第十章 開箱即用
“開箱即用”(batteries included)最初是由Frank Stajano提出的,指的是Python豐富的標準庫。
模塊
使用import將函數從外部模塊導入到程序中。
import math
math.sin(0)#結果為:0.0
模塊就是程序
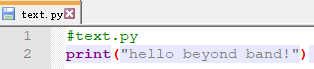
在文件夾中創建一個test.py,內容如下:
#text.py
print("hello beyond band!")
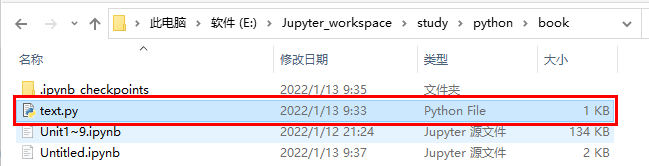
位置如下:
sys.path包含一個目錄(表示為字符串)列表,解釋器將在這些目錄中查找模塊。
import sys
sys.path.append('E:\Jupyter_workspace\study\python\book')import text#結果為:hello beyond band!
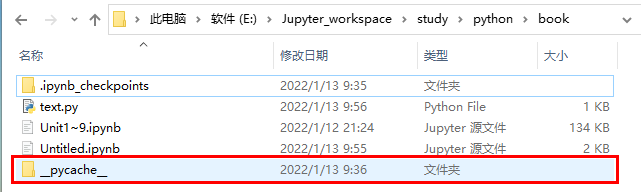
程序運行完之后會生成一個__pycache__文件夾,這個目錄包含處理后的文件,Python能夠更高效地處理它們。
以后再導入這個模塊時,如果.py文件未發生變化,Python將導入處理后的文件,否則將重新生成處理后的文件。
導入這個模塊時,執行了其中的代碼。但如果再次導入它,什么事情都不會發生。
模塊并不是用來執行操作(如打印文本)的,而是用于定義變量、函數、類等。
模塊是用來下定義的
模塊在首次被導入程序時執行。
在模塊中定義的類和函數以及對其進行賦值的變量都將成為模塊的屬性。
1,在模塊中定義函數
創建hellp.py
內容如下:
#hello.py
def hello():print("Hello beyond!!!")
在另一個py文件中導入該模塊
import sys
sys.path.append('E:\Jupyter_workspace\study\python\book')import hellohello.hello()#結果為:Hello beyond!!!
在模塊的全局作用域內定義的名稱都可像上面這樣訪問。
為何不在主程序中定義一切呢?
主要是為了重用代碼。通過將代碼放在模塊中,就可在多個程序中使用它們。
2,在模塊中添加測試代碼
檢查模塊是作為程序運行還是被導入另一個程序。為此,需要使用變量__name__。
在上面的基礎上進行測試:
import sys
sys.path.append('E:\Jupyter_workspace\study\python\book')import hellohello.hello()#結果為:Hello beyond!!!__name__#結果為:'__main__'
hello.__name__#結果為:'hello'
在主程序中(包括解釋器的交互式提示符),變量__name__的值是’__main__’,
而在導入的模塊中,這個變量被設置為該模塊的名稱。
一個包含有條件地執行的測試代碼的模塊
創建beyond.py
內容如下:
#beyond.py
def hello():print("beyond!")def test():hello()if __name__ == '__main__':test()
如果將這個模塊作為程序運行,將執行函數hello;
如果導入它,其行為將像普通模塊一樣。
在另一個py文件中導入該模塊
import sys
sys.path.append('E:\Jupyter_workspace\study\python\book')import beyondbeyond.hello()#結果為:beyond!
beyond.test()#結果為:beyond!
將測試代碼放在了函數test中。原本可以將這些代碼直接放在if語句中,但通過將其放在一個獨立的測試函數中,可在程序中導入模塊并對其進行測試。
讓模塊可用
1,將模塊放在正確的位置
將模塊放在正確的位置很容易,只需找出Python解釋器到哪里去查找模塊,再將文件放在這個地方即可。
模塊sys的變量path中找到目錄列表(即搜索路徑)。
如果要打印的數據結構太大,一行容納不下,可使用模塊pprint中的函數pprint(而不是普通print語句)。pprint是個卓越的打印函數,能夠更妥善地打印輸出。
import sys,pprint
pprint.pprint(sys.path)#結果為:
'''
['','D:\\Anaconda3\\python36.zip','D:\\Anaconda3\\DLLs','D:\\Anaconda3\\lib','D:\\Anaconda3','D:\\Anaconda3\\lib\\site-packages','D:\\Anaconda3\\lib\\site-packages\\Babel-2.5.0-py3.6.egg','D:\\Anaconda3\\lib\\site-packages\\win32','D:\\Anaconda3\\lib\\site-packages\\win32\\lib','D:\\Anaconda3\\lib\\site-packages\\Pythonwin','D:\\Anaconda3\\lib\\site-packages\\IPython\\extensions','C:\\Users\\yanyu\\.ipython','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook','E:\\Jupyter_workspace\\study\\python\x08ook']
'''
每個字符串都表示一個位置,如果要讓解釋器能夠找到模塊,可將其放在其中任何一個位置中。目錄site-packages是最佳的選擇,因為它就是用來放置模塊的。
只要模塊位于類似于site-packages這樣的地方,所有的程序就都能夠導入它。
將上述的beyond.py文件放入到site-packages文件夾下。
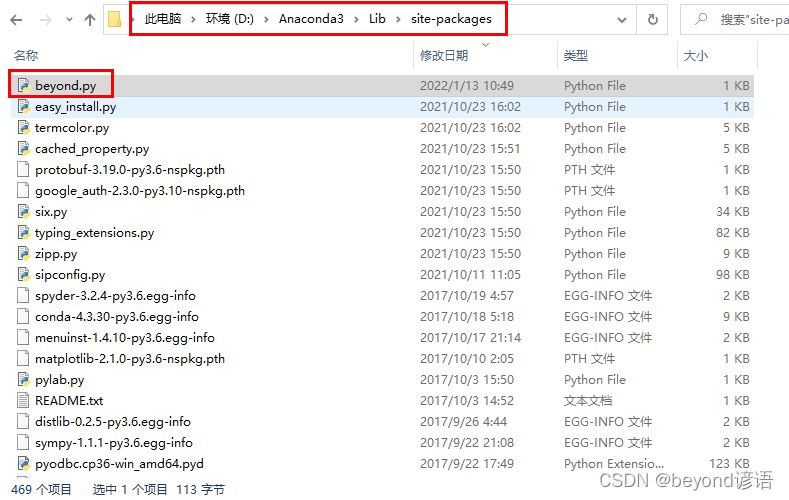
故在其他程序中可以直接導入即可:
import beyond
beyond.hello()#結果為:beyond!
