進程間通信
- 1 管道
- 匿名管道
- 命名管道
- 2 消息隊列
- 3 信號量
- POSIX信號量
- 有名信號量
- 無名信號量
- 有名信號量和無名信號量的公共操作
- 4 共享內存
- 5 信號
- 相關函數
- 6 套接字
- 針對 TCP 協議通信的 socket 編程模型
- 針對 UDP 協議通信的 socket 編程模型
- 針對本地進程間通信的 socket 編程模型
- 總結
Linux下的進程通信機制叫做IPC(InterProcess Communication),在Linux下有6大通信的方法,分別是:Socket、管道、信號、信號量、消息隊列、共享內存。
每個進程的用戶地址空間都是獨立的,一般而言是不能互相訪問的,但內核空間是每個進程都共享的,所以進程之間要通信必須通過內核。
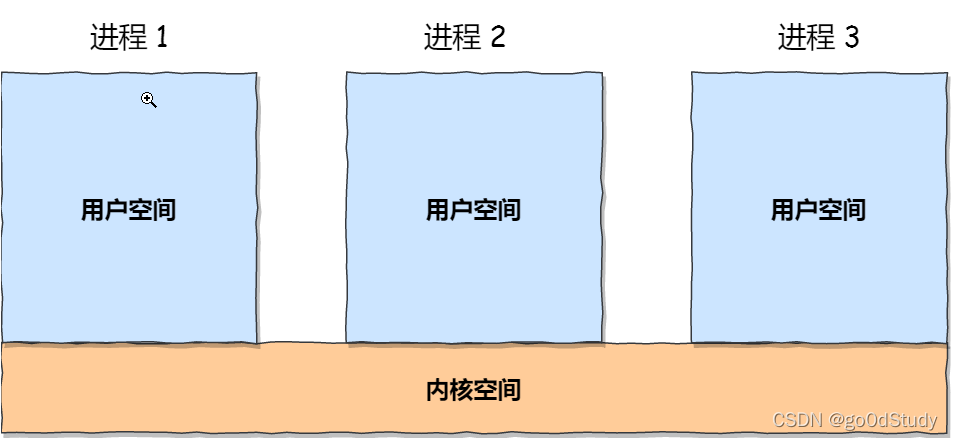
1 管道
參考文章:
- https://blog.csdn.net/modi000/article/details/122084165
- https://blog.csdn.net/wm12345645/article/details/82381407
匿名管道
匿名管道是在內核中申請一塊固定大小的緩沖區,程序擁有寫入和讀取的權利。匿名管道是半雙工的,數據傳輸只能在一個方向,并且只能在具有公共祖先的兩個進程之間使用。
管道是通過調用pipe函數創建的:
int pipe(int fd[2]);
fd[0]為讀端,fd[1]為寫端。
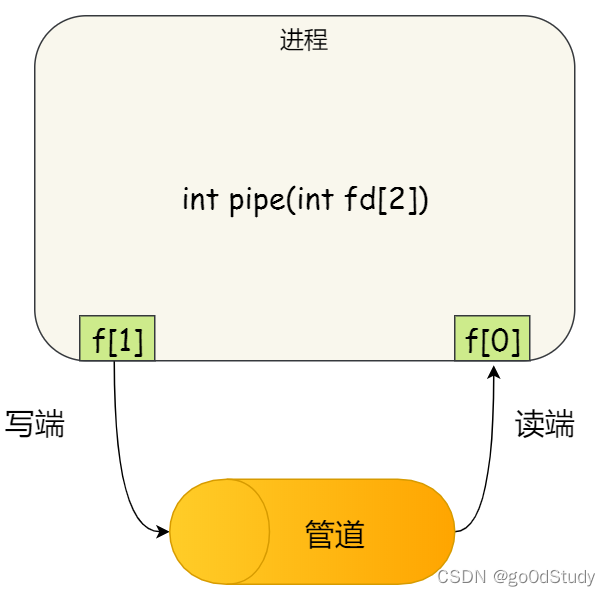
我們要注意,調用 pipe之后,管道是在內存中,fd[0]和fd[1]還在進程當中,現在只有調用pipe的進程才能對管道進行操作。那么怎么樣才能使得管道是跨過兩個進程使用呢?
