內核同步方法
- 1 原子操作
- 原子整數操作
- 原子性與順序性的比較
- 原子位操作
- 2 自旋鎖
- 自旋鎖是不可遞歸的
- 其他針對自旋鎖的操作
- 自旋鎖和下半部
- 3 讀-寫自旋鎖
- 4 信號量
- 創建和初始化信號量
- 使用信號量
- 5 讀-寫信號量
- 6 自旋鎖和信號量
- 7 完成變量
- 8 互斥鎖
- 互斥鎖API
- 9 禁止搶占
- 10 順序和屏障
1 原子操作
原子操作是保證指令以原子的方式執行,執行過程不被打斷。內核提供了兩組原子接口,一組針對整數進行操作,另一組針對單獨的位進行操作。在Linux支持的所有體系結構上都實現了這兩組接口。
原子整數操作
針對整數的原子操作只能對atomic_t類型的數據進行處理。Linux支持的所有機器上的整數數據都是32位的,但是使用atomic_t的代碼只能將該類型的數據當做24位來用。這個限制完全是因為在SPARC體系結構上,原子操作的實現不同于其他體系結構:32位int類型的低8位嵌入了一個鎖,
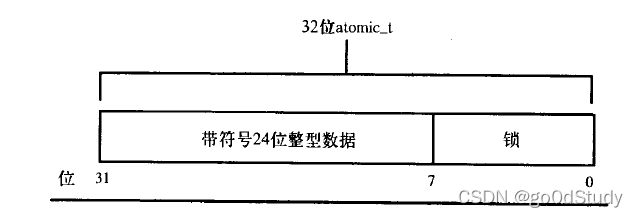
因為SPARC體系結構對原子操作缺乏指令級的支持,所有只能利用該鎖來避免對原子類型數據的并發訪問。
原子操作的聲明在<asm/atomic.h>文件中。所有的體系結構內核會提供一些相同的方法,有些體系結構會提供一些在該體系結構上使用的額外原子操作方法。
定義一個atomic_t類型的數據,還可以在定義時給它設定初值:
atomic_t v; /* 定義v */
atomic_t u = ATOMIC_INIT(0); /* 定義u并把u初始化為0 */
原子整數操作列表如下:

原子性與順序性的比較
原子性確保指令執行期間不被打斷,要么全部執行完,要么根本不執行。而順序性確保即使兩條或多條指令出現在獨立的執行線程中,它們要執行順序要按規定的執行。例如,給一個整數初始化為10,要么初始化成功,要么初始化失敗,這就是原子性。接著又有一個操作給整數初始化為20,原子性不管是先初始化為10還是先初始化為20,這是順序性的責任。
原子位操作
原子性操作是與體系結構相關的操作,定義在文件<asm/bitops.h>中。位操作函數是對普通的內存地址進行操作的,它的參數是一個指針和一個尾號。原子位操作的列表如下:

內核還提供了兩個例程用來從指定的地址開始搜素第一個被設置(未被設置)的位
int find_first_bit(unsigned long *addr,unsigned int size);
int find_first_zero_bit(unsigned long *addr,unsigned int size);
2 自旋鎖
Linux內核最常見的鎖是自旋鎖(spin lock)。自旋鎖最多只能被一個可執行線程持有。如果一個執行線程試圖獲得一個被爭用(已經被使用)的自旋鎖,那么該線程就會一直進行忙循環,等待鎖重新可用。在任何時刻,自旋鎖都可以防止多余一個的執行線程同時進入臨界區。
如果自旋鎖已經被爭用了,那么請求它的線程在等待鎖重新可用時將一直自旋,所以特別浪費處理器時間,因此自旋鎖不應該被長時間持有。
自旋鎖的實現和體系結構密切相關,代碼往往通過匯編實現。這些與體系結構相關的代碼定義在文件<asm/spinlock.h>中,實際需要用到的接口定義在文件<linux/spinlock.h>中。自旋鎖的基本使用形式如下:
spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;spin_lock(&mr_lock);
/* 臨界區 */
spin_unlock(&mr_lock);
因為自旋鎖在同一時刻至多被一個執行線程持有,所以一個時刻只能有一個線程位于臨界區內,這就為多處理器機器提供了防止并發訪問所需的保護機制。注意在單處理器機器上,編譯的時候并不會加入自旋鎖,它僅僅被當做一個設置內核搶占機制是否被啟用的開關。如果禁止內核搶占,那么在編譯時自旋鎖會被完全剔除內核。
自旋鎖是不可遞歸的
Linux內核實現的自旋鎖是不可遞歸的,如果你請求一個你已經持有的自旋鎖,那么你將會自旋,等待釋放這個鎖,由于自旋,釋放這個鎖的操作不會執行,所有會一直處于自旋忙等待中,于是你被自己鎖死了。
自旋鎖可以使用在中斷處理程序中。在中斷處理程序中使用自旋鎖時,一定要在獲取鎖之前,首先禁止本地中斷(當前處理器上的中斷請求),否則,中斷處理程序就會打斷正持有鎖的內核代碼,有可能試圖去爭用這個已經被持有的自旋鎖。這樣一來,中斷處理程序就會自旋,但是鎖的持有者在這個中斷處理程序執行完畢前不可能運行,會造成死鎖。注意,需要關閉的只是當前處理器上的中斷,如果中斷發生在不同的處理器上,即使中斷處理程序在同一鎖上自旋,也不會妨礙鎖的持有者最終釋放鎖。
內核提供的禁止中斷同時請求鎖的接口:
spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;
unsigned long flags;spin_lock_irqsave(&mr_lock,flags);
/* 臨界區 */
spin_lock_irqrestore(&mr_lock,flags);
函數spin_lock_irqsave保存中斷的當前狀態,并禁止中斷,然后再去獲取指定的鎖。反過來spin_lock_irqrestore對指定的鎖解鎖,然后讓中斷恢復到加鎖前的狀態。
配置選項CONFIG_DEBUG_SPINLOCK為使用自旋鎖的代碼加入了許多調試檢測手段。
其他針對自旋鎖的操作
spin_lock_init()用來初始化動態創建的自旋鎖。spin_try_lock試圖獲得某個特定的自旋鎖,其他自旋鎖操作如下:

自旋鎖和下半部
由于下半部可以搶占進程上下文中的代碼,所以當下半部和進程上下文共享數據時,必須對進程上下文中的共享數據進行保護,所以需要加鎖的同時還要禁止下半部執行。同樣,由于中斷程序程序可以搶占下半部,所以如果中斷處理程序和下半部共享數據,那么就必須在獲取恰當的鎖的同時還要禁止中斷。
3 讀-寫自旋鎖
Linux提供了專門的讀寫自旋鎖,這種自旋鎖為讀和寫分別提供了不同的鎖,一個或多個讀任務可以并發的持有讀者鎖;相反,用于寫的鎖最多只能被一個寫任務持有,而且此時不能有并發的讀操作。有時把讀寫鎖叫做共享排斥鎖,或者并發排斥鎖,因為這種鎖以共享(對讀者而言)和排斥(對寫著而言)的形式獲得使用。
加鎖邏輯:
- 假設臨界區內沒有任何的thread,這時候任何read thread或者write thread可以進入
- 假設臨界區內有一個read thread,這時候新來的read thread可以任意進入,但是write thread不可以進入
- 假設臨界區有一個write thread,這時候任何的read thread或者write thread 都不可以進入
- 假設臨界區內有一個或者多個read thread,write thread當然不可以進入臨界區,但是該write thread也無法阻止后續read thread的進入,他要一直等到臨界區一個read thread也沒有的時候,才可以進入。可見,rw spinlock給reader賦予了更高的權限。
讀寫自旋鎖的使用方式類似于普通自旋鎖:
rwlock_t my_rwlock = RW_LOCK_UNLOCKED; /* 初始化 */
read_lock(&my_rwlock);
/* 臨界區 只讀*/
read_unlock(&my_lock);
在可以寫的臨界區加上如下代碼:
write_lock(&my_rwlock);
/* 臨界區(寫) */
write_unlock(&my_rwlock);
不能同時請求讀鎖和寫鎖:
read_lock(&my_rwlock);
write_lock(&my_rwlock);
這樣將會帶來死鎖,因為寫鎖會不斷自旋,而讀鎖得不到釋放。
針對讀寫自旋鎖的操作如下:

在使用Linux讀-寫自旋鎖時,最后要考慮的一點是這種鎖照顧讀比照顧寫要多一點,當讀鎖被持有時,寫操作為了互斥訪問只能等待,但是,讀者卻可以繼續成功地占用鎖。而自旋等待的寫者在所有讀者釋放鎖之前是無法獲得鎖的。
自旋鎖提供了一種快速簡單的鎖實現方式,如果加鎖時間不長并且代碼不會休眠,利用自旋鎖時最佳選擇。
4 信號量
Linux中的信號量是一種睡眠鎖。如果有一個任務試圖獲得一個已經被占用的信號量時,信號量會將其放到一個等待隊列,然后讓其睡眠。這時處理器能去執行其他代碼。當持有信號量的進程將信號量釋放后,處于等待隊列中的那個任務將被喚醒,并獲得該信號量。
信號量可以同時允許任意數量的鎖持有者,而自旋鎖在一個時刻最多允許一個任務持有它。信號量同時允許的持有者數量可以在聲明信號量時指定,這個值稱為使用者數量。通常情況下,信號量和自旋鎖一樣,在一個時刻僅允許有一個鎖持有者。當數量等于1,這樣的信號量被稱為二值信號量或者被稱為互斥信號量;初始化時也可以把數量設置為大于1的非0值,這種情況,信號量被稱為計數信號量,它允許在一個時刻至多有count個鎖持有者。
信號量支持兩個原子操作P()和V()。前者叫做測試操作,后者叫做增加操作,后來系統把這兩種操作分別叫做down()和up(),Linux也遵從這種叫法。down()通過對信號量減1來請求一個信號量,如果減1結果是0或者大于0,那么就獲得信號量鎖,任務就可以進入臨界區,如果結果是負的,那么任務會被放入等待隊列。相反,當臨界區的操作完成后,up()操作用來釋放信號量,如果在該信號量上的等待隊列不為空,那么處于隊列中等待的任務被喚醒。
創建和初始化信號量
信號量的實現是與體系結構有關的,具體實現定義在文件<asm/semaphore.h>中。struct semaphore類型表示信號量。可以通過以下方式靜態聲明信號量:
static DECLARE_SEMAPHORE_GENERIC(name,count);
其中name是信號量變量名,count是信號量的使用者數量。創建更為普通的互斥信號量可以使用以下方式:
static DECLARE_MUTEX(name);
我們可以使用sema_init對信號量進行動態初始化:
sema_init(sem,count);
sem是指針,count是信號量的使用者數量。初始化一個動態創建的互斥信號量時使用以下函數:
sema_MUTEX(sem)
使用信號量
函數down_interruptible()試圖獲取指定的信號量,如果獲取失敗,它將以TASK_INTERRUPTIBLE狀態進入睡眠。如果進程在等待獲取信號量的時候接受到了信號,那么該進程就會被喚醒,而函數down_interruptible()會返回EINTR。另外一個函數down()獲取信號量失敗會讓進程在TASK_UNINTERRUPTIBLE狀態下睡眠,我們應該避免這種情況,因為進程等待信號量的時候就不再響應信號了。
使用down_trylock()函數,可以嘗試獲取指定的信號量,在信號量被占用時,它立刻返回非0值,否則,返回0,并且成功獲取信號量鎖。
要釋放指定的信號,需要調用up()函數。

針對信號量的操作如下表:

5 讀-寫信號量
與自旋鎖一樣,信號量也有區分讀寫訪問的可能,。讀寫信號量在內核中是由rw_semaphore結構表示的,定義在文件<linux/rwsem.h>中。通過以下語句可以創建靜態聲明的讀寫信號量:
static DECLARE_RWSEM(name);
動態創建讀寫信號量可以通過下面的函數:
init_rwsem(struct rw_semaphore *sem)
所有的讀寫信號量都是互斥信號量(它們的引用計數等于1)。只要沒有寫著,并發持有讀鎖的讀者數不限。相反,只有唯一的寫者(沒有讀者時)可以獲得寫鎖。所有的讀寫鎖的睡眠都不會被信號打斷,它只有一個down()操作:

6 自旋鎖和信號量
在中斷上下文中只能使用自旋鎖,在任務睡眠時只能使用信號量。

7 完成變量
如果在內核中一個任務需要發出信號通知另一個任務發生了某個特定事件,利用完成變量是使兩個任務以同步的簡單方法。如果一個任務要執行一些工作時,另一任務就會在完成變量上等待,當這個任務完成后,會使用完成變量去喚醒在等待的任務。
完成變量由結構體completion表示,定義在<linux/cmpletion.h>中。可以通過以下方式創建:
DECLARE_COMPLETION(mr_comp) /* 靜態創建 */
init_completion() /* 動態創建 */
在一個指定的完成變量上,需要等待的任務調用wait_for_completion()來等待特定事件。當特定事件發生后,產生事件的任務調用complete()來發送信號喚醒正在等待的任務。
8 互斥鎖
Mutex(互斥鎖)是較常用的鎖機制,為了理解它是怎么工作的,來看一看它在include/linux/mutex.h中的結構定義:
/** Simple, straightforward mutexes with strict semantics:** - only one task can hold the mutex at a time* - only the owner can unlock the mutex* - multiple unlocks are not permitted* - recursive locking is not permitted* - a mutex object must be initialized via the API* - a mutex object must not be initialized via memset or copying* - task may not exit with mutex held* - memory areas where held locks reside must not be freed* - held mutexes must not be reinitialized* - mutexes may not be used in hardware or software interrupt* contexts such as tasklets and timers** These semantics are fully enforced when DEBUG_MUTEXES is* enabled. Furthermore, besides enforcing the above rules, the mutex* debugging code also implements a number of additional features* that make lock debugging easier and faster:** - uses symbolic names of mutexes, whenever they are printed in debug output* - point-of-acquire tracking, symbolic lookup of function names* - list of all locks held in the system, printout of them* - owner tracking* - detects self-recursing locks and prints out all relevant info* - detects multi-task circular deadlocks and prints out all affected* locks and tasks (and only those tasks)*/
struct mutex {atomic_long_t owner;raw_spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNERstruct optimistic_spin_queue osq; /* Spinner MCS lock */
#endifstruct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXESvoid *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
};
其結構中有一個鏈表類型字段:wait_list,當競爭者無法獲取資源時,就會加入到該鏈表中,競爭者從調度器的運行列表中刪除,放入處于睡眠狀態的等待鏈表(wait_list)中。然后內核調度并執行其他任務,當鎖被釋放時,等待隊列中的等待者被喚醒,從wait_list移除,然后重新被調度。
互斥鎖API
- 聲明
靜態聲明:
#define DEFINE_MUTEX(mutexname) \struct mutex mutexname = __MUTEX_INITIALIZER(mutexname)
動態聲明:
struct mutex my_mutex;
mutex_init(&my_mutex);
- 獲取互斥鎖
void mutex_lock(struct mutex *lock);
int mutex_lock_interruptible(struct mutex *lock);
int mutex_lock_killable(struct mutex *lock);
int mutex_trylock(struct mutex *lock);
mutex_lock在不能獲得互斥鎖時,會把任務加入到睡眠隊列中,必須要保證互斥鎖能夠釋放。mutex_lock_interruptible在不能獲得互斥鎖時,會把任務加入到睡眠隊列中,但是任務在睡眠隊列時有信號到達,mutex_lock_interruptible會返回 -EINTR,程序會自動往下運行。
mutex_lock_killable在不能獲得互斥鎖時,會把任務加入到睡眠隊列中,只有殺死任務的信號,才能中斷驅動程序,程序會繼續往下運行。
mutex_trylock如果不能獲得互斥鎖,不會把任務加入到睡眠列表中,直接返回。
3. 釋放互斥鎖
void mutex_unlock(struct mutex *lock);
有時需要檢查互斥鎖是否鎖定。為此使用mutex_is_locked函數:
/*** mutex_is_locked - is the mutex locked* @lock: the mutex to be queried** Returns true if the mutex is locked, false if unlocked.*/
extern bool mutex_is_locked(struct mutex *lock);
已經被其他任務獲取了,返回true,沒有被使用返回false
互斥鎖沒有輪詢機制,每次在互斥鎖上調用mutex_unlock時,內核都會檢查wait_list中的等待任務,如果有等待者,則其中的一個將被喚醒,它們喚醒的順序域它們入睡的順序相同。
9 禁止搶占
由于內核時搶占性的,內核中的進程在任何時候都可能停下來以便另一個更高優先級的進程運行。這意味著一個任務與被搶占的任務可能會在同一個臨界區內運行,為了避免這種情況,內核搶占代碼使用自旋鎖作為非搶占區域的標記。如果一個自旋鎖被持有,內核便不能進行搶占。因為內核搶占和SMP面對相同的并發問題,并且內核已經是SMP安全的,因此,這種簡單的變化使得內核也是搶占安全的。
實際中,某些情況下并不需要自旋鎖,但是仍然需要關閉內核搶占,出現最頻繁的情況就是每個處理器上的數據。如果數據對每個處理器是唯一的,那么這樣的數據可能就不需要使用鎖來保護,因為數據只能被一個處理器訪問,如果自旋鎖沒有被持有,內核又是搶占的,那么一個新調度的任務就可能訪問同一個變量,如下所示