2,告訴解析器到哪里去查找
| 將模塊放在正確的位置可能不是合適的解決方案,其中的原因很多 |
|---|
| 1,不希望Python解釋器的目錄中充斥著你編寫的模塊。 |
| 2,沒有必要的權限,無法將文件保存到Python解釋器的目錄中。 |
| 3,想將模塊放在其他地方。 |
| 4,如果將模塊放在其他地方,就必須告訴解釋器到哪里去查找。 |
| 標準做法 | 解釋 |
|---|---|
| 1,將模塊所在的目錄包含在環境變量PYTHONPATH中 | 環境變量PYTHONPATH的內容隨操作系統而異,但它基本上類似于sys.path,也是一個目錄列表。 |
| 2,使用路徑配置文件 | 這些文件的擴展名為.pth,位于一些特殊目錄中,包含要添加到sys.path中的目錄。 |
包
為組織模塊,可將其編組為包(package)。
包其實就是另一種模塊(可包含其他模塊的模塊)。
模塊存儲在擴展名為.py的文件中,而包則是一個目錄。
要被Python視為包,目錄必須包含文件__init__.py。
要將模塊加入包中,只需將模塊文件放在包目錄中即可。還可以在包中嵌套其他包。
按照下面的五個文件夾路徑創建對應的文件和文件夾
| 文件/目錄 | 描述 |
|---|---|
~/python/ | PYTHONPATH中的目錄 |
~/python/drawing/ | 包目錄(包drawing) |
~/python/drawing/__init__.py | 包代碼(模塊drawing) |
~/python/drawing/colors.py | 模塊colors |
~/python/drawing/shapes.py | 模塊shapes |
import drawing#導入drawing包
import drawing.colors#導入drawing包中的模塊colors
from drawing import shapes#導入模塊shapes
'''
執行第1條語句后,便可使用目錄drawing中文件__init__.py的內容,但不能使用模塊shapes和colors的內容。
執行第2條語句后,便可使用模塊colors,但只能通過全限定名drawing.colors來使用。
執行第3條語句后,便可使用簡化名(即shapes)來使用模塊shapes。
'''
探索模塊
模塊包含什么
接下來以一個名為copy的標準模塊來進行解釋:
import copy
沒有引發異常,說明確實有這樣的模塊。
1,使用dir
函數dir,它列出對象的所有屬性(對于模塊,它列出所有的函數、類、變量等)
在這些名稱中,有幾個以下劃線打頭。根據約定,這意味著它們并非供外部使用。
使用一個簡單的列表推導將這些名稱過濾掉。
[n for n in dir(copy) if not n.startswith('_')] 結果包含dir(copy)返回的不以下劃線打頭的名稱,
import copy
dir(copy)#結果為:
"""
['Error','__all__','__builtins__','__cached__','__doc__','__file__','__loader__','__name__','__package__','__spec__','_copy_dispatch','_copy_immutable','_deepcopy_atomic','_deepcopy_dict','_deepcopy_dispatch','_deepcopy_list','_deepcopy_method','_deepcopy_tuple','_keep_alive','_reconstruct','copy','deepcopy','dispatch_table','error']
"""[n for n in dir(copy) if not n.startswith('_')]#結果為:['Error', 'copy', 'deepcopy', 'dispatch_table', 'error']2,變量__all__
由上述的代碼段可知,在dir(copy)返回的完整清單中,包含名稱__all__。
__all__這個變量包含一個列表,它與前面使用列表推導創建的列表類似,但是在模塊內部設置的。
import copy
copy.__all__#結果為:['Error', 'copy', 'deepcopy']
使用help獲取幫助
使用help獲取有關函數copy的信息
help(copy.copy)#結果為:
'''
Help on function copy in module copy:copy(x)Shallow copy operation on arbitrary Python objects.See the module's __doc__ string for more info.
'''
上述幫助信息指出,函數copy只接受一個參數x,且執行的是淺復制。
幫助信息是從函數copy的文檔字符串中提取的
print(copy.copy.__doc__)#結果為:
'''
Shallow copy operation on arbitrary Python objects.See the module's __doc__ string for more info.