我們可使用fork創建子進程,創建的子進程會繼承來自父進程的文件描述符,這樣我們就做到兩個進程各有1個fd[0]和fd[1],父子進程就可以往管道寫入或讀取數據實現通信了。
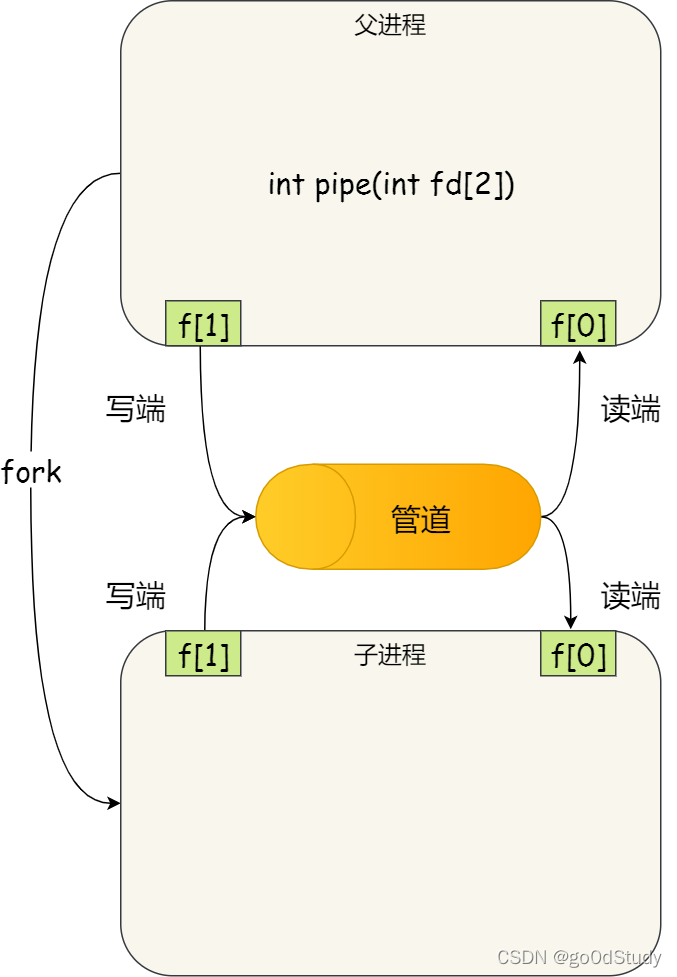
管道只能一端寫入,另一端讀出,所以上面這種模式容易造成混亂,因為父進程和子進程都可以同時寫入,也都可以讀出。那么,為了避免這種情況,通常的做法是:
- 父進程關閉讀取的 fd[0],只保留寫入的 fd[1];
- 子進程關閉寫入的 fd[1],只保留讀取的 fd[0];
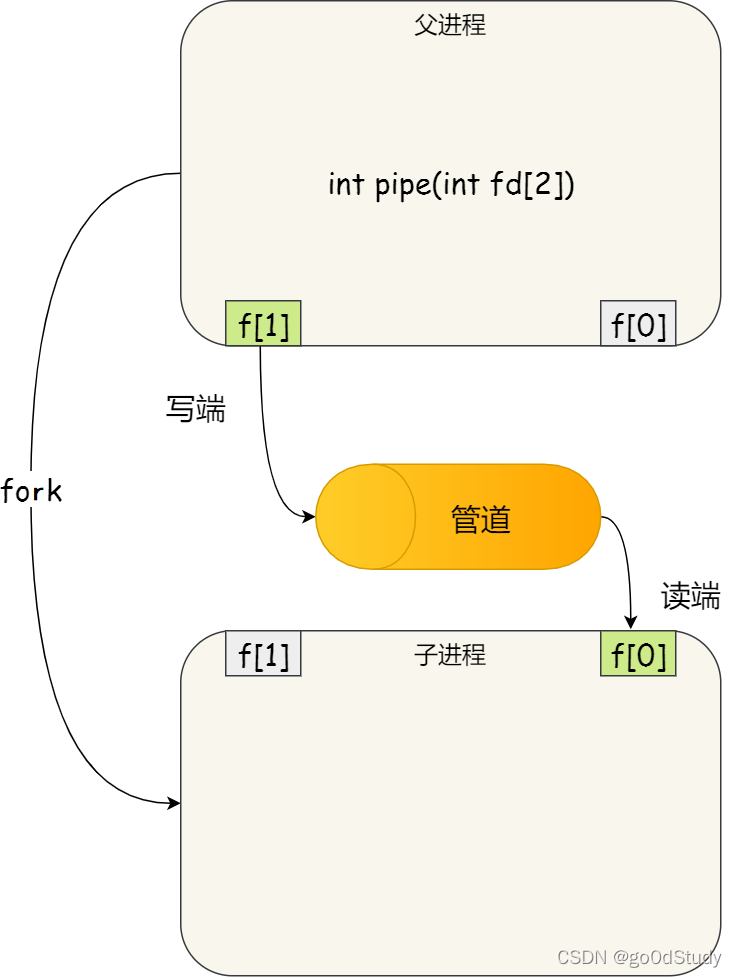
f[0]和f[1]都是文件描述符,我們可以調用close函數關閉。比如關閉f[0]
close(fd[0]);
命名管道
命名管道是在內核申請一塊固定大小的緩沖區,程序擁有寫入和讀取的權利,沒有血緣關系的進程也可進行通信。由mkfifo函數創建
int mkfifo(const char *pathname,mode_t mode);
創建一個名字由pathname指定的特殊文件,在進程里只要使用這個文件,就可以相互通信。
不管是匿名管道還是命名管道,進程寫入的數據都是緩存在內核中,另一個進程讀取數據時候自然也是從內核中獲取,同時通信數據都遵循先進先出原則,不支持 lseek 之類的文件定位操作。
我們以pipe為例:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/types.h>#define BUFF_SIZE 1024int main(void){int fd[2];pid_t pid;char *str = "hello world";char buff[BUFF_SIZE];if(pipe(fd)!=0){perror("pipe");exit(1);}pid = fork();if(pid<0){perror("fork()");}else if(pid==0){close(fd[0]);write(fd[1],str,sizeof(str));sleep(1);puts("write finished");}else{close(fd[1]);read(fd[0],buff,BUFF_SIZE);puts("read finished\n");printf("read source:%s\n",buff);}exit(0);}
運行結果:

2 消息隊列
參考文章:
- https://zhuanlan.zhihu.com/p/268389190
- https://blog.csdn.net/modi000/article/details/122084165
- https://blog.csdn.net/ljianhui/article/details/10287879
消息隊列是消息的鏈接表,存儲在內核中,由消息隊列標識符標識。
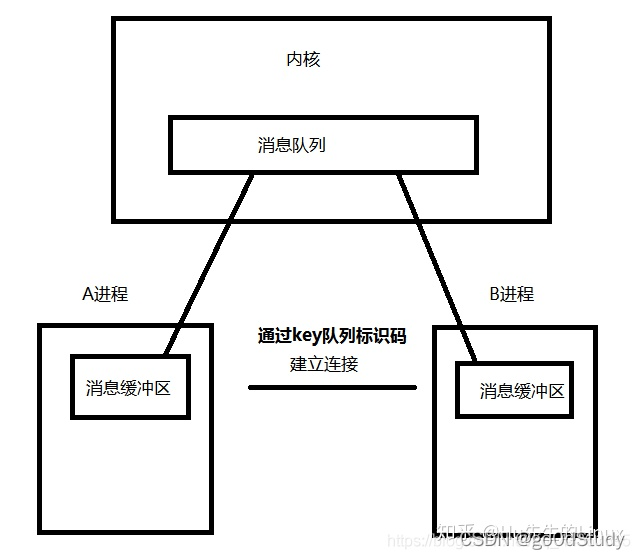
消息隊列是保存在內核中的消息鏈表,在發送數據時,會分成一個一個獨立的數據單元,也就是消息體(數據塊),消息體是用戶自定義的數據類型,消息的發送方和接收方要約定好消息體的數據類型,所以每個消息體都是固定大小的存儲塊,不像管道是無格式的字節流數據。如果進程從消息隊列中讀取了消息體,內核就會把這個消息體刪除。
- 創建一個消息隊列是msgget函數實現的:
int msgget(key_t key, int msgflg);
它返回一個以key命名的消息隊列標識符(非零整數),失敗時返回-1.