這樣,即使這是一個單處理器,變量foo也會被多個進程以偽并發的方式訪問。通常,這個變量會請求得到一個自旋鎖(防止多處理器上的真并發)。但是如果這是每個處理器上獨立的變量,可能就不需要鎖。
為了解決這個問題,可以通過preempt_disable()禁止內核搶占。這是一個可以嵌套調用的函數,可以調用任意次。每次調用都必須有一個相應的preempt_enable()調用。當最后一次preempt_enable()被調用后,內核搶占才重新啟用。
搶占計數存放著持有鎖的數量和preempt_disable()的調用次數,如果計數是0,那么內核可以進行搶占,如果為1或更大的值,那么內核就不會進行搶占。函數preempt_count()返回這個值。

為了更簡潔的方法解決每個處理器上的數據訪問問題,可以通過get_cpu獲得處理器編號。這個函數在返回當前處理器號前會首先關閉內核搶占。put_cpu()會恢復內核搶占:

10 順序和屏障
屏障是告訴編譯器不要對給定點周圍的指令序列進行重新排序。
rmb()方法提供了一個讀內存屏障,它確保在rmb()之前的載入操作不會被重新排在該調用之后,在rmb()之后的載入操作不會被重新排在該調用之前。
wmb()提供了一個寫內存屏障,這個函數的功能和rmb()類似,區別僅僅是它是針對存儲而非載入。
mb()方法即提供了讀屏障也提供了寫屏障。
內核和編譯器屏障方法如下:

注意,對于不同體系結構,屏障的實際效果差別很大。例如,如果一個體系結構不執行打亂存儲(比如intel x86芯片),那么wmb()就什么也不做。

方法及示例)
)


方法與示例)
)


方法與示例)


方法與示例)


)


方法與示例)
和History.back()的區別)