'''
相比于直接查看文檔字符串,使用help的優點是可獲取更多的信息,如函數的特征標(即它接受的參數)。
對模塊copy本身調用help
help(copy)#結果為:
'''
Help on module copy:NAMEcopy - Generic (shallow and deep) copying operations.DESCRIPTIONInterface summary:import copyx = copy.copy(y) # make a shallow copy of yx = copy.deepcopy(y) # make a deep copy of yFor module specific errors, copy.Error is raised.The difference between shallow and deep copying is only relevant forcompound objects (objects that contain other objects, like lists orclass instances).- A shallow copy constructs a new compound object and then (to theextent possible) inserts *the same objects* into it that theoriginal contains.- A deep copy constructs a new compound object and then, recursively,inserts *copies* into it of the objects found in the original.Two problems often exist with deep copy operations that don't existwith shallow copy operations:a) recursive objects (compound objects that, directly or indirectly,contain a reference to themselves) may cause a recursive loopb) because deep copy copies *everything* it may copy too much, e.g.administrative data structures that should be shared even betweencopiesPython's deep copy operation avoids these problems by:a) keeping a table of objects already copied during the currentcopying passb) letting user-defined classes override the copying operation or theset of components copiedThis version does not copy types like module, class, function, method,nor stack trace, stack frame, nor file, socket, window, nor array, norany similar types.Classes can use the same interfaces to control copying that they useto control pickling: they can define methods called __getinitargs__(),__getstate__() and __setstate__(). See the documentation for module"pickle" for information on these methods.CLASSESbuiltins.Exception(builtins.BaseException)Errorclass Error(builtins.Exception)| Common base class for all non-exit exceptions.| | Method resolution order:| Error| builtins.Exception| builtins.BaseException| builtins.object| | Data descriptors defined here:| | __weakref__| list of weak references to the object (if defined)| | ----------------------------------------------------------------------| Methods inherited from builtins.Exception:| | __init__(self, /, *args, **kwargs)| Initialize self. See help(type(self)) for accurate signature.| | __new__(*args, **kwargs) from builtins.type| Create and return a new object. See help(type) for accurate signature.| | ----------------------------------------------------------------------| Methods inherited from builtins.BaseException:| | __delattr__(self, name, /)| Implement delattr(self, name).| | __getattribute__(self, name, /)| Return getattr(self, name).| | __reduce__(...)| helper for pickle| | __repr__(self, /)| Return repr(self).| | __setattr__(self, name, value, /)| Implement setattr(self, name, value).| | __setstate__(...)| | __str__(self, /)| Return str(self).| | with_traceback(...)| Exception.with_traceback(tb) --| set self.__traceback__ to tb and return self.| | ----------------------------------------------------------------------| Data descriptors inherited from builtins.BaseException:| | __cause__| exception cause| | __context__| exception context| | __dict__| | __suppress_context__| | __traceback__| | argsFUNCTIONScopy(x)Shallow copy operation on arbitrary Python objects.See the module's __doc__ string for more info.deepcopy(x, memo=None, _nil=[])Deep copy operation on arbitrary Python objects.See the module's __doc__ string for more info.DATA__all__ = ['Error', 'copy', 'deepcopy']FILEd:\anaconda3\lib\copy.py
'''
文檔
文檔是有關模塊信息的自然來源
例如,你可能想知道range的參數是什么?
在這種情況下,與其在Python圖書或標準Python文檔中查找對range的描述,不如直接檢查這個函數。
print(range.__doc__)#結果為:
'''
range(stop) -> range object
range(start, stop[, step]) -> range objectReturn an object that produces a sequence of integers from start (inclusive)
