機器學習是什么?
機器學習=訓練樣本+特征+分類器,通過讓機器學習的方式,來達到某種功能的過程
深度學習是什么?
深度學習=海量的學習樣本+人工神經網絡
機器學習需要:樣本、特征、分類器、對訓練后的數據進行預測或檢驗
人臉樣本+haar特征+adaboost分類器===>就可以實現人臉識別
haar是由一系列模板組成
adaboost分類器是由三級極點組成,(強分類器、弱分類器、node結點)組成
hog特征+svm支持向量機===>實現小獅子的識別
一、視頻分解圖片
實現步驟:
1,將視頻加載進去load
2,讀取視頻的info信息
3,對視頻信息進行解碼parse,拿到單幀視頻
4,可以通過imshow進行展示,也可以通過imwrite進行保存
(flag,frame) = cap.read()
讀取每一幀,人眼可分辨每秒看到16幀
參數一:flag表示讀取是否成功
參數二:frame表示圖片的內容
將1.mp4視頻文件分解成圖片
import cv2
cap = cv2.VideoCapture("E:\Jupyter_workspace\study\DL\data/1.mp4")# 獲取一個視頻打開cap 1 file name
isOpened = cap.isOpened# 判斷是否打開‘
print(isOpened)
fps = cap.get(cv2.CAP_PROP_FPS)#幀率:視頻每秒可以展示的圖片
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))#視頻的寬度信息
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))#視頻的高度信息
print(fps,width,height)
i = 0
while(isOpened):if i == 10:breakelse:i = i+1(flag,frame) = cap.read()# 讀取每一張 flag frame fileName = 'E:\Jupyter_workspace\study\DL\data/image'+str(i)+'.jpg'print(fileName)if flag == True:cv2.imwrite(fileName,frame,[cv2.IMWRITE_JPEG_QUALITY,100])
print('end!')
二、圖片合成視頻
將視頻寫入進去,對寫入對象的創建
cv2.VideoWriter('2.mp4',-1,5,size)
參數一:圖片合成視頻
參數二:-1表示使用一個支持的解碼器
參數三:每秒處理的幀數,5幀
參數四:圖片視頻格式的大小
將一系列imagei(1<i<10)圖片合成2.mp4視頻
import cv2
img = cv2.imread('E:\Jupyter_workspace\study\DL\data/image1.jpg')
imgInfo = img.shape
size = (imgInfo[1],imgInfo[0])
print(size)
videoWrite = cv2.VideoWriter('2.mp4',-1,5,size)# 寫入對象 1 file name
# 2 編碼器 3 幀率 4 size
for i in range(1,11):fileName = 'E:\Jupyter_workspace\study\DL\data/image'+str(i)+'.jpg'img = cv2.imread(fileName)videoWrite.write(img)
print('end!')
三、Haar特征原理
什么是Haar特征?
特征:圖像某個區域的像素點,經過某種四則運算之后得到的結果,言而與之:像素進行運算所得到的結果;這個結果有可能是一個具體的值、向量、矩陣、多維
Haar是個具體的值,是經過白色方塊和黑色方塊之后相減得到的,故Haar特征得到的是一個值
如何利用特征區分目標?
通過閾值判決
如何得到判決?
