標簽下載地址
| 文件 | 內容 | 備注 |
|---|---|---|
| train-images-idx3-ubyte.gz | 訓練集圖片:55000張訓練圖片,5000張驗證圖片 | |
| train-labels-idx1-ubyte.gz | 訓練集圖片對應的數字標簽 | |
| t10k-images-idx3-ubyte.gz | 測試集圖片:10000張圖片 | t表示test,測試圖片,10k表示10*1000一共一萬張圖片 |
| t10k-labels-idx1-ubyte.gz | 測試集圖片對應的數字標簽 |
對于每一個樣本都有一個對應的標簽進行唯一的標識,故為一個監督學習
操作的每個圖片必須是灰度圖(單通道0是白色,1是黑色)
對于標簽5401
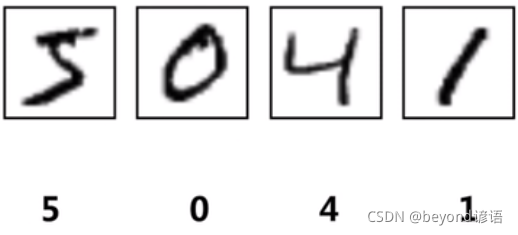
標簽中的4,并不是存儲4這個數字,而是存儲十位(0-9),第五行為黑色,則為1,即0000100000,因為1所處于第5個,即描述為:4
KNN最近鄰域法
KNN的根本原理:一張待檢測的圖片,與相應的樣本進行比較,如果在樣本圖片中存在K個與待檢測圖片相類似的圖片,那么就會把當前這K個圖片記錄下來。再在這K個圖片中找到相似性最大的(例如10個圖片中有8個描述的當前數字都是1,那么這個圖片檢測出來的就是1)
裝載圖片:
input_data.read_data_sets('MNIST_data',one_hot=True)
參數一:當前文件夾的名稱
參數二:one_hot是個布爾類型,one_hot中有一個為1,其余都為0
隨機獲取訓練數組的下標:
np.random.choice(trainNum,trainSize,replace=False)
參數一:隨機值的范圍
參數二:生成trainSize這么多個隨機數
參數三:是否可以重復
在0-trainNum之間隨機選取trainSize這么多個隨機數,且不可重復
import tensorflow as tf
import numpy as np
import random
from tensorflow.examples.tutorials.mnist import input_data
# load data 2 one_hot : 1 0000 1 fileName
mnist = input_data.read_data_sets('E:\\Jupyter_workspace\\study\\DL\\MNIST_data',one_hot=True)#完成數據的裝載,將裝載的圖片放入mnist中
# 屬性設置
trainNum = 55000#總共需要訓練多少張圖片
testNum = 10000#測試圖片
trainSize = 500#訓練是需要多少張圖片
testSize = 5#測試多少張圖片
k = 4#從訓練樣本中找到K個與測試圖片相近的圖片,并且統計這K個圖片中類別最多的幾,并且把這個數作為最終的結果
# data 分解 1 trainSize 2范圍0-trainNum 3 replace=False #數據的分解
#這里使用的是隨機獲取測試圖片和訓練圖片的下標,故每次運行的結果都會不一樣
trainIndex = np.random.choice(trainNum,trainSize,replace=False)#隨機獲取訓練數組的下標
testIndex = np.random.choice(testNum,testSize,replace=False)#隨機獲取測試圖片的標簽下標
trainData = mnist.train.images[trainIndex]# 獲取訓練圖片
trainLabel = mnist.train.labels[trainIndex]# 獲取訓練標簽
testData = mnist.test.images[testIndex]# 獲取測試的數據
testLabel = mnist.test.labels[testIndex]
print('trainData.shape=',trainData.shape)#訓練數據的維度 500*784 500表示圖片個數 圖片的寬高為28*28 = 784,即圖片上有784個像素點
print('trainLabel.shape=',trainLabel.shape)#訓練標簽的維度 500*10
print('testData.shape=',testData.shape)#測試數據的維度 5*784
print('testLabel.shape=',testLabel.shape)#測試標簽的維度 5*10
print('testLabel=',testLabel)
#testLabel是個五行十列的數據,在標簽中,所有的數據都放在數組中進行表示
'''
testLabel= [[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] 3--->testData [0][0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] 1--->testData [1][0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] 9--->testData [2][0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] 6--->testData [3][0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]] 4--->testData [4]
'''# tf input 784->image
trainDataInput = tf.placeholder(shape=[None,784],dtype=tf.float32)#定義訓練的數組,784列的數據表示一張完整的圖片,前面的行表示圖片的個數這里用None表示
trainLabelInput = tf.placeholder(shape=[None,10],dtype=tf.float32)#列為10,因為每個數字都是10維的
testDataInput = tf.placeholder(shape=[None,784],dtype=tf.float32)#定義測試數據
testLabelInput = tf.placeholder(shape=[None,10],dtype=tf.float32)#定義測試標簽#KNN的距離公式:
#knn distance 5*785. 5*1*784