to stop (exclusive) by step. range(i, j) produces i, i+1, i+2, ..., j-1.
start defaults to 0, and stop is omitted! range(4) produces 0, 1, 2, 3.
These are exactly the valid indices for a list of 4 elements.
When step is given, it specifies the increment (or decrement).
'''
“Python庫參考手冊”(https://docs.python.org/library)
使用源代碼
要學習Python,閱讀源代碼是除動手編寫代碼外的最佳方式。
假設你要閱讀標準模塊copy的代碼,可以在什么地方找到呢?
print(copy.__file__)#結果為:D:\Anaconda3\lib\copy.py
你可在代碼編輯器(如IDLE)中打開文件copy.py,并開始研究其工作原理。
標準庫:一些深受歡迎的模塊
sys
模塊sys讓你能夠訪問與Python解釋器緊密相關的變量和函數。
| 函數/變量 | 描述 |
|---|---|
| argv | 命令行參數,包括腳本名 |
| exit([arg]) | 退出當前程序,可通過可選參數指定返回值或錯誤消息 |
| modules | 一個字典,將模塊名映射到加載的模塊 |
| path | 一個列表,包含要在其中查找模塊的目錄的名稱 |
| platform | 一個平臺標識符,如sunos5或win32 |
| stdin | 標準輸入流——一個類似于文件的對象 |
| stdout | 標準輸出流——一個類似于文件的對象 |
| stderr | 標準錯誤流——一個類似于文件的對象 |
反轉并打印命令行參數
創建了一個sys.argv的副本,也可修改sys.argv。
import sys
args = sys.argv[1:]
args.reverse()
print(' '.join(args))#結果為:C:\Users\yanyu\AppData\Roaming\jupyter\runtime\kernel-17c0e23a-ea6e-40f9-98dc-68588128f0cc.json -fprint(' '.join(reversed(sys.argv[1:])))#結果為:C:\Users\yanyu\AppData\Roaming\jupyter\runtime\kernel-17c0e23a-ea6e-40f9-98dc-68588128f0cc.json -f
os
模塊os讓你能夠訪問多個操作系統服務。
os及其子模塊os.path還包含多個查看、創建和刪除目錄及文件的函數,以及一些操作路徑的函數(例如,os.path.split和os.path.join讓你在大多數情況下都可忽略os.pathsep)。
| 函數/變量 | 描述 |
|---|---|
| environ | 包含環境變量的映射 |
| system(command) | 在子shell中執行操作系統命令 |
| sep | 路徑中使用的分隔符 |
| pathsep | 分隔不同路徑的分隔符 |
| linesep | 行分隔符(’\n’、’\r’或’\r\n’) |
| urandom(n) | 返回n個字節的強加密隨機數據 |
要訪問環境變量PYTHONPATH,可使用表達式os.environ['PYTHONPATH']。
變量os.sep是用于路徑名中的分隔符。
在Windows中,標準分隔符為\\(這種Python語法表示單個反斜杠)
在UNIX(以及macOS的命令行Python版本)中,標準分隔符為/。
變量os.linesep是用于文本文件中的行分隔符:
在UNIX/OS X中為單個換行符(\n)
在Windows中為回車和換行符(\r\n)
啟動圖形用戶界面程序,如Web瀏覽器
在UNIX中:假設目錄為/usr/bin/firefox
import os
os.system('/usr/bin/firefox')
在Windows中:假設目錄為C:\Program Files\Mozilla Firefox
這里用引號將Program Files和Mozilla Firefox括起來了。
如果不這樣做,底層shell將受阻于空白處(對于PYTHONPATH中的路徑,也必須這樣做)。
另外,這里必須使用反斜桿,因為 Windows shell 無法識別斜杠。
import os
os.system(r'C:\"Program Files"\"Mozilla Firefox"\firefox.exe')
Windows特有的函數os.startfile,也可以完成該操作
import os
os.startfile(r'C:\Program Files\Mozilla Firefox\firefox.exe')
就啟動Web瀏覽器這項任務而言,使用模塊webbrowser,這個模塊包含一個名為open的函數,讓你能夠啟動默認Web瀏覽器并打開指定的URL。
import webbrowser
webbrowser.open('https://beyondyanyu.blog.csdn.net/')
fileinput
模塊fileinput讓你能夠輕松地迭代一系列文本文件中的所有行。
| 函數 | 描述 |
|---|---|
| input([files[, inplace[, backup]]]) | 幫助迭代多個輸入流中的行 |
| filename() | 返回當前文件的名稱 |
| lineno() | 返回(累計的)當前行號 |
| filelineno() | 返回在當前文件中的行號 |
| isfirstline() | 檢查當前行是否是文件中的第一行 |
| isstdin() | 檢查最后一行是否來自sys.stdin |
| nextfile() | 關閉當前文件并移到下一個文件 |
| close() | 關閉序列 |
fileinput.input是其中最重要的函數,它返回一個可在for循環中進行迭代的對象。
在Python腳本中添加行號
rstrip是一個字符串方法,它將刪除指定字符串兩端的空白,并返回結果
import fileinputfor line in fileinput.input(inplace=True):line = line.rstrip()num = fileinput.lineno()print('{:<50} # {:2d}'.format(line,num))
集合、堆和雙端隊列
1,集合
集合是由內置類set實現的,這意味著你可直接創建集合,而無需導入模塊sets。
set(range(1,30,2))#結果為:{1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29}
僅使用花括號這將創建一個空字典
type({})#結果為:dict
集合主要用于成員資格檢查,因此將忽略重復的元素
{0, 1, 2, 3, 0, 1, 2, 3, 4, 5}#結果為:{0, 1, 2, 3, 4, 5}
集合中元素的排列順序是不確定的
{'hjj', 'sq', 'hjq', 'hjj', 'hjq'}#結果為:{'hjj', 'hjq', 'sq'}
計算兩個集合的并集,可對其中一個集合調用方法union也可使用按位或運算符|
a = {1,2,3}
b = {2,3,4}
a.union(b)#結果為:{1, 2, 3, 4}
a | b#結果為:{1, 2, 3, 4}
還有其他一些方法和對應的運算符
a = {1,2,3}
b = {2,3,4}
c = a & b
c.issubset(a)#結果為:Truec <= a#結果為:True
c.issuperset(a)#結果為:Falsec >= a#結果為:False
a.intersection(b)#結果為:{2, 3}a & b#結果為:{2, 3}
a.difference(b)#結果為:{1}a - b#結果為:{1}
a.symmetric_difference(b)#結果為:{1, 4}a ^ b#結果為:{1, 4}a.copy()#結果為:{1, 2, 3}
a.copy() is a#結果為:False
集合是可變的,因此不能用作字典中的鍵。
集合只能包含不可變(可散列)的值,因此不能包含其他集合。
frozenset類型,它表示不可變(可散列)的集合。
構造函數frozenset創建給定集合的副本。
在需要將集合作為另一個集合的成員或字典中的鍵時,frozenset很有用。
a = set()
b = set()
a.add(b)#報錯!!!