通過機器學習得到判決文獻,讓機器知道什么是特征;通過機器學習獲取判決;利用計算的特征獲得閾值判決
計算公式:
特征=白色-黑色
特征=整個區域權重 + 黑色權重
特征=(p1-p2-p3+p4)*w
推導Haar特征公式:
黑色和白色的整體權重為-1;白色部分的權重值為1,黑色部分的權重值為-2
特征 = 整個區域 * 權重1 + 黑色 * 權重2 = (黑+白)* 1 + 黑 * (-2) = 黑+白 - 2 * 黑 = 白-黑
四、Haar特征遍歷原理
需要將haar模板從上到下,從左到右進行遍歷,也需要知道圖片的大小以及模板的大小,若原圖像大小為100100,harr模板大小為1010,則需要100次才可以將整個圖片遍歷完畢
原圖100100 模板1010 步長10 使用模板滑動
模板不僅可以進行滑動,還可以進行模板的縮放;例如原先的模板為1010,每次縮放10%,則下次的模板大小為1111,若為20級,則進行20次的縮放
舉例:原圖像為1080720大小,模板步長step為2,原始模板大小為1010
要想計算整個圖像上的haar特征當前的計算量為:14(14個模板) * 20(20級縮放,也就是20次縮放) * (1080/2 * 720/2)(需要這么多的模板) * (10 * 10這一百個點的加減運算) = 50-100億次的運算
若要求計算機處理每秒不得低于15幀,則 50-100億次 * 15 = 基本上為1000億次的運算量,故運算量太大,國外有個大神研究出了積分圖的概念,可以極大的減小運算量。
五、積分圖
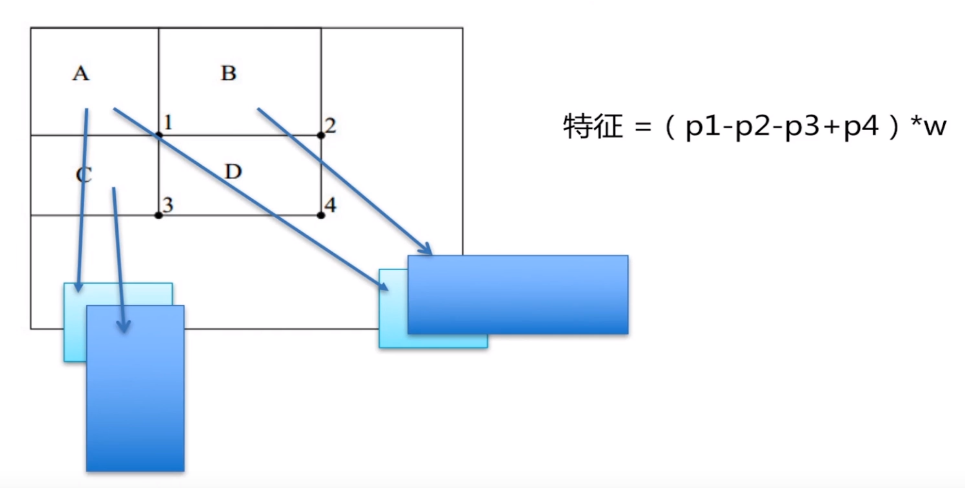
A為1,B為1 2,C為1 3,D為1 2 3 4
若求第4部分 = A-B-C+D = (1) - (1+2) - (1+3) + (1+2+3+4) = 4
六、Adaboost分類器
例如檢測:
蘋果、蘋果、蘋果、香蕉
0.1 — 0.1 — 0.1 — 0.5
則通過檢測的結果可以區分種類,此時需要一個終止條件
訓練終止條件:
1、迭代的最大次數
2、每次迭代完之后有個檢測概率p,即最小的誤差概率,例如三個蘋果,一個香蕉,此時的檢測概率為75%
分類器的結構、Adaboost分類器的計算過程、opencv自帶的人臉分類器的文檔xml結構
分類器的結構:設定一個閾值T,若haar特征>閾值T,則認為是蘋果,否則認為是香蕉,這是一級分類器,但效果不太好
haar>T1 and haar>T2,此時可以使用兩級分類器,兩個閾值。對于每一級的分類器規定為強分類器,則這是兩個強分類器組成;正常情況下Adaboost有15-20個強分類器所組成,若一個目標連續通過15-20這些閾值,則認為是準確目標。
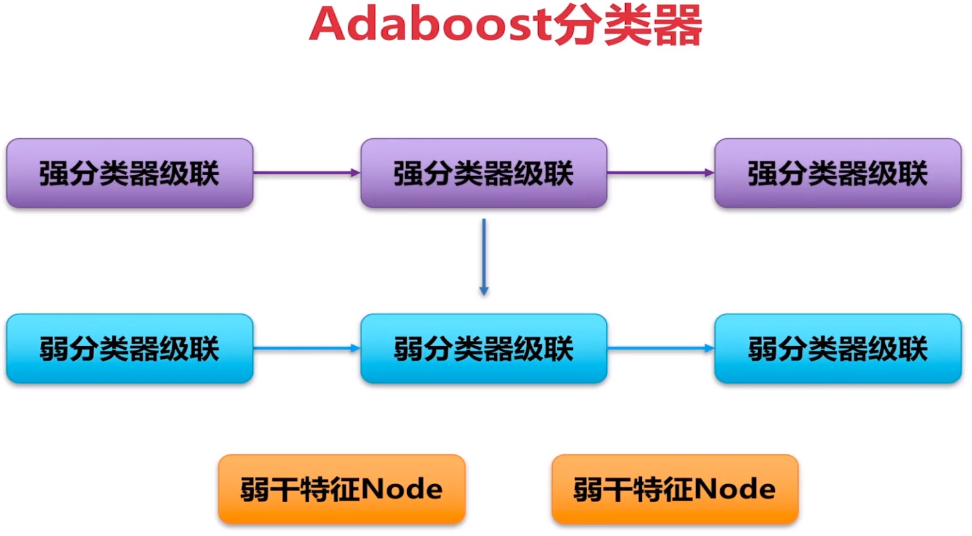
Adaboost分類器的計算過程
如上圖,三個強分類器組成:第一個強分類器特征為x1,閾值為t1、第二個強分類器特征為x2,閾值為t2、第三個強分類器特征為x3,閾值為t3
進行判決的時候x1>t1表明已經通過了第一個強分類器,同理,最后需要都通過這些強分類器,即:x1>t1 and x2>t2 and x3>t3 三個強分類器都通過時,則認為是目標
強分類器作用:判斷當前的閾值與當前的特征是否吻合,從而達到目標判決的效果
弱分類器作用:計算強分類器的特征,即計算當前的x1,x2,x3
例如:弱分類器計算的特征為y1,y2,y2;第二個強分類器的閾值x2 = sum(y1,y2,y3)由三個弱分類器計算的特征進行累加從而得到強分類器的特征x2