# 5 500 784 (3D) 2500*784#計算trainData測試圖片和trainData訓練圖片的距離之差,測試圖片有5張,訓練圖片有500張,每個維度都是784維,故最后計算的結果為一個三維數據,(測試數據,訓練數據,二者之差),會產生5*500*784個數據,故需要擴展testDataInput的維度f1 = tf.expand_dims(testDataInput,1) # 完成當前的維度轉換,原本的testDataInput是一個5*785,經過維度轉換則成為5*1*784 維度擴展
f2 = tf.subtract(trainDataInput,f1)# 完成測試圖片與訓練圖片二者之差,得到的結果放入784維中,可以通過sum將這784維的差異累加到一塊,即sum(784)
f3 = tf.reduce_sum(tf.abs(f2),reduction_indices=2)# 所有的數據都裝載到f2中,因為有的距離是負數,需要取絕對值;設置在第二個維度上進行累加 即:完成數據累加取絕對值之后的784個像素點之間的差異
#所有的差異距離都放入在放f3中,是個5*500數組f4 = tf.negative(f3)# 取反
f5,f6 = tf.nn.top_k(f4,k=4) # 選取f4中所有元素最大的四個值,因為f4是f3的取反,故選取f3中最小的四個數值
#f5為f3中最小的數,f6為這個最下的數所對應的下標# f6 index->trainLabelInput
#f6存儲的是最近的圖片的下標,通過這些下標作為索引去獲取圖片的標簽
f7 = tf.gather(trainLabelInput,f6)#根據f6的下標來# f8 f9都是表示數字的獲取# f8 num reduce_sum reduction_indices=1 '豎直'
f8 = tf.reduce_sum(f7,reduction_indices=1)#完成數字的累加,將f7這個三維通過豎直的方向進行累加# tf.argmax 選取f8中,某一個最大的值,并記錄其所處的下標index
f9 = tf.argmax(f8,dimension=1)#
# f9為5張測試圖片中最大的下標 test5 image -> 5 num
with tf.Session() as sess:# f1 <- testData 5張圖片p1 = sess.run(f1,feed_dict={testDataInput:testData[0:testSize]})#運行f1并給其一個參數,這個參數是testData測試圖片,testData中總共有5張圖片,這5張圖片維待檢測的手寫數字print('p1=',p1.shape)# p1= (5, 1, 784) 每個圖片必須用784維來表示p2 = sess.run(f2,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize]})#運行f2 表示訓練數據和測試二者對應數據做差print('p2=',p2.shape)#p2= (5, 500, 784) 例如:(1,100)表示第2張測試圖片和第101張訓練圖片所有的像素對應做差都放入784中,784都為具體的值,故需要對784進行累加 p3 = sess.run(f3,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize]})#print('p3=',p3.shape)#p3= (5, 500)表示(測試圖片是哪一張,訓練圖片是哪一張)print('p3[0,0]=',p3[0,0]) #130.451表示第1張測試圖片和第1張訓練圖片的距離差 knn distance p3[0,0]= 155.812p4 = sess.run(f4,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize]})print('p4=',p4.shape)print('p4[0,0]',p4[0,0])p5,p6 = sess.run((f5,f6),feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize]})#p5= (5, 4) 每一張測試圖片(5張)分別對應4張最近訓練圖片#p6= (5, 4)print('p5=',p5.shape)print('p6=',p6.shape)print('p5[0,0]',p5[0])# 第1張測試圖片分別對應4張最近訓練圖片的值print('p6[0,0]',p6[0])# 第1張測試圖片分別對應4張最近訓練圖片的下標p7 = sess.run(f7,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize],trainLabelInput:trainLabel})print('p7=',p7.shape)#p7= (5, 4, 10)表示5組4行10列print('p7[]',p7)#5組表示5個測試圖片,4行每行表示一個最近的測試圖片,每一行中又有10個元素,這10個元素分別對應10個lable標簽p8 = sess.run(f8,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize],trainLabelInput:trainLabel})print('p8=',p8.shape)#p8=(5,10)print('p8[]=',p8)#5行10列,每一行為f7每一組所對應的豎直方向上的累加p9 = sess.run(f9,feed_dict={trainDataInput:trainData,testDataInput:testData[0:testSize],trainLabelInput:trainLabel})print('p9=',p9.shape)#p9=(5,)是一個一維數組,5列print('p9[]=',p9)#每一個元素表示p8中最大值所對應的下標p10 = np.argmax(testLabel[0:testSize],axis=1)#最終標簽中的內容,統計一下第2個維度上的標簽print('p10[]=',p10)#若p9和p10的內容相同,則檢測概率為100%j = 0
for i in range(0,5):if p10[i] == p9[i]:j = j+1
print('ac=',j*100/testSize)


方法與示例)





方法與示例)




)
方法與示例)




