課程來源:人工智能實踐:Tensorflow筆記2
文章目錄
- 前言
- 一、搭建網絡八股sequential
- 1.函數介紹
- 2.6步法實現鳶尾花分類
- 二、搭建網絡八股class
- 1.創建自己的神經網絡模板:
- 2.調用自己創建的model對象
- 三、MNIST數據集
- 1.用sequential搭建網絡實現手寫數字識別
- 2.用類搭建網絡實現手寫數字識別
- 四、FASHION數據集
- 用sequential搭建網絡實現衣褲識別
- 總結
前言
本講目標:使用八股搭建神經網絡 神經網絡搭建八股 iris代碼復現 MNIST數據集 訓練MNIST數據集 Fashion數據集一、搭建網絡八股sequential
使用六步法,使用TensorFlow的API: tf.keras搭建網絡八股
1、import 導入相關模塊
2、train、test 告知要喂入網絡的訓練集、測試集是什么,也就是要指定訓練集、測試集的輸入特征和訓練集的標簽
3、model = tf.keras.models.Sequential 在sequential()中搭建網絡結構,逐層描述每層網絡,相當于走了一遍前向傳播
4、model.compile 在compile中配置訓練方法,告知訓練時選擇哪種優化器,選擇哪個損失函數,選擇哪種評測指標
5、model.fit 在fit中執行訓練過程,告知訓練集和測試集的輸入特征和標簽,告知每個batch是多少,告知要迭代多少次數據集
6、model.summary 用summary打印出網絡的結構和參數統計
1.函數介紹
sequential()用法:
model = tf.keras.models.Sequential([網絡結構]) #描述各層網絡
網絡結構舉例:
拉直層:tf.keras.layers.Flatter()
全連接層:tf.keras.layers.Dense(神經元個數,activation=“激活函數”,kernel_regularizer=哪種正則化)
activation(字符串給出) 可選:relu、softmax、signoid、tanh
kernel_regularizer可選:kernel_regularizer.l1()、kernel_regularizer.l2()
卷積層:tf.keras.layers.Conv2D(filters=卷積核個數,kernel_size=卷積核尺寸,strides=卷積步長,padding=“vaild” or “same”)
LSTM層:tf.kreas.layers.LSTM()
compile() 用法:
model.compile(optimizer =優化器,loss =損失函數,metrics=[“準確率”])
optimizer 可選:
‘sgd’ or tf.keras.optimizers.SGD(lr=學習率,momentum=動量參數)
‘adagrad’ or tf.keras.optimizers.Adagrad(lr=學習率)
‘adadelta’ or tf.keras.optimizers.Adadelta(lr=學習率)
‘adam’ or tf.keras.optimizers.Adam(lr=學習率,beta_1=0.9,beta_2=0.999)
loss 可選:
‘mse’ or tf.keras.losses.MeanSquaredError()
‘sparse_categorical_crossentropy’ or tf.keras.losses.SparseCategoricalCrossentropy(from_logits =False)
(有的神經網絡的輸出是經過了softmax等函數的概率分布,有些則不經概率分布直接輸出,from_logits 是在詢問是否是原始輸出)
Metrics 可選:
‘accuracy’:y_pred和y都是數值,如y_pred=[1] y=[1]
‘categorical_accuracy’:y_pred 和 y 都是獨熱碼(概率分布),如y_pred=[0,1,0], y=[0.5,0.5,0.5]
‘sparse_categorical_accuracy’:y_pred是數值,y是獨熱編碼,y_pred=[1],y=[0.5,0.5,0.5]
fit()用法:
model.fit(訓練集的輸入特征,訓練集的標簽,
? batch_size = ,epochs = ,
? validation_data =(測試集的輸入特征,測試集的標簽),
? validation_split =從訓練集劃分多少比例給測試集,
? validation_freq =多少次epoch測試一次)
model()用法:
model.summary()