弱分類器特征y1,y2,y3的計算:每個弱分類器是由若干個Node結點組成,最后的弱分類器的特征的計算還得歸結于特征節點Node的計算
Node結點計算弱分類器特征:在opencv中一個弱分類器最多支持3個haar特征,每一個haar特征構成一個Node結點
例如Node1對應haar特征1,若haar特征1 > Node結點1的閾值判決(haar1 > Node1 T),則把當前的結點特征z1 = α1
若haar特征1 < Node結點1的閾值判決(haar1 < Node1 T),則把當前的結點特征z1 = α2
這是Node1,同理可計算出z2、z3
Z = sum(z1,z2,z3),若Z>判決文獻T,則弱分類器的計算特征y1=AA
Z = sum(z1,z2,z3),若Z<判決文獻T,則弱分類器的計算特征y1=BB
將所有弱分類器的計算特征求和,可得強分類器x,x=sum(y1,y2,y3)
強分類器在和強分類器的閾值文獻T進行比較,x >T1
若連續通過三個強分類器的閾值判決文獻,則認為是目標
Adaboost訓練步驟
1,完成初始化數據的權值分布
蘋果 蘋果 蘋果 香蕉
0.1—0.1—0.1—0.1
2、遍歷閾值,計算出一系列的誤差概率P,選取一個最小的誤差概率minP,其對應的權值為t
3、計算權重G1(x)
4、更新訓練數據的權重分布
蘋果 蘋果 蘋果 香蕉
0.2—0.2—0.2—0.8
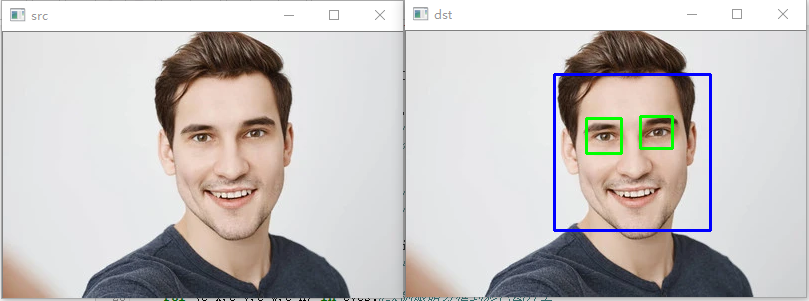
檢測人臉和人眼,并描繪出來
步驟:
1、加載xml文件
2、加載圖片
3、計算圖片的haar特征和對圖像進行灰度處理,haar特征的計算opencv已經封裝好了,調用即可;其中用戶自需要對圖像進行灰度處理即可,因為opencv中的所有haar特征都是基于灰度圖片來進行計算的
4、進行檢測,檢測出當前haar特征的人臉以及人臉上的特征,例如:人臉和眼睛
5、對檢測出來的結果進行遍歷,并繪制出檢測出來的方框
face_xml.detectMultiScale(gray,1.3,5)
參數一:需要進行人臉檢測的灰度圖
參數二:縮放系數,即比例縮放
參數三:人臉目標大小
import cv2
import numpy as np
# xml文件的引入
face_xml = cv2.CascadeClassifier('E:\Jupyter_workspace\study\DL\data/haarcascade_frontalface_default.xml')
eye_xml = cv2.CascadeClassifier('E:\Jupyter_workspace\study\DL\data/haarcascade_eye.xml')
# 加載含有人臉的圖片
img = cv2.imread('E:\Jupyter_workspace\study\DL\data/aa.jpg')
cv2.imshow('src',img)
# 計算haar特征和對圖像進行灰度轉化gray
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 人臉識別的檢測
faces = face_xml.detectMultiScale(gray,1.3,5)
print('face=',len(faces))#檢測當前的人臉個數