可以用ftok創建一個key_t的值
key_t ftok(const char *pathname, int proj_id);
功能:通過ftok返回的是根據文件(pathname)信息和計劃編號(proj_id)合成的IPC key鍵值。
返回值:成功:返回key_t值(即IPC鍵值);失敗:-1,錯誤原因在error中
- smgsnd函數添加消息到消息隊列
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
msgid是由msgget函數返回的消息隊列標識符;msgp 參數是指向調用者定義的結構的指針,其一般形式如下:
struct msgbuf {long mtype; /* message type, must be > 0 */char mtext[1]; /* message data */};mtext是要發送的數據,其類型是一個數組(也可以是其他數據結構),大小由msgsz指定,msgsz必須是一個非負整數,mtype 字段必須是正整數值,接收函數可以使用該值進行消息選擇;msgflg用于控制當前消息隊列滿或隊列消息到達系統范圍的限制時將要發生的事情
- msgrcv接受消息
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg);
msgtyp可以實現一種簡單的接收優先級。如果msgtype為0,就獲取隊列中的第一個消息。如果它的值大于零,將獲取具有相同消息類型(和msgsnd函數msgbuf結構體的mtype相等)的第一個信息。如果它小于零,就獲取類型等于或小于msgtype的絕對值的第一個消息。其他參數和msgsnd一樣。
- 消息隊列的控制函數msgctl
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
command是將要采取的動作,它可以取3個值

buf是指向msgid_ds結構的指針,它指向消息隊列模式和訪問權限的結構。
發送進程msgsend.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include "./msgbuf.h"int main(void)
{int running = 1;struct msgbuf data;long mtype=0;key_t key; int msgid;/* 創建消息隊列 */key = ftok("./",2);if(key==-1){printf("ftok error\n");exit(1);}/* 建立消息隊列 */msgid=msgget(key,IPC_CREAT|0666);if(msgid==-1){fprintf(stderr,"msgget error");exit(1);}/* 發送數據 */while(running){printf("enter some test:");fgets(data.mtext,BUFFSIZE ,stdin);data.mtype = 1;if(msgsnd(msgid,(void *)&data,BUFFSIZE,0)==-1){fprintf(stderr,"msgsnd error\n");exit(1);}if(strncmp(data.mtext,"end",3)==0){running = 0;}}exit(0);
}
接受進程代碼msgrec.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include "./msgbuf.h"int main(void)
{int msgid;key_t key;int running = 1;struct msgbuf data;memset(data.mtext,0,BUFFSIZE);long mtype=0;key = ftok("./",2);if(key==-1){printf("ftok error\n");exit(1);}/* 建立消息隊列 */msgid=msgget(key,IPC_CREAT|0666);if(msgid==-1){fprintf(stderr,"msgget error");exit(1);}/* 從隊列中獲取消息,直到遇到end消息為止 */while(running){if(msgrcv(msgid,(void *)&data,BUFFSIZE,mtype,0)==-1){fprintf(stderr,"msgrcv error with errno:%d\n",errno);exit(1);}printf("message:%s\n",data.mtext);/* 刪除消息隊列 */if(strncmp(data.mtext,"end",3)==0){if(msgctl(msgid,IPC_RMID,NULL)==0){printf("delete message queue success!\n");}running =0;}}exit(0);
}
msgbuf.h代碼:
#include <errno.h>#define BUFFSIZE 1024struct msgbuf{long mtype;char mtext[BUFFSIZE];
};運行結果:

3 信號量
參考文章:
- https://blog.csdn.net/modi000/article/details/122084165
- https://zhuanlan.zhihu.com/p/351692436
- https://zhuanlan.zhihu.com/p/22612079
信號量與管道、消息隊列不同,它是一個計數器,用于對多個進程提供對共享數據對象的訪問,也就是對臨界資源進行保護。
信號量表示資源的數量,為了獲得共享資源,進程需要執行下列操作:
- 測試控制該資源的信號量
- 若此信號量的值為正,則進程可以使用該資源,當使用該共享資源時,進程會將信號量值減1,表示它使用了一個資源單位。
- 否則,若此信號量的值為0,則進程進入休眠狀態,直到信號量值大于0.