2.6步法實現鳶尾花分類
代碼如下:
import tensorflow as tf
from sklearn import datasets
import numpy as np#由于這里是選擇從訓練集劃分出測試集,所以不需要單獨導入test
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
#打亂順序
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
#3個神經元,softmax激活,L2正則化
model = tf.keras.models.Sequential([tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
#SGD優化器、學習率0.1,使用SparseCategoricalCrossentropy作為損失函數,由于神經網絡末端使用softmax函數,輸出為概率分布,所以from_logits為false
#鳶尾花數據集給的標簽為0,1,2,神經網絡前向傳播的輸出是概率分布,使用sparse_categorical_accuracy作為準確率
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])
#輸入訓練數據,一次喂入32組數據,迭代500次,從訓練集中劃分出20%作為測試集,每迭代20次訓練集就要在測試集中驗證一次準確率
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
#打印網絡結構和參數統計
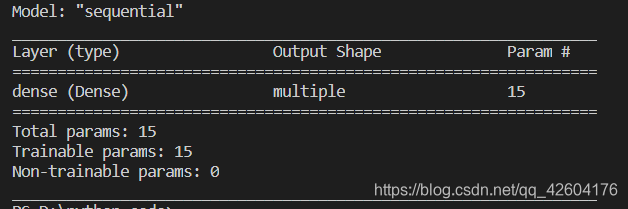
model.summary()
打印結果如下:
二、搭建網絡八股class
用sequential可以搭建出上層輸出就是下層輸入的順序網絡結構,但是無法寫出一些帶有跳連的非順序網絡結構。這時我們可以選擇用類class搭建神經網絡結構
使用六步法,使用TensorFlow的API: tf.keras搭建網絡八股
1、import
2、train、test
3、class MyMode(Model) model=MyModel
4、model.compile
5、model.fit
6、model.summary
1.創建自己的神經網絡模板:
偽代碼如下:
class MyModel(Model):def _init_(self):super(MyModel,self).init_()定義網絡結構塊def call(self,x):調用網絡結構塊,實現前向傳播return ymodel=MyModel()
代碼如下:
class IrisModel(Model):def __init__(self):super(IrisModel, self).__init__()#鳶尾花分類的單層網絡是含有3個神經元的全連接self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())def call(self, x):y = self.d1(x)return y
#實例化名為model的對象
model = IrisModel()
2.調用自己創建的model對象
代碼如下:
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as npx_train = datasets.load_iris().data
y_train = datasets.load_iris().targetnp.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
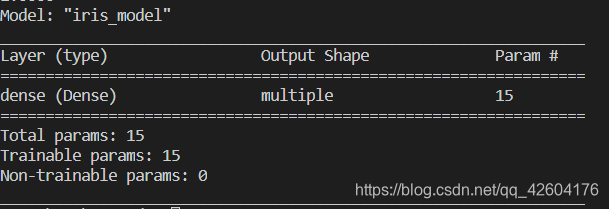
tf.random.set_seed(116)class IrisModel(Model):def __init__(self):super(IrisModel, self).__init__()self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())def call(self, x):y = self.d1(x)return ymodel = IrisModel()model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()打印結果如下:
三、MNIST數據集
MNIST數據集
提供6萬張28x28像素點的0~9手寫數字圖片和標簽,用于訓練。
提供1萬張28x28像素點的0~9手寫數字圖片和標簽,用于測試。
導入數據集
mnist =tf.keras.datasets.mnist
(x_train,y_train),(x_test,y_test)=mnist.load_data()
作為輸入特征,輸入神經網絡時,將數據拉伸為一維數組
tf.keras.layers.Flatter()
1.用sequential搭建網絡實現手寫數字識別
code:
import tensorflow as tfmnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#對輸入網絡的特征進行歸一化,使原本0~255的灰度值轉化為0~1的小數。
#把輸入特征的值變小更有利于神經網絡吸收
x_train, x_test = x_train / 255.0, x_test / 255.0
#用Sequential搭建網絡
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(), #把輸入特征拉直為1維數組,即784(28*28)個數值tf.keras.layers.Dense(128, activation='relu'), #定義第一層網絡有128個神經元,relu為激活函數tf.keras.layers.Dense(10, activation='softmax') #定義第二層網絡有10個神經元,softmax使輸出符合概率分布
])
#用compile配置訓練方法
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])
#每一輪訓練集迭代,執行一次測試集評測,隨著迭代輪數增加,手寫數字識別準確率不斷提升(使用測試集)
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
print result:
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [] - 4s 62us/sample - loss: 0.2589 - sparse_categorical_accuracy: 0.9262 - val_loss: 0.1373 - val_sparse_categorical_accuracy: 0.9607
Epoch 2/5
60000/60000 [] - 2s 40us/sample - loss: 0.1114 - sparse_categorical_accuracy: 0.9676 - val_loss: 0.1027 - val_sparse_categorical_accuracy: 0.9699
Epoch 3/5
60000/60000 [] - 3s 43us/sample - loss: 0.0762 - sparse_categorical_accuracy: 0.9775 - val_loss: 0.0898 - val_sparse_categorical_accuracy: 0.9722
Epoch 4/5
60000/60000 [] - 2s 41us/sample - loss: 0.0573 - sparse_categorical_accuracy: 0.9822 - val_loss: 0.0851 - val_sparse_categorical_accuracy: 0.9752
Epoch 5/5
60000/60000 [] - 2s 41us/sample - loss: 0.0450 - sparse_categorical_accuracy: 0.9858 - val_loss: 0.0846 - val_sparse_categorical_accuracy: 0.9738
Model: “sequential”
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) multiple 0
dense (Dense) multiple 100480
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
可以觀察到,隨著迭代輪數增加,準確率也不斷提升。訓練的參數也是極其多的,達到10萬多個。
2.用類搭建網絡實現手寫數字識別
只是實例化model的方法不同,其他與用sequential搭建網絡實現手寫數字識別一致。
init函數中定義了call函數中所用到的層,call函數中從輸入x到輸出y走過一次前向傳播,返回輸出y
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Modelmnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0class MnistModel(Model):def __init__(self):super(MnistModel, self).__init__()self.flatten = Flatten()self.d1 = Dense(128, activation='relu')self.d2 = Dense(10, activation='softmax')def call(self, x):x = self.flatten(x)x = self.d1(x)y = self.d2(x)return ymodel = MnistModel()model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()四、FASHION數據集
FASHION數據集
提供6萬張 28x28像素點的衣褲等圖片和標簽,用于訓練.
提供1萬張28x28像素點的衣褲等圖片和標簽,用于測試。

導入數據集
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
用sequential搭建網絡實現衣褲識別
加載數據需要較長時間,需耐心等待
import tensorflow as tffashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')
])model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy'])model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()用類的方法也可以實現,這里不做重復展開,套用八股模板即可。
總結
這個單元將整個訓練的構架走了一遍,并且以八股的形式做了總結,收獲很大。課程鏈接:MOOC人工智能實踐:TensorFlow筆記2

方法與示例)


之C語言程序設計復試筆試最后押題五套卷...)





(轉))



運算符)


的重要性)

