、完全兼容Mysql、快照備份等都能夠非常直接感受到,確實如描述所說,屬于名副其實了,這個我也不過多贅述。 - 通過對傳統數據庫的了解,實際上對于采用 ServerLess 架構的數據庫,是對中小公司的更好選擇,通過靈活的計費模式,按量付費不需要承擔過多的人力成本、運維成本就可以獲得一個高可用、高性能基礎設施,從而實現降本增效
TDSQL-C還可以非常簡單面對各種大流量場景,其中有一個非常簡單易用的功能就輸數據庫的流量負載均衡,通過設置RO組只讀實例的集合,然后通過權重進行流量負載均衡,相應的讀請求按一定規則發送到只讀實例,能夠顯著提高數據庫的讀負載能力。- 在產品上比較完備,感覺很細節,在提供數據庫的同時也提供了數據庫的可視化管理,不用再去下載數據庫管理客戶端就可以實現庫表級操作、實時監控、實例會話管理、
SQL窗口等操作;同時也有智能監控、健康管理分析等輔助工具,非常適合我這種懶人。
- 遇到的一些小問題:
- 將這個程序部署到騰訊云服務器的時候,發現使用內網地址連接不了這個 TDSQL-C 數據庫,但是公網沒問題,可是想著內網可以有更高的效率,于是一直排查,最后也是從文檔上發現,原來輕量型不能直接通過內網地址連接 TDSQL-C MySQL 版進行訪問,使用 云聯網 互通

- 期間在對數據庫進行壓力測試的時候,出現
Too many connections,后續排查發現是因為數據庫默認連接數是80
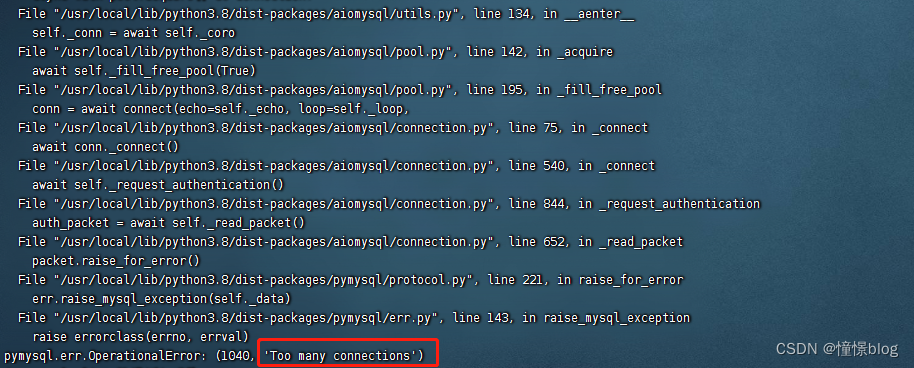
后面將這個默認值改大之后就再也沒出現過了:

參考文獻
騰訊云TDSQL-C官方文檔
feapder框架





)


)





)



)