根據初始值的不同,信號量可以細分為 2 類,分別為二進制信號量和計數信號量:
二進制信號量:指初始值為 1 的信號量,此類信號量只有 1 和 0 兩個值,通常用來替代互斥鎖實現進程同步;
計數信號量:指初始值大于 1 的信號量,當進程中存在多個進程,但某公共資源允許同時訪問的進程數量是有限的(出現了“狼多肉少”的情況),這時就可以用計數信號量來限制同時訪問資源的進程數量。
POSIX信號量
POSIX信號量是一個sem_t類型的變量,但POSIX有兩種信號量的實現機制:無名信號量和命名信號量。 無名信號量只可以在共享內存的情況下使用,比如實現進程中各個線程之間的互斥和同步,因此無名信號量也被稱作基于內存的信號量;命名信號量通常用于不共享內存的情況下,比如進程間通信。
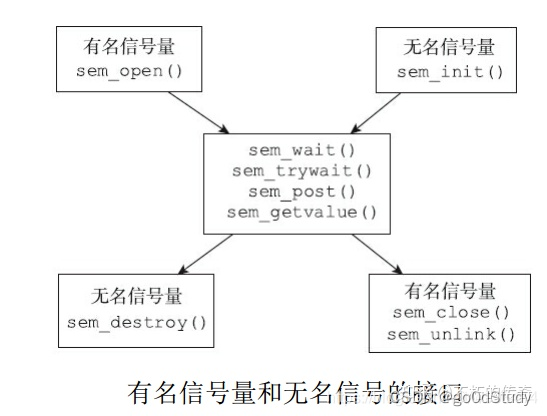
有名信號量
有名信號量由于其有名字, 多個獨立的進程可以通過名字來打開同一個信號量, 從而完成同步操作, 所以有名信號量的操作要方便一些, 適用范圍也比無名信號量更廣。
- 創建有名信號量
sem_t *sem_open(const char *name, int oflag);
sem_t *sem_open(const char *name, int oflag,mode_t mode, unsigned int value);

2. 有名信號量的關閉
int sem_close(sem_t *sem);
當一個進程打開有名信號量時, 系統會記錄進程與信號的關聯關系。 調用sem_close時, 會終止這種關聯關系, 同時信號量的進程數的引用計數減1。
- 有名信號量的刪除
int sem_unlink(const char *name);
函數會負責將該有名信號量刪除。 由于系統為信號量維護了引用計數, 所以只有當打開信號量的所有進程都關閉了之后, 才會真正地刪除。
無名信號量
無名信號量, 由于其沒有名字, 所以適用范圍要小于有名信號量。 只有將無名信號量放在多個進程或線程都共同可見的內存區域時才有意義, 否則協作的進程無法操作信號量, 達不到同步或互斥的目的。 所以一般而言, 無名信號量多用于線程之間。 因為線程會共享地址空間, 所以訪問共同的無名信號量是很容易辦到的事情。 或者將信號量創建在共享內存內, 多個進程通過操作共享內存的信號量達到同步或互斥的目的。
- 無名信號量的創建
int sem_init(sem_t *sem, int pshared, unsigned int value);

無名信號量的生命周期是有限的, 對于線程間共享的信號量, 線程組退出了,無名信號量也就不復存在了。 對于進程間共享的信號量, 信號量的持久性與所在的共享內存的持久性一樣。
無名信號量初始化以后, 就可以像操作有名信號量一樣操作無名信號量了。
- 無名信號量的銷毀
int sem_destroy(sem_t *sem);
sem_destroy用于銷毀sem_init函數初始化的無名信號量。 只有在所有進程都不會再等待一個信號量時, 它才能被安全銷毀。
有名信號量和無名信號量的公共操作
- 獲取信號量
#include <semaphore.h>int sem_wait(sem_t *sem);int sem_trywait(sem_t *sem);int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);Link with -pthread.- 歸還信號量2
int sem_post(sem_t *sem);
- 獲取當前信號量的值
int sem_getvalue(sem_t *restrict, int *restrict);
我們用信號量解決生產者拿消費者問題:
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <stdlib.h>#define N 10
#define true 1void show_buffer();
void *producer(void *id);
void *consumer(void *id);typedef int item;
//環形隊列
int in =0, out =0;
//緩沖區
item buffer[N];
//互斥、空緩沖區、滿緩沖區信號量
sem_t mutex,empty,full;/* 生產者 */
void *producer(void *id)
{while(true){item nextp = rand() % 10;sem_wait(&empty);sem_wait(&mutex);buffer[in]=nextp;in = (++in)%N;printf("======%s======\n",(char *)id);printf("生產了:%d\n",nextp);show_buffer();sem_post(&mutex);sem_post(&full);}