'''
TypeError Traceback (most recent call last)
<ipython-input-48-07ed0deb5758> in <module>()1 a = set()2 b = set()
----> 3 a.add(b)TypeError: unhashable type: 'set'
'''a.add(frozenset(b))
print(a.add(frozenset(b)))#結果為:None
print(a)#結果為:{frozenset()}
print(b)#結果為:set()
2,堆
堆(heap),它是一種優先隊列。
優先隊列讓能夠以任意順序添加對象,并隨時(可能是在兩次添加對象之間)找出(并刪除)最小的元素。
Python沒有獨立的堆類型,而只有一個包含一些堆操作函數的模塊。這個模塊名為heapq(其中的q表示隊列),它包含6個函數。
| 函數 | 描述 |
|---|---|
| heappush(heap, x) | 將x壓入堆中 |
| heappop(heap) | 從堆中彈出最小的元素 |
| heapify(heap) | 讓列表具備堆特征 |
| heapreplace(heap, x) | 彈出最小的元素,并將x壓入堆中 |
| nlargest(n, iter) | 返回iter中n個最大的元素 |
| nsmallest(n, iter) | 返回iter中n個最小的元素 |
函數heappush用于在堆中添加一個元素。
from heapq import *
from random import shuffle
data = list(range(10))
shuffle(data)
heap = []
for n in data:heappush(heap,n)heap#結果為:[0, 1, 5, 2, 4, 7, 9, 8, 3, 6]#位置i處的元素總是大于位置i // 2處的元素(反過來說就是小于位置2 * i和2 * i + 1處的元素)。這是底層堆算法的基礎,稱為堆特征(heap property)。
heappush(heap,0.5)
heap#結果為:[0, 0.5, 5, 2, 1, 7, 9, 8, 3, 6, 4]heappop(heap)#結果為:0
heappop(heap)#結果為:0.5
heappop(heap)#結果為:1heap#結果為:[2, 3, 5, 6, 4, 7, 9, 8]#函數heapify通過執行盡可能少的移位操作將列表變成合法的堆(即具備堆特征)。
heap = [5,8,0,3,6,7,9,1,4,2]
heapify(heap)
heap#結果為:[0, 1, 5, 3, 2, 7, 9, 8, 4, 6]#函數heapreplace從堆中彈出最小的元素,再壓入一個新元素。
heapreplace(heap,0.5)#結果為:0
heap#結果為:[0.5, 1, 5, 3, 2, 7, 9, 8, 4, 6]
heapreplace(heap,10)#結果為:0.5
heap#結果為:[1, 2, 5, 3, 6, 7, 9, 8, 4, 10]
3,雙端隊列
在需要按添加元素的順序進行刪除時,雙端隊列很有用。
在模塊collections中,包含類型deque以及其他幾個集合(collection)類型。
from collections import deque
q = deque(range(5))
q.append(5)
q.appendleft(6)
q#結果為:deque([6, 0, 1, 2, 3, 4, 5])q.pop()#結果為:5
q.popleft()#結果為:6q.rotate(3)
q#結果為:deque([2, 3, 4, 0, 1])q.rotate(-1)
q#結果為:deque([3, 4, 0, 1, 2])
雙端隊列支持在隊首(左端)高效地附加和彈出元素,還可高效地旋轉元素(將元素向右或向左移,并在到達一端時環繞到另一端)。
雙端隊列對象還包含方法extend和extendleft,其中extend類似于相應的列表方法,而extendleft類似于appendleft。
用于extendleft的可迭代對象中的元素將按相反的順序出現在雙端隊列中。
time
模塊time包含用于獲取當前時間、操作時間和日期、從字符串中讀取日期、將日期格式化為字符串的函數。
元組(2008, 1, 21, 12, 2, 56, 0, 21, 0)表示2008年1月21日12時2分56秒。這一天是星期一,2008年的第21天。
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | 年 | 如2000、2001等 |
| 1 | 月 | 范圍1~1 |
| 2 | 日 | 范圍1~31 |
| 3 | 時 | 范圍0~23 |
| 4 | 分 | 范圍0~59 |
| 5 | 秒 | 范圍0~61,這考慮到了閏一秒和閏兩秒的情況。 |
| 6 | 星期 | 范圍0~6,其中0表示星期一 |
| 7 | 儒略日 | 范圍1~366 |
| 8 | 夏令時 | 0、1或-1,夏令時數字是一個布爾值(True或False),但如果你使用-1,那么mktime[將時間元組轉換為時間戳(從新紀元開始后的秒數)的函數]可能得到正確的值。 |
| 函數 | 描述 |
|---|---|
| asctime([tuple]) | 將時間元組轉換為字符串 |
| localtime([secs]) | 將秒數轉換為表示當地時間的日期元組 |
| mktime(tuple) | 將時間元組轉換為當地時間 |
| sleep(secs) | 休眠(什么都不做)secs秒 |
| strptime(string[, format]) | 將字符串轉換為時間元組 |
| time() | 當前時間(從新紀元開始后的秒數,以UTC為準) |
函數time.asctime將當前時間轉換為字符串
import time
time.asctime()#結果為:'Sun Jan 16 10:41:41 2022'
兩個較新的與時間相關的模塊:datetime和timeit。
前者提供了日期和時間算術支持,而后者可幫助你計算代碼段的執行時間。
random
模塊random包含生成偽隨機數的函數,有助于編寫模擬程序或生成隨機輸出的程序。
雖然這些函數生成的數字好像是完全隨機的,但它們背后的系統是可預測的。
真正的隨機(如用于加密或實現與安全相關的功能),應考慮使用模塊os中的函數urandom。
| 函數 | 描述 |
|---|---|
| random() | 返回一個0~1(含)的隨機實數 |
| getrandbits(n) | 以長整數方式返回n個隨機的二進制位 |
| uniform(a, b) | 返回一個a~b(含)的隨機實數 |
| randrange([start], stop, [step]) | 從range(start, stop, step)中隨機地選擇一個數 |
| choice(seq) | 從序列seq中隨機地選擇一個元素 |
| shuffle(seq[, random]) | 就地打亂序列seq |
| sample(seq, n) | 從序列seq中隨機地選擇n個值不同的元素 |
函數random.random是最基本的隨機函數之一,它返回一個0~1(含)的偽隨機數。
首先,獲取表示時間段(1998年)上限和下限的實數。為此,可使用時間元組來表示日期(將星期、儒略日和夏令時都設置為?1,讓Python去計算它們的正確值),并對這些元組調用mktime
接下來,以均勻的方式生成一個位于該范圍內(不包括上限)的隨機數
然后,將這個數轉換為易于理解的日期。
from random import *
from time import *
date1 = (1998,12,2,0,0,0,-1,-1,-1)
time1 = mktime(date1)
date2 = (1999,7,5,0,0,0,-1,-1,-1)
time2 = mktime(date2)random_time = uniform(time1, time2)
print(asctime(localtime(random_time)))#結果為:Fri Feb 5 20:55:09 1999
詢問用戶要擲多少個骰子、每個骰子有多少面。擲骰子的機制是使用randrange和for循環實現。
from random import randrange
num = int(input('How many dice?'))
