一、SVM支持向量機
什么是SVM支持向量機?
SVM支持向量機本質仍是一個分類器,其核心為尋求一個最優超平面最終實現分類,實現分類問題
在尋求超平面的時候有多種方式,可以使用若干條直線或曲線進行分類,這里使用的是直線,即SVM核為線性核
SVM支持許多核,這里使用的是線性核
數據準備,即準備訓練樣本,需要有正負樣本兩種情況,正樣本和負樣本的個數不一定相同;在準備樣本的時候一定要準備label標簽,這個label標簽唯一描述當前訓練的數據,正是因為有了label標簽才使得其是一個監督學習的過程;監督學習:在學習一個數據的時候進行監督其對與錯,即判斷其是0還是1
訓練:創建SVM并且設置其屬性
通過train方法完成訓練
訓練完成后調用predict方法進行預測
實現案例:通過兩組男生和女生的一些身高和體重的信息,進行訓練,最后對指定身高和體重的人進行判別其性別。男生為1,女生為0。
import cv2
import numpy as np
import matplotlib.pyplot as plt
#1 準備data 男生和女生的身高和體重
rand1 = np.array([[155,48],[159,50],[164,53],[168,56],[172,60]])#女生
rand2 = np.array([[152,53],[156,55],[160,56],[172,64],[176,65]])#男生# 2 label 表示當前數據的唯一屬性,例如這里的0表示女生,1表示為男生
label = np.array([[0],[0],[0],[0],[0],[1],[1],[1],[1],[1]])#這里將男女生給合并處理了,女生在前男生在后,所以這里的array為五個0和五個1# 3 data
data = np.vstack((rand1,rand2))#垂直合并
data = np.array(data,dtype='float32')# svm 所有的數據都要有label
# [155,48] -- 0 女生 [152,53] ---1 男生
# 監督學習 0 負樣本 1 正樣本# 4 訓練
svm = cv2.ml.SVM_create() # ml 機器學習模塊、SVM_create() 創建
# 屬性設置
svm.setType(cv2.ml.SVM_C_SVC) # svm type
svm.setKernel(cv2.ml.SVM_LINEAR) # line
svm.setC(0.01)
# 訓練
result = svm.train(data,cv2.ml.ROW_SAMPLE,label)
# 預測
pt_data = np.vstack([[167,55],[162,57]]) #0 女生 1男生
pt_data = np.array(pt_data,dtype='float32')
print(pt_data)
(par1,par2) = svm.predict(pt_data)
print(par1)
print(par2)
效果圖如下:
二、Hog特征
什么是Hog特征?
特征:某個特定區域的像素,進行某種四則運算之后得到的結果
Haar特征是直接經過模板計算的結果
而Hog特征則比較復雜些
Hog特征實現的步驟:
1、Hog特征的模塊化劃分
2、根據Hog特征模板計算梯度和方向,當然其也對應有相應的模板概念
3、根據梯度和方向進行bin投影
4、計算每個模塊的Hog特征
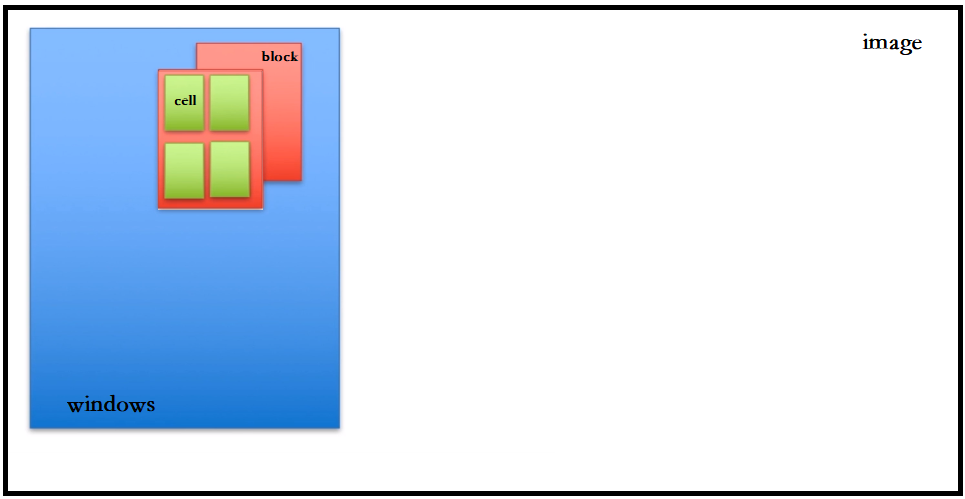
模塊劃分: 和Haar特征一樣,Hog特征也需要模塊劃分 image、windows、block、cell每個概念均有一個size()
image是整個圖片、windows窗體時藍色的長方形、block模塊時紅色的矩形、cell模塊時綠色的矩形
image>windows>block>cell成包含關系
block在滑動的時候有個step步長