}/* 消費者 */
void *consumer(void *id)
{while(true){sem_wait(&full);sem_wait(&mutex);item nextc = buffer[out];out = (++out)%N;int emp,ful;sem_getvalue(&empty,&emp);sem_getvalue(&full,&ful);printf("======%s======\n""緩沖區大小:%d\n""消費的物品:%d\n""空緩沖區的數量:%d\n""滿緩沖區的數量:%d\n",(char*)id,N,nextc,emp,ful);show_buffer();sem_post(&mutex);sem_post(&empty);}
}/* 顯示緩沖區內容 */
void show_buffer()
{printf("[ ");if(in==out)//滿for(int i=0;i<N;i++)printf("%2d ",buffer[i]);else if(out<in)for(int i=out ;(i%N)<in;i++)printf("2%d ",buffer[i]);else{for(int i=out;i<N;i++)printf("%2d ",buffer[i]);for(int i=0;i<in;i++)printf("%2d ",buffer[i]);}printf("]\n");
}int main(void)
{/*初始化信號量*/if(sem_init(&mutex,0,1)==-1)perror("sem_init");if(sem_init(&empty,0,N)==-1)perror("sem_init");if(sem_init(&full,0,0)==-1)perror("sem_init");/* 兩個生產者、兩個消費者 */pthread_t p1,p2,c1,c2;int ret;if((ret=pthread_create(&p1,NULL,producer,(void *)"生產者1"))!=0){fprintf(stderr,"ptheard_create error,error number :%d\n",ret);exit(1);}if((ret=pthread_create(&p2,NULL,producer,(void *)"生產者2"))!=0){fprintf(stderr,"ptheard_create error,error number :%d\n",ret);exit(1);}if((ret=pthread_create(&c1,NULL,consumer,(void *)"消費者1"))!=0){fprintf(stderr,"ptheard_create error,error number :%d\n",ret);exit(1);}if((ret=pthread_create(&c2,NULL,consumer,(void *)"消費者2"))!=0){fprintf(stderr,"ptheard_create error,error number :%d\n",ret);exit(1);}if(ret=pthread_join(p1,NULL)){fprintf(stderr,"ptheard_join error,error number :%d\n",ret);exit(1);}if(ret=pthread_join(p2,NULL)){fprintf(stderr,"ptheard_join error,error number :%d\n",ret);exit(1);}if(ret=pthread_join(c1,NULL)){fprintf(stderr,"ptheard_join error,error number :%d\n",ret);exit(1);}if(ret=pthread_join(c2,NULL)){fprintf(stderr,"ptheard_join error,error number :%d\n",ret);exit(1);}return 0;}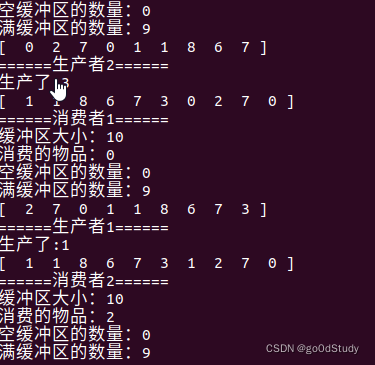
4 共享內存
參考文章:
- https://blog.csdn.net/modi000/article/details/122084165
- https://zhuanlan.zhihu.com/p/147826545
共享內存的機制,就是進程拿出一塊虛擬地址空間來,映射到相同的物理內存中。這樣這個進程寫入的東西,另外一個進程馬上就能看到了,都不需要拷貝來拷貝去,大大提高了進程間通信的速度。
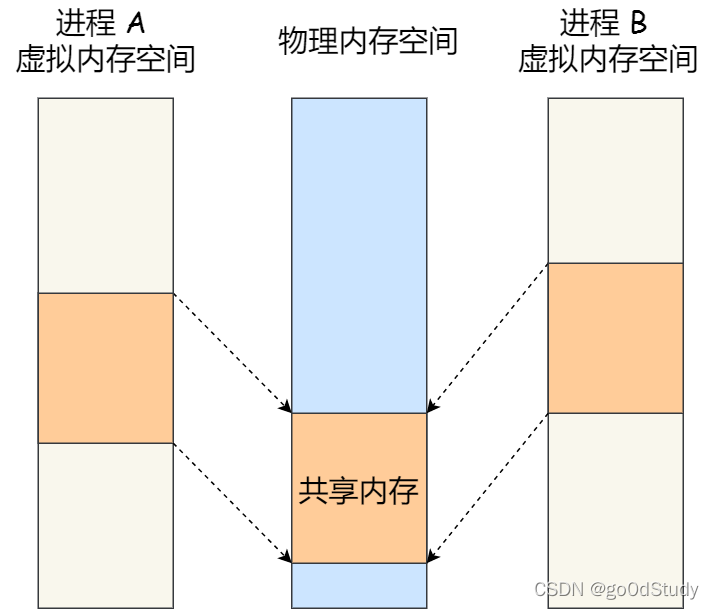
- 打開或創建共享內存
int shmget(key_t key, size_t size, int shmflg);