sides = int(input('How many sides per die?'))
sum = 0
for i in range(num):sum += randrange(sides) + 1
print("The result is",sum)#結果為:
'''
How many dice?3
How many sides per die?6
The result is 17
'''
shelve和json
1,一個潛在的陷阱
import shelve
s = shelve.open('database.dat')s['x'] = ['a','b','c']
s['x'].append('d')
s['x']#結果為:['a', 'b', 'c']
‘d’消失了
列表[‘a’, ‘b’, ‘c’]被存儲到s的’x’鍵下。
獲取存儲的表示,并使用它創建一個新列表,再將’d’附加到這個新列表末尾,但這個修改后的版本未被存儲!
最后,再次獲取原來的版本——其中沒有’d’。
解決方法:
import shelve
s = shelve.open('database.dat')temp = s['x']
temp.append('d')
s['x'] = temp
s['x']
2,一個簡單的數據庫示例
import sys,shelvedef store_person(db):pid = input("Enter unique ID number:")person = {}person['name'] = input("Enter name:")person['age'] = input("Enter age:")person['phone'] = input('Enter phone number:')db[pid] = persondef lookup_person(db):pid = input("Enter ID number:")fileld = input("What would you like to know?(name,age,phone)")fileld = field.strip.lower()print(fileld.capitablize() + ':', db[pid][field])def print_help():print("The available commands are:")print("store: Stores information about a person")print("lookup: Looks up a person from ID number")print("quit: Save changes and exit")print("?: Prints this message")def enter_command():cmd = input("Enter command(? for help):")cmd = cmd.strip().lower()def main():database = shelve.open("E:\\Jupyter_workspace\\study\\python\\book\\database.dat")try:while True:cmd = enter_command()if cmd == 'store':store_person(database)elif cmd == 'lookup':lookup_person(database)elif cmd == '?':print_help()elif cmd == 'quit':returnfinally:database.close()if name == '__main__':main()
re
模塊re提供了對正則表達式的支持。
1,正則表達式是什么?
正則表達式是可匹配文本片段的模式。
- 通配符
句點與除換行符外的任何字符都匹配,被稱為通配符(wildcard)。
正則表達式’.ython‘與字符串’python’和’jython’都匹配,但不與’cpython’、'ython’等字符串匹配,因為句點只與一個字符匹配,而不與零或兩個字符匹配。 - 對特殊字符進行轉義
普通字符只與自己匹配,但特殊字符的情況完全不同。
要讓特殊字符的行為與普通字符一樣,可對其進行轉義。
使用模式’python\\.org’,它只與’python.org'匹配。
為表示模塊re要求的單個反斜杠,需要在字符串中書寫兩個反斜杠,讓解釋器對其進行轉義。
這里包含兩層轉義:解釋器執行的轉義和模塊re執行的轉義。
也可使用原始字符串,如r'python\.org'。 - 字符集
用方括號將一個子串括起,創建一個所謂的字符集。字符集只能匹配一個字符。
'[pj]ython‘與’python‘和’jython'都匹配,但不與其他字符串匹配。
'[a-z]'與a~z的任何字母都匹配。
'[a-zA-Z0-9]'與大寫字母、小寫字母和數字都匹配。
'[^abc]'與除a、b和c外的其他任何字符都匹配。 - 二選一和子模式
‘python|perl’,只匹配字符串’python‘和’perl’,也可重寫為’p(ython|erl)’。
單個字符也可稱為子模式。 - 可選模式和重復模式
通過在子模式后面加上問號,可將其指定為可選的,即可包含可不包含。
r'(http://)?(www\.)?python\.org
只與下面這些字符串匹配:
‘http://www.python.org’
‘http://python.org’
‘www.python.org’
‘python.org’
問號表示可選的子模式可出現一次,也可不出現。
(pattern)*:pattern可重復0、1或多次。
(pattern)+:pattern可重復1或多次。
(pattern){m,n}:模式可從父m~n次。
r'w*\.python\.org'與’www.python.org‘匹配,也與’.python.org’、’ww.python.org‘和’wwwwwww.python.org‘匹配。同樣,r'w+\.python\.org'與’w.python.org‘匹配,但與’.python. org‘不匹配,而r'w{3,4}\.python\.org'只與’www.python.org‘和’wwww.python.org'匹配。
- 字符串的開頭和末尾
查找與模式匹配的子串
字符串’www.python.org‘中的子串’www‘與模式’w+‘匹配
確定字符串的開頭是否與模式’ht+p’匹配,為此可使用脫字符(’^’)來指出這一點。
'^ht+p‘與’http://python.org‘和’htttttp://python.org‘匹配,但與’www.http.org'不匹配。
同樣,要指定字符串末尾,可使用美元符號($)。
2,模塊re的內容
模塊re包含多個使用正則表達式的函數
| 函數 | 描述 |
|---|---|
| compile(pattern[, flags]) | 根據包含正則表達式的字符串創建模式對象 |
| search(pattern, string[, flags]) | 在字符串中查找模式 |
| match(pattern, string[, flags]) | 在字符串開頭匹配模式 |
| split(pattern, string[, maxsplit=0]) | 根據模式來分割字符串 |
| findall(pattern, string) | 返回一個列表,其中包含字符串中所有與模式匹配的子串 |
| sub(pat, repl, string[, count=0]) | 將字符串中與模式pat匹配的子串都替換為repl |
| escape(string) | 對字符串中所有的正則表達式特殊字符都進行轉義 |
函數re.compile將用字符串表示的正則表達式轉換為模式對象,以提高匹配效率。
函數re.search在給定字符串中查找第一個與指定正則表達式匹配的子串。如果找到這樣的子串,將返回MatchObject(結果為真),否則返回None(結果為假)。鑒于返回值的這種特征,可在條件語句中使用這個函數
import repat = "beyond"
string = "I like the beyond band"
if re.search(pat, string):print('Found it!')