Windows在滑動的時候也有個step步長
cell在滑動的時候會出現一個bin
windows是特征計算的最頂層單元,整個Hog特征計算最頂層也就計算到windows窗體這個地方;
一個窗口必須包含一個目標obj的所有的描述信息,只有把這些描述信息全部包含進去后,根據這些描述信息得到的這些窗體,根據窗體再計算出的特征才可以唯一描述當前這個目標objwindows的大小size,窗體的大小是任意的,官方推薦的使用在人臉識別的windows大小為64 * 128
block的大小,block是位于藍色windows窗體中,一般情況下windows的寬高必須是block的寬高的整數倍,一般block的大小為16 * 16
block的步長step,紅色的block會沿著藍色windows窗體從上到下,從左到右依次進行遍歷,正是因為遍歷的過程,所有才有了step這個概念
block每次向上向下或者向左向右滑動的長度即為step;
block的step描述的是block如何在windows下滑動;若block的大小為16 * 16,則一般情況下step的大小為8*8
在windows下block可以滑動多少次? {[(64-16)/8]+1} * {[(128-16)/8]+1} = 105次
若block的大小為1616,step為88;則一般情況下,cell大小推薦為88
一個cell大小為88,則一個block中包含4個cell,且cell是不可滑動的,是固定在block中;分別命名為:cell1、cell2、cell3、cell4bin、cell、梯度:簡而言之就是一個運算
在計算每一個像素的梯度的時候,即每個像素都有其對應的梯度;梯度具有兩個屬性:大小(或幅值)、方向(角度)
圓有360°,將360°按40°進行劃分,可以分為9塊,這9塊成為9個單元,每一個單元就成為一個bin,9塊就是9個bin
一個bin就是40°,剛好9個bin是360°
在cell中必須完整包含一個360°的完整信息,即只需要將這個cell完整包含這9個bin即可,即一個cell對應9個bin
Hog特征得到的是一個向量,因為是向量故存在維度的概念,可以完全描述目標obj對象的所有信息info,既然是所有信息,故應該為整個windows窗體中的信息,因為窗體windows是特征計算的最頂層單元,可以包含描述目標對象obj的所有信息
Hog特征的維度 = 所有windows窗體中block數(即105)* 每個block中cell的個數(一個block對應4個cell)* 每個cell對應的多少個bin(一個cell中包含9個bin)= 10549=3780,故Hog特征為3780維。
梯度如何計算方向和大小?
在進行梯度運算的時候需要以像素為單位,每個像素都有一個梯度,所有的像素共同都構建在一起形成了Hog特征,總共有windows窗體下所有的像素共同構成了Hog特征
特征模板包括水平和豎直方向上的模板 水平方向上的模板為 [1 0 -1] 對于水平方向上的模板實際上:左中右三個像素分別與模板進行相乘 a = p1 * 1 + p2 * 0 + p3 * -1 = 相鄰像素之差
豎直方向上的模板為 [[1],[0],[-1]] b = 上下像素之差
整個梯度幅值f = 根號下(a方 + b方) 當前的角度angle = arctan(a/b)bin的投影,其主要依賴于梯度 在bin中把0-360°劃分為9個bin,每個bin的范圍為0-40°
例如,bin1為0-20°,在這個0-20°這個范圍上的,就表示其在bin1上;bin1也可能在180-200°,即bin1總共為40°即可對于某個像素i和j來說,其梯度計算出來的幅值為f,角度a=10°,這個10°剛好位于0-20°之間,故其投影到bin1上
當然若a=190°,位于180-200°之間,其也投影在bin1上;此時投影的幅度即為f(前提是在正中間位置)。