- 共享內存映射
void *shmat(int shmid, const void *shmaddr, int shmflg);
將一個共享內存段映射到調用進程的數據段中。簡單來理解,讓進程和共享內存建立一種聯系,讓進程某個指針指向此共享內存。
- 解除共享內存映射
int shmdt(const void *shmaddr);
將共享內存和當前進程分離( 僅僅是斷開聯系并不刪除共享內存,相當于讓之前的指向此共享內存的指針,不再指向)。
- 共享內存控制
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
接下來我們做這么一個例子:創建兩個進程,在 A 進程中創建一個共享內存,并向其寫入數據,通過 B 進程從共享內存中讀取數據。
寫端:
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <string.h>#define SIZE 1024void printf_error(void *s)
{fprintf(stderr,"%s\n",(char *)s);exit(1);
}int main(void)
{key_t key;int shmid;int ret;/*創建key值 */key = ftok("../",2021);if(key==-1){printf_error("ftok error");}/* 創建共享內存 */shmid = shmget(key,SIZE ,IPC_CREAT|0666);if(shmid==-1){printf_error("shmget error");}/* 映射 */char *shmad = shmat(shmid,NULL,0);if(shmad < 0){printf_error("shmat error");}/* 拷貝數據至共享內存區 */memset(shmad,0,SIZE);strcpy(shmad,"How are you,mike\n");return 0;
}讀端:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>#define SIZE 1024void printf_error(void *s)
{fprintf(stderr,"%s\n",(char *)s);exit(1);
}
int main(void)
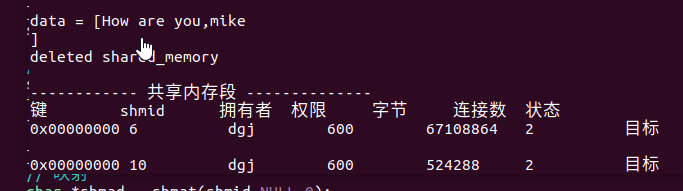
{int shmid;key_t key;int ret;/* 創建key值 */key = ftok("../",2021);if(key==-1){printf_error("ftok error");}system("ipcs -m"); //查看共享內存//打開共享內存shmid = shmget(key,SIZE,IPC_CREAT|0666);if(shmid<0){printf("shmget error");}// 映射char *shmad = shmat(shmid,NULL,0);if(shmad<0){printf_error("shmat error");}// 讀取共享內存區數據printf("data = [%s]\n",shmad);//分離共享內存和當前進程ret = shmdt(shmad);if(ret<0){printf_error("shmdt error");}printf("deleted shared_memory\n");//刪除共享內存shmctl(shmid,IPC_RMID,NULL);system("ipcs -m");return 0;
}
5 信號
參考文章:
- https://blog.csdn.net/modi000/article/details/122084165
- https://www.cnblogs.com/electronic/p/10939769.html
對于異常情況下的工作模式,就需要用「信號」的方式來通知進程。
信號是進程間通信機制中唯一的異步通信機制,因為可以在任何時候發送信號給某一進程,一旦有信號產生,我們就有下面這幾種,用戶進程對信號的處理方式。
-
執行默認操作。Linux 對每種信號都規定了默認操作,例如, SIGTERM 信號,就是終止進程的意思。Core 的意思是 Core Dump,也即終止進程后,通過 Core Dump 將當前進程的運行狀態保存在文件里面,方便程序員事后進行分析問題在哪里。
-
捕捉信號。我們可以為信號定義一個信號處理函數。當信號發生時,我們就執行相應的信號處理函數。
-
忽略信號。當我們不希望處理某些信號的時候,就可以忽略該信號,不做任何處理。有兩個信號是應用進程無法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它們用于在任何時候中斷或結束某一進程