# 繪制人臉,為檢測到的每個人臉進行畫方框繪制
for (x,y,w,h) in faces:cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)#人臉識別roi_face = gray[y:y+h,x:x+w]#灰色人臉數據roi_color = img[y:y+h,x:x+w]#彩色人臉數據# 1 grayeyes = eye_xml.detectMultiScale(roi_face)#眼睛識別,圖片類型必須是灰度圖print('eye=',len(eyes))#打印檢測出眼睛的個數for (e_x,e_y,e_w,e_h) in eyes:#繪制眼睛方框到彩色圖片上cv2.rectangle(roi_color,(e_x,e_y),(e_x+e_w,e_y+e_h),(0,255,0),2)cv2.imshow('dst',img)
cv2.waitKey(0)
效果圖如下:
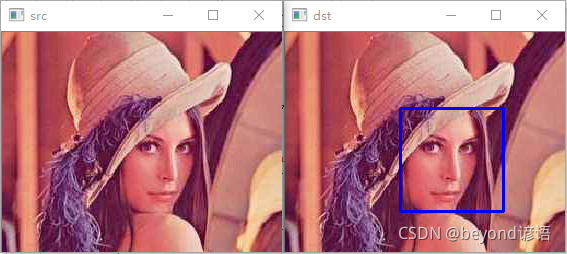
檢測人臉,將人臉進行ROI提取,并保存
# 1 load xml 2 load jpg 3 haar gray 4 detect 5 draw
import cv2
import numpy as np
# load xml 1 file name
face_xml = cv2.CascadeClassifier('E:\Jupyter_workspace\study\DL\data/haarcascade_frontalface_default.xml')
eye_xml = cv2.CascadeClassifier('E:\Jupyter_workspace\study\DL\data/haarcascade_eye.xml')
# load jpg
img = cv2.imread('E:\Jupyter_workspace\study\DL\data/face.jpg')
cv2.imshow('src',img)
# haar gray
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# detect faces 1 data 2 scale 3 5
faces = face_xml.detectMultiScale(gray,1.3,5)
print('face=',len(faces))
# draw
index = 0
for (x,y,w,h) in faces:cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)roi_face = gray[y:y+h,x:x+w]roi_color = img[y:y+h,x:x+w]fileName = "E:\Jupyter_workspace\study\DL\data/"+str(index)+'.jpg'cv2.imwrite(fileName,roi_color)index = index + 1# 1 grayeyes = eye_xml.detectMultiScale(roi_face)print('eye=',len(eyes))#for (e_x,e_y,e_w,e_h) in eyes:#cv2.rectangle(roi_color,(e_x,e_y),(e_x+e_w,e_y+e_h),(0,255,0),2)
cv2.imshow('dst',img)
cv2.waitKey(0)

)
方法與示例)
)



文件的輸出路徑?...)
方法及示例)
)
FAQ)
)

方法與示例)




方法與示例)