若a=15°,不在正中間的位置,此時會進行分解,f為正中間時的幅度,夾角函數f(夾角)的范圍在0.0-1.0之間 f1 = f*(夾角函數)
f2 = f*(1-夾角函數)計算整體的Hog特征,以及cell的復用 整個Hog的維度為3780
3780來源于windows窗體,其中windows窗體中包含block、cell、bin,每一個維度就是其中的每一個bin
一個維度,即來源于一個windows下的一個block下的某一個cell下的每一個bin
把每一個block的第一個cell進行9等分,命名為cell0-cell3,同樣bin有9個,命名為bin0-bin8
對于第一個cell來說,cell0總共有9個bin,即bin0-bin8 cell1、cell2、cell3均有9個bin
假設(i,j)像素投影在cell0像素的bin0下
根據梯度可以計算出梯度的方向和梯度的幅值,幅值為f,方向為某一個角度不知道,這個角度就會投影到cell0上的bin0上,這時候bin0的內容就變成了f0,bin0中描述了當前像素的梯度,投影完之后,bin0的內容就等于f0
像素(i+1,j)行加,列不變,所有的這些像素都位于cell0上,(i+1,j)也有可能投影到cell0上,角度也會投影到bin0上,這時候的bin0就變成了f1;
同樣還會有(i+2,j),(i+3,j)等等等等
將所有的像素全部都遍歷完,再使用sum累加的方式,把所有的bin0累加到一起;sum(bin0(f0+f1+…)) = bin0,這個bin0就是在cell0下計算出來的所有的bin0的值權重累加
對于像素(i,j)來說,它不僅可以影響bin0,還可能會影響bin1,所以在計算sum(bin0)的時候除了f0+f1還需要當前像素在其他下的投影,比如(i,j)像素,有可能仍然投影在bin0上,因為bin0是兩部分,其中一個bin可能會與cell0上的bin相同
cell復用 在一個block中存在著4個cell,這4個cell正常情況下是并列排序的分別是cell0-cell3
對于cell0來說,它對應的是自己的bin0-bin9,其實在真正的計算中,會將block進行另外一個維度的劃分,在這個維度上,將cell劃分為cellx0、cellx2、cellx4 例如在cellx0上,所有元素(i,j),(i,j)計算出來的bin只對當前的cell起作用,雖然其會進行分解成當前的bin和相鄰的bin(例如為bin+1)
無論是當前的bin還是bin+1也好,只對cell0起作用
對于cellx2來說,其所有的元素(i,j)不光對當前的cell2起作用,還對當前的另外一個cell(例如cell3),它同時投影到兩個cell上,會進行分解為bin、bin+1,和cell3上分解的bin和bin+1
對于cellx4,它上面的所有的元素(i,j),會對4個cell起作用,則會分解成8個bin
再與4個cell進行合并,共同構成了9維,在于block中的4個cell組合到一起共同構成了36位,這36位和整個windows下的105個blokc組合在一起共同構成了3780維
3780維度的Hog特征如何進行判決,就需要SVM相關知識 以SVM線性分類器為例,這個線性分類器首先需要進行訓練,訓練完成之后同樣會得到一個3780維度的向量,用Hog特征(3780維度向量) * SVM的3780維度向量特征 = 具體的值,這個值就是最終的判決文獻,這個值與標準的判決文獻進行比較,如果大于判決文獻,則認為是目標;否則認為是非目標
三、具體實現
1,準備檢測需要的各種樣本;2,對這些樣本進行Hog+SVM訓練;3,訓練好后,實驗test圖片進行預測
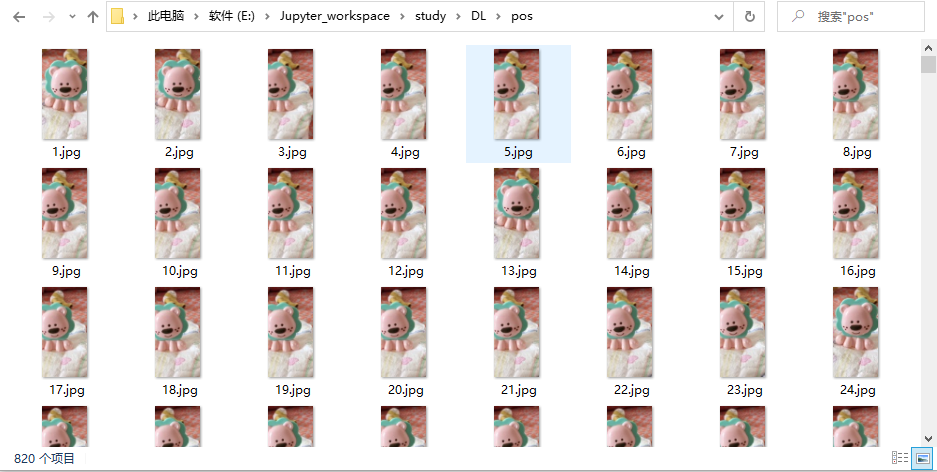
1、pos文件夾存放各種各樣的正樣本,正樣本也就是每個圖片樣本都包含這個小獅子;正樣本圖片的大小為64 * 128;正樣本盡可能多樣,即環境多樣、干擾多樣;正樣本個數為820