相關函數
- int kill(pid_t pid, int sig);
功能:信號發送
參數:pid:指定進程
sig:要發送的信號
返回值:成功 0;失敗 -1 - int raise(int sig);
功能:進程向自己發送信號
參數:sig:信號
返回值:成功 0;失敗 -1 - unsigned int alarm(unsigned int seconds)
功能:在進程中設置一個定時器
參數:seconds:定時時間,單位為秒
返回值:如果調用此alarm()前,進程中已經設置了鬧鐘時間,則返回上一個鬧鐘時間的剩余時間,否則返回0。
注意:一個進程只能有一個鬧鐘時間。如果在調用alarm時已設置過鬧鐘時間,則之前的鬧鐘時間被新值所代替
-
int pause(void);
功能:用于將調用進程掛起直到收到信號為止。 -
信號處理函數
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
功能:信號處理函數
參數: signum:要處理的信號//不能是SIGKILL和SIGSTOP;
handler:
1. SIG_IGN:忽略該信號;
2. SIG_DFL:采用系統默認方式處理信號。
3. 自定義的信號處理函數指針
返回值:成功:設置之前的信號處理方式;失敗:SIG_ERR
- void abort(void);
給自己發送異常終止信號(SIGABRO),終止并產生core文件。
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <sys/types.h>
#include <unistd.h>void handler(int num)
{printf(" this signal no. is %d\n",num);kill(getpid(),SIGTERM);
}int main(void)
{signal(SIGINT,handler);while(1);return 0;
}

6 套接字
文章來源:
- https://blog.csdn.net/modi000/article/details/122084165
前面提到的管道、消息隊列、共享內存、信號量和信號都是在同一臺主機上進行進程間通信,那要想跨網絡與不同主機上的進程之間通信,就需要 Socket 通信了。
創建一個socket:
int socket(int domain, int type, int protocal)
三個參數分別代表:
- domain 參數用來指定協議族,比如 AF_INET 用于 IPV4、AF_INET6 用于 IPV6、AF_LOCAL/AF_UNIX 用于本機;
- type 參數用來指定通信特性,比如 SOCK_STREAM 表示的是字節流,對應 TCP、SOCK_DGRAM 表示的是數據報,對應 UDP、SOCK_RAW 表示的是原始套接字;
- protocal 參數原本是用來指定通信協議的,但現在基本廢棄。因為協議已經通過前面兩個參數指定完成,protocol 目前一般寫成 0 即可;
根據創建 socket 類型的不同,通信的方式也就不同:
- 實現 TCP 字節流通信: socket 類型是 AF_INET 和 SOCK_STREAM;
- 實現 UDP 數據報通信:socket 類型是 AF_INET 和 SOCK_DGRAM;
- 實現本地進程間通信: 「本地字節流 socket 」類型是 AF_LOCAL 和 SOCK_STREAM,「本地數據報 socket 」類型是 AF_LOCAL 和 SOCK_DGRAM。另外,AF_UNIX 和 AF_LOCAL 是等價的,所以 AF_UNIX 也屬于本地 socket;
針對 TCP 協議通信的 socket 編程模型
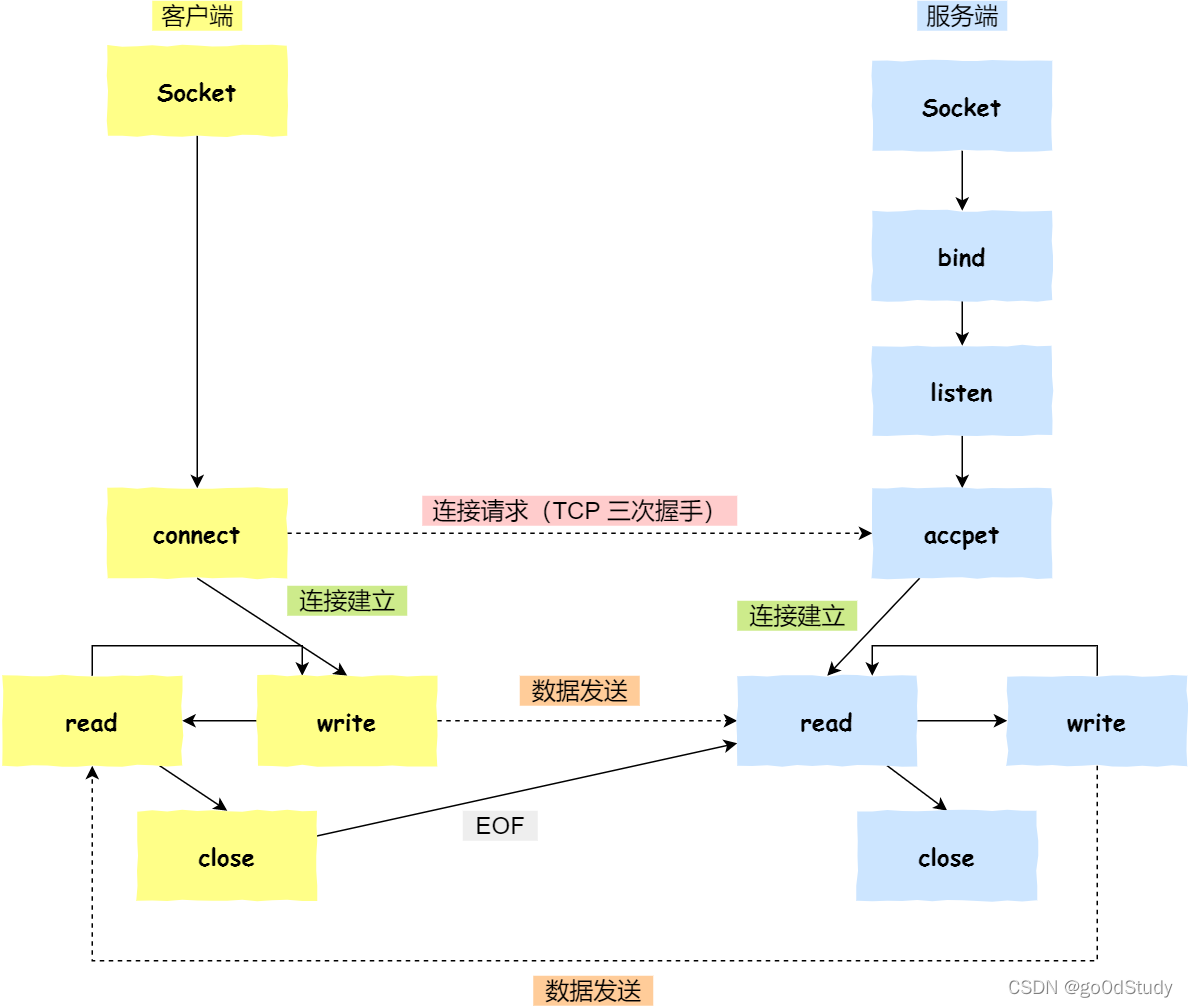
- 服務端和客戶端初始化 socket,得到文件描述符;
- 服務端調用 bind,將綁定在 IP 地址和端口;
- 服務端調用 listen,進行監聽;
- 服務端調用 accept,等待客戶端連接;
- 客戶端調用 connect,向服務器端的地址和端口發起連接請求;
- 服務端 accept 返回用于傳輸的 socket 的文件描述符;
- 客戶端調用 write 寫入數據;服務端調用 read 讀取數據;
- 客戶端斷開連接時,會調用 close,那么服務端 read 讀取數據的時候,就會讀取到了 EOF,待處理完數據后,服務端調用 close,表示連接關閉。
這里需要注意的是,服務端調用 accept 時,連接成功了會返回一個已完成連接的 socket,后續用來傳輸數據。
所以,監聽的 socket 和真正用來傳送數據的 socket,是「兩個」 socket,一個叫作監聽 socket,一個叫作已完成連接 socket。
