SQL SERVER的鎖機制(一)——概述(鎖的種類與范圍)
SQL SERVER的鎖機制(二)——概述(鎖的兼容性與可以鎖定的資源)
?
本文上接SQL SERVER的鎖機制(三)——概述(鎖與事務隔離級別)
?
?
六、各種事務隔離級別發生的影響
修改數據的用戶會影響同時讀取或修改相同數據的其他用戶。即這些用戶可以并發訪問數據。如果數據存儲系統沒有并發控制,則用戶可能會看到以下負面影響:
·?未提交的依賴關系(臟讀)
·?不一致的分析(不可重復讀)
·?幻讀
(一)臟讀:
例:張某正在執行某項業務,如下:
begin traninsert tbUnRead select 3,'張三'unionselect 4,'李四'---延遲秒,模擬真實交易情形,用于處理業務邏輯waitfor delay '00:00:05'rollback tran---此時李某對表中數據進行查詢,執行了以下語句:set Transaction isolation level read uncommitted--查詢數據select * from tbUnRead where name like '張%'
?
?
則李某可以看到張某所執行的插入語句,把數據添加到了數據庫,如下圖。
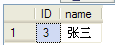
但是張某最終是沒有提交事務,而是回滾了事務,所以這條記錄并沒有真正插入到數據庫中。從而發生李某將臟讀的數據當成真實的查詢結果。
???要解決此問題,就是要把數據庫的事務隔離級別由未提交讀修改成已提交讀。只有當查詢結果的正確性不是非常重要,或者是隔一段時間查詢一次情況下,即使這一次查詢結果是錯,而下次查詢結果是對的,并不會有太大影響,這才適合使用未提交讀。
?
(二)不可重復讀
例:張某正在查詢數據,如下
set Transaction isolation level read committedbegin transelect * from tbUnRead where ID=2---延遲秒,模擬真實交易情形,用于處理業務邏輯waitfor delay '00:00:05'select * from tbUnRead where ID=2commit tran---此時李對表中數據進行了更新,如下語句:update tbUnReadset name='Jack_upd'where ID=2
?
?上面的執行語句造成張某在同一個事務內,兩次相同的查詢條件,查詢到不相同的結果(如下圖)。
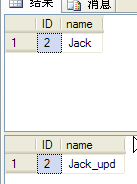
這是由于“已提交讀”隔離級別對共享鎖保留的時間是:一旦查詢完畢就立即釋放,而非事務完成才釋放。所在張某雖然還在使用事務,事務過程中的所有獨占鎖都會一直保留,讓事務中所更改的數據別人不可進行查詢與更改,直到事務完成。但是,被查詢的數據在事務過程中是查詢完畢就立即釋放共享鎖,所以別人仍然可以進行修改,造成一筆事務中,兩次相同的查詢條件,可以得到不相同的結果。最佳的解決方案是將隔離級別設置為“可重復讀”。
“可重復讀”事務隔離級別,讓事務過程中所曾經建立的共享鎖都一直保留到事務完成,雖然可以避免“不可重復讀”的問題,但是也會導致數據鎖定太久,而別人無法讀取數據,影響并發率,甚至提高了“死鎖”的發生率。
?
(三)幻讀
例:張某正在查詢數據,如下
set Transaction isolation level REPEATABLE READbegin transelect * from tbUnRead where ID=3---延遲秒,模擬真實交易情形,用于處理業務邏輯waitfor delay '00:00:05'select * from tbUnRead where ID=3commit tran--此時李某新增了一條記錄,如下語句:INSERT TBUNreadselect 3,'幻讀'
?
?
?