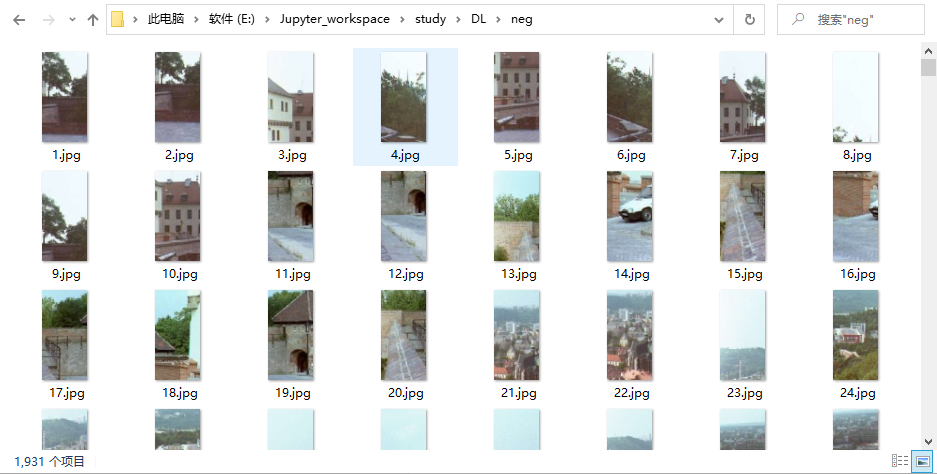
neg文件夾下為各種各樣的負樣本,負樣本也是各種各樣的圖片,這些負樣本中沒有包含正樣本小獅子圖樣,負樣本中一定不能出現正樣本的;負樣本圖片大小也為64*128;負樣本也要盡可能的環境、干擾條件多樣;負樣本個數1931
一般正負樣本比例在1:2 - 1:3之間;且名字的命名最好規范因為后續要進行遍歷樣本的獲取:1,來源于網絡;2、來源于公司內部;3、自己收集(寫個爬蟲自己爬或者錄視頻,100s的視頻,1s就有30幀的圖片,100s的視頻就是3000張樣本)
在深度學習中,一個好的樣本,遠勝過一個復雜的神經網絡 對于機器學習中,樣本需要幾千幾萬個;而在深度學習中,需要的樣本動則十幾萬,上百萬個
2,對樣本進行訓練
1、完成為參數的設置,其中參數包括了windows窗體的大小、block的大小、block的步長、cell的大小、bin的個數
2、創建一個Hog
3、獲取當前SVM的參數
4、計算Hog
5、準備label標簽
6、完成訓練
7、訓練完后,進行預測
8、通過使用繪圖操作,看下預測的完成效果
Hog的創建:
cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nBin)
參數一:當前windows窗口的大小
參數二:block的大小
參數三:block的步長
參數四:cell的大小
參數五:bin的個數
SVM的創建:
cv2.ml.SVM_create()
SVM的訓練:
svm.train(featureArray,cv2.ml.ROW_SAMPLE,labelArray)
參數一:特征數組
參數二:機器學習
參數三:標簽數組
detectMultiScale(imageSrc,0,(8,8),(32,32),1.05,2)
參數一:待檢測的原圖
參數二:windwos滑動步長
參數三:窗體大小
參數四:縮放
參數五:線條寬度
圖片的繪制:
cv2.rectangle(imageSrc,(x,y),(x+w,y+h),(255,0,0),2)
參數一:圖片
參數二:起始位置
參數三:終止位置
參數四:顏色
參數五:線條寬度
# 訓練
# 1 參數 2hog 3 svm 4 computer hog 5 label 6 train 7 pred 8 draw
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 參數的定義
PosNum = 820#正樣本個數
NegNum = 1931#負樣本個數,與實際的圖片個數得一致,不可隨便填寫
winSize = (64,128)#窗體大小
blockSize = (16,16)#每一個塊的大小定義為16*16;一個windows下有105個block
blockStride = (8,8)#block的步長設置為8*8的步長;4 cell
cellSize = (8,8)#cell的大小seize也設置為8*8
nBin = 9#bin的個數設置為9個;每個cell下有9個bin;Hog+SVM的特征維度為3780# 2 hog創建
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nBin)
# 3 svm分類器的創建
svm = cv2.ml.SVM_create()
# 4 計算hog
#定義當前Hog特征的維度
featureNum = int(((128-16)/8+1)*((64-16)/8+1)*4*9) #3780
featureArray = np.zeros(((PosNum+NegNum),featureNum),np.float32)#用于裝載當前的特征;
labelArray = np.zeros(((PosNum+NegNum),1),np.int32)#用于裝載當前的標簽
'''
為什么要創建featureArray和labelArray數組?