成功連接建立之后,雙方開始通過 read 和 write 函數來讀寫數據,就像往一個文件流里面寫東西一樣。
針對 UDP 協議通信的 socket 編程模型
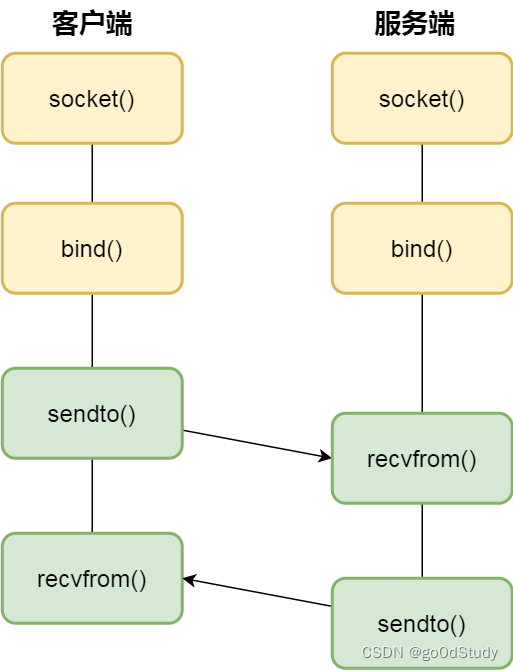
UDP 是沒有連接的,所以不需要三次握手,也就不需要像 TCP 調用 listen 和 connect,但是 UDP 的交互仍然需要 IP 地址和端口號,因此也需要 bind。
對于 UDP 來說,不需要要維護連接,那么也就沒有所謂的發送方和接收方,甚至都不存在客戶端和服務端的概念,只要有一個 socket 多臺機器就可以任意通信,因此每一個 UDP 的 socket 都需要 bind。
另外,每次通信時,調用 sendto 和 recvfrom,都要傳入目標主機的 IP 地址和端口。
針對本地進程間通信的 socket 編程模型
本地 socket 被用于在同一臺主機上進程間通信的場景:
- 本地 socket 的編程接口和 IPv4 、IPv6 套接字編程接口是一致的,可以支持「字節流」和「數據報」兩種協議;
- 本地 socket 的實現效率大大高于 IPv4 和 IPv6 的字節流、數據報 socket 實現;
對于本地字節流 socket,其 socket 類型是 AF_LOCAL 和 SOCK_STREAM。
對于本地數據報 socket,其 socket 類型是 AF_LOCAL 和 SOCK_DGRAM。
本地字節流 socket 和 本地數據報 socket 在 bind 的時候,不像 TCP 和 UDP 要綁定 IP 地址和端口,而是綁定一個本地文件,這也就是它們之間的最大區別。
總結
Linux 內核提供了不少進程間通信的方式,其中最簡單的方式就是管道,管道分為「匿名管道」和「命名管道」。
匿名管道顧名思義,它沒有名字標識,匿名管道是特殊文件只存在于內存,沒有存在于文件系統中,shell 命令中的「|」豎線就是匿名管道,通信的數據是無格式的流并且大小受限,通信的方式是單向的,數據只能在一個方向上流動,如果要雙向通信,需要創建兩個管道,再來匿名管道是只能用于存在父子關系的進程間通信,匿名管道的生命周期隨著進程創建而建立,隨著進程終止而消失。
命名管道突破了匿名管道只能在親緣關系進程間的通信限制,因為使用命名管道的前提,需要在文件系統創建一個類型為 p 的設備文件,那么毫無關系的進程就可以通過這個設備文件進行通信。另外,不管是匿名管道還是命名管道,進程寫入的數據都是緩存在內核中,另一個進程讀取數據時候自然也是從內核中獲取,同時通信數據都遵循先進先出原則,不支持 lseek 之類的文件定位操作。
消息隊列克服了管道通信的數據是無格式的字節流的問題,消息隊列實際上是保存在內核的「消息鏈表」,消息隊列的消息體是可以用戶自定義的數據類型,發送數據時,會被分成一個一個獨立的消息體,當然接收數據時,也要與發送方發送的消息體的數據類型保持一致,這樣才能保證讀取的數據是正確的。消息隊列通信的速度不是最及時的,畢竟每次數據的寫入和讀取都需要經過用戶態與內核態之間的拷貝過程。
共享內存可以解決消息隊列通信中用戶態與內核態之間數據拷貝過程帶來的開銷,它直接分配一個共享空間,每個進程都可以直接訪問,就像訪問進程自己的空間一樣快捷方便,不需要陷入內核態或者系統調用,大大提高了通信的速度,享有最快的進程間通信方式之名。但是便捷高效的共享內存通信,帶來新的問題,多進程競爭同個共享資源會造成數據的錯亂。
那么,就需要信號量來保護共享資源,以確保任何時刻只能有一個進程訪問共享資源,這種方式就是互斥訪問。信號量不僅可以實現訪問的互斥性,還可以實現進程間的同步,信號量其實是一個計數器,表示的是資源個數,其值可以通過兩個原子操作來控制,分別是 P 操作和 V 操作。
與信號量名字很相似的叫信號,它倆名字雖然相似,但功能一點兒都不一樣。信號是進程間通信機制中唯一的異步通信機制,信號可以在應用進程和內核之間直接交互,內核也可以利用信號來通知用戶空間的進程發生了哪些系統事件,信號事件的來源主要有硬件來源(如鍵盤 Cltr+C )和軟件來源(如 kill 命令),一旦有信號發生,進程有三種方式響應信號 1. 執行默認操作、2. 捕捉信號、3. 忽略信號。有兩個信號是應用進程無法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,這是為了方便我們能在任何時候結束或停止某個進程。
前面說到的通信機制,都是工作于同一臺主機,如果要與不同主機的進程間通信,那么就需要 Socket 通信了。Socket 實際上不僅用于不同的主機進程間通信,還可以用于本地主機進程間通信,可根據創建 Socket 的類型不同,分為三種常見的通信方式,一個是基于 TCP 協議的通信方式,一個是基于 UDP 協議的通信方式,一個是本地進程間通信方式。

方法與示例)
)


方法與示例)


方法與示例)


)


方法與示例)
和History.back()的區別)


方法及示例)