張某已經把隔離級別設置為“可重復讀”,雖然是曾經讀取的數據,不管是共享鎖還是互斥鎖都?保留到了事務結束,但是無法阻止其他人運行新增操作,導致第一次查詢時沒有數據,第二次查詢時卻有了數據。被稱為“幻讀”。如下圖。
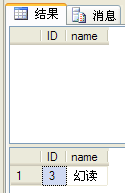
為了避免此類問題,可以將隔離級別設置為“可序列化”,設置之后,則其他人則無法新增數據。
?
?
七、各隔離級別所能防止的訪問錯誤
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
| 未提交讀 | 是 | 是 | 是 |
| 已提交讀 | 否 | 是 | 是 |
| 可重復讀 | 否 | 否 | 是 |
| 快照 | 否 | 否 | 否 |
| 可序列化 | 否 | 否 | 否 |
?
?
八、常用鎖與事務隔離級別間的交互影響
| ? | 已提交讀 | 可重復讀 | 快照 | 可序列化 |
| 共享 | 讀完數據后就釋放 | 事務結束才釋放 | 不加鎖,以版本來控制 | 事務結束才釋放 |
| 更新 | 讀完數據后就釋放或是升級成獨占鎖 | 讀完數據后就釋放或是升級成獨占鎖 | 不加鎖,以版本來控制 | 讀完數據后就釋放或升級成獨占鎖 |
| 獨占 | 事務結束才釋放 | 事務結束才釋放 | 不加鎖,以版本來控制 | 事務結束才釋放 |
?
九、動態鎖定管理
數據庫引擎使用動態鎖定管理策略來控制鎖定和系統的最佳成本效益。數據庫引擎可以動態調整數據粒度與鎖定類型,當使用最低一級的行鎖而非更大范圍的頁鎖時,可以降低兩個事務要求相同范圍的數據鎖定的可能性,增強并行訪問的能力,可同時服務更多的用戶,減小死鎖的機率。相反低級鎖轉為高級鎖可以減小系統的資源負擔,但會增加并行爭用的可能性。
此機制由鎖管理器進行管理,每一個鎖都需要內存去記錄,并且要與鎖管理器進行合作,才能完成數據訪問操作,你可以想像當表中有100萬條記錄時,你執行一條沒有where語句的update指令時,在默認情況下數據庫引擎會采用行鎖,但這要記錄100萬條行鎖記錄,以及相關的意向共享鎖,必定會消耗掉大量的系統資源,當系統資源不足時,數據庫引擎會自動提升鎖的級別,也就是由行鎖提升為頁鎖,如果資源還是不足,則會再次提升,提升為表鎖。
就以上例子來說,如果每個頁可以放200條記錄,則100萬表記錄的行鎖轉為5000個頁鎖,還省掉了大量的意向共享鎖。如果資源還是一足,則可以再次提升鎖級別,提升到表鎖,這樣就只需要一個鎖就可以了。
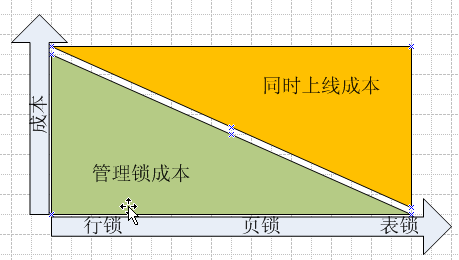
愈大范圍的鎖花費在管理鎖之上的資源就愈少。但相對來說,同時上線并發訪問該資源的人數就越少。例如:或采用行鎖,則你訪問你的記錄,我訪問我的記錄,互相不影響,但如果升級到頁鎖,則如果你先搶到該分頁,而我要訪問的記錄又恰恰在這一分頁上,則我必須要等你釋放該分頁之后才能訪問。如果升級到表鎖,則同一時間,該表中的記錄只能一個人才能訪問,其他人不能訪問。如下圖。
?
?
?
一般情況下,是不需要手工去設置鎖定范圍的,可以由Microsoft?SQL?Server?數據庫引擎視情況而定,使用動態鎖定策略確定最經濟的鎖。?執行查詢時,數據庫引擎會根據架構和查詢的特點自動決定最合適的鎖。?例如,為了縮減鎖定的開銷,優化器可能在執行索引掃描時在索引中選擇頁級鎖。
動態鎖定具有下列優點:
·?簡化數據庫管理。?數據庫管理員不必調整鎖升級閾值。
·?提高性能。?數據庫引擎通過使用適合任務的鎖使系統開銷減至最小。
·?應用程序開發人員可以集中精力進行開發。?數據庫引擎將自動調整鎖定。
在?SQL?Server?2008?中,鎖升級的行為已發生改變,其中引入了?LOCK_ESCALATION選項






![obj[]與obj._Ruby中帶有示例的Array.rassoc(obj)方法](http://pic.xiahunao.cn/obj[]與obj._Ruby中帶有示例的Array.rassoc(obj)方法)


)
)




函數以及C ++ STL中的示例)
分數)


)