首先SVM是監督學習,監督學習就需要樣本和標簽
實際上SVM在學習的過程中學習的是Hog的特征,Hog特征才是SVM學習的真正的樣本
同樣label標簽是在SVM進行監督學習的過程中使用
'''# svm 監督學習 樣本 標簽 svm -》image hog
#處理正樣本
for i in range(0,PosNum):fileName = 'E:\\Jupyter_workspace\\study\\DL\\pos\\'+str(i+1)+'.jpg'#正樣本的路徑img = cv2.imread(fileName)#獲取當前的樣本hist = hog.compute(img,(8,8))#計算當前的Hpg特征 3780維度for j in range(0,featureNum):featureArray[i,j] = hist[j]#featureArray裝載的是Hog的特征;例如Hot1為[1,:]、Hot2為[2,:],# featureArray hog [1,:] hog1 [2,:]hog2 labelArray[i,0] = 1#正樣本的label全部標記為1#處理正樣本
for i in range(0,NegNum):fileName = 'E:\\Jupyter_workspace\\study\\DL\\neg\\'+str(i+1)+'.jpg'#負樣本的路徑img = cv2.imread(fileName)hist = hog.compute(img,(8,8))# 3780for j in range(0,featureNum):featureArray[i+PosNum,j] = hist[j]#正樣本已經全部放在featureArray中,要裝載負樣本的時候必須從i+PosNum行開始labelArray[i+PosNum,0] = -1#負樣本的label全部標記為-1#完成屬性設置,從而開始進行訓練
svm.setType(cv2.ml.SVM_C_SVC)#設置SVM的屬性
svm.setKernel(cv2.ml.SVM_LINEAR)#設置SVM的內核為線性內核
svm.setC(0.01)# 6 train
ret = svm.train(featureArray,cv2.ml.ROW_SAMPLE,labelArray)# 7 myHog的核心參數為:myDetect
# myDetect是一個數組,數組的數據來源于resultArray和rho
# myHog調用當前的detectMultiScale方法,完成整個目標的預測# 7 檢測 核心:create Hog -》 myDetect—》array-》
# resultArray來源于resultArray = -1*alphaArray*supportVArray
# rho來源于svm來源于svm.train
alpha = np.zeros((1),np.float32)
rho = svm.getDecisionFunction(0,alpha)
print(rho)
print(alpha)
alphaArray = np.zeros((1,1),np.float32)#定義alphaArray,為了與支持向量機數組進行相乘
supportVArray = np.zeros((1,featureNum),np.float32)#定義支持向量機數組supportVArray
resultArray = np.zeros((1,featureNum),np.float32)
alphaArray[0,0] = alpha
resultArray = -1*alphaArray*supportVArray
'''
supportVArray支持向量的個數
resultArray是3780維
rho一行一列的一維
myDetect這個數組是3781維
'''# detect MyHog的創建
myDetect = np.zeros((3781),np.float32)#myDetect其實就是一個array數組
for i in range(0,3780):myDetect[i] = resultArray[0,i]
myDetect[3780] = rho[0]
# rho svm (判決)
#構建Hog
myHog = cv2.HOGDescriptor()
myHog.setSVMDetector(myDetect)#設置Hog的屬性# load 讀取待檢測的圖片
imageSrc = cv2.imread('Test2.jpg',1)
# (8,8) win
objs = myHog.detectMultiScale(imageSrc,0,(8,8),(32,32),1.05,2)
# xy wh objs是個三維數組,而寬高信息放在最后一維
#獲取特征的寬高特征
x = int(objs[0][0][0])
y = int(objs[0][0][1])
w = int(objs[0][0][2])
h = int(objs[0][0][3])# 繪制展示
cv2.rectangle(imageSrc,(x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow('dst',imageSrc)
cv2.waitKey(0)
效果圖如下:
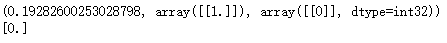

訓練正樣本:
訓練負樣本:
測試樣本:




文件的輸出路徑?...)
方法及示例)
)
FAQ)
)

方法與示例)




方法與示例)