#結果為:Found it!
函數re.split根據與模式匹配的子串來分割字符串。
使用re.split時,可以空格和逗號為分隔符來分割字符串。
import resome_text = 'alpha, beta,,,,gamma delta'
re.split('[, ]+', some_text)#結果為:['alpha', 'beta', 'gamma', 'delta']#如果模式包含圓括號,將在分割得到的子串之間插入括號中的內容。
re.split('o(o)','foobar')#結果為:['f', 'o', 'bar']#參數maxsplit指定最多分割多少次。
re.split('[, ]+', some_text, maxsplit=2)#結果為:['alpha', 'beta', 'gamma delta']
re.split('[, ]+', some_text, maxsplit=1)#結果為:['alpha', 'beta,,,,gamma delta']#函數re.findall返回一個列表,其中包含所有與給定模式匹配的子串。
#要找出字符串包含的所有單詞
pat = '[a-zA-Z]+'
text = '"Hm... Err -- are you sure?" he said, sounding insecure.'
re.findall(pat, text)#結果為:['Hm', 'Err', 'are', 'you', 'sure', 'he', 'said', 'sounding', 'insecure']#查找所有的標點符號
pat = r'[.?\-",]+'
re.findall(pat, text)#結果為:['"', '...', '--', '?"', ',', '.']#函數re.sub從左往右將與模式匹配的子串替換為指定內容。
pat = '{name}'
text = 'Dear {name}...'
re.sub(pat, 'Mr. Gumby', text)#結果為:'Dear Mr. Gumby...'#re.escape是一個工具函數
re.escape('www.python.org')#結果為:'www\\.python\\.org'
re.escape('But where is the ambiguity?')#結果為:'But\\ where\\ is\\ the\\ ambiguity\\?'
3,匹配對象和編組
在模塊re中,查找與模式匹配的子串的函數都在找到時返回MatchObject對象。
這種對象包含與模式匹配的子串的信息,還包含模式的哪部分與子串的哪部分匹配的信息。這些子串部分稱為編組(group)。
編組就是放在圓括號內的子模式,它們是根據左邊的括號數編號的,其中編組0指的是整個模式。
’There (was a (wee) (cooper)) who (lived in Fyfe)’
包含如下編組:
0 There was a wee cooper who lived in Fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in Fyfe
r’www.(.+).com$’
編組0包含整個字符串,而編組1包含’www.‘和’.com’之間的內容。
| 方法 | 描述 |
|---|---|
| group([group1, …]) | 獲取與給定子模式(編組)匹配的子串 |
| start([group]) | 返回與給定編組匹配的子串的起始位置 |
| end([group]) | 返回與給定編組匹配的子串的終止位置(與切片一樣,不包含終止位置) |
| span([group]) | 返回與給定編組匹配的子串的起始和終止位置 |
方法group返回與模式中給定編組匹配的子串。如果沒有指定編組號,則默認為0。
如果只指定了一個編組號(或使用默認值0),將只返回一個字符串;否則返回一個元組,其中包含與給定編組匹配的子串。
方法start返回與給定編組(默認為0,即整個模式)匹配的子串的起始索引。
方法end類似于start,但返回終止索引加1
方法span返回一個元組,其中包含與給定編組(默認為0,即整個模式)匹配的子串的起始索引和終止索引。
import re
m = re.match(r'www\.(.*)\..{3}', 'www.beyondyanyu.net')m.group(1)#結果為:4
m.end(1)#結果為:15
m.span(1)#結果為:(4,15)
4,替換中的組號和函數
將’*something*‘替換為’<em>something</em>’
import re#首先開始創建模板:
emphasis_pattern = r'\*([^\*]+)\*''''
上下這兩條正則表達式等價,很顯然下面的加有注解很人性化。
'''emphasis_pattern = re.compile(r'''
\* #起始突出標志---一個星號
( #與要突出的內容匹配的編組的起始位置
[^\*]+ #與除星號外的其他字符都匹配
) #編組到此結束
\* #結束突出標志
''',re.VERBOSE)re.sub(emphasis_pattern, r'<em>\1</em>', 'Hello, *world*!')#結果為:'Hello, <em>world</em>!'
重復運算符默認是貪婪的,這意味著它們將匹配盡可能多的內容。
import reemphasis_pattern = r'\*(.+)\*'
re.sub(emphasis_pattern, r'<em>\1</em>', '*This* is *it*!')#結果為:'<em>This* is *it</em>!'
這個模式匹配了從第一個星號到最后一個星號的全部內容,其中包含另外兩個星號!這就是貪婪的意思:能匹配多少就匹配多少。
在后面加上問號來將其指定為非貪婪
import reemphasis_pattern = r'\*\*(.+?)\*\*'
re.sub(emphasis_pattern, r'<em>\1</em>', '**This** is **it**!')#結果為:'<em>This</em> is <em>it</em>!'
