霍夫曼編碼是一種不等長非前綴編碼方式,于1951年由MIT的霍夫曼提出。
用于對一串數字/符號編碼獲取最短的結果,獲取最大的壓縮效率。
特點:不等長、非前綴
等長式編碼
等長編碼,意思是對出現的元素采用相同位數的序號進行標定,如下列所示:(這里我們采用三位)

假設有這樣一串數據:

編碼后的數據量:12 x 3bit=36bit.
思考:對5個數編碼沒必要每個數是同樣的長度,只要五個字符對應的五個編碼各自具有可區分性就行了。
非等長編碼就是對不同的字符進行不同長度的編碼
非等長式編碼
如下列所示,我們采用非等長編碼:

拿剛才說的字符串舉例:

編碼后的數據量是:3x2+1x5+2x3+41+14=25bit.
數據量減少了。
思考:如何確定哪種字符使用比較長的編碼,哪種字符使用比較短的編碼?
出現次數越多的字符我們使用更加短的編碼,出現次數越少的字符我們使用更加長的編碼。
現在可能又有疑問:為何不能像這樣,B=0,A=1,類似這樣,我們可以獲取更加短的編碼。
這里就要說到霍夫曼編碼的另外一個特性:非前綴編碼。
非前綴編碼
以下圖為例:
任何一個數據的編碼都不與其他數據的編碼的前綴重復。
如果B的編碼為1,則和其他編碼的前綴重復。
又如,C為11的話就和A、D、E的前綴重復了。
非前綴編碼的優點:
在編碼的時候其實和前綴編碼一樣,并沒有什么簡化的步驟。
但是在解碼的時候將會有不同的效果:
假設,我們現在有一串數據:

解碼得:
1110 110 1111 0 10 0 110 10 0 0 0 10
D A E B C B A C B B B C
已知碼表,對編碼后的信息進行解碼,不需要知道斷位信息,即可解碼。也就是說我們不需要知道哪幾個字符屬于同一個就可以進行解碼.
前綴編碼
假設編碼方式為如下。

當獲取的數據串是:

在不知道斷位信息的前提下,我們是無法對這串數據進行編碼的。
霍夫曼編碼
霍夫曼編碼提供一種自動的方式獲取非前綴非等長的編碼,通過二叉樹進行編碼。
1)將信源符號的概率按減小的順序排隊。
2)把兩個最小的概率相加,并繼續這一步驟,始終將較高的概率分支放在右邊,直到最后變成概率1。
3)畫出由概率1處到每個信源符號的路徑,順序記下沿路徑的0和1,所得就是該符號的霍夫曼碼字。
4)將每對組合的左邊一個指定為0,右邊一個指定為1(或相反)。
例子講解:
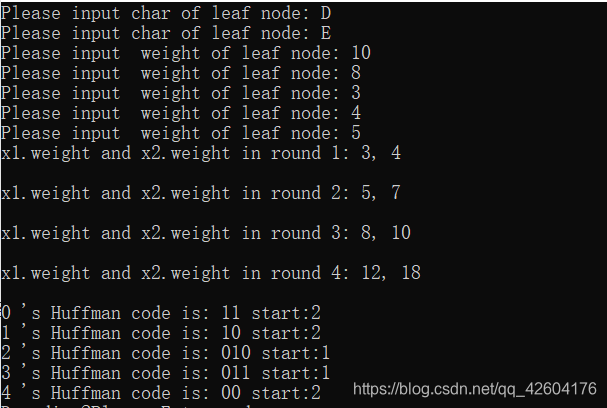
1、計算每個字符出現次數
| input | 出現次數 |
|---|---|
| B | 10 |
| A | 8 |
| C | 3 |
| D | 4 |
| E | 5 |
2、把出現次數(概率)最小的兩個相加,并作為左右子樹,重復此過程,直到概率值為1

第一次:將概率最低值3和4相加,組合成7:
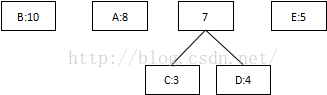
第二次:將最低值5和7相加,組合成12:

第三次:將8和10相加,組合成18:
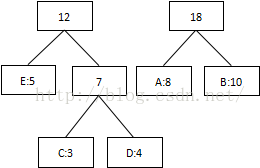
第四次:將最低值12和18相加,結束組合:
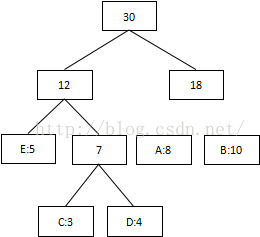
3 將每個二叉樹的左邊指定為0,右邊指定為1
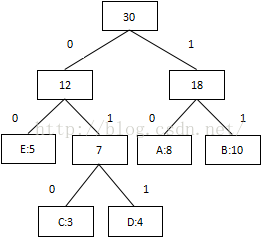
4 沿二叉樹頂部到每個字符路徑,獲得每個符號的編碼
| output | 編碼 |
|---|---|
| B | 11 |
| A | 10 |
| C | 010 |
| D | 011 |
| E | 00 |
霍夫曼編碼的缺陷:
(1)哈夫曼編碼所形成的碼字不是復唯一的,但編碼效率是唯一的在對最小的兩個概率符號賦值時,可以規定為大的為“1”、小的為“0”,反之也可以。如果兩個符號的出現概率相等時,排列時無論哪個在前都是可以的,所以哈夫曼所構造的碼字不是唯一的,對于制同一個信息源,無論上述的前后順序如何排列,它的平均碼長是不會改變的,所以編碼效率是唯一的。
(2)只有當信息源各符號出現的概率很不平百均的時候,哈夫曼編碼的效果才明顯。
(3)哈夫曼編碼必須精確地統度計出原始文件中每個符號的出現頻率,如果沒有這些精確的統計,將達不到預期的壓縮效果。霍夫曼編通常要經過兩遍操作,第一遍進行統計,第二遍產生編碼,所以編碼速度相對慢。另外實現的電路復雜,各問種長度的編碼的譯碼過程也是較復雜的,因此解壓縮的過程也比較慢。
(4)哈夫曼編碼只能用整數來表示單個符號而不能用小數,這很大程度上限制了壓縮效果。
(5)哈夫曼所有位都是合在一起的,如果改動其中一位就可以答使其數據變得面目全非
編程實現
代碼摘自博客:霍夫曼編碼(Huffman Coding)
#include <stdio.h>
#include<stdlib.h>
#include<string>
#include <iostream>#define MAXBIT 100
#define MAXVALUE 10000
#define MAXLEAF 30
#define MAXNODE MAXLEAF*2 -1typedef struct
{int bit[MAXBIT];int start;
} HCodeType; /* 編碼結構體 */
typedef struct
{int weight;int parent;int lchild;int rchild;char value;
} HNodeType; /* 結點結構體 *//* 構造一顆哈夫曼樹 */
void HuffmanTree (HNodeType HuffNode[MAXNODE], int n)
{ /* i、j: 循環變量,m1、m2:構造哈夫曼樹不同過程中兩個最小權值結點的權值,x1、x2:構造哈夫曼樹不同過程中兩個最小權值結點在數組中的序號。*/int i, j, m1, m2, x1, x2;/* 初始化存放哈夫曼樹數組 HuffNode[] 中的結點 */for (i=0; i<2*n-1; i++){HuffNode[i].weight = 0;//權值 HuffNode[i].parent =-1;HuffNode[i].lchild =-1;HuffNode[i].rchild =-1;HuffNode[i].value=' '; //實際值,可根據情況替換為字母 } /* end for *//* 輸入 n 個葉子結點的權值 */for (i=0; i<n; i++){printf ("Please input char of leaf node: ", i);scanf ("%c",&HuffNode[i].value);getchar();} /* end for */for (i=0; i<n; i++){printf ("Please input weight of leaf node: ", i);scanf ("%d",&HuffNode[i].weight);getchar();} /* end for *//* 循環構造 Huffman 樹 */for (i=0; i<n-1; i++){m1=m2=MAXVALUE; /* m1、m2中存放兩個無父結點且結點權值最小的兩個結點 */x1=x2=0;/* 找出所有結點中權值最小、無父結點的兩個結點,并合并之為一顆二叉樹 */for (j=0; j<n+i; j++){if (HuffNode[j].weight < m1 && HuffNode[j].parent==-1){m2=m1; x2=x1; m1=HuffNode[j].weight;x1=j;}else if (HuffNode[j].weight < m2 && HuffNode[j].parent==-1){m2=HuffNode[j].weight;x2=j;}} /* end for *//* 設置找到的兩個子結點 x1、x2 的父結點信息 */HuffNode[x1].parent = n+i;HuffNode[x2].parent = n+i;HuffNode[n+i].weight = HuffNode[x1].weight + HuffNode[x2].weight;HuffNode[n+i].lchild = x1;HuffNode[n+i].rchild = x2;printf ("x1.weight and x2.weight in round %d: %d, %d\n", i+1, HuffNode[x1].weight, HuffNode[x2].weight); /* 用于測試 */printf ("\n");} /* end for */} /* end HuffmanTree *///解碼
void decodeing(char string[],HNodeType Buf[],int Num)
{int i,tmp=0,code[1024];int m=2*Num-1;char *nump;char num[1024];for(i=0;i<strlen(string);i++){if(string[i]=='0')num[i]=0; elsenum[i]=1; } i=0;nump=&num[0];while(nump<(&num[strlen(string)])){tmp=m-1;while((Buf[tmp].lchild!=-1)&&(Buf[tmp].rchild!=-1)){if(*nump==0){tmp=Buf[tmp].lchild ; } else tmp=Buf[tmp].rchild;nump++;} printf("%c",Buf[tmp].value); }
}int main(void)
{HNodeType HuffNode[MAXNODE]; /* 定義一個結點結構體數組 */HCodeType HuffCode[MAXLEAF], cd; /* 定義一個編碼結構體數組, 同時定義一個臨時變量來存放求解編碼時的信息 */int i, j, c, p, n;char pp[100];printf ("Please input n:\n");scanf ("%d", &n);HuffmanTree (HuffNode, n);for (i=0; i < n; i++){cd.start = n-1;c = i;p = HuffNode[c].parent;while (p != -1) /* 父結點存在 */{if (HuffNode[p].lchild == c)cd.bit[cd.start] = 0;elsecd.bit[cd.start] = 1;cd.start--; /* 求編碼的低一位 */c=p; p=HuffNode[c].parent; /* 設置下一循環條件 */} /* end while *//* 保存求出的每個葉結點的哈夫曼編碼和編碼的起始位 */for (j=cd.start+1; j<n; j++){ HuffCode[i].bit[j] = cd.bit[j];}HuffCode[i].start = cd.start;} /* end for *//* 輸出已保存好的所有存在編碼的哈夫曼編碼 */for (i=0; i<n; i++){printf ("%d 's Huffman code is: ", i);for (j=HuffCode[i].start+1; j < n; j++){printf ("%d", HuffCode[i].bit[j]);}printf(" start:%d",HuffCode[i].start);printf ("\n");}printf("Decoding?Please Enter code:\n");scanf("%s",&pp);decodeing(pp,HuffNode,n);getchar();return 0;
}
Reference:
霍夫曼編碼(HuffmanCoding)
哈夫曼編碼和二進制編碼優缺點比較
《數字圖像處理PPT.李竹版》




)

)
方法與示例)
)



文件的輸出路徑?...)
方法及示例)
)
FAQ)
)

方法與示例)