5,其他有趣的標準模塊
| 模塊名稱 | 描述 |
|---|---|
| argparse | 在UNIX中,運行命令行程序時常常需要指定各種選項(開關),Python解釋器就是這樣的典范。這些選項都包含在sys.argv中,但要正確地處理它們絕非容易。模塊argparse使得提供功能齊備的命令行界面易如反掌。 |
| cmd | 這個模塊讓你能夠編寫類似于Python交互式解釋器的命令行解釋器。你可定義命令,讓用戶能夠在提示符下執行它們。或許可使用這個模塊為你編寫的程序提供用戶界面? |
| csv | CSV指的是逗號分隔的值(comma-seperated values),很多應用程序(如很多電子表格程序和數據庫程序)都使用這種簡單格式來存儲表格數據。這種格式主要用于在不同的程序之間交換數據。模塊csv讓你能夠輕松地讀寫CSV文件,它還以非常透明的方式處理CSV格式的一些棘手部分。 |
| datetime | 如果模塊time不能滿足你的時間跟蹤需求,模塊datetime很可能能夠滿足。datetime支持特殊的日期和時間對象,并讓你能夠以各種方式創建和合并這些對象。相比于模塊time,模塊datetime的接口在很多方面都更加直觀。 |
| difflib | 這個庫讓你能夠確定兩個序列的相似程度,還讓你能夠從很多序列中找出與指定序列最為相似的序列。例如,可使用difflib來創建簡單的搜索程序。 |
| enum | 枚舉類型是一種只有少數幾個可能取值的類型。很多語言都內置了這樣的類型,如果你在使用Python時需要這樣的類型,模塊enum可提供極大的幫助。 |
| functools | 這個模塊提供的功能是,讓你能夠在調用函數時只提供部分參數(部分求值,partial evaluation),以后再填充其他的參數。在Python 3.0中,這個模塊包含filter和reduce。 |
| hashlib | 使用這個模塊可計算字符串的小型“簽名”(數)。計算兩個不同字符串的簽名時,幾乎可以肯定得到的兩個簽名是不同的。你可使用它來計算大型文本文件的簽名,這個模塊在加密和安全領域有很多用途。 |
| itertools | 包含大量用于創建和合并迭代器(或其他可迭代對象)的工具,其中包括可以串接可迭代對象、創建返回無限連續整數的迭代器(類似于range,但沒有上限)、反復遍歷可迭代對象以及具有其他作用的函數。 |
| logging | 使用print語句來確定程序中發生的情況很有用。要避免跟蹤時出現大量調試輸出,可將這些信息寫入日志文件中。這個模塊提供了一系列標準工具,可用于管理一個或多個中央日志,它還支持多種優先級不同的日志消息。 |
| statistics | 計算一組數的平均值并不那么難,但是要正確地獲得中位數,以確定總體標準偏差和樣本標準偏差之間的差別,即便對于偶數個元素來說,也需要費點心思。在這種情況下,不要手工計算,而應使用模塊statistics! |
| timeit | 模塊timeit(和配套的命令行腳本)是一個測量代碼段執行時間的工具。這個模塊暗藏玄機,度量性能時你可能應該使用它而不是模塊time。 |
| profile | 模塊profile(和配套模塊pstats)可用于對代碼段的效率進行更全面的分析。 |
| trace | 模塊trace可幫助你進行覆蓋率分析(即代碼的哪些部分執行了,哪些部分沒有執行),這在編寫測試代碼時很有用。 |
小結
| 概念 | 解釋 |
|---|---|
| 模塊 | 模塊基本上是一個子程序,主要作用是定義函數、類和變量等。模塊包含測試代碼時,應將這些代碼放在一條檢查name == 'main’的if語句中。如果模塊位于環境變量PYTHONPATH包含的目錄中,就可直接導入它;要導入存儲在文件foo.py中的模塊,可使用語句import foo。 |
| 包 | 包不過是包含其他模塊的模塊。包是使用包含文件__init__.py的目錄實現的。 |
| 探索模塊 | 在交互式解釋器中導入模塊后,就可以眾多不同的方式對其進行探索,其中包括使用dir、查看變量__all__以及使用函數help。文檔和源代碼也是獲取信息和洞見的極佳來源。 |
| 標準庫 | Python自帶多個模塊,統稱為標準庫。 |
| 標準庫名稱 | 介紹 |
|---|---|
| sys | 這個模塊讓你能夠訪問多個與Python解釋器關系緊密的變量和函數。 |
| os | 這個模塊讓你能夠訪問多個與操作系統關系緊密的變量和函數。 |
| fileinput | 這個模塊讓你能夠輕松地迭代多個文件或流的內容行。 |
| sets、heapq和deque | 這三個模塊提供了三種很有用的數據結構。內置類型set也實現了集合。 |
| time | 這個模塊讓你能夠獲取當前時間、操作時間和日期以及設置它們的格式。 |
| random | 這個模塊包含用于生成隨機數,從序列中隨機地選擇元素,以及打亂列表中元素的函數。 |
| shelve | 這個模塊用于創建永久性映射,其內容存儲在使用給定文件名的數據庫中。 |
| re | 支持正則表達式的模塊。 |
本章節介紹的新函數
| 函數 | 描述 |
|---|---|
| dir(obj) | 返回一個按字母順序排列的屬性名列表 |
| help([obj]) | 提供交互式幫助或有關特定對象的幫助信息 |
| imp.reload(module) | 返回已導入的模塊的重載版本 |

方法)


:項目管理三大目標)



)

方法與示例)


之C語言程序設計復試筆試最后押題五套卷...)





(轉))